istio 学习笔记
参考:istio简介和基础组件原理(服务网格Service Mesh)-CSDN博客
Istio = 微服务框架 + 服务治理。
Istio的关键功能:
HTTP/1.1,HTTP/2,gRPC和TCP流量的自动区域感知负载平衡和故障切换。
通过丰富的路由规则,容错和故障注入,对流行为的细粒度控制。
支持访问控制,速率限制和配额的可插拔策略层和配置API。
集群内所有流量的自动量度,日志和跟踪,包括集群入口和出口。
安全的服务到服务身份验证,在集群中的服务之间具有强大的身份标识。
微服务拆分之后,单个微服务的复杂度大幅降低,但是由于系统被从一个单体拆分为几十甚至更多的微服务, 就带来了另外一个复杂度:微服务的连接、管理和监控。
对于一个大型系统, 需要对多达上百个甚至上千个微服务的管理、部署、版本控制、安全、故障转移、策略执行、遥测和监控等,谈何容易。更不要说更复杂的运维需求,例如A/B测试,金丝雀发布,限流,访问控制和端到端认证。
1、什么是Service Mesh(服务网格)?
Service Mesh是专用的基础设施层,轻量级高性能网络代理。提供安全的、快速的、可靠地服务间通讯,与实际应用部署一起,但对应用透明。应用作为服务的发起方,只需要用最简单的方式将请求发送给本地的服务网格代理,然后网格代理会进行后续操作,如服务发现,负载均衡,最后将请求转发给目标服务。当有大量服务相互调用时,它们之间的服务调用关系就会形成网格。
如果我们可以在架构中的服务和网络间透明地注入一层,那么该层将赋予运维人员对所需功能的控制,同时将开发人员从编码实现分布式系统问题中解放出来。通常将这个统一的架构层与服务部署在一起,统称为“服务啮合层”。由于微服务有助于分离各个功能团队,因此服务啮合层有助于运维人员从应用特性开发和发布过程中分离出来。通过系统地注入代理到微服务建的网络路径中,Istio将迥异的微服务转变成一个集成的服务啮合层。
Istio力图解决前面列出的微服务实施后需要面对的问题。Istio 首先是一个服务网络,但是Istio又不仅仅是服务网格: 在 Linkerd, Envoy 这样的典型服务网格之上,Istio提供了一个完整的解决方案,为整个服务网格提供行为洞察和操作控制,以满足微服务应用程序的多样化需求。
流量控制:控制服务之间的流量和API调用的流向,使得调用更可靠,并使网络在恶劣情况下更加健壮。
可观察性:了解服务之间的依赖关系,以及它们之间流量的本质和流向,从而提供快速识别问题的能力。
策略执行:将组织策略应用于服务之间的互动,确保访问策略得以执行,资源在消费者之间良好分配。策略的更改是通过配置网格而不是修改应用程序代码。
服务身份和安全:为网格中的服务提供可验证身份,并提供保护服务流量的能力,使其可以在不同可信度的网络上流转。
平台支持:Istio旨在在各种环境中运行,包括跨云, 预置,Kubernetes,Mesos等。最初专注于Kubernetes,但很快将支持其他环境。
集成和定制:策略执行组件可以扩展和定制,以便与现有的ACL,日志,监控,配额,审核等解决方案集成。
这些功能极大地减少了应用程序代码,底层平台和策略之间的耦合,使微服务更容易实现。
之前的做法:
找个Spring Cloud或者Dubbo的成熟框架,直接搞定服务注册,服务发现,负载均衡,熔断等基础功能。自己开发服务路由等高级功能, 接入Zipkin等Apm做全链路监控,自己做加密、认证、授权。 想办法搞定灰度方案,用Redis等实现限速、配额。
维跑来提了点要求,在他看来很合理的要求,比如说:简单点的加个黑名单, 复杂点的要做个特殊的灰度:将来自iPhone的用户流量导1%到Stagging环境的2.0新版本
Istio 超越 spring cloud和dubbo 等传统开发框架之处, 就在于不仅仅带来了远超这些框架所能提供的功能, 而且也不需要应用程序为此做大量的改动, 开发人员也不必为上面的功能实现进行大量的知识储备。
架构
整体架构
Istio服务网格逻辑上分为数据面板和控制面板。

当前流行的两款开源的服务网格 Istio 和 Linkerd 实际上都是这种构造,只不过 Istio 的划分更清晰,而且部署更零散,很多组件都被拆分,控制平面中包括 Mixer、Pilot、Auth,数据平面默认是用Envoy;而 Linkerd 中只分为 Linkerd 做数据平面,namerd 作为控制平面。
数据面板由一组智能代理(Envoy)组成,代理部署为边车,调解和控制微服务之间所有的网络通信。
控制面板负责管理和配置代理来路由流量,以及在运行时执行策略。
Istio中Envoy (或者说数据面板)扮演的角色是底层干活的民工,而该让这些民工如何工作,由包工头控制面板来负责完成。
控制平面的特点:
不直接解析数据包
与控制平面中的代理通信,下发策略和配置
负责网络行为的可视化
通常提供API或者命令行工具可用于配置版本化管理,便于持续集成和部署
数据平面的特点:
通常是按照无状态目标设计的,但实际上为了提高流量转发性能,需要缓存一些数据,因此无状态也是有争议的
直接处理入站和出站数据包,转发、路由、健康检查、负载均衡、认证、鉴权、产生监控数据等
对应用来说透明,即可以做到无感知部署
Istio的这个架构设计,将底层Service Mesh的具体实现,和Istio核心的控制面板拆分开。从而使得Istio可以借助成熟的Envoy快速推出产品,未来如果有更好的Service Mesh方案也方便集成。
Pilot负责收集和验证配置并将其传播到各种Istio组件。
它从Mixer和Envoy中抽取环境特定的实现细节,为他们提供独立于底层平台的用户服务的抽象表示。此外,流量管理规则(即通用4层规则和7层HTTP/gRPC路由规则)可以在运行时通过Pilot进行编程。

Istio的工作机制和架构,分为控制面和数据面两部分。可以看到,控制面主要包括Pilot、Mixer、Citadel等服务组件;数据面由伴随每个应用程序部署的代理程序Envoy组成,执行针对应用程序的治理逻辑。带圆圈的数字代表在数据面上执行的若干重要动作。虽然从时序上来讲,控制面的配置在前,数据面执行在后。
(1)自动注入:指在创建应用程序时自动注入 Sidecar代理。在 Kubernetes场景下创建 Pod时,Kube-apiserver调用管理面组件的 Sidecar-Injector服务,自动修改应用程序的描述信息并注入Sidecar。在真正创建Pod时,在创建业务容器的同时在Pod中创建Sidecar容器。
(2)流量拦截:在 Pod 初始化时设置 iptables 规则,当有流量到来时,基于配置的iptables规则拦截业务容器的Inbound流量和Outbound流量到Sidecar上。应用程序感知不到Sidecar的存在,还以原本的方式进行互相访问。在图2-1中,流出frontend服务的流量会被 frontend服务侧的 Envoy拦截,而当流量到达forecast容器时,Inbound流量被forecast服务侧的Envoy拦截。
3)服务发现:服务发起方的 Envoy 调用管理面组件 Pilot 的服务发现接口获取目标服务的实例列表。在图 2-1 中,frontend 服务侧的 Envoy 通过 Pilot 的服务发现接口得到forecast服务各个实例的地址,为访问做准备。
(4)负载均衡:服务发起方的Envoy根据配置的负载均衡策略选择服务实例,并连接对应的实例地址。在图2-1中,数据面的各个Envoy从Pilot中获取forecast服务的负载均衡配置,并执行负载均衡动作。
(5)流量治理:Envoy 从 Pilot 中获取配置的流量规则,在拦截到 Inbound 流量和Outbound 流量时执行治理逻辑。在图 2-1 中,frontend 服务侧的 Envoy 从 Pilot 中获取流量治理规则,并根据该流量治理规则将不同特征的流量分发到forecast服务的v1或v2版本。当然,这只是Istio流量治理的一个场景,更丰富的流量治理能力后续讲解。
(6)访问安全:在服务间访问时通过双方的Envoy进行双向认证和通道加密,并基于服务的身份进行授权管理。在图2-1中,Pilot下发安全相关配置,在frontend服务和forecast服务的Envoy上自动加载证书和密钥来实现双向认证,其中的证书和密钥由另一个管理面组件Citadel维护。
(7)服务遥测:在服务间通信时,通信双方的Envoy都会连接管理面组件Mixer上报访问数据,并通过Mixer将数据转发给对应的监控后端。在图2-1中,frontend服务对forecast服务的访问监控指标、日志和调用链都可以通过这种方式收集到对应的监控后端。
(8)策略执行:在进行服务访问时,通过Mixer连接后端服务来控制服务间的访问,判断对访问是放行还是拒绝。在图2-1中,Mixer后端可以对接一个限流服务对从frontend服务到forecast服务的访问进行速率控制。
(9)外部访问:在网格的入口处有一个Envoy扮演入口网关的角色。在图2-1中,外部服务通过Gateway访问入口服务 frontend,对 frontend服务的负载均衡和一些流量治理策略都在这个Gateway上执行。
这里总结在以上过程中涉及的动作和动作主体,可以将其中的每个过程都抽象成一句话:服务调用双方的Envoy代理拦截流量,并根据管理面的相关配置执行相应的治理动作,这也是Istio的数据面和控制面的配合方式。
Pilot负责在Istio服务网格中部署的Envoy实例的生命周期。
Envoy API负责和Envoy的通讯, 主要是发送服务发现信息和流量控制规则给Envoy
Envoy提供服务发现,负载均衡池和路由表的动态更新的API。这些API将Istio和Envoy的实现解耦。
Polit定了一个抽象模型,以从特定平台细节中解耦,为跨平台提供基础
Platform Adapter则是这个抽象模型的现实实现版本, 用于对接外部的不同平台
最后是 Rules API,提供接口给外部调用以管理Pilot,包括命令行工具Istioctl以及未来可能出现的第三方管理界面
服务规范和实现
Pilot架构中, 最重要的是Abstract Model和Platform Adapter,我们详细介绍。
Abstract Model:是对服务网格中“服务”的规范表示,即定义在istio中什么是服务,这个规范独立于底层平台。。
Platform Adapter:这里有各种平台的实现,目前主要是Kubernetes,另外最新的0.2版本的代码中出现了Consul和Eureka。
暂时而言(当前版本是0.1.6, 0.2版本尚未正式发布),目前 Istio 只支持K8s一种服务发现机制。
Mixer的功能
Mixer 提供三个核心功能:
前提条件检查。允许服务在响应来自服务消费者的传入请求之前验证一些前提条件。前提条件包括认证,黑白名单,ACL检查等等。
配额管理。使服务能够在多个维度上分配和释放配额。典型例子如限速。
遥测报告。使服务能够上报日志和监控。
在Istio内,Envoy重度依赖Mixer。
数据平面-Envoy
Istio 作为控制平面,在每个服务中注入一个 Envoy 代理以 Sidecar 形式运行来拦截所有进出服务的流量,同时对流量加以控制。所以我们需要关心的是istio是如何进行Sidecar 注入到应用pod中的。下面我们就来了解一下
Sidecar 模式
什么是 Sidecar 模式
将应用程序的功能划分为单独的进程可以被视为 Sidecar 模式。Sidecar 设计模式允许你为应用程序添加许多功能,而无需额外第三方组件的配置和代码。
就如 Sidecar 连接着摩托车一样,类似地在软件架构中, Sidecar 应用是连接到父应用并且为其扩展或者增强功能。Sidecar 应用与主应用程序松散耦合。
让我用一个例子解释一下。想象一下假如你有6个微服务相互通信以确定一个包裹的成本。
每个微服务都需要具有可观察性、监控、日志记录、配置、断路器等功能。所有这些功能都是根据一些行业标准的第三方库在每个微服务中实现的。
但再想一想,这不是多余吗?它不会增加应用程序的整体复杂性吗?
Sidecar模式是一种设计模式,它将应用程序的一部分功能从主应用程序中剥离出来,作为单独的进程运行。这个被剥离出来的部分被称为Sidecar。Sidecar与主应用程序运行在同一个主机上,并通过本地网络进行通信。这种模式的出现,主要是为了解决微服务架构中的一些问题。
在微服务架构中,服务间的通信是一个重要的问题。由于服务数量众多,且每个服务都可能有多个实例,因此服务间的通信复杂度很高。Sidecar模式通过将一部分功能剥离出来,作为独立的进程运行,可以简化服务间的通信。同时,由于Sidecar与主应用程序运行在同一个主机上,因此它们之间的通信效率也很高。
Sidecar模式的一个典型应用场景是在云原生环境中。在云原生环境中,每个应用程序都被打包成一个独立的容器,并运行在Kubernetes等容器编排平台上。通过Sidecar模式,可以在每个应用程序的容器中运行一个独立的Sidecar容器,用于实现一些通用的功能,如日志收集、监控、服务注册与发现等。这样,每个应用程序就只需要关注自己的业务逻辑,而不需要关心这些通用功能的实现。
总的来说,Sidecar模式是一种很有用的设计模式,它可以简化微服务架构中的服务间通信,提高通信效率,同时也可以简化应用程序的开发和运维工作。
使用 Sidecar 模式的优势
- 通过抽象出与功能相关的共同基础设施到一个不同层降低了微服务代码的复杂度。
- 因为你不再需要编写相同的第三方组件配置文件和代码,所以能够降低微服务架构中的代码重复度。
- 降低应用程序代码和底层平台的耦合度。
Sidecar 模式如何工作
使用 Sidecar 模式部署服务网格时,无需在节点上运行代理(因此您不需要基础结构的协作),但是集群中将运行多个相同的 Sidecar 副本。从另一个角度看:我可以将一组微服务部署到一个服务网格中,你也可以部署一个有特定实现的服务网格。在 Sidecar 部署方式中,你会为每个应用的容器部署一个伴生容器。Sidecar 接管进出应用容器的所有流量。在 Kubernetes 的 Pod 中,在原有的应用容器旁边运行一个 Sidecar 容器,可以理解为两个容器共享存储、网络等资源,可以广义的将这个注入了 Sidecar 容器的 Pod 理解为一台主机,两个容器共享主机资源。
Sidecar 注入详解
在讲解 Istio 如何将 Envoy 代理注入到应用程序 Pod 中之前,我们需要先了解以下几个概念:
- Sidecar 模式:容器应用模式之一,Service Mesh 架构的一种实现方式。
- Init 容器:Pod 中的一种专用的容器,在应用程序容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本。
- iptables:流量劫持是通过 iptables 转发实现的。
Sidecar 注入详解
在讲解 Istio 如何将 Envoy 代理注入到应用程序 Pod 中之前,我们需要先了解以下几个概念:
- Sidecar 模式:容器应用模式之一,Service Mesh 架构的一种实现方式。
- Init 容器:Pod 中的一种专用的容器,在应用程序容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本。
- iptables:流量劫持是通过 iptables 转发实现的。
Init 容器
Init 容器是一种专用容器,它在应用程序容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本。
一个 Pod 中可以指定多个 Init 容器,如果指定了多个,那么 Init 容器将会按顺序依次运行。只有当前面的 Init 容器必须运行成功后,才可以运行下一个 Init 容器。当所有的 Init 容器运行完成后,Kubernetes 才初始化 Pod 和运行应用容器。
Init 容器使用 Linux Namespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问 Secret 的权限,而应用程序容器则不能。
在 Pod 启动过程中,Init 容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出。如果由于运行时或失败退出,将导致容器启动失败,它会根据 Pod 的 restartPolicy 指定的策略进行重试。然而,如果 Pod 的 restartPolicy 设置为 Always,Init 容器失败时会使用 RestartPolicy 策略。
在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态。Init 容器的端口将不会在 Service 中进行聚集。 正在初始化中的 Pod 处于 Pending 状态,但应该会将 Initializing 状态设置为 true。Init 容器运行完成以后就会自动终止。
这里举一个简单的例子
我们部署一个简单的容器,在其中添加了两个init容器,这两个容器init1-container解析myservice域名(服务),如果不能解析(也就是服务没有部署),则会循环打印,不结束。这样后面的init容器和应用容器也就不会部署。
-----------------------------------------------------------------
参考:Istio原理及介绍 - 简书 (jianshu.com)
连接、安全加固、控制和观察服务的开放平台, 开放平台就是指它本身是开源的,服务对应的是微服务,也可以粗略地理解为单个应用。
中间的四个动词就是 Istio 的主要功能,官方也各有一句话的说明。这里再阐释一下:
- 连接(Connect):智能控制服务之间的调用流量,能够实现灰度升级、AB 测试和红黑部署等功能
- 安全加固(Secure):自动为服务之间的调用提供认证、授权和加密。
- 控制(Control):应用用户定义的 policy,保证资源在消费者中公平分配。
- 观察(Observe):查看服务运行期间的各种数据,比如日志、监控和 tracing,了解服务的运行情况。
什么是 Service Mesh
简单来说,网络代理可以简单类比成现实生活中的中介,本来需要通信的双方因为各种原因在中间再加上一道关卡。本来双方就能完成的通信,为何非要多此一举呢?
那是因为代理可以为整个通信带来更多的功能,比如:
- 拦截:代理可以选择性拦截传输的网络流量,比如一些公司限制员工在上班的时候不能访问某些游戏或者电商网站,再比如把我们和世界隔离开来的 GFW,还有在数据中心中拒绝恶意访问的网关。
- 统计:既然所有的流量都经过代理,那么代理也可以用来统计网络中的数据信息,比如了解哪些人在访问哪些网站,通信的应答延迟等。
- 缓存:如果通信双方比较”远“,访问比较慢,那么代理可以把最近访问的数据缓存在本地,后面的访问不用访问后端来做到加速。CDN 就是这个功能的典型场景。
- 分发:如果某个通信方有多个服务器后端,代理可以根据某些规则来选择如何把流量发送给多个服务器,也就是我们常说的负载均衡功能,比如著名的 Nginx 软件。
- 跳板:如果 A、B 双方因为某些原因不能直接访问,而代理可以和双方通信,那么通过代理,双方可以绕过原来的限制进行通信。这应该是广大中国网民比较熟悉的场景。
- 注入:既然代理可以看到流量,那么它也可以修改网络流量,可以自动在收到的流量中添加一些数据,比如有些宽带提供商的弹窗广告。
Service Mesh 可以看做是传统代理的升级版,用来解决现在微服务框架中出现的问题,可以把 Service Mesh 看做是分布式的微服务代理。
在传统模式下,代理一般是集中式的单独的服务器,所有的请求都要先通过代理,然后再流入转发到实际的后端。
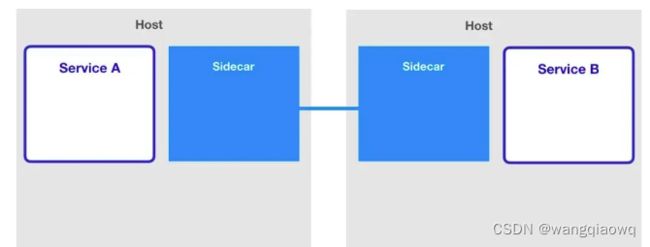
而在 Service Mesh 中,代理变成了分布式的,它常驻在了应用的身边(最常见的就是 Kubernetes Sidecar 模式,每一个应用的 Pod 中都运行着一个代理,负责流量相关的事情)。
这样的话,应用所有的流量都被代理接管,那么这个代理就能做到上面提到的所有可能的事情,从而带来无限的想象力。
Service Mesh 中,代理会知道整个集群的所有应用信息,并且额外添加了热更新、注入服务发现、降级熔断、认证授权、超时重试、日志监控等功能,让这些通用的功能不必每个应用都自己实现,放在代理中即可。
换句话说,Service Mesh 中的代理对微服务中的应用做了定制化的改进!

借着微服务和容器化的东风,传统的代理摇身一变,成了如今炙手可热的 Service Mesh
应用微服务之后,每个单独的微服务都会有很多副本,而且可能会有多个版本,这么多微服务之间的相互调用和管理非常复杂,但是有了 Service Mesh,我们可以把这块内容统一在代理层。

有了看起来四通八达的分布式代理,我们还需要对这些代理进行统一的管理。
手动更新每个代理的配置,对代理进行升级或者维护是个不可持续的事情,在前面的基础上,在加上一个控制中心,一个完整的 Service Mesh 就成了。
管理员只需要根据控制中心的 API 来配置整个集群的应用流量、安全规则即可,代理会自动和控制中心打交道根据用户的期望改变自己的行为。
NOTE:所以你也可以理解 Service Mesh 中的代理会抢了 Nginx 的生意,这也是为了 Nginx 也要开始做 NginMesh 的原因。
Istio 官方给出的架构图:

Istio 就是我们上述提到的 Service Mesh 架构的一种实现,服务之间的通信(比如这里的 Service A 访问 Service B)会通过代理(默认是 Envoy)来进行。而且中间的网络协议支持 HTTP/1.1,HTTP/2,gRPC 或者 TCP,可以说覆盖了主流的通信协议。
控制中心做了进一步的细分,分成了 Pilot、Mixer 和 Citadel,它们的各自功能如下:
- Pilot:为 Envoy 提供了服务发现,流量管理和智能路由(AB 测试、金丝雀发布等),以及错误处理(超时、重试、熔断)功能。 用户通过 Pilot 的 API 管理网络相关的资源对象,Pilot 会根据用户的配置和服务的信息把网络流量管理变成 Envoy 能识别的格式分发到各个 Sidecar 代理中。
- Mixer:为整个集群执行访问控制(哪些用户可以访问哪些服务)和 Policy 管理(Rate Limit,Quota 等),并且收集代理观察到的服务之间的流量统计数据。
- Citadel:为服务之间提供认证和证书管理,可以让服务自动升级成 TLS 协议。
代理会和控制中心通信,一方面可以获取需要的服务之间的信息,另一方面也可以汇报服务调用的 Metrics 数据。
知道了 Istio 的核心架构,再来看看它的功能描述就非常容易理解了:
- 连接:控制中心可以从集群中获取所有服务的信息,并分发给代理,这样代理就能根据用户的期望来完成服务之间的通信(自动地服务发现、负载均衡、流量控制等)。
- 安全加固:因为所有的流量都是通过代理的,那么代理接收到不加密的网络流量之后,可以自动做一次封装,把它升级成安全的加密流量。
- 控制:用户可以配置各种规则(比如 RBAC 授权、白名单、Rate Limit 或者 Quota 等),当代理发现服务之间的访问不符合这些规则,就直接拒绝掉。
- 观察:所有的流量都经过代理,因此代理对整个集群的访问情况知道得一清二楚,它把这些数据上报到控制中心,那么管理员就能观察到整个集群的流量情况了
Istio 解决什么问题
首先,原来的单个应用拆分成了许多分散的微服务,它们之间相互调用才能完成一个任务,而一旦某个过程出错(组件越多,出错的概率也就越大),就非常难以排查。
用户请求出现问题无外乎两个问题:错误和响应慢。如果请求错误,那么我们需要知道那个步骤出错了,这么多的微服务之间的调用怎么确定哪个有调用成功?哪个没有调用成功呢?
如果是请求响应太慢,我们就需要知道到底哪些地方比较慢?整个链路的调用各阶段耗时是多少?哪些调用是并发执行的,哪些是串行的?这些问题需要我们能非常清楚整个集群的调用以及流量情况。

此外,微服务拆分成这么多组件,如果单个组件出错的概率不变,那么整体有地方出错的概率就会增大。服务调用的时候如果没有错误处理机制,那么会导致非常多的问题。
比如如果应用没有配置超时参数,或者配置的超时参数不对,则会导致请求的调用链超时叠加,对于用户来说就是请求卡住了。
如果没有重试机制,那么因为各种原因导致的偶发故障也会导致直接返回错误给用户,造成不好的用户体验。
此外,如果某些节点异常(比如网络中断,或者负载很高),也会导致应用整体的响应时间变长,集群服务应该能自动避开这些节点上的应用。
最后,应用也是会出现 Bug 的,各种 Bug 会导致某些应用不可访问。这些问题需要每个应用能及时发现问题,并做好对应的处理措施。

应用数量的增多,对于日常的应用发布来说也是个难题。应用的发布需要非常谨慎,如果应用都是一次性升级的,出现错误会导致整个线上应用不可用,影响范围太大。
而且,很多情况我们需要同时存在不同的版本,使用 AB 测试验证哪个版本更好。
如果版本升级改动了 API,并且互相有依赖,那么我们还希望能自动地控制发布期间不同版本访问不同的地址。这些问题都需要智能的流量控制机制。

为了保证整个系统的安全性,每个应用都需要实现一套相似的认证、授权、HTTPS、限流等功能。这个问题需要一个能自动管理安全相关内容的系统。

用什么姿势接入 Istio?
一般情况下,集群管理团队需要对 Kubernetes 非常熟悉,了解常用的使用模式,然后采用逐步演进的方式把 Istio 的功能分批掌控下来。
第一步,自然是在测试环境搭建一套 Istio 的集群,理解所有的核心概念和组件。
了解 Istio 提供的接口和资源,知道它们的用处,思考如何应用到自己的场景中,然后是熟悉 Istio 的源代码,跟进社区的 Issues,了解目前还存在的 Issues 和 Bug,思考如何规避或者修复。
第二步,可以考虑接入 Istio 的观察性功能,包括 Logging、Tracing、Metrics 数据。
应用部署到集群中,选择性地(一般是流量比较小,影响范围不大的应用)为一些应用开启 Istio 自动注入功能,接管应用的流量,并安装 Prometheus 和 Zipkin 等监控组件,收集系统所有的监控数据。
这一步可以试探性地了解 Istio 对应用的性能影响,同时建立服务的性能测试基准,发现服务的性能瓶颈,帮助快速定位应用可能出现的问题。
第三步,为应用配置 Time Out 超时参数、自动重试、熔断和降级等功能,增加服务的容错性。
第四步,和 Ingress、Helm、应用上架等相关组件和流程对接,使用 Istio 接管应用的升级发布流程。
让开发者可以配置应用灰度发布升级的策略,支持应用的蓝绿发布、金丝雀发布以及 AB 测试。
第五步,接入安全功能。配置应用的 TLS 互信,添加 RBAC 授权,设置应用的流量限制,提升整个集群的安全性。
总结
Istio 的架构在数据中心和集群管理中非常常见,每个 Agent 分布在各个节点上(可以是服务器、虚拟机、Pod、容器)负责接收指令并执行,以及汇报信息。
控制中心负责汇聚整个集群的信息,并提供 API 让用户对集群进行管理。
Istio 的出现为负责的微服务架构减轻了很多的负担,开发者不用关心服务调用的超时、重试、Rate Limit 的实现,服务之间的安全、授权也自动得到了保证。
集群管理员也能够很方便地发布应用(AB 测试和灰度发布),并且能清楚看到整个集群的运行情况。
但是这并不表明有了 Istio 就可以高枕无忧了,Istio 只是把原来分散在应用内部的复杂性统一抽象出来放到了统一的地方,并没有让原来的复杂消失不见。
因此我们需要维护 Istio 整个集群,而 Istio 的架构比较复杂,尤其是它一般还需要架在 Kubernetes 之上,这两个系统都比较复杂,而且它们的稳定性和性能会影响到整个集群。
因此再采用 Isito 之前,必须做好清楚的规划,权衡它带来的好处是否远大于额外维护它的花费,需要有相关的人才对整个网络、Kubernetes 和 Istio 都比较了解才行。
------------------------------------------------------------------------------------------------------------
参考:【译】为什么有Kubernetes了还要Istio? - 哔哩哔哩 (bilibili.com)
K8s对于基于声明式配置的应用生命周期管理是必须的,Istio对于应用内流量治理,安全治理和可观察性是必须的。如果你已经用K8s构建了一个稳定的应用,你如何在两个服务之间配置一个负载均衡和流控,这时我们就需要Istio登场了。
Envoy引入的xDS协议,被众多开源软件支持,比如,Istio,MOSN,etc。Istio提出xDS作为ServiceMesh,云原生组件。Envoy能胜任可基于API配置的,多种现代的代理场景,如API网关,ServiceMesh代理网关,边界网关。
Kubernetes vs Service Mesh
下面的示意图K8s和ServiceMesh(每Pod1sidecar模型)在服务访问上的区别。

流量转发
每个K8s的节点都部署了一个可以和APIServer通信的kube-proxy,获取集群信息,配置iptables,把请求直接发给EndPoint。
服务发现

Istio可以使用K8s的服务注册,也可以通过控制面的适配器对接其他服务发现系统生成数据面的透明代理的配置(作为CRD保存在etcd中)。数据面的透明代理作为边车容器部署在每个应用的Pod中,所有这些边车容器都会请求控制面来同步代理配置。这里说代理是“透明”的,是因为应用容器完全感觉不到代理的存在。kube-proxy组件也需要拦截流量,区别在于kube-proxy拦截进出K8s Node的流量,而边车代理是拦截进出Pod的流量。
ServiceMesh的缺点
当K8s每个节点都跑了大量Pod时,给每个Pod添加原始路由转发将会增加响应的延迟,这是因为边车拦截带来了更多的跳数也消耗了更多资源。为了细粒度管理流量,Istio引入了一系列抽象,这会带来更多的学习成本,但是随着Istio逐渐流行,这个情况会缓解。
ServiceMesh的优点
首先,kube-proxy的配置是全局的,不能从服务的粒度管理,然而,Istio基于边车代理能做到更细的流量管理,带来更多弹性。
Kube-proxy的缺点
首先,当某个Pod不能正常工作时,它不会自动尝试另一个Pod。每个Pod都有健康检查机制,当Pod健康检查出问题时,kubelet将会重启Pod,kube-proxy将会移除相关转发规则。此外,NodePort模式的Service不支持TLS,或者其他更负责的路由机制。
kube-proxy实现同一个Service的多个Pod之间的负载均衡。但是你怎么做多个Service之间的细粒度管理,比如根据应用的版本,按照百分比切分流量(他们都是同一个Service,但是不同的部署)或者做金丝雀发布(灰度发布)或者蓝绿发布?
Kubernetes社区给出了一种方式来用部署做金丝雀发布:本质上就是通过给部署的Pod打标签。
Kubernetes Ingress vs. Istio Gateway
kube-proxy只能路由K8s集群内的流量。K8s的Pod是通过CNI创建的网络中定位的。Ingress 是专门用于和集群外通信的K8s中的资源对象,是由位于K8s边缘节点的Ingress控制器来驱动的,负责管理南北流量。Ingress必须依赖Ingress控制器,比如nginx controller和 traefik。Ingress只适配Http流量,非常简单易用。它只能通过匹配有限的几个字段来路由流量,比如service,port,path等。路由比如mysql,redis和其他rpc等tcp流量是不可能的。这就是为何你在ingress资源注解中别人会写nginx配置语言。直接路由南北流量的唯一方式就是使用Service的LoadBalancer模式或者NodePort模式,前者依赖云供应商的支持,后者需要额外的端口管理。
Istio Gateway功能上和Ingress 类似,那就是负责南北向流量进出集群。Istio Gateway规范描述了负责在网格边缘接收链接的负载均衡。规范还描述了一系列端口和使用这些端口的协议,比如负载均衡的SNI配置。Gateway是CRD扩展也服用了边车代理的能力
Envoy
Envoy是Istio的默认边车代理。Istio扩展了其基于xDS控制面的协议。

基本术语
下游(Downstream)下游Host链接Envoy,发送请求,接收响应;就是我们发送请求的Host。
上游(Upstream)上游接收来自Envoy的链接和请求,返回响应;也就是接收请求的Host。
监听器(Listener)listener是实名网络地址(比如端口,unix domain socket)下游客户端能链接监听器,Envoy会暴露一两个监听器给下游Host来连接。
集群(Cluster)一个集群是一组供Envoy连接的逻辑独立的上游Host。Envoy通过服务发现发现集群的成员。集群的成员的健康状态由主动健康检查决定,Envoy根据负责均衡策略决定路由到集群那个成员。
Envoy可以配置多个Listener,每个Listener可以配置一个过滤器链,过滤器链是可扩展的,我们可以简单的修改流量的行为,比如加密和私有rpc等。
xDS协议是Envoy提议的,是Istio默认边车代理,但是只要实现了xDS协议,那它理论上就能当作Istio的边车代理,比如蚂蚁集群开源的MOSN。

Istio是功能丰富的ServiceMesh,包含如下能力:
流量治理:Istio最基本的功能
策略控制:访问控制,遥测,配额管理,账单。
可观察性:在边车代理中实现。
安全认证:Citadel组件负责key和证书管理。
Istio的流量治理
下面的CRD是Istio用来做流量治理的:
Gateway:描述了一个运行在边缘网络的负载均衡器用来接收入站出站的TCP,Http连接。
VirtualService:实际上把Gateway和K8s Service 连接到一起。还提供了额外的操作:比如定义一组能应用于某个Host上的流量路由规则。
DestinationRule:DestinationRule定义了路由后的流量策略。简单来说,它定义了流量是如何路由的。此外还能定义负载均衡策略,连接池大小,还有一些探测(比如从连接池中移除不健康的节点)。
EnvoyFilter:此配置描述了proxy的过滤器,一般由pilot自动生成,通常很少有用户会用到。
ServiceEntry:默认情况下,Istio ServiceMesh中的Service没有能力对mesh外部做服务发现。ServiceEntry允许额外的服务加入到Isito的服务注册中来,并允许mesh内自动发现的服务访问并路由那些手动加入的service。
Kubernetes vs. xDS vs. Istio
k8s kube-proxy,xDS, and Istio组件的流量治理抽象后,我们来对比下流量治理这方面三者的组件,协议

总结
k8s的职责在于应用的生命周期管理,尤其是部署和管理(扩展,自动回复,释放)。
k8s为微服务提供了一个可扩展,高可靠的部署管理平台。
service mesh是基于透明代理的,在服务之间通过边车拦截流量,通过控制面管理流量的。
service mesh将流量治理从k8s中解耦出来,消除了service mesh内流量治理对于kube-proxy的依赖;通过提供更接近微服务应用层的抽象,来管理Service的流量,安全,可观察性。
xDS是ServiceMesh配置的标准协议之一。
ServiceMesh是K8s的服务的更高层次的抽象。
结论
如果说K8s管理的对象是Pod,那么ServiceMesh管理的对象就是Service,实际上就是K8s来管理微服务在上层应用ServiceMesh。