页表和cache
页表基本原理
页表主要用来将虚拟地址映射到物理地址,在使用虚拟地址访问内存时,微处理器首先将虚拟地址拆分成页号和页内偏移量,然后使用页号在页表中查找对应的物理页框号,将物理页地址加上页内偏移量,得到最终的物理地址。
32位系统中,当页大小为4KB时,如要覆盖4GB内存,需要1M个页项,如果页项是连续的,每个页项占4字节的话,页表总共需要4MB。
虚拟地址组成:
| 20位 | 12位 |
|---|---|
| 页号 | 页内偏移 |
4MB如果在进程运行前都准备好,对于进程来说空间占用太大了。可以考虑用多级页表,实现动态分配,假如分两级,每级各占10比特:
| 10位 | 10位 | 12位 |
|---|---|---|
| 页目录项(Page Directory Entry,PDE) | 页表表项(Page Table Entry,PTE) | 页内偏移(Page Offset) |
一个页目录项可以覆盖210个页,也就是1MB内存。
cache基本原理
cache是为了缓存经常用到的内存数据。
先不考虑缓存的是物理地址还是虚拟地址。
cache以cache line为单位进行缓存,如果cache line是8字节,那这8字节会一起加载到cache中,要失效也是一起失效。
直接映射缓存
下图是一个64字节大小的cache,data array中每行是一个cache line,cache line有一个D位,表示数据是否dirty。
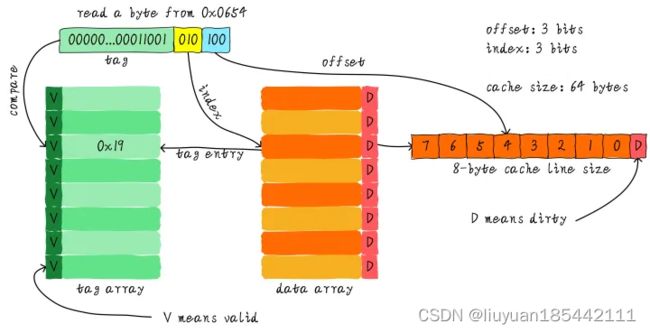
cache将地址分为3部分:tag index offset。
offset是地址在cache line中的偏移,该例中cache line是8字节,所以需要3比特。
index是地址在data array中的索引,该例中cache size是64字节,cache line是8字节,所以data array有8行,index需要3比特。
地址 0x14 和 0x654 都映射到cache中一个位置,那怎么区分存储的是哪个数据呢,靠比较tag。
1个tag对应1个cache line,所以offset位不需要考虑,对比tag的时候已经定位到具体的行了,index位也是固定的了,所以tag只需要记录除offset和index外的位,该例中是32-3-3=26位。tag array和data array容量相同,并且一一对应,如果tag是 0x19,就表示当前cache line的起始地址是 0x650。
| 26位 | 3位 | 3位 |
|---|---|---|
| tag | index | offset |
我们可以从图中看到tag旁边还有一个valid bit,用来表示cache line中数据是否有效。当系统刚启动时,cache中的数据都应该是无效的。所以,上述比较tag确认cache line是否命中之前还会检查valid bit是否有效。只有在有效的情况下,比较tag才有意义。如果无效,直接判定cache缺失。
图中这种方式叫直接映射缓存,它对地址的缓存是循环的,0x00,0x40,0x80…开始的8字节都映射到同一个cache line中。
系统启动后,当我们访问 0x00 地址时,cache会缺失,然后数据会从主存加载到cache中第0行cache line。当我们访问0x40地址时,依然索引到cache中第0行cache line,由于此时cache line中存储的是地址0x00地址对应的数据,所以此时依然会cache缺失。然后从主存中加载0x40地址数据到第0行cache line中。同理,继续访问0x80地址,依然会cache缺失。这就相当于每次访问数据都要从主存中读取,访问0x40地址时,就会把0x00地址缓存的数据替换。这种现象叫做cache颠簸(cache thrashing)。
多路组相连缓存
针对这个问题,引入多路组相连缓存。我们首先研究下最简单的两路组相连缓存。
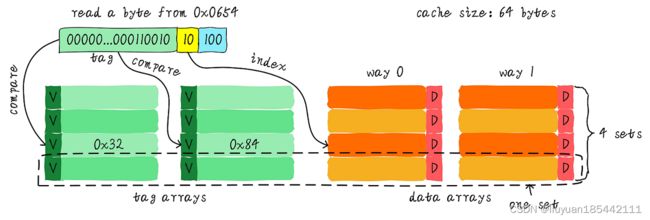
data array中竖着叫路,横着叫组。将64字节cache分成两路,之前data array有8行,现在有两个data array,所以只有4行了,index也只需要2比特了。tag还是占除index和offset外的所有位。
根据index找到是哪组,然后将组内的所有cache line对应的tag取出来和地址中的tag部分对比,如果其中一个相等就意味着命中。就像链表一样。
据说会降低cache颠簸的频率。
直接映射缓存是组相连缓存的一种特殊情况,每个组只有1个cache line,它只有1路。全相连缓存是另一种特殊情况,它只有1组。
cache size = 2index位数 * 路数 * 2offset位数 = 路数 * 2(index位数+offset位数)
cache组织方式
PIPT和VIPT
如果cache缓存的是物理地址,称为PIPT,Physically Indexed Physically Tagged。CPU发出的虚拟地址经过MMU转换成物理地址,再将物理地址发往cache控制器查找确认是否命中cache。
如果缓存的是虚拟地址,称为VIVT,Virtually Indexed Virtually Tagged。虚拟地址直接送到cache控制器,如果cache hit,直接从cache中返回数据给CPU,如果cache miss,则把虚拟地址发往MMU,经过MMU转换成物理地址,从主存读取数据。
缓存命中的时候,相比PIPT,VIVT少了虚拟地址到物理地址的转换。但是VIVT有歧义和别名的问题。
歧义是指不同的数据在cache中具有相同的tag和index。假设A进程虚拟地址0x4000映射物理地址0x2000,B进程虚拟地址0x4000映射物理地址0x3000。当A进程运行时,访问0x4000地址会将物理地址0x2000的数据加载到cache中。当切换到B进程的时候,B进程访问0x4000会怎样?当然是会cache hit,B进程本来想得到物理地址0x3000对应的数据,但是却由于cache hit得到了物理地址0x2000的数据。进程切换的时候flush cache可以避免歧义问题。
同一个物理地址的数据被加载到不同的cache line中就会出现别名现象。比如虚拟地址0x2000和0x4000(二者在不同的cache line中)都映射到相同的物理地址0x8000,这意味着进程既可以从0x2000读取数据,也能从地址0x4000读取数据。这是由页表的多对一导致的。一个解决方法是,让映射到同一物理地址的虚拟地址,在cache中也有相同的地址。但这只对直接映射缓存有效,细节后面会详细说。
VIPT
为了提升cache查找性能,我们不想等到虚拟地址转换物理地址完成后才去查找cache。因此,我们可以使用虚拟地址对应的index位查找cache,与此同时(硬件上同时进行)将虚拟地址发到MMU转换成物理地址。二者都完成时,比较cache line对应的tag和物理地址,以此判断是否命中cache。我们称这种方式为VIPT(Virtually Indexed Physically Tagged)。
cache line对应的tag可以使用完整的物理地址。此时不会有歧义问题,比如之前例子中,B进程访问0x4000时会发现tag不同,于是cache miss。由于物理地址和虚拟地址的低12位是相同的,cache line对应的tag可以只存物理地址的高20位,对比的时候将其加上地址的低12位便是完整的物理地址了。
别名问题是因为虚拟地址和物理地址多对一导致的,只要物理地址相同的虚拟地址,也在相同的cache地址中就不会有问题。也就是让这些虚拟地址的index位和offset位相同。
当index位和offset位之和不大于12时,各个虚拟地址的低12位和物理地址的低12位本就相同,所以index位和offset位也必然相同,此时不存在别名问题。
当index位和offset位之和大于12时,为同一物理地址分配多个虚拟地址时,则要保证虚拟地址的index位和offset位相同,可以让其全为0,也就相当于按“cache size/路数”对齐了。
这种方法在VIVT中只对直接映射缓存有效。因为在多路组相连缓存中,对应同一物理地址的多个虚拟地址会映射到同一组中,如果是Virtually Tagged,因为tag不同,它们会定位到不同的路中。
PIVT
不存在,因为PIVT方式首先要通过MMU转换成物理地址,然后才能根据物理地址index域查找cache,既然都有了物理地址,干嘛不直接用PIPT。
参考
Cache的基本原理
Cache组织方式