Linux sed命令(二)进阶
在之前的文章 Linux sed命令(一)基础中,我们分析了sed命令的基本使用,它们基本可以满足我们的大多数操作,然而我们可以发现它存在着一些局限,比如:需要跨行操作、跳转操作时,我们就需要学习sed更多的高级特性了。
一、多行命令
sed编辑器中有三个可以用来处理多行文本的特殊命令:
- N:将数据流的下一行加进模式空间创建一个多行组
- D:删除多行组中的一行
- P:打印多行组中的一行
后面会陆续用到这几个命令。
1、单行的next命令 n命令
小写的n命令会告诉编辑器移动到数据流的下一行文本,而不用回到命令最开始的地方再执行一遍。听着很抽象,请看以下示例。如果我们想删除一个文件中的空白行时,很简单就会想到以下方法:
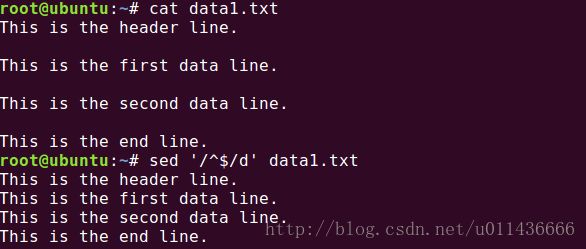
这里用到了^$来匹配空行,并用d命令将其删掉。假如我们只想删除一个空白行呢?按照目前我们知道的针对单行的操作方式来说,很难做到。接下来请看下面方法:
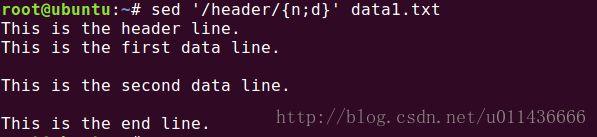
命令sed '/header/{n;d}' data1.txt 的作用是:查找含有header字符串的那一行,接着执行大括号{ }中的命令列表,n表示将下一行读入到sed编辑器的工作空间(又叫模式空间),d命令来删除这一行。很容易想到,我们改变address就可以对多行数据进行操作了!
2、合并文本行(多行版) N命令
单行的next命令(小写n)会将数据流的下一行放入sed的模式空间,而多行版的next命令(大写N)会将下一行数据添加到模式空间已有的文本后。请看以下示例:
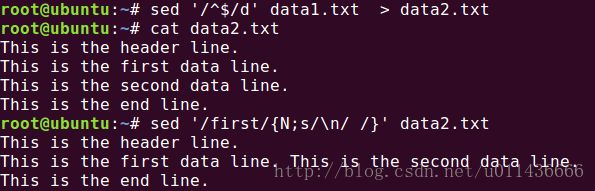
这里用到的sed '/first/{N;s/\n/ /}' data2.txt 是什么意思呢?首先是查找到first字符串所在的行,再执行命令列表中的N命令,将first的下一行附加到模式空间中(这是first这一行在sed的模式空间中),然后用s命令用空格替换换行符。逻辑非常的清晰。我们稍加修改,便可以完成更多的操作:


注意观察上图,首先执行的是N命令,将行添加到模式空间中,再执行替换命令,但是我们发现第二行和第三行并没有连接然后替换,而是三四行进行了连接替换的操作。这是因为,当读取第一行时,由于模式空间中是空的,所以第一行并没有添加进去,而是当读到第二行时将第二行附加到了第一行后面形成新行,然而这一新行并未满足s命令的条件,所以没有发生替换。于是,再从第三行进行sed命令的操作,如此循环下去。
3、多行删除和多行打印命令
多行删除-在sed命令基础中我们介绍了单行删除命令d,而多行删除命令为D,请看下面的示例:
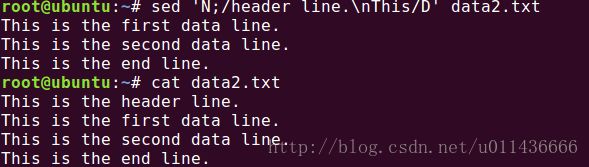
这里的命令sed 'N;/header line.\nThis/D' data2.txt 表示读取连接两行后,用D命令进行多行删除,然而我们发现,它只是删除了模式空间中的第一行,而非连接后的一行!这是我们试试单行删除命令d,可以发现,它将连接后的两行当做一行删除掉了,如下所示,这一点要特别注意!

多行打印-多行打印(大写P)和多行删除的原理区别不大,它只打印多行模式空间中的第一行,直到换行符为止的所有字符。
二、保持空间和模式空间
模式空间 (pattern space)是一块活跃的缓冲区,在sed编辑器执行命令时它会保存待检查的文本。(要记住除非使用多行命令,一般模式空间中只保存一条数据)。sed编辑器中有另一块称作保持空间 (hold space)的缓冲区域,可以用来临时保存模式空间中的一些行。sed中有5条命令可以用来操作保持空间:
| 命令 | 描述 |
|---|---|
| h | 将模式空间复制到保持空间 |
| H | 将模式空间附加到保持空间 |
| g | 将保持空间复制到模式空间 |
| G | 将保持空间附加到模式空间 |
| x | 交换模式空间和保持空间的内容 |
适当的使用这几个交换操作,可以起到很有用的效果,后面会逐渐使用这几条命令。
三、排除命令
感叹号命令(!)用来排除命令,也就是让原来的命令不起作用。看一个简单的示例:
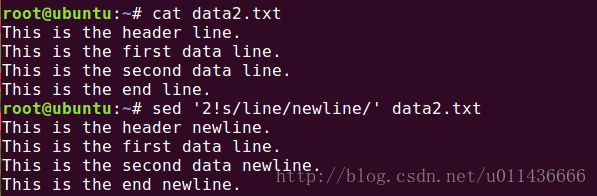
这里我们的目的是替换line为newline,然而在开始的address里,用了2!,即表示对第二行不进行后面的命令,结果也正如预期。我们可以充分发挥想象,来进行过多的操作。
四、改变流
什么叫做改变流呢?通常sed编辑器会从脚本的开头开始,一直执行到脚本的结尾(D命令例外?)。sed编辑器提供了一种方法来改变脚本的执行流程,其结果与结构化编程类似。
1、分支
分支命令的格式如下:[address]b [lable] 参数address确定了哪些行的数据会触发分支命令,lable定义了要跳转到的位置,如果不定义lable则默认调到脚本的结尾。
如下图所示,我们指定了2,3b,即执行第二三行时跳转到lable处,然而我们没有定义lable,所以什么操作也没进行。
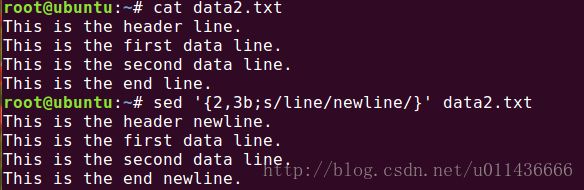
定义lable的话也很简单,如下图我们用/first/b jump来匹配到含有first的行,并且跳转到lable定义处:jump,所以这一行执行分支标签后的操作,而为匹配到的行执行前面的操作。

特别注意:
如果分支命令的模式没有匹配,sed编辑器会继续执行脚本中的命令,包括分支标签后的命令!
这里有时候会出现一些意想不到的错误,比如我们要将含有first中一行的line改为jumped_line,将其他行的line改为newline,我们也许会写出如下的sed命令:
sed '{/first/b jump;s/line/newline/:jump
s/line/jumped_line/}' data2.txt
运行之后可以发现:
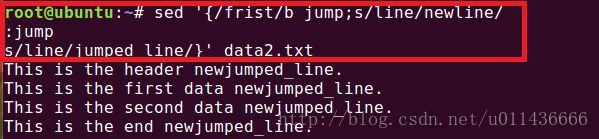
结果并非如我们所愿,问题就在于如果没有匹配上,会执行包括跳转标签后的所有命令!
2、测试
测试命令(t)[address]t [lable]类似于分支命令也可以用来改变sed编辑器脚本的执行流程,测试命令会根据替换命令的结果跳转到某个标签,而不是根据地址进行跳转。
如下图,先执行替换命令,如果test成功,则执行它并且不会执行第二条替换命令;如果没执行成功,则执行第二条命令。类似于一个if-then-else的逻辑。

我们这里只是用替换命令做一个示例而已,换成其他命令都是可以的:

合理的使用test命令,会起到强大的功能,比如我们有一行存在很多,的文本,我们需要去掉,保留文本,这时可以用test命令带上label构造一个无限循环:

如上图所示,我们用替换命令s/,/ /来替换每一个逗号,之后用test命令跳转到开头,实际上是完成了一个循环替换逗号的功能。
改变流的branch和test命令很强大,使用它也需要很好的理解和想象力。
五、模式替代
1、&符号
问题引入:我们可以使用模式来替代数据流中的文本,然而在使用通配符的时候,很难知道哪些文本会被匹配。比如:我们想要给行中用通配符.来匹配多个单词,并给其加上双引号”“。在尚未学习&符号时,我们很难完成这个操作!

2、替代单独的单词-子模式
通过上面的示例我们很容易发现:&符号就是来替换前面通过模式匹配到的字符的。有时你只想提取这个字符串的一部分呢?
sed编辑器中用圆括号()来定义替换模式中的子模式(\(string\))。替代字符由反斜线和数字组成,表明子模式的位置,第一个子模式为\1,第二个为\2,以此类推。
如下图所示,我们替换掉含有.second line(用到了.通配符)的行,再用
“\1” LINE,将匹配到的字符串中的第一个子模式包上双引号,加上LINE后构造新的字符串替换掉匹配到的。

通过使用以上的几条高级特性的命令,我们可以完成很多的高级操作了,要达到熟练使用的程度还需要大量的练习来融会贯通。后面笔者也会分享一些使用的sed脚本来处理一些通用的问题。:)