Clickhouse数据库七:配置高可用(复本)
Clickhouse数据库七:配置高可用(复本)
副本的目的主要是保障数据的高可用性,即使一台clickhouse节点宕机,那么也可以从其他服务器获得相同的数据。
clickhouse的副本严重依赖zookeeper, 用于通知副本server状态变更
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复本表和非复本表。
7.1 复本写入流程

7.2 配置规划

7.3 在hadoop103安装clickhouse
参考:https://blog.csdn.net/weixin_42796403/article/details/115033468
7.4 创建配置文件: metrika.xml
- 分别在
hadoop102和hadoop103创建配置文件metrika.xml, 配置zookeeper地址
sudo vim /etc/clickhouse-server/config.d/metrika.xml
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
- 告诉clickhouse 刚刚创建的配置文件的地址
在hadoop102和hadoop103添加如下配置
sudo vim /etc/clickhouse-server/config.xml
找到节点, 在下面添加如下内容
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
![]()
7.5 分别在hadoop102和hadoop103建表
clickhouse的复本是表级别的. 有些语句不会自动产生复本, 有些语句会自动产生复本
- 对于
INSERT和ALTER语句操作数据会在压缩的情况下被复制 - 而
CREATE,DROP,ATTACH,DETACH 和 RENAME语句只会在单个服务器上执行,不会被复制
所以建表的时候, 需要在2个节点上分别手动建表
- 在hadoop102建表
create table rep_t_order_mt2020 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop102')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
- 在hadoop103上建表
create table rep_t_order_mt2020 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop103')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
- 说明
ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2020','rep_hadoop103')
参数1: 该表在zookeeper中的路径.
/clickhouse/tables/{shard}/{table_name} 通常写法,
shard表示表的分片编号, 一般用01,02,03…表示
table_name 一般和表明保持一致就行
参数2: 在zookeeper中的复本名. 相同的表, 复本名不能相同
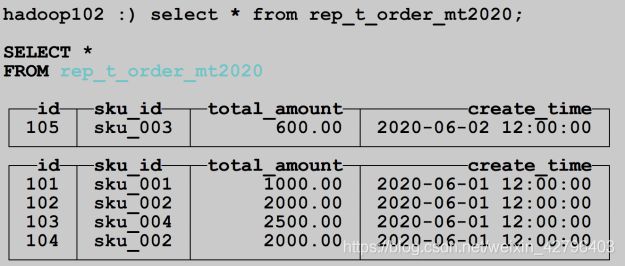
- 在hadoop102上插入数据
insert into rep_t_order_mt2020
values(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00')
- 分别在hadoop102和hadoop103查询