LLM与数据分析
写在前面
本文主要以LLM的应用为基础,说明LLM与数据开发、数据分析领域的相关工作以及未来可能存在的发展。
1.基于向量数据库的prompt工程
问题背景
大模型能够回答较为普世的问题,但是若要服务于垂直领域,会存在知识深度和时效性不足的问题,那么企业如何抓住机会并构建垂直领域服务?

目前有两种模式,第一种是基于大模型之上做垂直领域模型的Fine Tune,这个综合投入成本较大,更新的频率也较低,并不适用于所有的企业;第二种就是在向量数据库中构建企业自有的知识资产,通过大模型+向量数据库来搭建垂直领域的深度服务,本质是使用数据库进行提示工程(Prompt Engineering)。
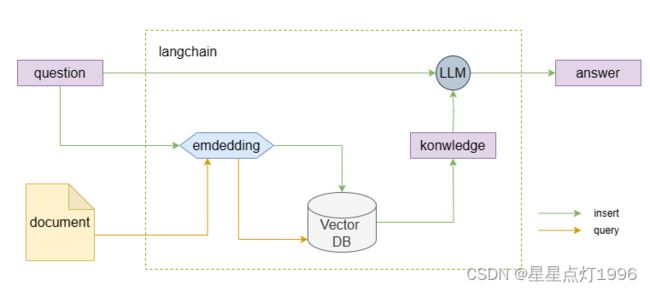
上图显示了使用向量数据库搭建问答系统的基本框架。
1、用户的question通过embedding后通过词向量数据库查询与之相关的信息,产生konwledge。
2、用户的question和产生的konwledge一起喂给LLM,然后产生answer。
知识库的构成则由document转为向量,然后存储在向量数据库中。
向量数据库概述
- 搜索
在传统数据库,搜索功能都是基于不同的索引方式(B Tree、倒排索引等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
例如,如果你搜索“小狗”,那么你只能得到带有“小狗”关键字相关的结果,而无法得到“柯基”、“金毛”等结果,因为“小狗”和“金毛”是不同的词,传统数据库无法识别它们的语义关系,所以传统的应用需要人为的将“小狗”和“金毛”等词之间打上特征标签进行关联,这样才能实现语义搜索,因此,向量数据库的核心在于相似性搜索(Similarity Search)。
高效的搜索算法有很多,其主要思想是通过两种方式提高搜索效率:
1、减少向量大小——通过降维或减少表示向量值的长度。
2、缩小搜索范围——可以通过聚类或将向量组织成基于树形、图形结构来实现,并限制搜索范围仅在最接近的簇中进行,或者通过最相似的分支进行过滤。
参考链接:向量数据库技术鉴赏
- 索引
在实际的业务场景中,往往不需要在整个向量数据库中进行相似性搜索,而是通过部分的业务字段进行过滤再进行查询。所以存储在数据库的向量往往还需要包含元数据,例如用户 ID、文档 ID 等信息。这样就可以在搜索的时候,根据元数据来过滤搜索结果,从而得到最终的结果。
为此,向量数据库通常维护两个索引:一个是向量索引,另一个是元数据索引。然后,在进行相似性搜索本身之前或之后执行元数据过滤,但无论哪种情况下,都存在导致查询过程变慢的困难。
过滤过程可以在向量搜索本身之前或之后执行,但每种方法都有自己的挑战,可能会影响查询性能:
- Pre-filtering:在向量搜索之前进行元数据过滤。虽然这可以帮助减少搜索空间,但也可能导致系统忽略与元数据筛选标准不匹配的相关结果。
- Post-filtering:在向量搜索完成后进行元数据过滤。这可以确保考虑所有相关结果,在搜索完成后将不相关的结果进行筛选。
为了优化过滤流程,向量数据库使用各种技术,例如利用先进的索引方法来处理元数据或使用并行处理来加速过滤任务。平衡搜索性能和筛选精度之间的权衡对于提供高效且相关的向量数据库查询结果至关重要。
- 现有向量数据库调研
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 7.4K | Python | ❌ |
| milvus | https://github.com/milvus-io/milvus | 21.5K | Go/Python/C++ | ✅ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ | ✅ |
| qdrant | https://github.com/qdrant/qdrant | 11.8K | Rust | ✅ |
| typesense | https://github.com/qdrant/qdrant | 12.9K | C++ | ❌ |
| weaviate | https://github.com/weaviate/weaviate | 6.9K | Go | ✅ |
- 传统数据库的扩展
除了选择专业的向量数据库,使用传统数据库进行扩展也是一种方法。类似 Redis 除了传统的 Key Value 数据库用途外,Redis 还提供了 Redis Modules,这是一种通过新功能、命令和数据类型扩展 Redis 的方式。例如使用 RediSearch 模块来扩展向量搜索的功能。
同理的还有 PostgreSQL 的扩展,PostgreSQL 提供使用 extension 的方式来扩展数据库的功能,例如 pgvector 来开启向量搜索的功能。它不仅支持精确和相似性搜索,还支持余弦相似度等相似性测量算法。最重要的是,它是附加在 PostgreSQL 上的,因此可以利用 PostgreSQL 的所有功能,例如 ACID 事务、并发控制、备份和恢复等。还拥有所有的 PostgreSQL 客户端库,因此可以使用任何语言的 PostgreSQL 客户端来访问它。可以减少开发者的学习成本和服务的维护成本。
milvus介绍
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
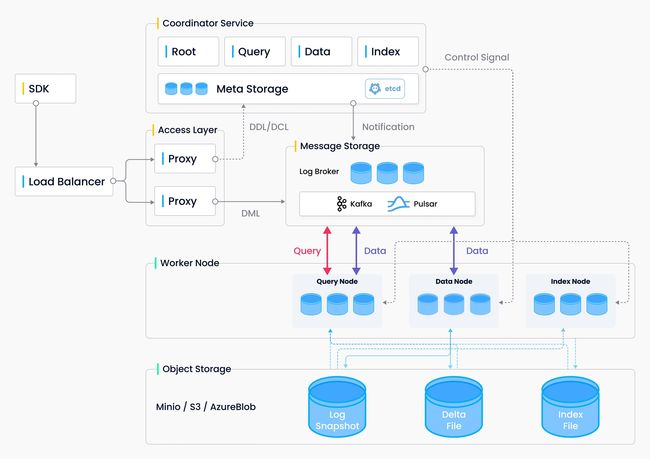
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
- 接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
- 协调服务(Coordinator Service):系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
| 角色名称 | 作用 |
|---|---|
| root coord | 负责处理数据定义语言(DDL)和数据控制语言(DCL)请求。比如,创建或删除 collection、partition、index 等,同时负责维护中心授时服务 TSO 和时间窗口的推进 |
| query coord | 负责管理 query node 的拓扑结构和负载均衡以及从增长的 segment 移交切换到密封的 segment |
| data coord | 负责管理 data node 的拓扑结构,维护数据的元信息以及触发 flush、compact 等后台数据操作 |
| index coord | 负责管理 index node 的拓扑结构,构建索引和维护索引元信息 |
- 执行节点(Worker Node):系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
| 角色名称 | 作用 |
|---|---|
| Query node | 通过订阅消息存储(log broker)获取增量日志数据并转化为 growing segment,基于对象存储加载历史数据,提供标量 + 向量的混合查询和搜索功能。 |
| Data node | 通过订阅消息存储获取增量日志数据,处理更改请求,并将日志数据打包存储在对象存储上实现日志快照持久化 |
| Index node | 负责执行索引构建任务。Index node 不需要常驻于内存,可以通过 serverless 的模式实现 |
- 存储服务 (Object Storage): 系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
| 角色名称 | 作用 |
|---|---|
| meta store | 负责存储元信息的快照,比如:集合 schema 信息、节点状态信息、消息消费的 checkpoint 等。元信息存储需要极高的可用性、强一致和事务支持,因此,etcd 是这个场景下的不二选择。除此之外,etcd 还承担了服务注册和健康检查的职责。 |
| log broker | 负责存储日志的快照文件、标量 / 向量索引文件以及查询的中间处理结果。Milvus 采用 MinIO 作为对象存储,另外也支持部署于 AWS S3 和 Azure Blob 这两大最广泛使用的低成本存储。但是,由于对象存储访问延迟较高,且需要按照查询计费,因此 Milvus 未来计划支持基于内存或 SSD 的缓存池,通过冷热分离的方式提升性能以降低成本。 |
| object storage | 负责存储日志的快照文件、标量 / 向量索引文件以及查询的中间处理结果。Milvus 采用 MinIO 作为对象存储,另外也支持部署于 AWS S3 和 Azure Blob 这两大最广泛使用的低成本存储。但是,由于对象存储访问延迟较高,且需要按照查询计费,因此 Milvus 未来计划支持基于内存或 SSD 的缓存池,通过冷热分离的方式提升性能以降低成本。 |
实践案例
现阶段存在诸多的向量数据库结合LLM进行使用,有点百家曾鸣的意思,本节以阿里云的AnalyticDB PostgreSQL作为实践案例进行说明。ChatBot模型的整体架构框架如下:
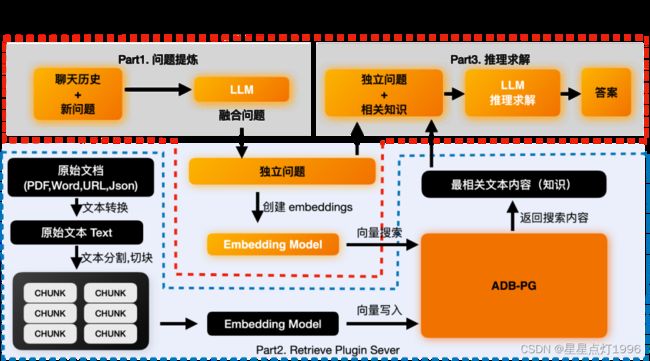
整个过程主要有两个流程:前端问答流程+后端数据处理和存储流程。底层主要依赖两个模块:基于大语言模型的推理模块+基于向量数据库的向量数据管理模块。
前端问答流程
- Part1. 问题提炼:
这个部分是可选的,之所以存在是因为有些问题是需要依赖于上下文的。因为用户问的新问题可能没办法让LLM理解这个用户的意图。比如用户的新问题是"它能做什么"。LLM并不知道它指的是谁,需要结合之前的聊天历史。LLM没法正确回答"它有什么用"这样的模糊问题,但是能正确回答"Doris有什么用"这样的独立问题。如果你的问题本身就是独立的,则不需要这个部分。得到独立问题后,我们可以基于这个独立问题,来求取这个独立问题的embedding。然后去向量数据库中搜索最相似的向量,找到最相关的内容。这个行为在Part2 Retrieval Plugin的功能中。 - Part2. 向量检索:
独立问题求取embedding这个功能会在text2vec模型中进行。在获得embedding之后就可以通过这个embedding来搜索已经事先存储在向量数据库中的数据了。比如我们已经在ADB-PG中存储了下面内容。我们就可以通过求取的向量来获得最相近的内容或者知识,比如第一条和第三条。
| id | Content | embedding | document |
|---|---|---|---|
| 1 | Doris是… | [0.1, -0.1,0,1] | OLAP数据库Doris |
| 2 | NBA比分 湖人-篮网 | [0.2,0.1,0.2,-1] | NBA今日播报 |
| 3 | Doris可以帮助我们XXX | [0.2,0.1,0.2,-1] | OLAP数据库Doris |
| 4 | AIGC是xxx | [0.2,0.1,0.2,-1] | AIGC介绍 |
- Part3. 推理求解
在获得最相关的知识之后,我们就可以就可以让LLM基于最相关的知识和独立问题来进行求解推理,得到最终的答案了。这里就是结合“Doris是…”,“Doris可以帮助我们xxx”等等最有效的信息来回答“Doris有什么用”这个问题了。最终让GPT的推理求解大致是这样:
基于以下已知信息,简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说"根据已知信息无法回答该问题"或"没有提供足够的相关信息",不允许在答案中添加
编造成分,答案请使用中文。
已知内容:
1.Apache Doris产生与PALO...
2.Doris可以帮助我们xxx
问题:
Doris有什么用
后端数据处理和存储流程
- Step1:先将原始文档中的文本内容全部提取出来。然后根据语义切块,切成多个chunk,可以理解为可以完整表达一段意思的文本段落。在这个过程中还可以额外做一些元数据抽取,敏感信息检测等行为。
- Step2:将这些Chunk都丢给embedding模型,来求取这些chunk的embedding。
- Step3:将embedding和原始chunk一起存入到向量数据库中。
ADB-PG建表举例说明
假设有一个文本知识库,它是将一批文章分割成chunk再转换为embedding向量后入库的,其中chunks表包含以下字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | serial | 编号 |
| chunk | varchar(1024) | 文章切块后的文本chunk |
| intime | timestamp | 文章的入库时间 |
| url | varchar(1024) | 文本chunk所属文章的链接 |
| feature | real[] | 文本chunk embedding向量 |
2.LLM应用于探索性数据分析
本节主要对微软在探索式数据分析(Exploratory Data Analysis,EDA)领域的研究工作进行汇总。该项研究相关成功以及发表在SIGMOD等全球顶会上,起对应的工作也已经应用于Microsoft Excel、Microsoft Power BI和Microsoft Forms等微软产品中。
探索性数据分析(EDA)与传统统计分析(Classical Analysis)的区别
- 传统的统计分析通常是先假设样本服从某种分布,然后把数据套入假设模型再做分析。
- 探索性数据分析方法重视数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。
QuickInsights
论文链接:https://dl.acm.org/doi/10.1145/3299869.3314037
数据洞察(Data insight):“insight” 是指从多维数据中发现的 interesting data pattern(有趣的数据模式),它反映了数据在某种特定视角下的有趣特征。
insight建模
数据模型:给定多维数据集 R ( D , M ) \R(\mathcal{D},\mathcal{M}) R(D,M),其中 D = { D 1 , … , D d } \mathcal{D}=\{D_1,…,D_d\} D={D1,…,Dd} 表示维度的集合, M \mathcal{M} M 表示度量的集合。那么, d o m ( D i ) dom(D_i) dom(Di) 表示 D i D_i Di 的空间,例如如果 D i = D_i= Di= 性别,那么 d o m ( D i ) = { 男、女 } dom(D_i)=\{男、女\} dom(Di)={男、女}
insight的定义:ℎ ≔ {(), , (),, }
- insight subject
≔ {(), , ()}
子空间(subspace):过滤条件的集合,相当于where语句
分解(breakdown):可以理解为自变量x,相当于在哪些维度上进行group by
度量(measure):可以理解为因变量y,相当于通过sum()、count()等计算的指标
一个例子:
分别用{{*}, ServerName, CPU Usage}和{{China}, Year, Sales}表达下面两个subject。
- insight types
PowerBI 现在一共支持 12 种不同类型的洞察分析,这些分析可以分为 3 大类:
SinglePointInsight:占比类分析。例如,手机销量,国外(subspace (country != China))手机销量(measure)的breakdown (by country),这样的insight里,那些top1/top2/No. Last 都有一定的价值。
SingleShapeInsight:时序类分析,与”占比类分析“的唯一区别,使用有序维度进行指标的分解。例如:某个上市公司的净利润持续变化情况通过trend指标表示,对于投资者来说这种Insight有非常高的含金量
CompundInsight:多度量相关性分析,对多个子空间、多个指标的洞察。例如:Correlation代表了2个Subspace在同一个Measure上有正向或者负向的关联关系,可以表征广告增收情况和新的广告投放模型是否正相关。
- insight scores
= () ∙ ()
重要性(impact):反映了洞察主题对整个数据集的重要程度。下图展示了当影响度量(impact-measure)是市场份额时,两个不同市场的销售趋势。依据反单调性条件,市场份额越高,越重要。
 显著性(significance):用于评估洞察主题(insight subject)的聚合值(aggregation values),它被用于反应我们得到的洞察事实(即获得的聚合值)与随机的基线(baseline)相比的重要程度。下图展示了两个时间序列,左边的比右边的更显著,因为它包含一定的规律性而不是纯噪声。
显著性(significance):用于评估洞察主题(insight subject)的聚合值(aggregation values),它被用于反应我们得到的洞察事实(即获得的聚合值)与随机的基线(baseline)相比的重要程度。下图展示了两个时间序列,左边的比右边的更显著,因为它包含一定的规律性而不是纯噪声。

系统架构
下图描述了 QuickInsights 的整体工作流程。整个工作流程可分为 3 个阶段:
-
搜索 & 任务生成(Search & Task Generation)
主题搜索模块会尝试枚举所有可能的子空间。每个子空间会通过 AutoImpact 模块计算并被赋予重要性度量 impact。然后,通过通过函数依赖性检查器(Functional-Dependency checker)的分解维度(breakdowns)会与子空间结合,生成洞察评估任务。生成的任务被存储在优先级队列中,重要性度量 impact 数值越高,优先级越高。每个task是按照参数计算所有的聚合指标,例如:
“SELECT Aggr1(measure1), Aggr2(measure2), … GROUP BY breakdownDimension where filter = subspace”. -
查询 & 评估(Query & Evaluation)
任务的计算分为 3 步。1、 队列中优先级最高的任务会被工作线程取出;2、执行数据查询,并根据任务参数对所有度量进行聚合;3、发现洞察后,进行洞察评估。 -
存储 & 细化(Store & Refinement)
提高insight质量
通过检测和消除函数依赖(Functional Dependency 简称 FD)产生的 EII(Easily Inferable Insights 容易推断的洞察)来提高洞察质量。下图说明了5种可能导致Ell的FD。
以ID2为例举例:“高度类别”(Height-Category)是通过度量高度(height)来计算的
- l o w : h e i g h t ≤ 100 low: height \le 100 low:height≤100
- m e d i d u m : 100 < h e i g h t < 1000 medidum: 100
- h i g h : h e i g h t ≥ 1000 high: height\ge1000 high:height≥1000
任意以高度类型作为分解维度,描述高度的洞察都是无效的。以 Outstanding No.1 洞察为例:“类型为 high 的高度在整体的类型中处于领先地位”,这个结论无论洞察的子空间是什么,都是预先确定(pre-determined)的。

MetaInsight
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2021/03/metainsight-extended.pdf
在 QuickInsight 的框架下,数据洞察被表征为 三元组。实际分析场景中,研究员们发现这样的洞察主要适用于服务基础的分析任务。MetaInsight 是在基本数据洞察的基础上,利用多个insight subject 内部的同质关系,形成更高层面的数据洞察,从而可更有效地推动探索性数据分析。
MetaInsight模型
MetaIngInsight定义:MetaInsightHDP:=
MetaInsight 把 HDP (同质数据模式 Homogeneous Data Pattern)分类为 CommSet 和异常特征 Exc,从而提供了一个结构化的知识表现形式。MetaInsight 是 EDA 中经典的假设、验证过程的具象化表示,每个 commonness 表示了一个通用知识,exceptions 被用于让用户聚焦于非同寻常的案例,并了解它与通用知识的差异。
实例分析
假设有一个数据集,假设存储的表名叫 sale_table 示例如下:
下图显示了一个典型的EDA迭代。
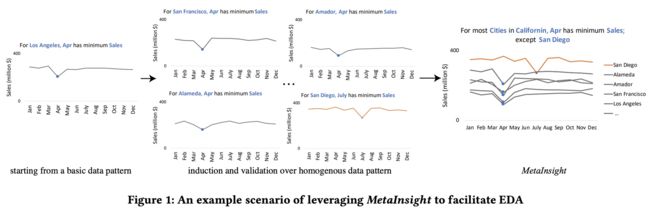
- starting from a basic data pattern
数据分析师执行如下SQL:
SELECT SUM(sales) FROM sale_table WHERE city='Los Angeles' GROUP BY month - induction and validation over homogenous data pattern
然后提出一个假设:其他城市是不是也有同样的销售额降低的情况,
改变 filter:
SELECT SUM(sales) FROM sale_table WHERE city='Amador' GROUP BY TO_MONTH(order_date) - MetaInsight
是不是有异常性案例,所以他进行一次验证性查询“是否所有城市都在4月份销售额掉底,是否有异常案例?”
经过分析,圣地亚哥在 7 月份销售额掉底(异常案例)
注:什么是同质案例?如何获取同质案例?
一个具有显著性的案例,是从一个数据域(< filter,group by 字段,度量> 三元组)中探测出来的。那么,将这个三元组任意变更一个元素,就得到了这个数据域的衍生数据域。以上面例子来说,原始的查询是:SELECT SUM(sales) FROM sale_table WHERE city='Los Angeles' GROUP BY month
- 改变 filter:例如
SELECT SUM(sales) FROM sale_table WHERE city='Amador' GROUP BY TO_MONTH(order_date)。 - 改变 group by 字段:例如
SELECT SUM(sales) FROM sale_table WHERE city='北京' GROUP BY TO_WEEK(month)。类比 EDA 场景中,观察到洛杉矶交易额月趋势有单峰性异常,继续观察周趋势的数据分布情况。文章中限定了一个约束,扩展的 group by 字段必须是时间类型。但是推广一下,扩展的 group by 字段可以是和原有字段具有函数依赖的字段。例如,原来的字段是"city",那么就可以将group by 字段扩展为 “province”。 - 改变度量:例如
SELECT SUM(profit) FROM sale_table WHERE city='Los Angeles' GROUP BY month。类比 EDA 中,得到交易额的月分布后,继续探索利润及其他度量的分布情况。
工作流
为了高效且交互式的 EDA,MetaInsight 挖掘过程是递进式的,在预先定义的时间窗口内,返回当前最好的结果。将挖掘过程解构成搜索 search、查询 query、评估 evaluation 3 个功能。所有合格的 MetaInsight 候选都会被存储,然后被后续的任务(例如模式索引,排序或多样化)处理。
下图是MetaInsight的工作流程。数据模式挖掘模块以多维数据作为入参,挖掘数据集中的数据模式。找到数据模式后,相关的数据域就会被扩展成几个 HDS,然后 MetaInsight 挖掘模块以此为入参,找到 MetaInsight 后将其保存下来并在时间窗到期时将其发送到排名模块。搜索功能探查所有(同质)数据域,输出对应的计算单元,并计算这些计算单元的优先级。查询功能在每个计算单元中进行,它的职责是从原始数据中查询、具体特定的(同质)数据域。评估功能执行数据模式评估及 MetaInsight 评估,用以决定数据模式及 MetaInsights 是否存在。
XInsight
论文链接:https://arxiv.org/abs/2207.12718
在数据分析场景中,可解释性是固有的一个需求。人们对各种数据中的现象进行观察,总结出适用概念,提出假设性的机制来解释观测,再提供预测,等等。这些分析过程中可解释性是普遍存在的。
一个典型的场景是对异常数据进行解释。对异常的解释不仅在 MetaInsight 的使用中较为常见,而且更广泛地存在于日常数据分析的场景中。例如在销量数据中,用户希望探知某一年销量下降的原因;在游客数据中,用户希望解析出不同地域之间游客的差异。
Xinsight模型
explanation的定义:explanation := ⟨type, predicate, responsibility⟩
- type ∈{causal,non-causal}:表示因果和非因果两种类型
- predicate(谓词):解释的内容
- responsibility∈(0,1):对why query进行量化
案例分析
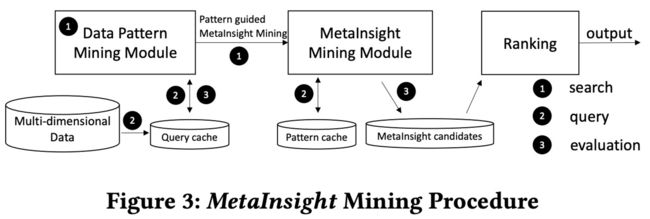
下图显示了XDA的一个应用场景。通过基础的数据洞察,发现A和B地区肺癌存严重程度不一样,提出问题:吸烟为患者为什么患有不同严重程度的肺癌?这是典型的因果问题。
XInsight 首先利用因果发现(causal discovery)定性地寻找数据内部变量之间的因果关系。基于定性的因果关系,XInsight 提出了 XTranslator,将因果图(causal graph)上的因果语义转化为可解释数据分析(Explainable Data Analysis,XDA)的语义。根据 XDA 层面的语义信息,XInsight 再进一步利用实际因果性(actual causality)框架定量地分析每个变量内部不同取值对数据差异的影响,最终获得解释。
通过 XInsight 可以得出一个因果关系的解释,即“吸烟”是肺癌严重程度的定性因素,并且强调“吸烟=是”(Smoking=Yes)及其作为定量解释的责任(responsibility)。用户能够据此更深入地理解不同区域患者肺癌严重程度之间的差异,并针对吸烟这一因素提出相应的干预措施,如制定更严格的烟草控制政策、推广禁烟宣传等,以达到更好的防控效果。
工作流
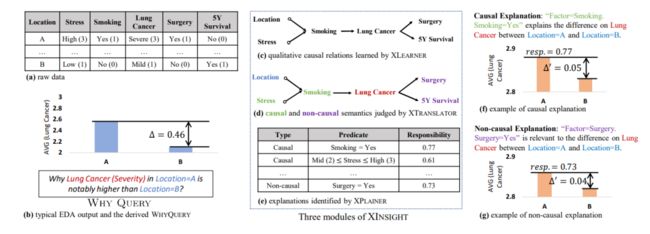
XInsight通过Xleaner、Xtranslator、Xplainer三个模块为可解释的数据分析提供了一个统一的框架。XInsight的工作流程如下图所示。
- 首先Xleaner预先学习来自收集到数据的因果图。
- 在收到用户的WhyQuery后,Xtranslator根据因果图上的因果单元别有可能给出的因果或者非应该变量
- 最后,XPlainer检查每个具有潜力的已识别变量,并决定给定Why Query的最佳解释。

InsightPilot
Demonstration of InsightPilot: An LLM-Empowered Automated Data Exploration System
论文链接:https://arxiv.org/abs/2304.00477
MetaInsight 和 XInsight 所展现出的自动化数据探索工具的巨大潜力,都是基于某个特定的数据洞察,从而触发了数据分析意图(data analysis intent),它们的输出是数据分析意图在数据中的一种体现。但是,从另一个角度来看,这表示现有的解决方案的智能程度仍存在不足,MetaInsight 和 XInsight 还需要依赖人类数据分析师来找到特定的触发条件,并且在多数情况下,单一的数据洞察往往不能满足用户的真实需求。
案例分析
传统方式:
- 以一位教育分析师 Alice 为例。她正在通过探索式数据分析,试图了解学生数学成绩的总体趋势。Alice 花费了数十分钟手动筛选和排序数据,并绘制了数学成绩随时间的变化图,发现数学成绩整体上升。
- 接下来,她希望比较不同学校学生的表现,所以她又花费了更多的时间手动筛选数据,对比了 A、B、C 三所学校的学生数学成绩。她发现 A、B 两校的数学成绩呈现上升趋势,而 C 校在2020年出现了一个异常值。
- Alice 好奇地决定深入研究这个异常值。她花费了大量时间来回探索数据,通过各种变量进行筛选和分组,最终发现当排除 “Take-home” 考试时,C 校2020年的异常值便不再存在。于是,她记录下这一发现,并得出结论:这个异常值是由于 C 校在2020年改变考试形式所导致的。

为了实现更为自动化的数据探索,InsightPilot 将数据探索的过程抽象为由 context-intent-analysis 组成的序列,即利用大语言模型(LLM)理解已有的数据洞察(context)、提出一个合理的数据分析意图(intent),并由 Insight Engine 将意图转化为具体的数据分析(analysis)。通过利用数据分析的结果对数据洞察进行更新,让 LLM 推荐新的数据分析意图,从而迭代形成若干个由 context-intent-analysis 三元组完成的序列,从而使 InsightPilot 完成整个数据探索的过程。
下图显示了Alice使用InsightPilot应用于Alice的场景。
- 首先,用户通过用户界面用自然语言提出一个问题:“请展示学生数学成绩中值得挖掘的趋势。”
- Insight Engine 会根据用户的问题从数据中生成初始洞察,并以自然语言的形式呈现给 LLM。例如,一个根据用户问题生成的洞察可能是:“学校 A 的平均成绩排名第一。”针对用户的问题,LLM 从初始洞察中选择与用户问题最相关的洞察,因此选择了“学生的数学成绩随着时间的推移呈上升趋势。”
- 接下来,当 LLM 选择了一个相关洞察后,Insight Engine 会对这个洞察进行分析,并向 LLM 提供可行的分析意图选项。在这个示例中,LLM 在“理解”和“归纳”两种意图中最终选择了“归纳”。
- 然后,在收到选定的分析意图后,Insight Engine 将执行相应的查询语句并用一组新的洞察来回应分析意图。为了总结所选的洞察,Insight Engine 会尝试按照不同学校和考试形式来总结数学成绩的趋势。它发现:“除了学校 C,大多数学校的学生数学成绩随着时间的推移呈上升趋势。学校 C 在2020年出现了一个异常值。”
- 为了进一步探索数据,LLM 将再次选择洞察和分析意图与Insight Engine交互。此时,LLM要求 Insight Engine “解释学校 C 在2020年的异常值。”

Intentional Query
每次LLM选择洞察和分析意图时,Insight Engine都会启动相应的IQuery来实例化分析意图。InsightPilot一共产生三种类型的IQuery:understand、summarize、explain,分别对应QuickInsight、MeatInsight、XInsight。
| 类型 | 方式 | 用户给定的Insight | 实例化分析Insight |
|---|---|---|---|
| understand | 基于所选Insight从输入数据集中提取上下文子集 | 数学成绩的增长趋势 | 上下文子集将构成“主题=数学”的行 |
| summarize | 可以触发对所选见解的两种总结(数学科目、学校) | 数学成绩的增长趋势 | 1、对于大多数学校,学生的数学成绩随着时间的推移一直在增加,除了C学校 2、对于大多数科目,学生的分数随着时间的推移一直在增加 |
| explain | 用于解释洞察中的意外结果 | C学校2020年数学成绩的异常值 | 2019年和2020年C学校学生数学成绩的差异是由考试表=带回家引起的。当排除考试表=拿回家时,2020年不再是一个例外。 |
Prompt 工程
为了将LLM顺利集成到InsightPilot中,需要为LLM提供一组包含指令和上下文的提示。根据InsightPilot的不同阶段,InsightPilot开发了四个提示模板,即Initialization、 Analysis intent selection、Insight selection以及Report generation。
- Initialization,用于通过InsightPilot的一些常规指令、对数据集的描述、用户查询和初始见解来初始化LLM。用户查询由用户提供,最初的见解来自于在整个数据集上运行QuickInsight,然后,提示要求LLM从QuickInsight的输出中选择一个洞察作为确定IQuery的起点。
- Analysis intent selection,用于推荐分析意图,该分析意图有助于用LLM选择的洞察力回答用户询问。有了这个提示,LLM将被要求选择其中一个意图,以进一步与洞察引擎交互,并使用相应的IQuery探索数据。
- Insight selection,用于选择洞察。如果LLM对结果不满意,它将从输出中选择一个洞察,并开始新的迭代以进一步探索数据。
- Report generation,用于生成描述数据探索过程的报告。从技术上讲,我们记录LLM和洞察引擎之间的交互,并存储所有洞察,然后,我们对见解进行排名,并选择排名靠前的topn 提示中的见解,此外,然后,LLM将被要求以连贯和有意义的方式生成一份报告,以回答用户的询问。
Insight 排序
由于LLM的容量有限,不可能将所有见解提供给LLM,为了处理这些压倒性的见解,我们采用了三种混合策略来排名和提取顶部topN见解。
- Insight Redundancy-based Elimination,基于冗余的消除。如果生成以下三个洞察:“学校=A的数学成绩最高”、“学校=A的2022年成绩最高”和“学校=B的2022年数学成绩最高“,自动删除第三个洞察。
- Semantic Similarity-based Elimination,基于语义相似性的消除。为了实现这一点,InsightPilot使用了一个嵌入模型,该模型可以将文本输入(如洞察描述和用户查询)转换为高维空间中的向量表示,计算每个洞察的向量表示与用户查询的向量表示之间的余弦相似性,选择最相似的topN。
- Insight Diversity-based Ranking,基于多样性的排名。在应用上述两种策略后,试图根据它们的多样性对它们进行排名,以提供更全面的报告。
3.大模型驱动的自主代理
博客链接:https://lilianweng.github.io/posts/2023-06-23-agent/
随着chatgpt提供的plugin和function call功能出现,激发了大家对LLM作为智能中枢架构的思考。microsoft、google基于LLM发布的copilot架构的应用程序之前陆续推出时,也是引发大家思考LLM是如何与外部复杂的系统交互的。之前在github上,有一些project实现了类似的能力,有开发脚手架的比如langchain agent,也有AutoGPT、BabyAGI这种已经有一定封装的工具。但缺乏一篇能站在更高视角,比如用人类的记忆、人类使用工具的类比映射到人工智能,去讲这套架构以及这套架构在应用层面有哪些想象空间的文章。
Agent 系统总览
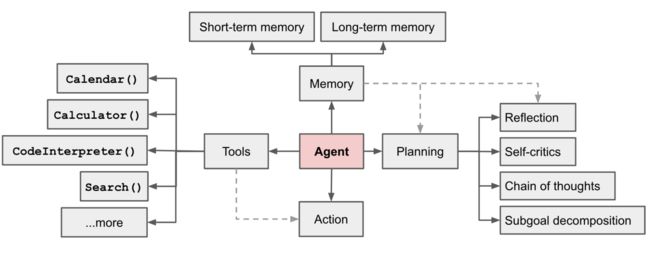
在基于LLM的自动agent体系里, LLM就是作为agent的大脑,其他几个能力作为补充:
- 规划能力
子目标与拆解: Agent大脑把大的任务拆解为更小的,可管理的子任务,这对有效的、可控的处理好大的复杂的任务效果很好。
反省和改良: Agent能基于过去的动作做自我批评和自我反省,从过去的问题中学习从而改良未来的动作,从而能够改善最终的结果。 - 记忆
短期记忆: 我会把所有基于context的学习能力 (详细请看 Prompt Engineering) ,其实就是prompt内的学习能力作为短期记忆。
长期记忆: Agent能够保留和无限召回的历史信息能力,这通常通过外部的向量数据库和快速取数能力组合实现。 - 工具使用
Agent能学习到在模型内部知识不够时(比如在pre-train时不存在,且之后没法改变的模型weights)去调用外部API,比如获取实时的信息,处理代码的能力,访问专有的信息知识库等等。
组件一:规划
任务拆解
-
思维链(Chain of thought,CoT; Wei et al. 2022)已成为提高模型在复杂任务上性能的标准提示(prompt)技术。该模型被指示需要进行“逐步思考”,从而利用更多的测试时间计算将困难任务分解为更小、更简单的步骤。思维链将大任务转化为多个可处理的任务,并对模型思考过程进行了解释。
-
思想树(Tree of Thoughts;Yao et al. 2023)通过在每个步骤中探索多种推理可能性来扩展思维链。它首先将问题分解为多个思考步骤,并在每个步骤中生成多个思考,从而形成一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态都通过分类器(通过提示)或多数投票进行评估。
-
另一种非常独特的方法是LLM+P(Liu et al. 2023),它依赖于外部的经典规划器来进行长期规划。这种方法利用规划领域定义语言(Planning Domain Definition Language,PDDL)作为中间接口来描述规划问题。在这个过程中,LLM首先(1)将问题转化为“问题PDDL(Problem PDDL)”,然后(2)请求经典规划器基于现有的“领域PDDL(Domain PDDL)”生成一个PDDL规划,最后(3)将PDDL规划转化回自然语言。
自我反思
-
ReAct (Yao et al. 2023) ReAct整合了推理和行动能力,他扩展了LLM,让LLM能做一些语言模型内部能力不具备的行为,也扩展了大语言模型的表达空间。他让大语言模型能够与外部环境交互(比如使用Wikipedia search API),使用外部search engine),同时再把这些与外部交互获取的结果整理后放入prompt里与LLM交互,让LLM进一步的进行推理,这样整个系统就能将大语言模型与外部系统交互、思考的整个过程进行追踪,相当于用自然语言做了logging。
-
Chain of Hindsight(CoH; Liu et al. 2023) 的想法是在上下文中呈现一系列逐步改进的输出历史,并训练模型跟随趋势产生更好的输出。通过带有反馈标记的历史输出序列,来鼓励模型不断改进。人类反馈(Human feedback)数据是一个集合 Dh= {(x, yi, ri, zi)} i=1-n,其中 x是提示,yi是模型的完成结果,ri是对于yi的评分,zi是对所提供回答的回顾反馈。在给定序列前缀的条件下,模型被微调为仅预测(对应最高评分),以便模型可以根据反馈序列进行自我反思,产生更好的输出。模型在测试时可以选择接收人类注释员的多轮指令。
组件二:记忆
记忆的类型
记忆可以定义为获取、存储、保留和后续检索信息的过程。人脑中有几种类型的记忆。
- 感知记忆:这是记忆的最早阶段,能够在原始刺激结束后保留感觉信息(视觉、听觉等)的印象能力。感觉记忆通常只持续几秒钟。子类包括图像记忆(视觉)、回声记忆(听觉)和触觉记忆(触感),作为学习嵌入原始输入的表示,包括文本、图像或其他模态。
- 短期记忆(STM)或工作记忆(Working Memory):它存储我们目前意识到并需要进行复杂认知任务(如学习和推理)所需的信息。短期记忆被认为具有大约7个项目的容量(Miller 1956),并持续20-30秒,是短暂且有限的,因为它受到Transformer有限的上下文窗口长度的限制。
- 长期记忆(LTM):长期记忆可以将信息存储在一个非常长的时间内,从几天到几十年不等,并且具有几乎无限的存储容量。长期记忆是代理人在查询时可以关注的外部向量存储,通过快速检索可访问。

最大内积搜索(Maximum Inner Product Search,MIPS)
外部存储器可以缓解有限的注意力跨度限制。一种常见的做法是将信息的嵌入表示保存到一个向量存储数据库中,该数据库可以支持快速的最大内积搜索(MIPS)。为了优化检索速度,常见的选择是使用近似最近邻(approximate nearest neighbors,ANN)算法,以在一定的准确性损失下返回大约前k个最近邻,以换取巨大的加速效果。
组建三:工具的使用
-
ChatGPT插件和OpenAI API函数调用是LLM在实践中能够使用工具的很好例子。工具API的集合可以由其他开发者提供(如插件)或自定义(如函数调用)。
-
HuggingGPT(Shen et al. 2023)是一个框架,利用ChatGPT作为任务规划器,根据模型描述选择HuggingFace平台上可用的模型,并根据执行结果总结回应。
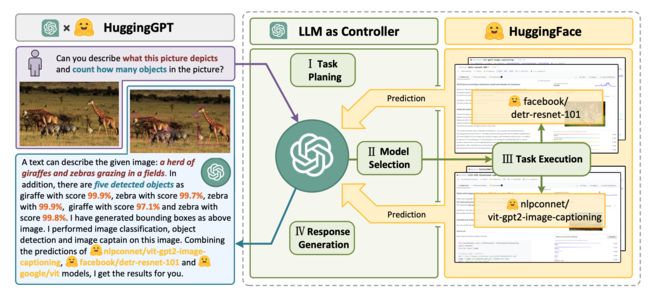
该系统由4个阶段组成:
(1)任务规划(Task planning):LLM作为大脑,将用户请求解析为多个任务。每个任务都有四个属性:任务类型、ID、依赖关系和参数。他们使用少量示例(few-shot)来指导LLM进行任务解析和规划。
(2)模型选择(Model selection):LLM将任务分配给专家模型,其中请求被构建为一个多项选择题。LLM被提供了一个模型列表供选择。由于上下文长度有限,需要基于任务类型进行筛选。
(3)任务执行(Task execution):专家模型在特定任务上执行并记录结果。
(4)响应生成(Response generation):LLM接收执行结果并向用户提供总结的结果。