2023.11.8 hadoop学习-概述,hdfs dfs的shell命令
目录
1.分布式和集群
2.Hadoop框架
3.版本更新
4.hadoop架构详解
5.页面访问端口
6.Hadoop-HDFS
HDFS架构
HDFS副本
7.SHELL命令
8.启动hive服务
1.分布式和集群
- 分布式: 多台服务器协同配合完成同一个大任务(每个服务器都只完成大任务拆分出来的单独1个子任务)
- 集 群: 多台服务器联合起来独立做相同的任务(多个服务器分担客户端发来的请求)
- 注意: 集群如果客户端请求量(任务量)多,多个服务器同时处理不同请求(不同任务),如果请求量少,一台服务器干活,其他服务器做备份使用
2.Hadoop框架
- Hadoop简介:是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
- Hadoop起源: Doug Cutting 创建的,最早起源一个Nutch项目。
- 三驾马车: 谷歌的三遍论文加速了hadoop的研发
- Hadoop框架意义: 作为大数据解决方案,越来越多的企业将Hadoop 技术作为进入大数据领域的必备技术。
- 狭义上来说:Hadoop指Apache这款开源框架,它的核心组件有:HDFS,MR,YANR
- 广义上来说:Hadoop通常是指一个更广泛的概念——Hadoop生态圈
- Hadoop发行版本: 分为开源社区版和商业版。
- 开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差。
- 商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,如: cloudera的CDH等。
3.版本更新
1.x版本系列: hadoop的第二代开源版本,该版本基本已被淘汰 hadoop组成: HDFS(存储)和MapReduce(计算和资源调度)
2.x版本系列: 架构产生重大变化,引入了Yarn平台等许多新特性 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
3.x版本系列: 因为2版本的jdk1.7不更新,基于jdk1.8升级产生3版本 hadoop组成: HDFS(存储)和MapReduce(计算)和YARN(资源调度)
4.hadoop架构详解
当前版本hadoop组成: HDFS , MapReduce ,YARN
HDFS:(分布式文件系统),解决海量数据存储
元数据: 描述核心数据的数据
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于辅助NameNode进行文件块元数据存储
DataNode:集群当中的从节点,主要用于存储真实的海量的业务数据
YARN:(作业调度和集群资源管理的框架),解决资源任务调度
ResourceManager: 接收用户的计算请求任务,并负责集群的资源管理和分配
NodeManager: 负责执行主节点分配的任务(给MR的计算程序提供资源)
MapReduce:(分布式运算编程框架),解决海量数据计算
如何计算: 核心思想就是分而治之 Map负责分解,Reduce负责合并
MR程序: 使用java/python然后去编写MR程序,成本高 如何解决? 在hive平台上编写sql,执行sql底层自动转为MR程序
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
5.页面访问端口
HDFS:9870
YARN:8088
jobhistory:19888
6.Hadoop-HDFS
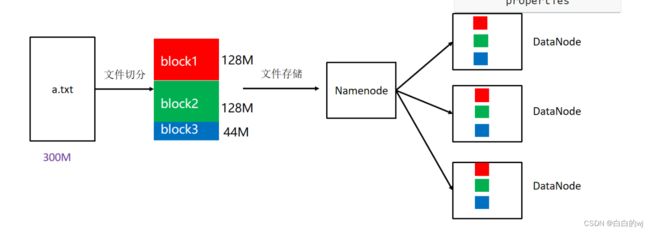
HDFS存储大文件,把大文件默认切割成128M大小的block块,进行存储
HDFS存储块的时候,会给每个块进行备份(一共三份)
HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。
HDFS架构

1、Client
发请求就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode
就是 master,它是一个主管、管理者。
处理客户端读写请求。
管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件切割后的块(block)信息…)。
配置3副本备份策略。
3、DataNode
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块(block)。
执行数据块的读/写操作。
定时向namenode汇报block信息。
4、Secondary NameNode
并非 NameNode 的备份节点。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
只是辅助 NameNode,对HDFS元数据进行合并,合并后再交给NameNode。
在紧急情况下,可辅助恢复 NameNode 部分数据。
HDFS副本
block块: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
block 块大小默认: 128M(134217728字节)
注意: 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
副本系数默认: 3个
hdfs默认文件: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
7.SHELL命令
hdfs的shell命令概念: 安装好hadoop环境之后,可以执行类似于Linux的shell命令对文件的操作,如ls、mkdir、rm等,对hdfs文件系统进行操作查看,创建,删除等。
hdfs的shell命令格式1: hadoop fs -命令 参数
hdfs的shell命令格式2: hdfs dfs -命令 参数
hdfs的家目录默认: /user/root 如果在使用命令操作的时候没有加根目录/,默认访问的是此家目录/user/root
查看目录下内容: hdfs dfs -ls 目录的绝对路径
创建目录: hdfs dfs -mkdir 目录的绝对路径
创建文件: hdfs dfs -touch 文件的绝对路径
移动目录/文件: hdfs dfs -mv 要移动的目录或者文件的绝对路径 目标位置绝对路径
复制目录/文件: hdfs dfs -cp 要复制的目录或者文件的绝对路径 目标位置绝对路径
删除目录/文件: hdfs dfs -rm [-r] 要删除的目录或者文件的绝对路径
查看文件的内容: hdfs dfs -cat 要查看的文件的绝对路径 注意: 除了cat还有head,tail也能查看
查看hdfs其他shell命令帮助: hdfs dfs --help
注意: hdfs有相对路径,如果操作目录或者文件的时候没有以根目录/开头,就是相对路径,默认操作的是/user/root
把本地文件内容追加到hdfs指定文件中: hdfs dfs -appendToFile 本地文件路径 hdfs文件绝对路径
注意: window中使用页面可以完成window本地和hdfs的上传下载,当然linux中使用命令也可以完成文件的上传和下载
linux本地上传文件到hdfs中: hdfs dfs -put linux本地要上传的目录或者文件路径 hdfs中目标位置绝对路径
hdfs中下载文件到liunx本地: hdfs dfs -get hdfs中要下载的目录或者文件的绝对路径 linux本地目标位置路径
8.启动hive服务
后台启动metastore服务: nohup hive --service metastore &
后台启动hiveserver2服务: nohup hive --service hiveserver2 &
查看metastore和hiveserver2进程是否启动: jps 注意: 服务名都叫RunJar,可以通过进程编号区分
服务启动需要一定时间可以使用lsof查看: lsof -i:10000 注意: 如果无内容继续等待,如果有内容代表启动成功
[root@node1 bin]# nohup hive --service metastore &
[1] 13490
nohup: 忽略输入并把输出追加到"nohup.out"
回车[root@node1 bin]# nohup hive --service hiveserver2 &
[2] 13632
nohup: 忽略输入并把输出追加到"nohup.out"
回车
[root@node1 bin]# jps
...
13490 RunJar
13632 RunJar
[root@node1 bin]#
# 注意:10000端口号一般需要等待3分钟左右才会查询到
[root@node1 bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 18804 root 520u IPv6 266172 0t0 TCP *:ndmp (LISTEN)
# 此处代表hive启动成功