CV计算机视觉每日开源代码Paper with code速览-2023.11.7
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】Understanding Deep Representation Learning via Layerwise Feature Compression and Discrimination
-
论文地址:https://arxiv.org//pdf/2311.02960
-
开源代码(即将开源):GitHub - Heimine/PNC_DLN

2.【图像分类】(ICLR2023)Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification
-
论文地址:https://arxiv.org//pdf/2311.02392
-
开源代码:GitHub - jarucezh/cldfd: Code implementation of ICLR paper entitled "Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification"
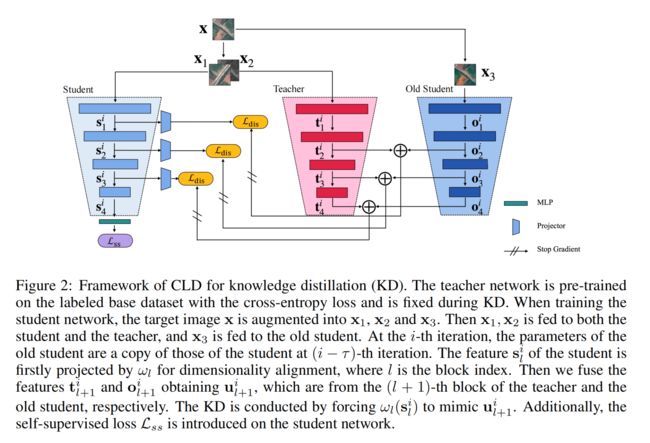
3.【开放世界目标检测】Proposal-Level Unsupervised Domain Adaptation for Open World Unbiased Detector
-
论文地址:https://arxiv.org//pdf/2311.02342
-
开源代码:https://github.com/lxycopper/PLU

4.【异常检测】Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
-
论文地址:https://arxiv.org//pdf/2311.02782
-
开源代码(即将开源):https://github.com/caoyunkang/GPT4V-for-Generic-Anomaly-Detection

5.【异常检测】Exploring Grounding Potential of VQA-oriented GPT-4V for Zero-shot Anomaly Detection
-
论文地址:https://arxiv.org//pdf/2311.02612
-
开源代码(即将开源):https://github.com/zhangzjn/GPT-4V-AD
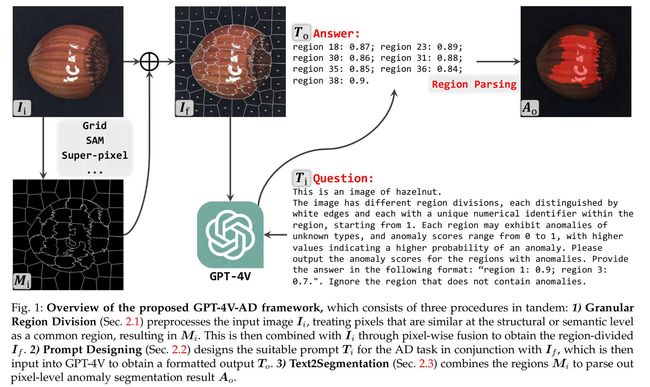
6.【图像分割】Rethinking Evaluation Metrics of Open-Vocabulary Segmentaion
-
论文地址:https://arxiv.org//pdf/2311.03352
-
开源代码:https://github.com/qqlu/Entity/tree/main

7.【实例分割】ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
-
论文地址:https://arxiv.org//pdf/2311.02734
-
工程主页:ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
-
开源代码:GitHub - nicogorlo/isar: Open-Vocabulary *I*nstance *S*egmentation *a*nd *R*e-identification

8.【人脸识别】(NeurIPS2023)UniTSFace: Unified Threshold Integrated Sample-to-Sample Loss for Face Recognition
-
论文地址:https://arxiv.org//pdf/2311.02523
-
开源代码:GitHub - CVI-SZU/UniTSFace

9.【人脸识别】Towards Machine Unlearning Benchmarks: Forgetting the Personal Identities in Facial Recognition Systems
-
论文地址:https://arxiv.org//pdf/2311.02240
-
开源代码:https://github.com/ndb796/MachineUnlearning

10.【医学图像分割】(NeurIPS2023)Uncertainty Estimation for Safety-critical Scene Segmentation via Fine-grained Reward Maximization
-
论文地址:https://arxiv.org//pdf/2311.02719
-
开源代码:https://github.com/med-air/FGRM

11.【医学图像分割】SSL-DG: Rethinking and Fusing Semi-supervised Learning and Domain Generalization in Medical Image Segmentation
-
论文地址:https://arxiv.org//pdf/2311.02583
-
开源代码:https://github.com/yezanting/SSL-DG

12.【图像增强】Zero-Shot Enhancement of Low-Light Image Based on Retinex Decomposition
-
论文地址:https://arxiv.org//pdf/2311.02995
-
开源代码(即将开源):GitHub - liwenchao0615/ZERRINNet: Low light image enhancement

13.【动作识别】(ACM MM 2023)Unified Multi-modal Unsupervised Representation Learning for Skeleton-based Action Understanding
-
论文地址:https://arxiv.org//pdf/2311.03106
-
开源代码:GitHub - HuiGuanLab/UmURL: This is a repository contains the implementation of our ACM MM 2023 paper Unified Multi-modal Unsupervised Representation Learning for Skeleton-based Action Understanding.

14.【领域泛化】Robust Fine-Tuning of Vision-Language Models for Domain Generalization
-
论文地址:https://arxiv.org//pdf/2311.02236
-
开源代码:GitHub - mit-ll/robust-vision-language-finetuning: This repository contains code for the IEEE 2023 paper Robust Fine-Tuning of Vision-Language Models for Domain Generalization, by Kevin Vogt-Lowell, Noah Lee, Theodoros Tsiligkaridis, and Marc Vaillant.
15.【多模态】GLaMM: Pixel Grounding Large Multimodal Model
-
论文地址:https://arxiv.org//pdf/2311.03356
-
工程主页:GLaMM
-
开源代码(即将开源):GitHub - mbzuai-oryx/groundingLMM: Grounding Large Multimodal Model (GLaMM), the first-of-its-kind model capable of generating natural language responses that are seamlessly integrated with object segmentation masks.
16.【多模态】SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis
-
论文地址:https://arxiv.org//pdf/2311.03355
-
工程主页:SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis
-
开源代码(即将开源):GitHub - prismformore/seggen: SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis. https://seggenerator.github.io/

17.【多模态】CogVLM: Visual Expert for Pretrained Language Models
-
论文地址:https://arxiv.org//pdf/2311.03079
-
开源代码:https://github.com/THUDM/CogVLM

18.【多模态】AnyText: Multilingual Visual Text Generation And Editing
-
论文地址:https://arxiv.org//pdf/2311.03054
-
开源代码(即将开源):https://github.com/tyxsspa/AnyText

19.【多模态】ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models
-
论文地址:https://arxiv.org//pdf/2311.02692
-
工程主页:LAMM
-
开源代码:GitHub - OpenGVLab/LAMM: [NeurIPS 2023 Datasets and Benchmarks Track] LAMM: Multi-Modal Large Language Models and Applications as AI Agents

20.【多模态】(WACV2024)Augment the Pairs: Semantics-Preserving Image-Caption Pair Augmentation for Grounding-Based Vision and Language Models
-
论文地址:https://arxiv.org//pdf/2311.02536
-
开源代码:https://github.com/amzn/augment-the-pairs-wacv2024

21.【多模态】PILL: Plug Into LLM with Adapter Expert and Attention Gate
-
论文地址:https://arxiv.org//pdf/2311.02126
-
开源代码:GitHub - DsaltYfish/PILL
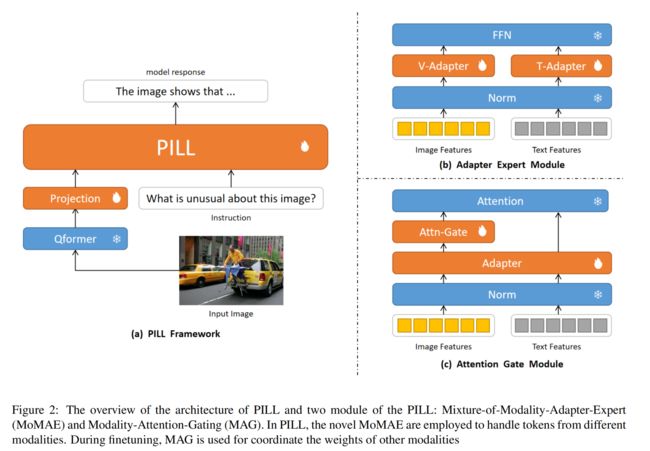
22.【深度估计】(WACV2024)Continual Learning of Unsupervised Monocular Depth from Videos
-
论文地址:https://arxiv.org//pdf/2311.02393
-
开源代码(即将开源):GitHub - NeurAI-Lab/CUDE-MonoDepthCL: Code for WACV'24 paper Continual Learning of Unsupervised Monocular Depth from Videos
23.【自动驾驶】MapSeg: Segmentation guided structured model for online HD map construction
-
论文地址:https://arxiv.org//pdf/2311.02503
-
开源代码:https://github.com/FlyEgle/CVPR_hdmap

24.【轨迹预测】JRDB-Traj: A Dataset and Benchmark for Trajectory Forecasting in Crowds
-
论文地址:https://arxiv.org//pdf/2311.02736
-
开源代码(即将开源):GitHub - vita-epfl/JRDB-Traj: JRDB dataset: trajectory prediction baselines and data preprocessing

25.【人体姿态估计】(NeurIPS2023)A Single 2D Pose with Context is Worth Hundreds for 3D Human Pose Estimation
-
论文地址:https://arxiv.org//pdf/2311.03312
-
工程主页:A Single 2D Pose with Context is Worth Hundreds for 3D Human Pose Estimation
-
开源代码:https://github.com/QitaoZhao/ContextAware-PoseFormer

26.【人体姿态估计】(ICCV Workshop 2023)Efficient, Self-Supervised Human Pose Estimation with Inductive Prior Tuning
-
论文地址:https://arxiv.org//pdf/2311.02815
-
开源代码:GitHub - princetonvisualai/hpe-inductive-prior-tuning

27.【NeRF】Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video
-
论文地址:https://arxiv.org//pdf/2311.02848
-
工程主页:Project Page
-
开源代码(即将开源):GitHub - yanqinJiang/Consistent4D: Official Implementation of Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video

28.【NeRF】VR-NeRF: High-Fidelity Virtualized Walkable Spaces
-
论文地址:https://arxiv.org//pdf/2311.02542
-
工程主页:VR-NeRF: High-Fidelity Virtualized Walkable Spaces

29.【人体重建】Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images
-
论文地址:https://arxiv.org//pdf/2311.02892
-
开源代码(即将开源):GitHub - yztang4/HaP

论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.11.6
CV计算机视觉每日开源代码Paper with code速览-2023.11.3
CV计算机视觉每日开源代码Paper with code速览-2023.11.2
CV计算机视觉每日开源代码Paper with code速览-2023.11.1
CV计算机视觉每日开源代码Paper with code速览-2023.10.31