从零开始-与大语言模型对话学技术-gradio篇(3)
前言
本文部分内容来自网上搜集与个人实践。如果任何信息存在错误,欢迎读者批评指正。本文仅用于学习交流,不用作任何商业用途。
我使用了 Gradio 库构建了一个简单的界面,用于实时人脸识别。整个程序分为几个部分,下面逐一解释各部分的作用。
目录
前言
**导入相关库**
**定义函数**
**构建 Gradio 界面**
**详细解释输入输出过程**
1. **Image** 选项卡:
2. **Camera** 选项卡:
3. **Encode** 选项卡:
4. **Upload** 选项卡:
5. **Real-time** 选项卡:
代码
总结
参考:
**导入相关库**
- `os`:用于处理文件和目录的操作
- `retinaface`:用于人脸检测的库
- `gradio`:用于构建简单的用户界面
- `cv2`:OpenCV 库,用于处理图像和视频
- `enperdict`:自定义库,包含 `VideoDetector` 类和 `detect_image` 函数
**定义函数**
1. `detect_upload`:处理上传的视频文件,进行人脸识别,并将结果保存在指定的路径下。
2. `detect_realtime`:实时捕获摄像头图像,进行人脸识别。
3. `detect_image_change`:处理上传的图像文件,进行人脸识别,并返回结果。
4. `encode_faces`:对人脸数据集中的人脸进行编码。
5. `capture_photo`:从摄像头捕获图像并保存到人脸数据集中。
**构建 Gradio 界面**
使用 Gradio 的模块化组件,我们创建了一个包含五个选项卡的界面。每个选项卡对应一个功能,如下所述:
1. **Image**:上传图像文件进行人脸识别。包含一个文件输入,一个图像输出,以及一个按钮用于触发识别操作。
2. **Camera**:通过摄像头实时捕获图像进行人脸识别。包含一个文本框用于输入姓名,一个摄像头图像输入,一个文本输出,以及一个按钮用于提交操作
3. **Encode**:对人脸数据集进行编码。包含一个按钮用于触发编码操作,以及一个文本输出显示编码结果。
4. **Upload**:上传视频文件进行人脸识别。包含一个文件输入,一个文件输出,以及一个按钮用于触发视频识别操作。
5. **Real-time**:实时捕获摄像头视频进行人脸识别。包含一个按钮用于启动实时识别操作。
**详细解释输入输出过程**
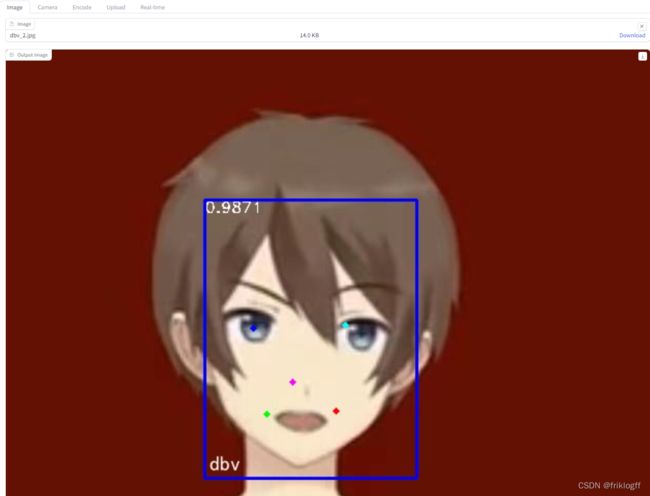
1. **Image** 选项卡:
- 输入:用户通过文件输入组件上传图像文件。
- 输出:将图像文件传递给 `detect_image_change` 函数,该函数识别图像中的人脸并返回处理后的图像。处理后的图像显示在图像输出组件中。
2. **Camera** 选项卡:
- 输入:用户在文本框中输入姓名,通过摄像头捕获图像。
- 输出:将姓名和图像传递给 `capture_photo` 函数,该函数将捕获的图像保存到人脸数据集中。成功保存后,输出文本组件显示保存的文件名。
3. **Encode** 选项卡:
- 输出:点击按钮触发 `encode_faces` 函数,该函数对人脸数据集中的人脸进行编码。编码完成后,输出文本组件显示编码结果。

4. **Upload** 选项卡:
- 输入:用户通过文件输入组件上传视频文件。
- 输出:将视频文件传递给 `detect_upload` 函数,该函数识别视频中的人脸并将处理后的视频保存在指定路径下。处理后的视频作为文件输出组件返回。

5. **Real-time** 选项卡:
- 输出:点击按钮触发 `detect_realtime` 函数,该函数实时捕获摄像头视频并进行人脸识别。实时识别结束后,用户可以关闭窗口。
最后,通过 `demo.launch()` 启动 Gradio 界面。
代码
import os
from retinaface import Retinaface
import gradio as gr
import cv2
from enperdict import VideoDetector, detect_image
def detect_upload(video_path, video_save_path='output/result.avi', video_fps=25.0):
video_path = video_path.name
# 上传视频文件并进行人脸识别
detector = VideoDetector(video_path, video_save_path, video_fps)
while True:
frame = detector.process_frame()
if frame is None:
break
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
detector.release()
cv2.destroyAllWindows()
print(f"Returning video path: {video_save_path}")
return video_save_path
def detect_realtime(video_path=None, video_save_path='output/result.mp4', video_fps=25.0):
# 开启摄像头实时进行人脸识别
video_path = 0
detector = VideoDetector(video_path, "", video_fps)
while True:
frame = detector.process_frame()
if frame is None:
break
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
detector.release()
cv2.destroyAllWindows()
def detect_image_change(image=None):
image_path = image.name
temp_img_path = "output/result.jpg"
result = detect_image(image_path, temp_img_path)
return result
num = 0
def encode_faces():
'''
在更换facenet网络后一定要重新进行人脸编码,运行encoding.py。
'''
retinaface = Retinaface(1)
list_dir = os.listdir("face_dataset")
image_paths = []
names = []
for name in list_dir:
image_paths.append("face_dataset/" + name)
names.append(name.split("_")[0])
retinaface.encode_face_dataset(image_paths, names)
return "Encoding complete!"
def capture_photo(name, img):
"""
:param name:
:param img:
:return:
"""
if name == "":
return "Name cannot be empty!"
if img is None:
return "img cannot be empty"
else:
global num
num += 1
cv2.imwrite("face_dataset/" + name + "_" + str(num) + ".jpg", img)
return "success to save" + name + "_" + str(num) + ".jpg"
# 使用 Gradio 的模块化组件,构建包含五个选项卡的界面
with gr.Blocks() as demo:
with gr.Tab("Image"):
# Image 选项卡: 上传图像文件进行人脸识别
image_input = gr.File(label="Image")
image_output = gr.Image(label="Output Image")
image_button = gr.Button("Detect")
image_button.click(detect_image_change, inputs=image_input, outputs=image_output)
with gr.Tab("Camera"):
# Camera 选项卡: 通过摄像头实时捕获图像进行人脸识别
image_input = [gr.components.Textbox(label="Name"),
gr.components.Image(source="webcam", label="Webcam"),
]
image_output = gr.components.Textbox(label="output")
image_button = gr.Button("提交")
image_button.click(capture_photo, inputs=image_input, outputs=image_output)
with gr.Tab("Encode"):
# Encode 选项卡: 对人脸数据集进行编码
encode_button = gr.Button("Encode")
encode_output = gr.Textbox(label="Output")
encode_button.click(encode_faces, outputs=encode_output)
with gr.Tab("Upload"):
# Upload 选项卡: 上传视频文件进行人脸识别
video_input = gr.File(label="video_path")
video_output = gr.File(label="Output Video")
upload_button = gr.Button("Upload")
upload_button.click(detect_upload, inputs=video_input, outputs=video_output)
with gr.Tab("Real-time"):
# Real-time 选项卡: 实时捕获摄像头视频进行人脸识别
realtime_button = gr.Button("Start")
realtime_button.click(detect_realtime)
demo.launch()总结
从零开始-与大语言模型对话学技术-gradio篇(1)
从零开始-与大语言模型对话学技术-gradio篇(2)
以上内容大致总结介绍了一个gradio实现的人脸识别UIdemo设计,UI集成的功能包括拍照,对人脸数据集中的人脸进行编码,识别照片,识别视频,实时识别功能,希望以上的内容对你有所帮助,喜欢的可以给博主来一个三连,以上还有往期跳转连接
参考:
Gradio官网:https://www.gradio.app/
Gradio官方文档:https://gradio.app/docs