数据结构 排序 (图解+C语言)
★★★★★排序
当数据量非常大时,排序的效率就非常重要;所以以下学习的排序的数据起步量都是10000个以上
各种排序的统一函数名规范:
void X_Sort( ElementType A[],int N );
排序名称 待排元素 数组大小
放在数组里
元素类型包括所有能排大小的数据结构,比如数字,字符串等等,都可以用排序算法;
.默认为将整数从小到大排序:为了简单起见,所有排序算法的理解和代码都是以整数为例;
.输入的N为正整数;
.只讨论基于比较的排序(> = < 有定义):对于要排序的数据类型,有明确的大小相等的定义;
.只讨论内部排序:假设内存空间充足,所有数据能一次性的导入内存空间;排序过程在内存中完成;
外部排序:数据量大于内存,需要分若干次数据的导入导出才能完成的排序;
.稳定性:任意两个相等的数据,排序前后的相对位置不发生改变;
.没有一种排序时任何情况下都表现最好的:每一种算法都有它存在的理由
当数据具有某种特征的时候,某一种算法可能是最好的
测试用例说明:
给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。
本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下:
- 数据0:只有1个元素;
- 数据1:11个不相同的整数,测试基本正确性;
- 数据2:10^3个随机整数;
- 数据3:10^4个随机整数;
- 数据4:10^5个随机整数;
- 数据5:10^5个顺序整数;
- 数据6:10^5个逆序整数;
- 数据7:10^5个基本有序的整数;
- 数据8:10^5个随机正整数,每个数字不超过1000。
输入格式:
输入第一行给出正整数N(≤105),随后一行给出N个(长整型范围内的)整数,其间以空格分隔。
输出格式:
在一行中输出从小到大排序后的结果,数字间以1个空格分隔,行末不得有多余空格。
输入样例:
11 4 981 10 -17 0 -20 29 50 8 43 -5输出样例:
-20 -17 -5 0 4 8 10 29 43 50 981
代码长度限制 16 KB
时间限制 10000 ms
内存限制 64 MB ※简单排序:
▶♥ 冒泡排序
20 把数据想象成泡泡,大数据=>大泡泡,小数据=>小泡泡;
12 不断地做从上到下扫描,每当看到更大的大泡泡时,就把它往下压;
39 每次从上到下扫描一遍:如果A[i] > A[i+1];Swap(A[i],A[i+1]);
9 所以每一次扫描就是只将最大的泡泡交换到最底下
60 当扫描一遍发现已经都排好序了,即没有发生Swap,那就跳出循环
8
42 void Bubble_Sort( ElementType A[],int N )
3 {
28 int i,Tag = 1; //存在需要排序的情况
while(Tag){
Tag = 0; //假设已经都排好了
for(i=0;i A[i+1]){
Swap( &A[i],&A[i+1] );
Tag = 1; //有Swap发生,还需要扫描
}
}
}
}
代码优化:由于每一次扫描一定是将最大的泡泡压到了最底下,所以下一次扫描时,只需扫描到倒数第二的位置就可以啦
以此类推,每扫描一遍,下次需要扫描的长度就-1;
void Bubble_Sort( ElementType A[],int N ) void Bubble_Sort( ElementType A[],int N )
{ {
int i,Tag = 1; int i,P,flag;
while(Tag){ for(P=N-1;P>0;P--){
Tag = 0; flag = 0;
for(i=0;i A[i+1]){ if(A[i] > A[i+1]){
Swap( &A[i],&A[i+1] ); Swap( &A[i],&A[i+1]);
Tag = 1; flag = 1;
} }
} }
if(flag == 0){
N--; break;
} }
} }
}
时间复杂度:最好情况 T=O(N)
最坏情况 T=O(N^2)
冒泡排序的缺点:时间复杂度达到O(N^2)
优点:①如果待排元素放在链表里,同样适用
②具有稳定性
. 测试结果:
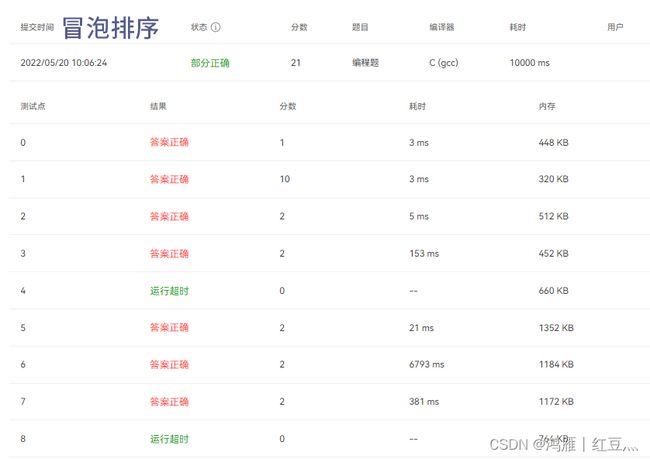
代码:
#include
void Swap( int* a,int* b );
void Print( int A[],int N );
void Bubble_Sort( int A[],int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i0;P--){
IsAllInOrder = 1;
for(i=0;iA[i+1]){
Swap( &A[i],&A[i+1] );
IsAllInOrder = 0;
}
}
if(IsAllInOrder){
break;
}
}
}
void Swap( int* a,int* b )
{
int Temp = *a;
*a = *b;
*b = Temp;
}
void Print( int A[],int N )
{
int i;
for(i=0;i ▶♥ 插入排序
将排序的过程模拟为抓牌的过程,
抓第一张,放在A[0],不动
抓第二张 和前面的比较 如果前面的比较大 那就后移一位 即A[1] = A[0];
抓第三张 和第二张比较 如果第二张比较大 那就后移一位 即A[2] = A[1];再和第一张比较 第一张大 那就A[1] = A[0];然后A[0] = 这张牌
... ... 手里这张牌大 那就A[1] = 这张牌
如此循环 直到抓完最后一张牌
抓第一张牌10 放手里 10
抓第二张牌8 对比 8 10
抓第三张牌J 对比 8 10 J
抓第四张牌3 一张张 对比 3 8 10 J
void Insertion_Sort( ElementType A[],int N )
{
for(P=1;P0;i--){//依次和前面的牌比较
if(A[i-1] > Temp){ //如果不符合顺序
A[i] = A[i-1]; //后移一位
}else{ //否则
A[i] = Temp; //新牌落座
break; //不用再比了,跳出循环
}
}
}
}
代码优化:
void Insertion_Sort( ElementType A[],int N )
{
for(P=1;P0 && A[i-1]>Temp;i--){
A[i] = A[i-1]; /* 移出空位 */
}
A[i] = Temp; /* 新牌落座 */
}
}
时间复杂度:最好情况 T=O(N)
最坏情况 T=O(N^2)
优点:程序简单,步骤少,具有稳定性
. 测试结果:

比冒泡好很多;
代码:
#include
void Print( int A[],int N );
void Insertion_Sort( int A[],int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i=1 && A[i-1]>Temp;i--){
A[i] = A[i-1];
}
A[i] = Temp;
}
}
void Print( int A[],int N )
{
int i;
for(i=0;i ※排序进阶:
※时间复杂度下界
.对于下标iA[j],则称(i,j)是一对逆序对(inversion)
.问题:序列{34,8,64,51,32,21}中有多少逆序对?
(34,8) (34,32) (34,21) (64,51) (64,32) (64,21) (51,32) (51,21) (32,21) 9对
简单排序(比如冒泡排序 插入排序 Low选择排序) 每次都只是交换一个逆序对,所以交换的次数都是9次
.交换2个相邻元素正好消去1个逆序对
.插入排序:T(N,I)=O(N+I) I是逆序对的个数
口 如果序列基本有序,则插入排序简单且高效
.定理:任意N个不同元素组成的序列平均具有N(N-1)/4个逆序对
.定理:任何仅以交换相邻两元素来排序的算法,其平均时间复杂度为Ω(N^2) Ω指的是下界
.这意味着:要提高算法效率,我们必须
==>每次消去不止1个逆序对!
==>每次交换相隔较远的2个元素!
.
▶♥ 希尔排序 (by Donald Shell)
利用插入排序的简单,同时克服插入排序每次只交换相邻两个元素的这个缺点
例如: 81 94 11 96 12 35 17 95 28 58 41 75 15
先做5-间隔排序 即(81 35 41) (94 17 75) (11 95 15) (96 28) (12 58)
35 17 11 28 12 41 75 15 96 58 81 94 95
再做3-间隔排序 28 12 11 35 15 41 58 17 94 75 81 96 95
最后1-间隔排序
.定义增量序列Dm>D(m-1)>...>D1=1
.对每个Dk进行"Dk-间隔"排序(k=M,M-1,...,1)
.注意到:更小间隔的排序没有将上一步的结果变坏
"Dk-间隔"有序的序列,在执行"Dk-1-间隔"排序后,仍然是"Dk-间隔有序"的
原始希尔排序 Dm=N/2,Dk=D(K+1)/2
void Shell_Sort( ElementType A[],int N )
{
for(D=N/2;D>0;D/=2){
/* 插入排序 */
for(P=D;P=D && A[i-D]>Temp;i-=D){
A[i] = A[i-D];
}
A[i] = Temp;
}
}
}
希尔排序不具有稳定性
最坏情况:T=Θ(N^2) Θ既是上界又是下界 O是一个上界(有可能达不到) Ω是一个下界
例如: 1 9 2 10 3 11 4 12 5 13 6 14 7 15 8 16
按8-间隔 4-间隔 2-间隔排序后没有任何变化
问题点:增量元素不互质,则小增量可能根本不起作用
更多增量序列:
◎Hibbard增量序列
.Dk = 2^k-1 ————————相邻元素互质
.最坏情况:T=Θ(N^3/2)
.猜想:Tavg = O(N^%/4)
◎Sedgewick增量序列
.{1,5,19,41,109,...} ——————9*4^i-9*2^i+1 或 4^i-3*2^i+1
.猜想:Tavg = O(N^7/6),Tworst = (N^4/3)
希尔排序本质上还是插入排序,只不过先用增量调整了不相邻的逆序对。
Sedgewick增量序列:int Sedgewick[] = {260609,146305,64769,36289,16001,8929,3905,2161,929, 505,209, 109, 41, 19, 5, 1, 0};
即使一个简单的算法,但是关于它的时间复杂度分析可能非常的难
void Shell_Sort( ElementType A[],int N )
{ /* 希尔排序—— 用Sedgewick增量序列 */
int Si,D,P,i;
ElementType Temp;
/* 这里只列出一小部分增量 */
int Sedgewick[] = {929,505,209,109,41,19,5,1,0};
for(Si=0;Swdgewick[Si]>=N;Si++);//初始增量Sedgewick[Si]不能超过待排序列长度
for(D=Sedgewick[Si];D>0;D=Sedgewick[++Si]){
for(P=D;p=D && A[i-D]>Temp;i-=D){
A[i] = A[i-D];
}
A[i] = Temp;
}
}
}
. 总过程:
分解步骤:
第一步:增量为4
第二步:增量为2
第三步:增量为1
测试结果:
1.原始希尔排序:
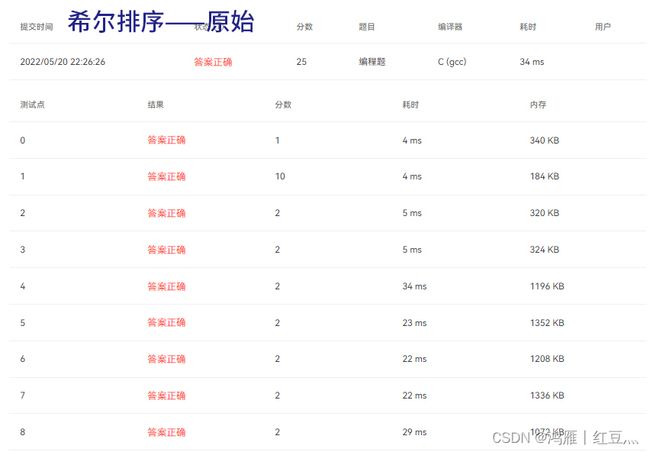
相比插入排序,提升很大,特别是对逆序序列和随机序列
代码:
#include
void Print( int A[],int N );
void Shell_Sort_Original( int A[],int N );
void Insertion_Sort( int A[],int N,int D );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i0;D/=2){
Insertion_Sort( A,N,D );
}
}
void Insertion_Sort( int A[],int N,int D )
{
int P,i,Temp;
for(P=D;P=D && A[i-D]>Temp;i-=D){
A[i] = A[i-D];
}
A[i] = Temp;
}
}
void Print( int A[],int N )
{
int i;
for(i=0;i 2.Hibbard增量——希尔排序:
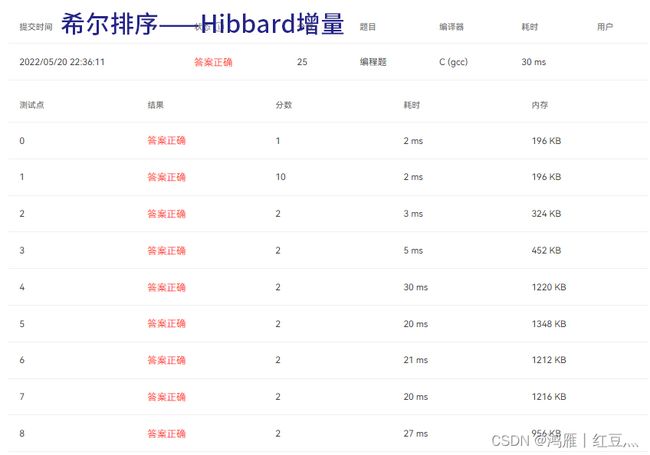
速度相比与原始的希尔排序提升了一点,主要是为了避免原始希尔排序遇到的特殊尴尬情况
代码:
#include
#include
void Print( int A[],int N );
void Shell_Sort_Hibbard( int A[],int N );
void Insertion_Sort( int A[],int N,int D );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i0;K--){
D = (int)pow(2,K)-1;
Insertion_Sort( A,N,D );
}
}
void Insertion_Sort( int A[],int N,int D )
{
int P,i,Temp;
for(P=D;P=D && A[i-D]>Temp;i-=D){
A[i] = A[i-D];
}
A[i] = Temp;
}
}
void Print( int A[],int N )
{
int i;
for(i=0;i 3.Sedgewick增量——希尔排序:
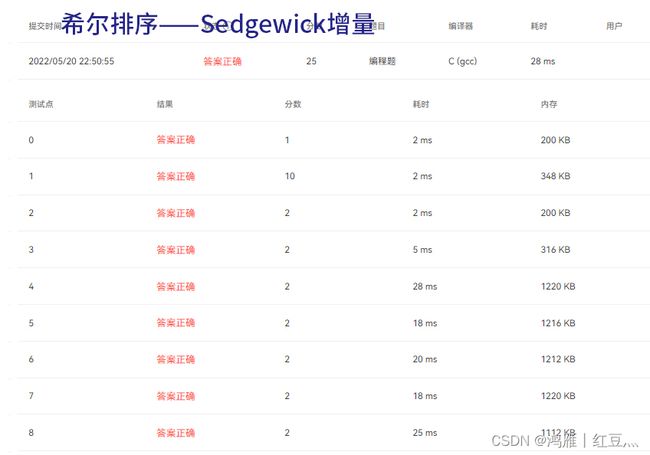
Sedgewick增量的希尔排序 表现优异
代码:
#include
void Print( int A[],int N );
void Shell_Sort_Sedgewick( int A[],int N );
void Insertion_Sort( int A[],int N,int D );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i=N;Si++);
for(;Sedgewick[Si]>0;Si++){
D = Sedgewick[Si];
Insertion_Sort( A,N,D );
}
}
void Insertion_Sort( int A[],int N,int D )
{
int P,i,Temp;
for(P=D;P=D && A[i-D]>Temp;i-=D){
A[i] = A[i-D];
}
A[i] = Temp;
}
}
void Print( int A[],int N )
{
int i;
for(i=0;i ▶♥ 选择排序
从0到N-1 每次选择一个下标,这个下标所存的元素去和其他所有的元素对比,如果比这个小,那就交换过来
所以选择每完成一趟,一定是将最小的元素选择出来了,并放在在正确的位置;
即第i次选择,一定将第i小的元素选择出来了,放在了第i位上.
粗暴方法之Low写法:
void Selection_Sort( ElementType A[]),int N )
{
for(i=0;i测试结果:
1.选择排序之粗暴+Low:
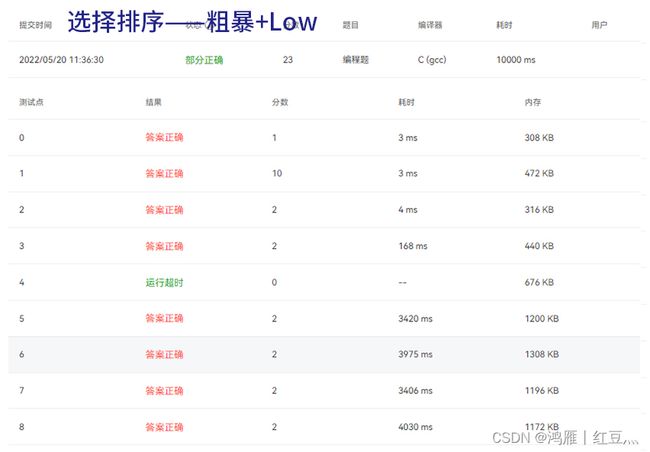
也就比冒泡好那么一点点,对于基本有序的序列还不如冒泡,以后千万别这么写了
代码:
#include
void Swap( int* a,int* b );
void Print( int A[],int N );
void Selection_Sort_Low( int A[],int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i A[j]){
Swap( &A[i],&A[j] );
}
}
}
}
void Swap( int* a,int* b )
{
int Temp = *a;
*a = *b;
*b = Temp;
}
void Print( int A[],int N )
{
int i;
for(i=0;i 2.选择排序之正常写法:
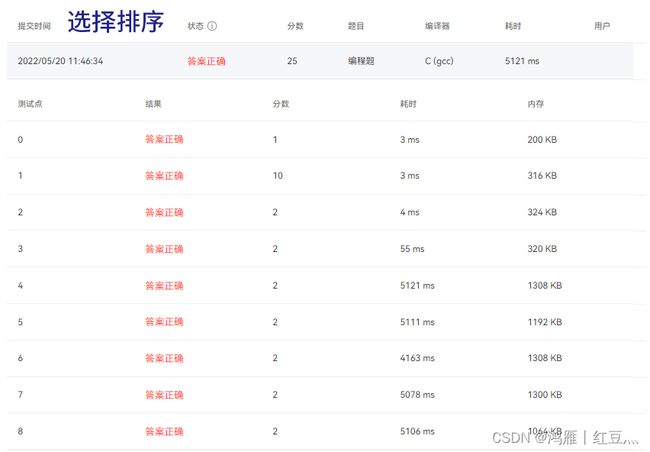
不是很好,不如普通的插入排序
代码:
#include
void Swap( int* a,int* b );
void Print( int A[],int N );
void Selection_Sort( int A[],int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i 选择排序之进阶
▶♥ 堆排序
从上面的选择排序可以看出,如果能快速的找出最小元,那么效率就会大大提高;
如何快速找到最小元? 想到什么?没错!!! ———————堆
堆排序是在选择排序的基础上进行的改进
◎堆排序1:
耿直BOY算法:
void Heap_Sort( ElementType A[],int N )
{
BuildHeap(A);//将数组调整为最小堆
for(i=0;i=0;i--){ //BuildMaxHeap;
PercDown( A,i,N );
}
for(i=N-1;i>0;i--){ //DeleteMaxHeap;
Swap( &A[0],&A[i] );
PercDown( A,0,i );
}
} 优点:高效,适合解决top(K)问题,冒泡排序找top太慢了,插入排序必须等排完才能找到
缺点:不具有稳定性
.定理:堆排序处理N个不同元素的随机排序的平均比较次数是 2NlogN-O(NlogN)
.虽然堆排序给出最佳平均时间复杂度,但实际效果不如用Sedgewick增量序列的希尔排序
void Heap_Sort( ElementType A[],int N )
{
int i;
for(i=N/2;i>=0;i--){
PercDown( A,i,N );
}
for(i=N-1;i>0;i--){
Swap( &A[0],&A[i] );
PercDown( A,0,i );
}
}
void PercDown( ElementType A[],int i,int N )
{/*将N个元素的数组以A[i]为根的子堆调整为最大堆*/
int Parent,Child;
ElementType Temp = A[i];//取出根结点存放的值
for(Parent=i;(Parent*2+1)= A[Child]){
break;
}else{
A[parent] = A[Child];
}
}
A[Parent] = Temp;
}
. 测试结果:
1.堆排序之将原数组调整为最小堆:

比不上采用增量序列的希尔排序,跟原始的希尔排序差不多,但是空间多了不少;所以以后需要的话还是采用最大堆的方式;
代码:
#include
void Print( int A[],int N );
void Heap_Sort_MinHeap( int A[],int N );
void PercDown_MinHeap( int A[],int i,int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i=0;i--){
PercDown_MinHeap( A,i,N );
}
int TempA[N];
int TempN = N;
for(i=0;iA[Child+1]){
Child++;
}
if(Temp <= A[Child]){
break;
}else{
A[Parent] = A[Child];
}
}
A[Parent] = Temp;
}
void Print( int A[],int N )
{
int i;
for(i=0;i 2.堆排序之将原数组调整为最大堆:

对比小顶堆,数据量大的时候空间优化还是很明显的,但是不具有稳定性,空间和时间都是比希尔排序差那么一点
代码:
#include
void Swap( int* a,int* b );
void Print( int A[],int N );
void Heap_Sort( int A[],int N );
void PercDown( int A[],int i,int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i=0;i--){
PercDown( A,i,N );
}
for(i=N-1;i>0;i--){
Swap(&A[0],&A[i]);
PercDown( A,0,i );
}
}
void PercDown( int A[],int i,int N )
{
int Temp = A[i];
int Parent,Child;
for(Parent=i;(Parent*2+1)= A[Child]){
break;
}else{
A[Parent] = A[Child];
}
}
A[Parent] = Temp;
}
void Swap( int* a,int* b )
{
int Temp = *a;
*a = *b;
*b = Temp;
}
void Print( int A[],int N )
{
int i;
for(i=0;i ▶♥ 归并排序
归并的核心:两个有序子列的归并
例如: 1 13 24 26 2 15 27 38 将这两个已经排好序的序列合并成一个序列
算法实现:每个数组一个指针变量(下标)Aptr,Bptr, 比较这两个指针所指的元素大小,
小的元素复制到新的数组中,然后其指针后移一位,继续比较,直到其中一个序列比较完
将另一个序列剩下的没有比较的元素复制到新数组中
核心代码:
/* L=左边序列的起始位置 R=右边序列的起始位置 RightEnd=右边终点位置 两个序列紧邻着放在一个数组里*/
void Merge( ElementType A[],ElmentType TempA[],int L,int R,int RightEnd )
{
LeftEnd = R - 1; //左边终点位置 两个序列紧邻着放在一个数组里
Temp = L; //存放合并后的数组起始位置
NumElements = RightEnd - L + 1;
while(L<=LeftEnd && R<=RightEnd){
if(A[L]<=A[R]){
TempA[Temp++] = A[L++];
}else{
TempA[Temp++] = A[R++];
}
}
while(L<=LeftEnd){ //直接复制左边剩下的
TempA[Temp++] = A[L++];
}
while(R<=RightEnd){ //直接复制右边剩下的
TempA[Temp++] = A[R++];
}
for(i=0;i T(N)=O(NlogN) 没有最坏 最好 平均 任何情况下都是O(NlogN)
最后统一函数接口:
void Merge_Sort( ElementType A[],int N )
{
ElementType* TmpA = NULL;
TmpA = (ElementType*)malloc(N*sizeof(ElementType));
if(TmpA != NULL){
MSort( A,TmpA,0,N-1);//
free(TmpA);
}else{
Error("空间不足");
}
}
. 递归算法 需要占用系统堆栈 加上需要额外的操作 导致递归往往较慢
◎2.循环迭代算法(非递归算法)
A 口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口口
↘↙↘↙ ↘↙↘↙
1 ----————----————----————----————----————----————----————----————
↘↙ ↘↙ ↘↙ ↘↙
2 --------————————--------————————---------————————--------————————
↘ ↙ ↘ ↙ ↘ ↙ ↘ ↙
3 ----------------————————————————-----------------————————————————
↘ ↙ ↘ ↙
i --------------------------------——————————————————————————————————
↘ ↙
------------------------------------------------------------------
将相邻的两个元素做一次归并得到若干个有序的序列,
再将相邻的两个序列做一次归并
......
直到归并成一个有序的序列
☼并不需要每一次归并都开一个对应大小的数组,只需开一个跟原数组同等大小的临时数组TmpA就行
第一次A归并到TmpA,第二次TmpA归并到A,第三次A归并到TmpA....
额外空间复杂度是O(N)
核心算法:循环中的某一趟递归 length=当前有序子列的长度 从1开始 翻倍增长
void Merge_pass(ElementType A[],ElementType TmpA[],int N,int length )
{
for(i=0;i<=N-2*length;i+=2*length){
Merge1( A,TmpA,i,i+length,i+2*length-1 );//原Merge函数上减去从TmpA倒回A的步骤
}
if(i+length 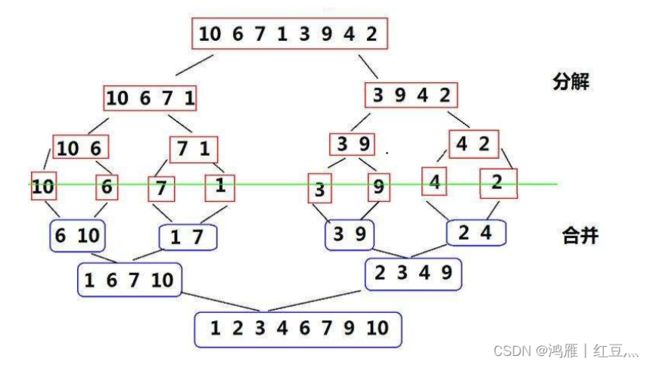
测试结果:
1.归并排序之递归算法:
归并排序 各方面都表现优异 且具有稳定性,额外空间占用可以接受
代码:
#include
#include
void Print( int A[],int N );
void Merge_Sort( int A[],int N );
void MSort( int A[],int TmpA[],int Left,int Right );
void Merge( int A[],int TmpA[],int Left,int Right,int RightEnd );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i 2.归并排序之循环算法:

归并排序的循环算法 空间够的情况下 相当不错
代码:
#include
#include
void Print( int A[],int N );
void Merge_Sort( int A[],int N );
void Merge_pass( int A[],int TmpA[],int N,int length );
void Merge1( int A[],int TmpA[],int Left,int Right,int RightEnd );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i ▶♥ 快速排序
传说中,在现实应用中最快的一种排序算法.
但总是存在最坏情况,使得它的表现非常糟糕;
不过大多数情况下,对于大规模的随机数据,快速排序还是相当出色的
前提是要把每个细节处理好!
◆算法概述:
口.核心思想 【分而治之】
在一堆整数里面选择一个作为主元(pivot) ,然后将数据分为两大块;左边的数据都比主元小,右边的都比主元大
然后递归的治理左边和右边
最后将这3块数据集合并起来,完成快速排序;
例如: 13 81 第一步选择主元: 假如选择了 65
92 43 65 第二部, 分 13 43 81
31 57 26 31 57 26 65 92 75
75 0 0
第三步, 治 0 13 26 31 53 57 65 75 81 92
第四步, 合 0 13 26 31 53 57 65 75 81 92
伪码描叙:
void Quicksort( ElementType A[],int N )
{
if(N < 2) return;
pivot = 从A[]中选一个主元;
将S = { A[] \ pivot } 分成2个独立子集;
A1 = { a∈S | a <= pivot } 和
A2 = { a∈S | a >= pivot };
A[] = Quicksort(A1,N1) ∪ { pivot } ∪ Quicksort(A2,N2);
}
算法实现的细节1:怎么选主元? 如果选的主元将集合分为其中一个元素过少,而另一个元素过多, 快速排序快不起来
比如每次都是选了最小的元素作为主元;
细节2:选好主元之后如何分? 如果分的过程太耗时,整个算法也快不起来
快速排序算法的最好情况:每次正好中分 ==> T(N)=O(NlogN)
口.如何选主元:
1.令pivot = A[0] ? 不行! 比如对基本有序的数组,这样的主元将导致左右严重失衡
1 2 3 4 5 6 ... ... N-1 N
2 3 4 5 6 ... ... N-1 N
3 4 5 6 ... ... N-1 N
...
T(N)=O(N)+T(N-1)
=O(N)+O(N-1)+T(N-2)
=O(N)+O(N-1)+O(N-2)+ ... + O(2)+O(1)
=O(N^2)
用递归的方式,实现了1个时间复杂度为O(N^2)的算法,简直是一个递归的囧!
2.随机取pivot? 但是rand()函数不便宜
3.一个经典的取主元的方法:
取头、中、尾这2个数的中位数
比如 8 12 3 的中位数 8
也有取5位数 7位数的中位数的方法
ElementType Median3( ElementType A[],int Left,int Right )
{
int Center = ( Left + Right ) / 2;
if(A[Left] > A[Center]){
Swap( &A[Left],&A[Center] );
}
if(A[Left] > A[Right]){
Swap( &A[Left],&A[Right] );
}
if(A[Center] < A[Right]){
Swap( &A[Center],&A[Right] );
} //这3步if走完 一定是A[Left] <= A[Center] <= A[Right];
Swap( &A[Center],&A[Right-1] ); //为了后续操作方便,将pivot藏在右边
/* Left位置的元素一定比主元小,Right位置的元素一定比主元大,Right-1位置上的是主元
后面分的时候只要考虑Left+1 到 Right-2 就行了*/
return A[Right-1]; //返回主元pivot
}
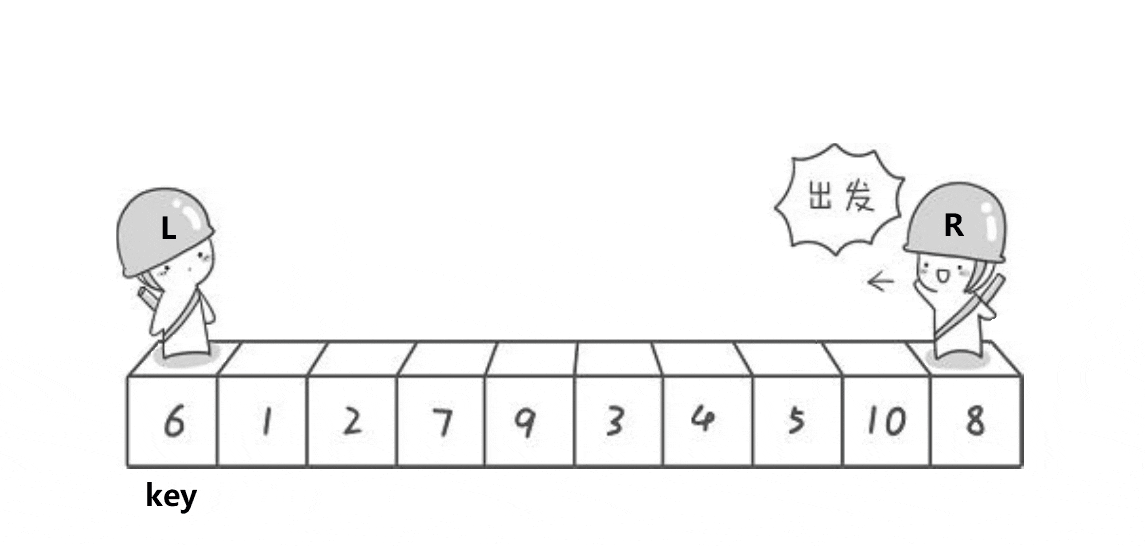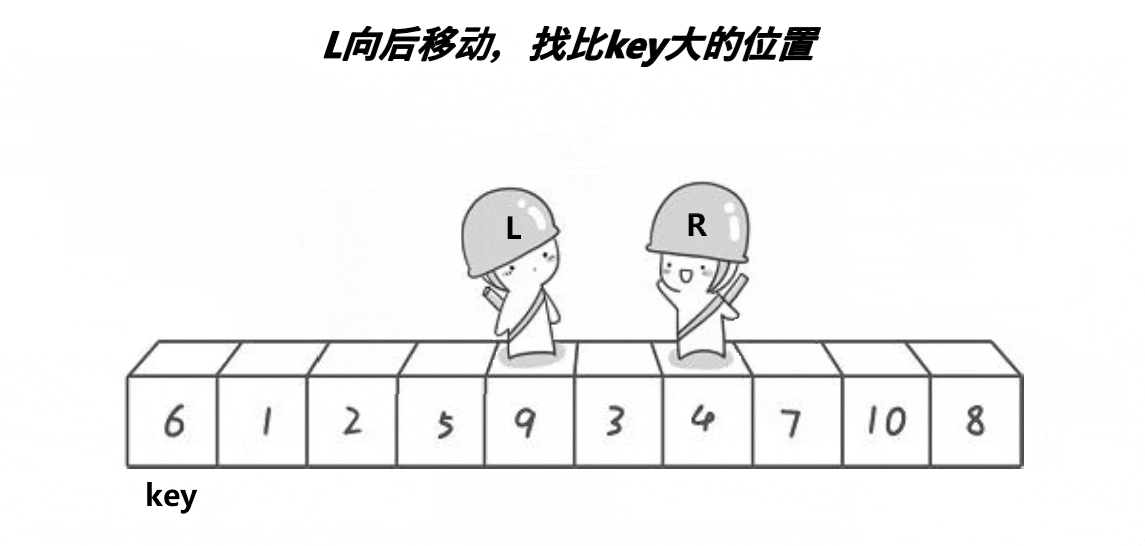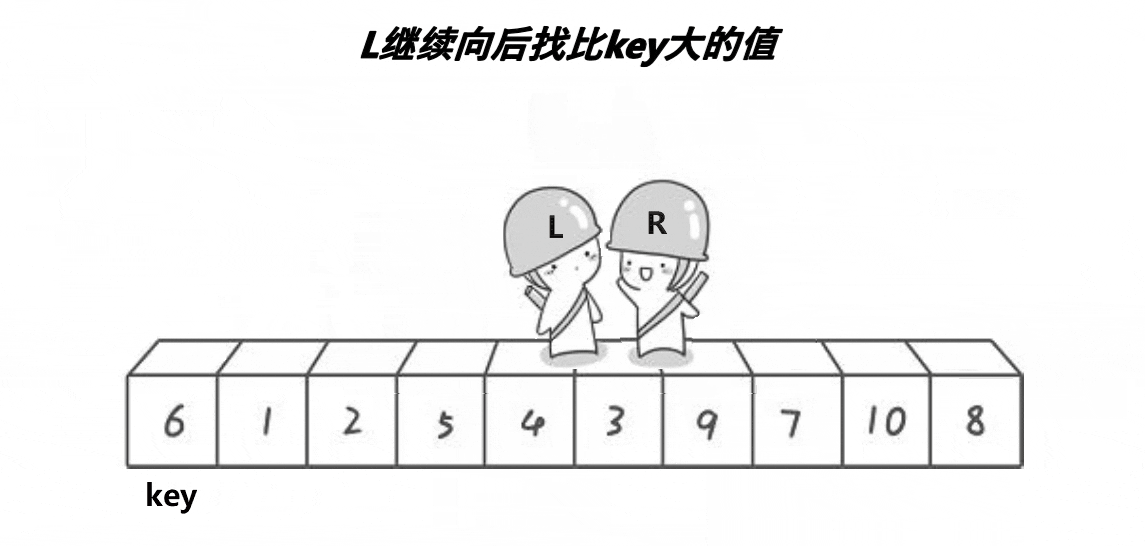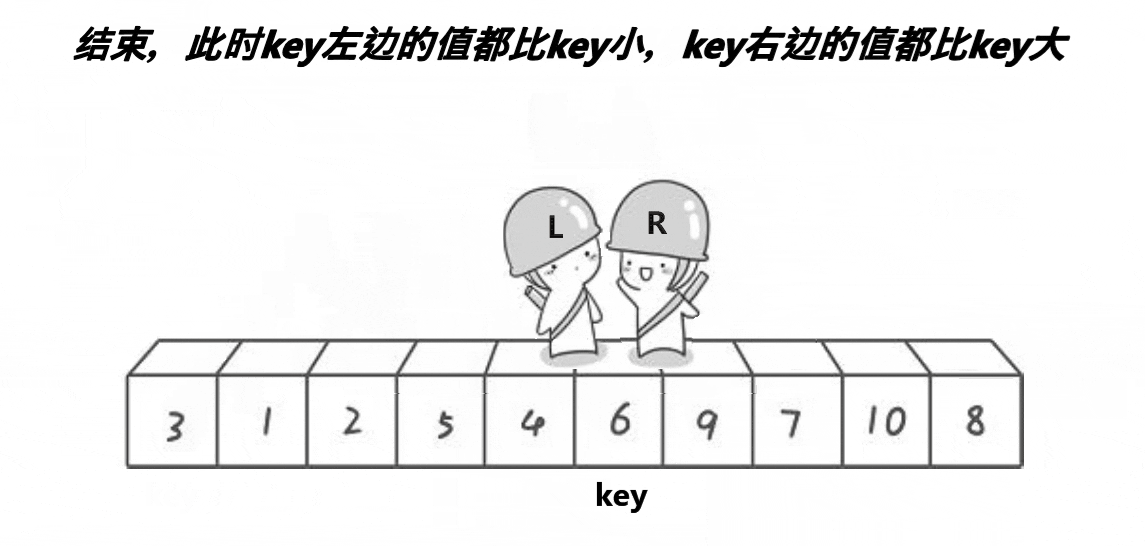
口.子集划分:
【左右指针法】
Median3取主元后 假如取了主元6,放在了Right-1的位置上
Left 8 1 4 9 0 3 5 2 7 6 Right
两个指针i,j i→ ←j pivot
先i所指的元素和主元比较 j
如果比主元小 后移一位 继续比较
如果比主元大 暂停
Left 2 1 4 9 0 3 5 8 7 6 Right
去比较j所指的元素 i→ ←j pivot
如果比主元大 前移一位 继续比较 i j
如果比主元小 暂停
Left 2 1 4 5 0 3 9 8 7 6 Right
交换i和j所指的元素 i→ j pivot
Left 2 1 4 5 0 3 9 8 7 6 Right
然后继续上面的步骤 j i pivot
当i > j时,循环跳出; Left 2 1 4 5 0 3 6 8 7 9 Right
主元换到i位置,子集划分完毕 j i
pivot
可以看出:快速排序每次选定主元,根据该主元划分子集完毕后,主元就放到了正确的位置
以后都不会再动了.
这就是快速排序之所以快的原因.
口.特殊情况分析 :
当有元素等于主元时,该如何操作?
a.不停下,不交换
缺点:可能i j停下的位置靠后,划分的两个子集元素个数差距较大
比如一个全是1 的序列 i会一直移动到最后,j没机会移动
优点:避免了很多无用的交换
b.停下来,做交换
缺点:做了很多无用的交换
优点:最后i j停下的位置上相对更好,主元换到i位置后 划分的两个子集元素个数不会差距太大
考虑到时间复杂度 还是选择b 停下来作交换吧.
口.小规模数据的处理:
考虑到快速排序时用递归的方式实现,将占用额外的系统堆栈的空间,每一次调用系统堆栈的时候
都有一大堆的Push Pop额外操作
所以当数据规模比较小时(例如N不到100),可能还不如简单的插入排序快
解决方案:
.当递归到数据规模比较小时,停止递归,直接调用简单排序(例如插入排序)
.在程序中定义一个阈值Cutoff,递归到小于这个阈值时,调用简单排序
————不同的Cutoff将对效率有不同的影响
◆算法实现:
void Quicksort( ElementType A[],int Left,int Right )
{
if(Cutoff <= Right-Left){ //元素过多,进入快排
Pivot = Median3( A,Left,Right );//选主元
i = Left; j = Right-1;
while(1){ //将序列中比主元小的移到左边,大的移到右边
while(A[++i] < Pivot);
while(A[++i] < Pivot);
if(i< j)
Swap( &A[i],&A[j] );
else
break;
}
Swap( &A[i],&A[Right-1] ); //将主元换到正确位置
Quicksort( A,Left,i-1 ); //递归解决左边
Quicksort( A,i+1,Right ); //递归解决右边
}else //元素太少,直接简单排序
Insertion_Sort( A+Left,Right-Left+1 ); //这里的A+Left 需要理解下: 想想以前学的指针 int* p;p++
}
最后统一函数接口:
void Quick_Sort( ElementType A[],int N )
{
Quicksort( A,0,N-1 );
}
最后:快速排序不具有稳定性.
/* 快速排序 - 直接调用库函数 */
#include
/*---------------简单整数排序--------------------*/
int compare(const void *a, const void *b)
{ /* 比较两整数。非降序排列 */
return (*(int*)a - *(int*)b);
}
/* 调用接口 */
qsort(A, N, sizeof(int), compare);
/*---------------简单整数排序--------------------*/
/*--------------- 一般情况下,对结构体Node中的某键值key排序 ---------------*/
struct Node {
int key1, key2;
} A[MAXN];
int compare2keys(const void *a, const void *b)
{ /* 比较两种键值:按key1非升序排列;如果key1相等,则按key2非降序排列 */
int k;
if ( ((const struct Node*)a)->key1 < ((const struct Node*)b)->key1 )
k = 1;
else if ( ((const struct Node*)a)->key1 > ((const struct Node*)b)->key1 )
k = -1;
else { /* 如果key1相等 */
if ( ((const struct Node*)a)->key2 < ((const struct Node*)b)->key2 )
k = -1;
else
k = 1;
}
return k;
}
/* 调用接口 */
qsort(A, N, sizeof(struct Node), compare2keys);
/*--------------- 一般情况下,对结构体Node中的某键值key排序 ---------------*/
. 
测试结果:

快速排序 名不虚传~!
代码:
#include
#include
#define Cutoff 500
void Swap( int* a,int* b );
void Print( int A[],int N );
void Quick_Sort( int A[],int N );
void Quicksort( int A[],int Left,int Right );
int Median3( int A[],int Left,int Right );
void Insertion_Sort( int A[],int N );
int main()
{
int N;
scanf("%d",&N);
int i,A[N];
for(i=0;i Cutoff ){
int pivot,i,j;
pivot = Median3( A,Left,Right );
i = Left;
j = Right-1;
while(1){
while(A[++i] < pivot);
while(A[--j] > pivot);
if(i < j){
Swap( &A[i],&A[j] );
}else{
break;
}
}
Swap( &A[i],&A[Right-1] );
Quicksort( A,Left,i-1 );
Quicksort( A,i+1,Right );
}else{
Insertion_Sort( A+Left,Right-Left+1 );
}
}
int Median3( int A[],int Left,int Right )
{
int Center = (Left+Right)/2;
if(A[Left] > A[Center]){
Swap( &A[Left],&A[Center] );
}
if(A[Left] > A[Right]){
Swap( &A[Left],&A[Right] );
}
if(A[Center] > A[Right]){
Swap( &A[Center],&A[Right] );
}
Swap( &A[Center],&A[Right-1] );
return A[Right-1];
}
void Insertion_Sort( int A[],int N )
{
int P,i,Tmp;
for(P=1;P=1 && A[i-1]>Tmp;i--){
A[i] = A[i-1];
}
A[i] = Tmp;
}
}
void Swap( int* a,int* b )
{
int Temp = *a;
*a = *b;
*b = Temp;
}
void Print( int A[],int N )
{
int i;
for(i=0;i ▶♥ 桶排序(进阶的计数排序)
假设某省的一次模拟考,考生为N(很大),他们的数学成绩都是在0到150之间的整数(假设不存在小数的情况),
于是只有M=151个成绩值.如何在线性时间内将学生按数学成绩排序呢?
当数据具有这种量很大,但是值的可能性比较少的特性时,我们就可以用桶排序(计数排序),在线性时间内完成排序
算法概述:
.为每一种可能的值建一个桶(计数数组)
.遍历整个数据,根据元素的值,将元素放入对应的桶(计数数组)中
.遍历每个桶,输出桶中的元素,结果就是已经排好序了的
建M个桶(计数数组)(链表) 0 1 2 3 4 ... ... 149 150
将元素放入对应的桶中 count 口 口 口 口 口 口 口
↓ ↓ ↓ ↓ ↓ ↓ ↓
● 口 口 口 口 口 口
↓ ↓ ↓ ↓ ↓ ↓
● 口 ● 口 口 口
↓ ↓ ↓ ↓
● ● 口 ●
↓
●
void Bucket_Sort( ElementType A[],int N )
{
count[]初始化;
while(读入每个学生的数学成绩)
将该生插入count[grade]链表;
for(i=0;i简单计数排序图示:
桶排序图示:
仔细观察 数据8:10^5个随机正整数,每个数字不超过1000。
N=10^5个数据 只有取值M=1000种可能,M< 符合桶排序的特征,所以可以用桶排序(这里只需用简单的计数排序)来高效排序 测试结果: 比前面任何一种排序都要快好多~! 代码: 数据8 由于给出了数据是最大999的正整数 即最大是3位数,那么可以通过LSD的基数排序(3趟桶排序)来完成;但是由于不符合M>>N ,可以预计效率不高 测试结果: 符合预期~! f代码:
#include 以上是取值之范围远小于数据个数 M<
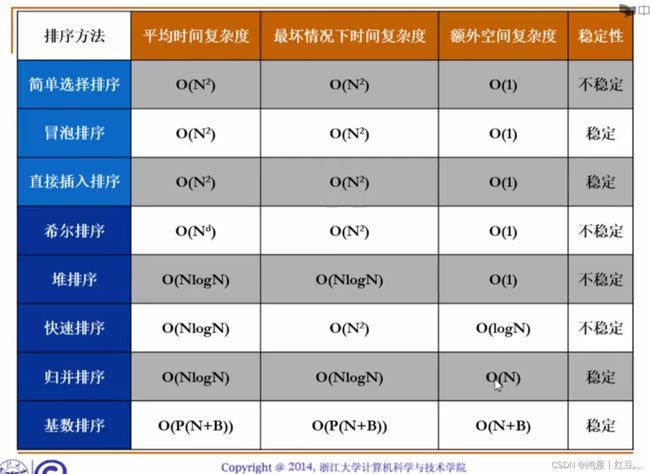
#include ▶♥ 总结:排序算法的比较
排序方法 平均时间复杂度 最坏情况下时间复杂度 额外空间复杂度 稳定性
简单选择排序 O(N^2) O(N^2) O(1) 不稳定(交换之前先做一次比较,就是稳定)
冒泡排序 O(N^2) O(N^2) O(1) 稳定
直接插入排序 O(N^2) O(N^2) O(1) 稳定
以上三种统称简单排序,程序简单好写
希尔排序 O(N^d)(d<=2) O(N^2) O(1) 不稳定
堆排序 O(NlogN) O(NlogN) O(1) 不稳定
快速排序 O(NlogN) O(N^2) O(logN) 不稳定
归并排序 O(NlogN) O(NlogN) O(N) 稳定
基数排序 O(P(N+B)) O(P(N+B)) O(N+B) 稳定