线程安全问题分析
文章目录
-
- 一、抢占式执行
- 二、两个线程修改同一变量
- 三、原子性
- 四、内存可见性
- 五、指令重排序
多线程可以实现并发编程,从而提升效率。但由于多线程的调度的随机性,导致程序出现错误,这就叫做
“线程不安全”。如果在多线程的条件下,程序运行的结果和单线程条件下运行的结果是一致的,那么该线程就是安全的。
那么,多线程在哪些情况下会不安全呢?有如何解决这样的不安全问题呢?
一、抢占式执行
出现线程安全问题的根本问题就是线程的抢占式执行
抢占式执行意思就是,当某个线程正在执行,在就绪队列中有一个更高优先级的任务出现了,当前任务就会被抢占(中断),那个更高优先级的线程就会上位被执行即获取到 CPU 的控制权
对于这样的根本原因导致的线程安全问题我们是没有办法从根源解决的
二、两个线程修改同一变量
代码案例:
public class test1 {
private static int count = 0;//被thread1和thread2线程同时修改的变量count
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(()->{
for (int i = 0;i < 200000;i ++) {
count ++;
}
});
//thread1.join();
thread1.start();//创建thread1线程
Thread thread2 = new Thread(()->{
for (int i = 0;i <200000;i ++) {
count++;
}
});
thread2.start();//创建thread2线程
thread1.join();
thread2.join();//main线程阻塞等待,直到两个线程执行完毕
System.out.println("count = "+count);
}
}
代码结果:

代码结果的值多次执行都是不一样的,且都是20_0000 到 40_0000之间的数字。
为解决这样的问题,我们可以对代码结构进行一定的调整,比如在本案例中可以使用 join 方法等待线程 thread1 执行完 count 自增操作再执行线程 thread2。这样的做法虽然保证了结果的正确性,却没有并发编程带来的效率的提升
三、原子性
上述案例之所以出现俩线程修改同一变量就会出现线程不安全,是因为此时线程针对变量 count 的自增操作不是原子的
count ++ 步骤解析:
- 将内存中的值读到CPU寄存器中(
load) - 将寄存器中的数进行加一操作(
add) - 将寄存器中的值写回到内存中(
save)
当其中一线程正在执行 count ++ 操作中的步骤时,如果这三个步骤不是原子性的,没有打包到一起进行执行。那么就会有其他的线程在半道杀进来,导致结果出现错误
- 执行顺序一:

当 thread1 线程执行 ++ 操作和 thread2 线程执行 ++ 操作分离开时,最后两次自增结果是正确的
- 执行顺序二:

当 thread1 线程从内存中读取到 0 后, thread2 线程也从内存中读取到 0,前者自增后将 1 写回到内存中,后者也进行自增将 1 写回到内存中,两个线程共进行了两次自增操作,但结果却只增加了 1
- 执行顺序三:
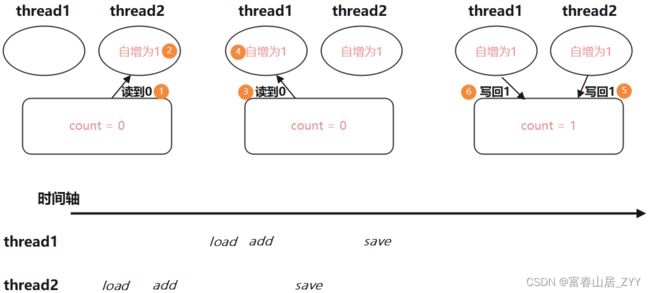
线程 thread 2 已经从内存中读取到 0,也在 CPU 中完成了自增操作,还没把 1 给存到内存中,线程 thread 1就把内存中的 0 给读走了,导致最后两个线程共进行了两次自增操作,但结果却只增加了 1
因为 count ++ 操作不是原子性的,导致除了两个线程分别完整执行完 ++ 操作(串行)以外,其他的线程执行情况都会出现结果的 BUG
解决办法:
加锁。通过加锁操作使得 count ++ 操作编程原子性的,使得无序的结果变得唯一。最常用的加锁方案就是通过 synchronized 关键字进行加锁
代码改进:
public class test1 {
private static int count = 0;
//给 count ++ 操作进行加锁操作
public static synchronized void increase() {
count++;
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(()->{
for (int i = 0;i < 200000;i ++) {
increase();
}
});
thread1.start();
Thread thread2 = new Thread(()->{
for (int i = 0;i <200000;i ++) {
increase();
}
});
thread2.start();
thread1.join();
thread2.join();
System.out.println("count = "+count);
}
}
代码结果:

无论运行几次,结果都是 40_0000,符合预期效果
当 increase 方法加上 synchronized 关键字后,某线程进入了该方法就会加锁,别的线程想获取到锁就必须等到当前获取到锁的线程执行好 increase 方法后,锁释放了,才有获得锁的机会
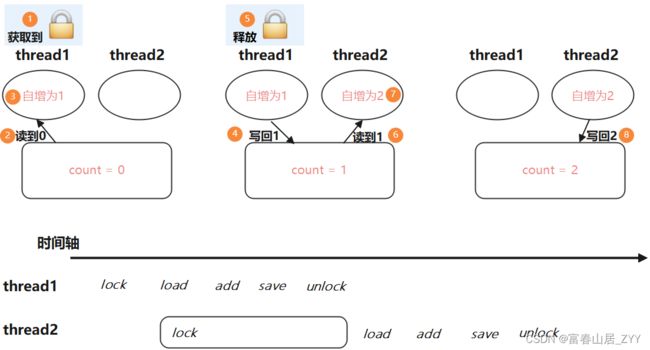
线程 thread 1 先获取到锁,执行之后的自增逻辑。在此期间,线程 thread 2 也尝试获取到锁,但是所已经被拿走了,就只能陷入阻塞等待(此时线程状态为 Block 状态),直到线程 thread 1 执行完所有自增相关操作后将锁释放了,才有获取到锁的机会进行自增操作
引入加锁操作后,就相当于将自增中的三个步骤打包到一起,变成原子性,结果正确,但由于中间涉及到阻塞等待,并发性就会降低,就会导致程序效率下降,但就算如此加锁操作还是很有必要的。
四、内存可见性
可见性就是一个线程对一个共享的变量值进行修改,其他的线程能够及时的看见
代码案例:
在线程 t1 中不断的读取 count 变量,其值为 0 就进行不断的循环,直到 count 的值不为 0 ,就跳出循环
在 main 线程中去修改 count 的值,使其值不为 0
预期结果是当 count 的被改了以后,线程 t1 结束
public class func14 {
private static int count = 0;
public static void main(String[] args) {
Thread t1 = new Thread(()->{
while (true) {
if (count != 0) {
break;
}
}
System.out.println("线程t1已结束");
});
t1.start();
Scanner scan = new Scanner(System.in);
System.out.println("请输入count的值:");
count = scan.nextInt();
System.out.println("count = " + count);
}
}
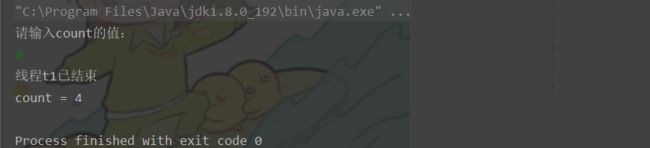
代码结果:

线程 t1 并没有结束,但 count 的值确实是被修改了
分析结果:
出现这样的结果就是因为内存的可见性
count 就是线程之间的共享变量,存储在主内存中,每一个线程都有自己的工作内存,实际指的就是寄存器。线程读或者修改一个共享变量的时候,都会将变量数据从主内存中拷贝到工作内存中,然后该读的读,该修改的修改,修改好的数据就再同步到主内存中。
在线程 t1 在不停循环读取 count 的值时,因为编译器优化产生了误判
编译器发现反复读取 count 的次数太多了,并且读取出的值还都是一样的,编译器也无法将多线程之间的联系进行分析,就决定省略不断读取 count 值的操作,直接保留 count 的一次的结果(0),之后想要读取再也不会去内存中读,而是选择去寄存器中读,毕竟寄存器读取数据的速度比去内存中读数据要快很多
main 线程中去修改 count的值,线程 t1 没法感觉到
虽然寄存器读取数据的速度更快,但由于寄存器的成本比内存高很多,所以内存的存在还是很有必要的
解决办法:
-
使用
synchronized关键字禁止了编译器在 synchronized 内部的代码中产生优化
Thread t1 = new Thread(()->{ while (true) { synchronized (func14.class) { if (count != 0) { break; } } } System.out.println("线程t1已结束"); });代码结果:
-
使用
volatile关键字修饰对应的变量同样可以禁止编译器进行优化,保证每次数据的读取都从内存中读,实现内存的可见性
private static volatile int count = 0;
五、指令重排序
指令重排序也是编译器优化的一种,在保证原有代码的逻辑不变的情况下,编译器会对程序指令的执行顺序进行一定的优化重排,从而提升效率。
指令重排序在单线程的情况下还是比较准确的,但是在多线程的条件下,就容易出现误判的现象,导致逻辑和原来的代码产生不一致,产生了线程不安全的现象
解决方法:
同样通过 synchronized 关键字,编译器就不会对对应代码进行优化
完!