Class 09 - Data Frame和查看数据
Class 09 - Data Frame和查看数据
-
- DataFrame
- tibbles
- head()
- str()
- colnames()
- mutate()
- 创建 Dataframe
DataFrame
在我们开始做数据清洗或者检查数据是否存在偏差之前,我们需要先将我们的数据转换成合适的格式方便我们做后续的处理。
这就要说到DataFrame了。因为他很像电子表格或 SQL 表。
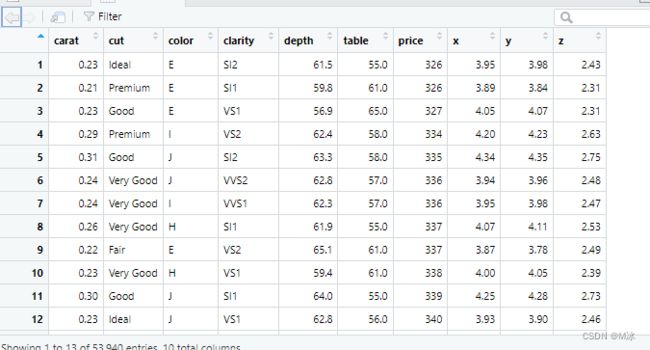
这是 R 中通过view来显示的DataFrame的示例:
-
有列、行和带有数据的单元格。
-
列包含一个变量,行具有一组与每一列匹配的值。
-
每一列中的数据都是相同的数据类型。
其实把他当成一个表格来理解就可以了
tibbles
tidyverse 可以使处理数据变得更容易
-
首先,tibbles 永远不会改变输入的数据类型。 他们不会将您的字符串更改为因子或其他任何内容。 Tibbles 也从不更改变量的名称,并且从不创建行名称。
-
tibbles 使 R 中的打印更容易。 它们不会意外地使您的控制台超载,因为它们会自动设置为仅拉出前 10 行和适合屏幕的尽可能多的列。 在处理大量数据时非常有用。
下面我们使用diamonds数据集,来演示。 该数据集是 tidyverse 中 ggplot2 包的一部分。 所以可以首先加载 ggplot2。如果没有安装的ggplot2,可以使用 install.packages(ggplot2 )来进行安装就可以找到diamonds数据集了。
# 加载包
library(ggplot2)
# 加载数据集
data(diamonds)
# 查看数据集
diamonds
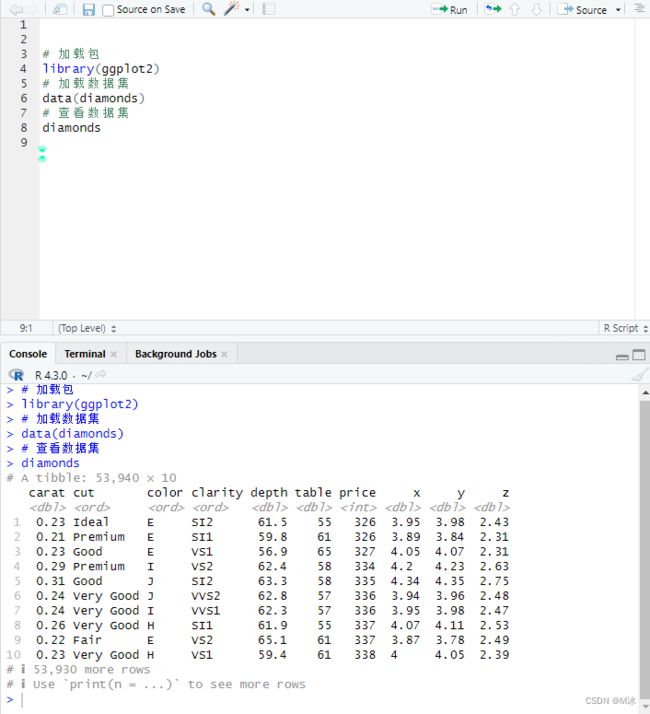
可以看到,这个数据集包含53930行和10个列。
由于之前已经安装过tidyverse 功能包,RStudio默认使用tibbles来输出数据,所以我们看到的数据之显示了前10行的数据。
head()
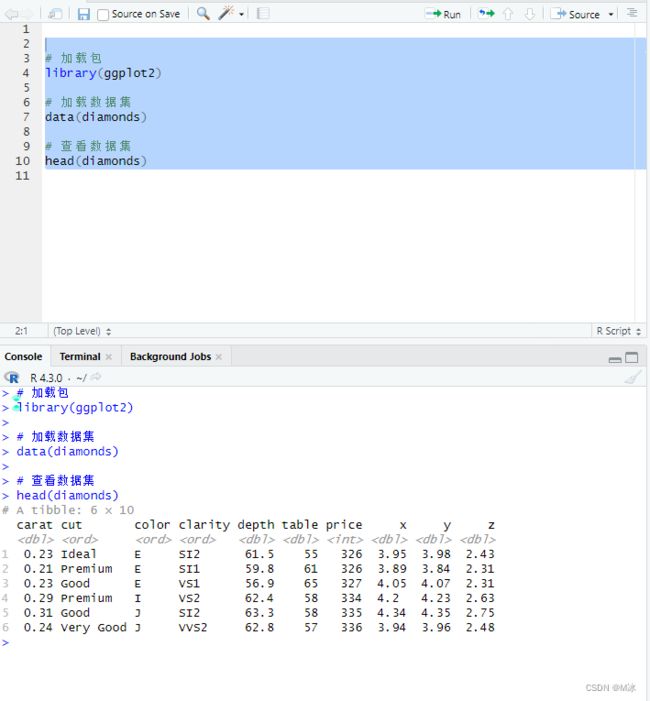
一般在导入数据之后,都会习惯的查看一下导入的数据是否是正确的。
这时候可以使用head()函数,他会之输出数据的前6行。这样浏览起来会更便捷一些。
# 加载包
library(ggplot2)
# 加载数据集
data(diamonds)
# 查看数据集
head(diamonds)
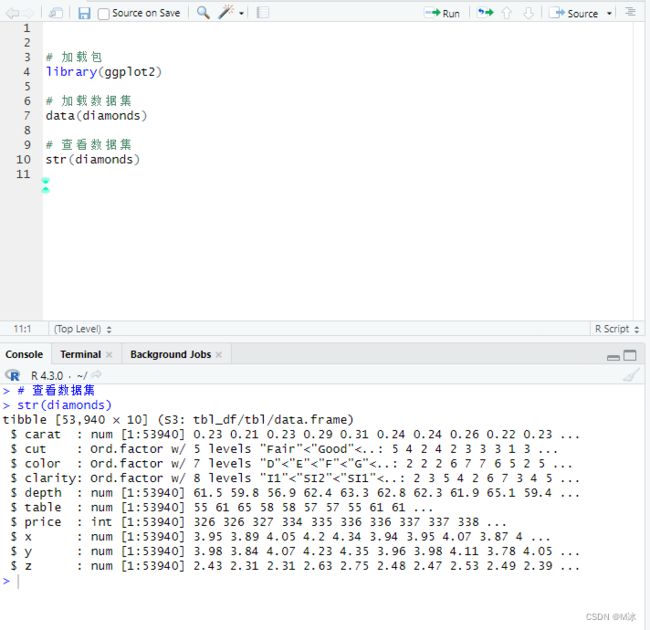
str()
str()函数可以帮我们查看Dataframe中,每一列数据的数据类型,因子,包含的不同数据内容,以一个类似横向表的方式来展示。
# 加载包
library(ggplot2)
# 加载数据集
data(diamonds)
# 查看数据集
str(diamonds)
colnames()
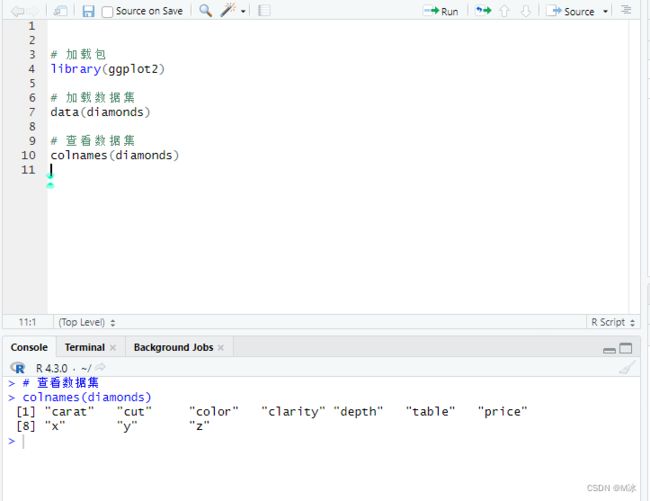
当我们只需要查看每一列的名字,或者需要提取每一列的列名的时候,可以使用colnames()函数来提取每一列的名字。
# 加载包
library(ggplot2)
# 加载数据集
data(diamonds)
# 查看数据集
colnames(diamonds)
mutate()
mutate() 函数可以很便捷的帮我们在Dataframe中创建新的列,比如需要对现有的某一列数据进行计算,但是又不改变原来列中的数据,这时候就需要我们在数据中添加一个新的列来储存计算后的新数据。
mutate() 是 tidyverse 中 dplyr 包的一部分。 因此,在使用mutate() 之前,需要先加载 tidyverse 功能包。
例如,添加一个新列new_clo。 我们需要做的就是输入 mutate(),然后括号中先传入数据集diamonds的名称,然后再输入创建新列的名new_clo 并用=链接计算表达式z*100,中间用逗号分隔。
# 加载包
library(tidyverse)
# 加载数据集
data(diamonds)
# 查看数据集
mutate(diamonds,new_clo = z*100)
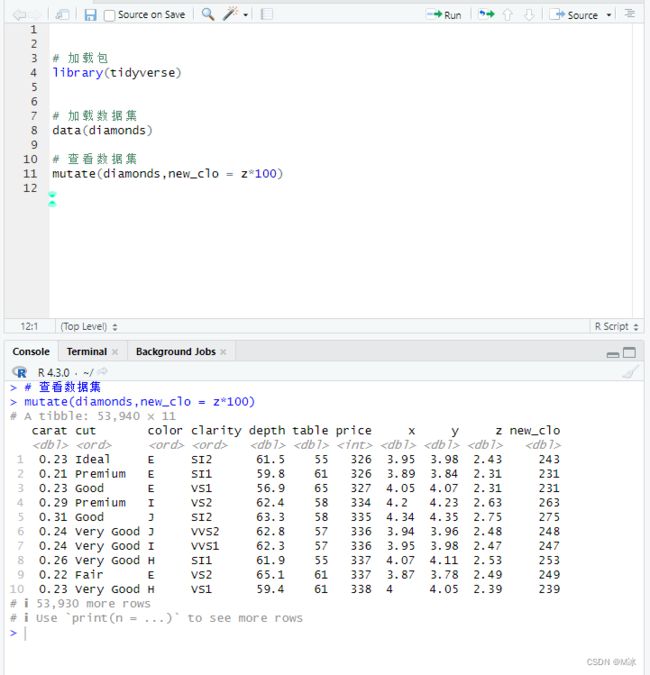
在最右侧的一列就是我们新添加的列new_clo。
添加新的列,一般都是默认添加到末尾最右侧。
创建新列时不会丢失任何列。 数据的其余部分仍然相同。
创建 Dataframe
在R语言中如何创建Dataframe格式数据呢?
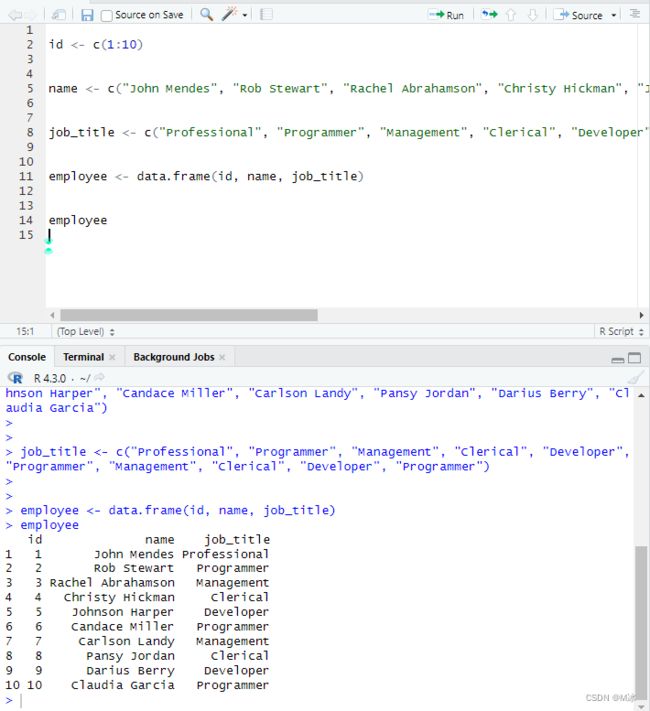
只需要先创建机组不同的数据,数组的长度要一致,然后通过data.frame()函数,把他们组合到一起就完成了。
举个例子:
# 创建id
id <- c(1:10)
# 创建名字
name <- c("John Mendes", "Rob Stewart", "Rachel Abrahamson", "Christy Hickman", "Johnson Harper", "Candace Miller", "Carlson Landy", "Pansy Jordan", "Darius Berry", "Claudia Garcia")
# 创建职位名称
job_title <- c("Professional", "Programmer", "Management", "Clerical", "Developer", "Programmer", "Management", "Clerical", "Developer", "Programmer")
# 创建为Dataframe
employee <- data.frame(id, name, job_title)
# 查看数据
employee