第十一课:逻辑综合基本原理及设计输入
主要内容
综合,就是把idea变成现实的过程;
逻辑综合和功能仿真/形式验证可以是同步进行的;
Synthesis Flow
顶层综合的flow,主要分为五大步骤;
①首先导入库文件和design设计文档/RTL coding;
②第二步是加入一些时序约束及设计规则约束;
③利用综合工具跑综合,通过改一些不同的参数,得到不同的结果;这一步将占用EDA工具95%时间;
④对得到的结果进行横向和纵向进行分析,如在同一个结果中分析时序差的原因,或将不同参数得到的结果进行横向对比;这一步占用人的时间最多;
⑤将符合要求的综合结果输出netlist;
在整个后端flow中,一般的工作方向有两类,一是flow开发,编写所需要的各种flow脚本;二是进行综合结果分析的工作,就是利用开发的flow,通过调节不同参数,分析得到的不同结果及debug;
Synthesis
Synthesis=Translation+Gate Mapping+Logic Optimization=转换+门级映射+逻辑优化;
当我们告诉综合工具要做综合了,工具就是做了上述三个事情,先把RTL coding 和约束进行转换,然后再进行门级映射gate mapping,最后再做逻辑优化;
门级网表:前面第一课就说过,门级网表也是代码,不过不是像verilog coding那种,而是工具自动得到的门级电路图,如上图右侧所示,里面包含了各种门和连线;
Translation
当我们把coding读到工具里面时,工具会立刻转换并得到一个GTECH网表(gtech),这是一个过渡用的中间网表,这个网表里面的这些门是EDA软件得到的,并不是真实存在的,所以那些门的延时之类的数据是不存在的;
Gate Mapping

Gate Mapping门级映射,建立理解就是替换,前面不是得到了GTECH网表嘛,里面的门都是EDA工具得到的,在此处,就是确定了代工厂后,将GTECH中的各个门换成相应代工厂内的标准门,这个简单替换的过程叫映射;
Logic Optimization

完成映射过程后,工具就开始进行逻辑优化,更换不同面积的门等,检查是否满足时序、面积、DRC等约束的要求;
Tsetup=max delay(规定延时不能大于多少),Thold=Tmin delay(延时不能小于多少);在逻辑综合阶段只考虑Tsetup,不考虑Thold(CTS之后),原因第六课有解释;
前面第六课也提到过,在代工厂的标准cell中,同一种门会有不同的选择,有的延时低但面积大,有的延时高但面积小,后端的总体思路就是:在满足时序约束的前提下,用最小的面积;
另外,代工厂还会提供一些复杂门,一个复杂门可以代替多个简单门,且有更好的时序和更优的面积,那么问题来了,能否大量使用复杂门呢?
答:不能,因为复杂门的连线更多更集中,当某区域大量存在复杂门时,后面进行金属连线时,就会导致连线过密集,称为连线拥塞;所以有些时候宁可用简单门也不用复杂门;
DRC:Design Rule Check;一般来说,代工厂的DRC指的是线宽/间距等检查,但此处指的是逻辑DRC,即上述的max fanout/capacitance/transition等,工艺厂商会规定一个cell的最大输入转换时间,最大负载电容(与带载能力相关),最大扇出等(扇出的物理参数理解就是负载电容,只不过扇出针对的是输出端,而负载电容应该还包含输入端管脚的负载电容;/例:一个与门后面带两个与门,那么fanout就是2,这两个与门产生的电容值就是负载电容,因此fanout越大,负载电容肯定越大,但负载电容的容值肯定更精确,故一般用负载电容来约束负载能力),所有的这些值,最终都与cell的延时相关;
前面第六课提过,cell延时正比于输入转换时间和负载电容,代工厂会给出一个包含这两个参数的二维查找表,以供查找;超过这个表规定部分的延时就是工具利用线性插值得到的值,那么最终得到的延时信息肯定是不准的,超出表格延时不准就不是工艺厂商的责任了; 所以DRC约束的目的就是为了能够根据二维查找表精确计算cell延时;当cell驱动能力不够时,就加驱动能力大的buffer,降低fanout等;
例:见下图

此处,index1/2就分别代表了输入转换时间和负载电容,具体哪个对哪个要看另外的说明;若此时,index1取0.006,不在上面列出来的数中,那也没关系,只要在0-0.12768之间,工具通过线性插值得到的延时信息是可靠的;但一旦超过了上述范围,那么工具插出来的值就不准了;
DC三种操作方式
①design_vision,直接打开gui界面进行操作,适合新手;
②dc_shell,命令行模式;
③Batch mode:批处理模式,先把批处理命令写好,然后运行;
注:topographical_mode是高级模式,不是纯逻辑综合,而是在进行综合时会将物理实现步骤(见图3 physical implements)的一些内容考虑进去,最后得到的综合结果与做完PR的结果更加匹配;当然使用时也需要提供给综合工具一些物理实现相关信息;可以简写为-topo;
”tee”:常说”tee一下”,即把前面tcl脚本运行的结果存到DC.log文件里,”-i”表示把结果输出到文件内的同时,也在窗口显示出来,直观;如果不加的话,就只会输出到文件,不会直接显示出来;

简述:
①”\newline”=space;
②当要注释某行时,tcl中是使用”#”,而不是"//";
③在某行中进行注释时,由于tcl的command没有截止符号,所以需要在#前面加个”;”
④运行脚本前,先source加载到内存中来;

一些dc和linux通用的命令:pwd/ls/cd/!之类的;
注意最后一条,当在dc中得到一个rpt后,如DC.rpt,这时候你不想退出dc,但又想把该rpt打开,就可以:”sh gvim DC.rpt”,在前面加个”sh”命令就可以调用任何linux命令了;但在一般操作中,如果该文件比较大占内存,容易导致dc闪退,所以小文件无所谓,大文件还是另外打开吧。
Design and Technology Data

DC运行及导入RTL

①首先cd进入risc_design文件夹,内含三个文件夹,cons/为约束文件夹,rtl/为rtl coding,libs/为工艺厂商提供的一些库及相关文件;
②打开dc_shell,这里选的是topo模式;所以接下来的第三步他会要设置物理实现的相关文件;
③利用”read”命令,把rtl coding读到dc工具中来;
④可以看到,首先工具先加载了自带的”.db”库文件,然后就会得到gtech.db未映射的中间级网表;
⑤随后的warning是因为没有设置相应的link_library文件,先不管;
⑥”“unmapped ddc”就是gtech文件,".ddc"格式是把所有的相关文件先打包到一起;
导入约束并综合
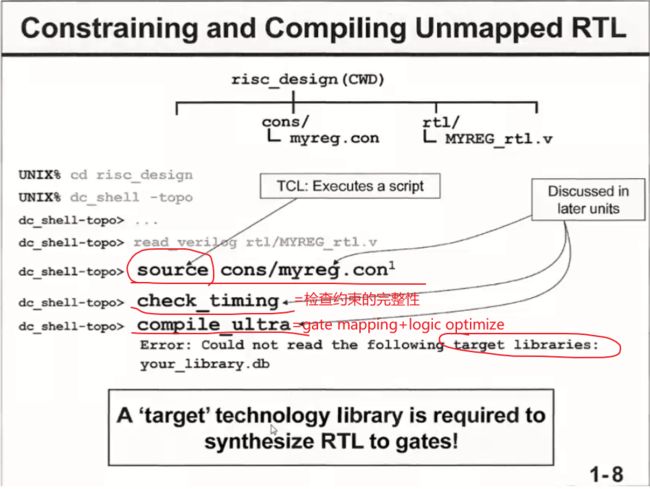
①加载完rtl coding后,就需要加载约束文件了,约束文件通常写成一个脚本,需要用"source"命令加载到内存中来;
②此处的”check_timing”不是检查时序,而是检查每条路径是否都加了时序约束,检查时序约束完整性;
③“compile_ultra"就是执行剩下的两步综合命令:映射+逻辑优化;下面有报”Error”,提示没有相关的目标工艺库文件,这里的目标库文件就是工艺厂商提供的工艺库文件了,因为映射的过程就是把EDA自己的各种门换成工艺厂商标准门的过程,没有工艺库文件就无法替换;
Target_library

如图标注,这是lib文件的一些内容,其中.db格式的是打不开的,但可以转换为.lib格式再用gvim打开;通过cell名称”mh_sbufx2“可以大致看出,这是一个buffer cell,x2表示的是驱动能力;
前面说了,在进行gate_mapping时,如果没有指定目标工艺库文件的话,DC会报error,因为DC默认的target_library=your_library.db,而your_library.db这个文件默认是不存在的,所以会报错;
因此,我们需要人为的设置target_library指定的文件,用set_app_var命令,其实这个命令和set命令的功能是一样的,但是set_app_var一般针对的是DC软件自带的固有变量,即target_library是DC的固有变量,此时用set_app_var的话,系统会检查后面的变量是否有误,这样可以保证人没有写错单词而引起软件报错;把工艺库文件的”路径/文件名”给到target_library变量,就算设置好了目标工艺库文件了;记住,目标库只有一个,而且必须是标准单元库,不包括其他一些IP库;
得到Gate_Netlist

综合之前,先设置目标工艺库文件;然后运行综合,最后,利用”write“命令把得到的网表文件保存下来,为了区别rtl coding的.v格式文件,此处的网表文件我们一般设置为”.gv”;最后退出;
门级网表分析步骤
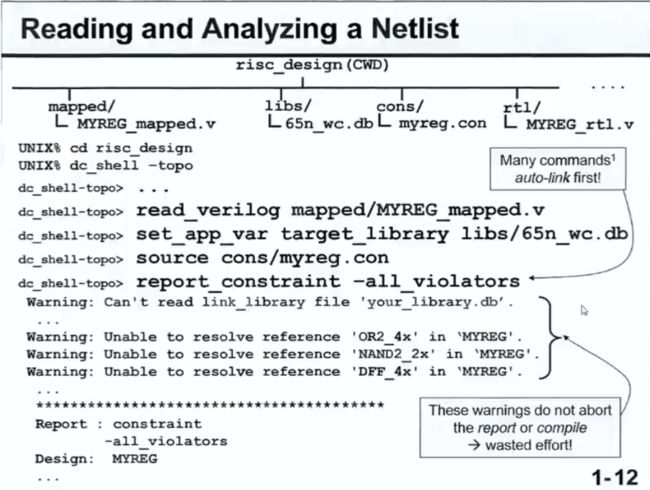
得到网表后,要对网表进行分析,故首先用read把网表读进来,然后设置目标库,加载时序约束,”report_constraint -all_violators“把所有违规的地方报告出来;但后面又报警告了,说是没有设置link_library,下面就来讲一下什么是链接库及怎么设置;
Link_library

link_library:链接库,当把门级网表读到DC里面去了以后,因为门级网表里面的各种门已经是映射后的工艺标准门了,上面的一些门名称都是按工艺厂商库文件定义的,这时候DC工具就无法识别了,因此,链接库就是起到一个链接作用,DC工具会查链接库去对比,找到相应的门在DC工具中的命名,可以简单理解为gate mapping的反过程;所以一般在设置目标库的时候,也一起把链接库设置了,格式如上;
为什么此处设置链接库的时候,不是直接用工艺库的文件名,而是用变量替换呢?为了方便以后改工艺库文件,要改的话只需要改一个地方就好了;
完整的导入门级网表分析流程;
search_path设置
如上,上面在导入目标库/链接库/约束/rtl coding等文件时,通常前面会带一个文件路径,这样万一以后文件路径有改变,那么修改起来很麻烦,故引出search_path命令;

search_path:DC固有变量,如上图,search_path命令有默认的一些路径,一般是安装路径,我们用的时候不用修改他的默认值,而是在后面加上一些值,这也是为什么search_path前面有个变量替换的原因;
我们可以把一些常用的文件路径列成一个list,跟在search_path后面,如上的格式,这样在写命令时,文件前面就不用带路径了,DC会自己去按list里面列出来的路径挨个去找对应的文件;
隐藏文件设置-.synopsys_dc.setup
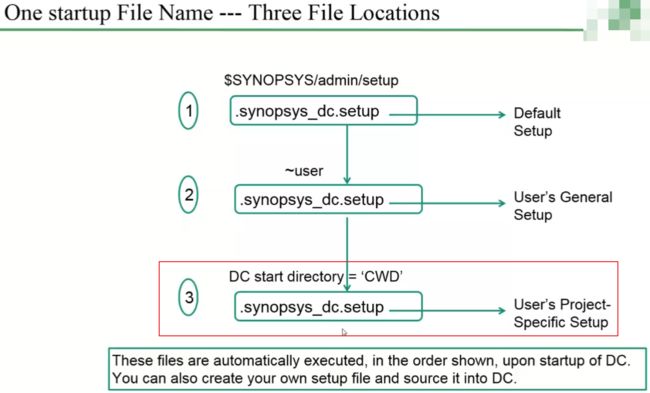
三个隐藏文件是DC自动生成的,前面两个我们一般不用管,最后一个我们需要修改一些内容;

打开第三个文件后,我们把这三个固有变量修改一下,symbol_lib一般不设置;

修改成上述的;除了那三个固有变量外,还可以定义一些缩写,因为那几个命令是经常用的,每次打都要打一串,可以定义一些缩写;
alias:缩写/别名;


一个简单的问题:当我们要更换新的工艺库时,可以怎么做?
①全部重新来一遍当然是可以的;
②还可以用图二的方法,这时候目标库和链接库就不一样了,因为加载老的网表时用的反映射流程需要对照老的网表,即链接库为老库;然后导入新的目标库跑一边综合就可以啦;
完整命令流程总结

上面就是整个运行dc跑综合的命令啦,里面的每条命令背后对应的关系都分析过啦~
几个常犯错误
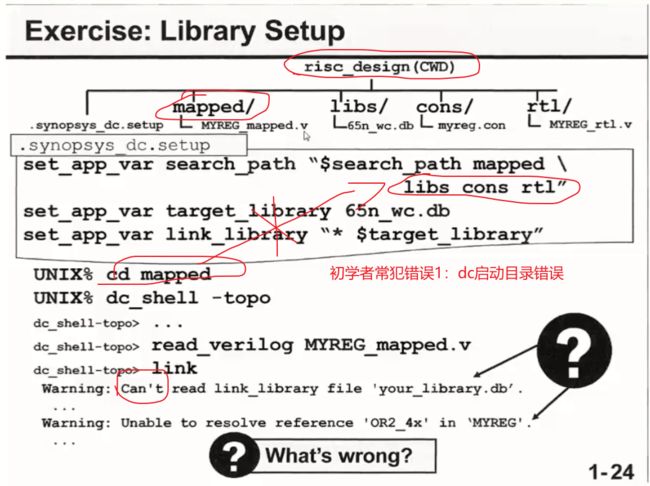
错误:dc启动目录错误,导致dc在当前启动目录下找不到search_path中设置的目录list,从而导致文件加载失败;
层次化设计
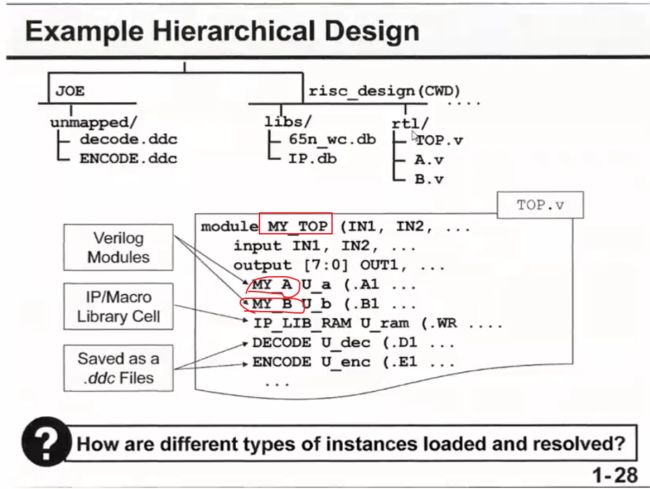
当一个芯片中含多个模块时,通常采用层次化设计,有一个顶层模块TOP.v和其他模块;
注意,此处的MY_TOP不是文件名,而是模块名,该模块里面可以包换其他的模块;

当我们把这些coding导入dc时,有以上三种方式:
①依次读取每个模块,读取三次;这样的话,dc会默认最后一次读取的为当前要跑综合的模块;
②把三个模块当作一个grouping导入,那么dc会认为第一个是当前的模块;
③把三个模块整合到一个.v文件内,那么dc会认为该文件中的第一部分为当前模块;

因此,我们在运行dc前,可以先把当前模块MY_TOP定义了,然后只要这里面包含了什么模块,dc就会跑对应模块的代码综合;
读rtl coding的另一种方式

前面是用read+current_design来读取coding的,现在可以用analysis+elaborate命令达到相同的效果;二者的不同在于:
①后者可看为把read命令分成了两步来实现,第一步是会分别检查MY_TOP包含的各个不同模块是否存在存在连接error,有的话就会报错,不需要像read命令把所有代码都导入后才检查;
②后者的elaborate命令是唯一可以在读取coding时更改代码参数的命令,而不需要去重新修改rtl coding;很关键!这样就实现了我们前面说的:通过调控一些不同的参数得到不同的网表在横向对比;
其他IP库的处理
对于芯片中包含的一些其他IP,也会有库文件,但dc是不需要在对这些IP库进行综合的了,简单来说,这些IP模块已经是设计布置好的了,我们只是拿来用,无需dc综合优化,直接当成一个大的cell就行了,因此这些IP的库文件只需要放在link_lib中,用来进行反映射过程使;一些其他的各种奇怪库文件,都是放在链接库中,目标库只有唯一一个,那就是标准工艺库;
.ddc文件的读取与保存
.ddc文件相当于是一个打包文件,举个例子,这里面的A.v & B.v是别人写好的而且已经综合优化好了,打包成ddc文件发给你,那么你用时就需要把ddc读进来;这种情况比较少见;

ddc文件的保存,和verilog一样,只不过格式那里写的是ddc,在综合前后都可以保存ddc文件;保存ddc文件是很用必要的,当我们综合完退出后,突然想再看一下某个参数时,这时候只需要再次read .ddc文件进到dc,就会把相关的设计网表/约束等全部加载进来,而不需要再重新跑一遍综合;