payara micro开发指南
微服务与payara
在Java世界内部,Spring框架已成为微服务开发的事实上的标准,通过诸如Spring Boot和Spring Data之类的库,该框架易于使用,并且可以进行高效且大部分情况下轻松进行开发。
但是,近年来也出现了许多其他的框架,声称可以缩短Java应用程序的启动时间并减少其内存占用。下面将进行简单介绍。
Spring
为了解决早期Java Enterprise的复杂性,Spring于2003年应运而生。Spring核心是依赖注入(DI)和面向切面编程(AOP),后来衍生出易于使用的Spring MVC等Web应用框架。通过其良好的文档,全面的各方面整合类库,Spring使开发人员可以有效地创建和维护应用程序,并提供平坦的学习曲线。
Spring在运行时使用反射执行DI。因此,当启动spring应用程序时,将在类路径中扫描带注解的类。基于此,实例化并链接到具体对象。这种做法非常灵活且对开发人员很友好,但它可能使得启动过程缓慢并占用大量内存。另外,将这种机制迁移到GraalVM非常困难,因为GraalVM不支持反射。
Micronaut
Micronaut是比较新的全栈微服务框架,由Grails框架的创建者于2018年引入。
Micronaut提供了构建功能全面的微服务应用程序所需的所有工具。同时,它旨在提供快速启动并减少内存占用。通过使用Java注解处理器执行DI,创建面向切面的代理(而不是运行时)配置应用程序,可以实现此目标。
Micronaut中的许多API均受Spring和Grails的启发。这无可厚非,毕竟这样有助于快速吸引Spring及Grails的开发人员。Micronaut提供了诸如Micronaut HTTP,数据,安全性和各种其他技术的连接器之类的模块。但是,这些库的成熟度仍落后于Spring的同类库。
Quarkus
Quarkus是Red Hat在2019年引入的Kubernetes原生Java框架。 它基于MicroProfile,Vert.x,Netty和Hibernate等标准构建。
Quarkus的目标是通过在容器编排平台中允许更快的启动,较低的内存消耗和近乎即时的扩展来使Java成为Kubernetes中的领先平台。Quarkus通过使用自定义的Maven插件在编译时而不是在构建时执行尽可能多的工作来达到此目的(在Quarkus中,这也称为编译时启动)。
Quarkus使用了大多数现有的标准技术,而且还支持扩展。但是,由于该项目仅在一年之前才开始,所以这些扩展的成熟度和兼容性还不够。随着平台的发展,这种情况将来可能会改变。
Helidon MicroProfile
MicroProfile项目立项于2016年,与其前身JEE一样,MicroProfile实际上是一种规范,可以由各供应商自由实现。到目前为止,MicroProfile规范已经提出了多种实现方式,最著名的是Payara Micro和Helidon MP。
Payara是从GlassFish派生的Jakarte EE服务器,而Payara Micro是其MicroProfile实现。Helidon是Oracle在2018年启动的运行时,提供了自己的MicroProfile规范实现。
由于它们是从JEE派生的,因此MicroProfile规范已经很成熟并且有据可查。但是,它缺少用于现代技术的连接器或替代,诸如Spring Data和Spring Security之类的库的方法。
此外,由于同时开始了Jakarta EE(也在Eclipse Foundation中)的开发,MicroProfile的未来尚不清楚。因此,似乎两个项目将来可能会合并。
payara micro使用
上文介绍了payara的由来,接下来将继续介绍payara的使用。
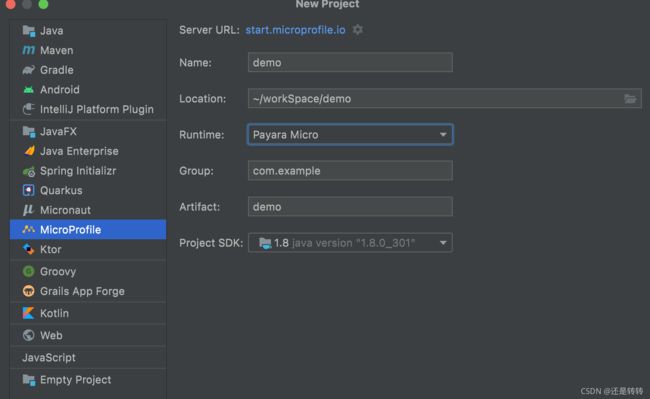
创建Hello World
通过idea创建一个MicroProfile新工程,Runtime选择Payara Micro。如下所示:
 点击next生成示例代码,非常简单,主要类如下所示:
点击next生成示例代码,非常简单,主要类如下所示:

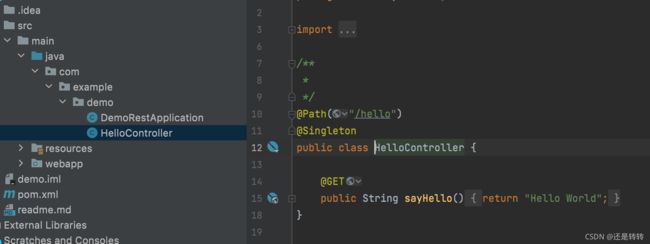
idea生成的代码中有一些空的配置文件,事实上resources和webapp目录下的文件可以直接删掉,只要保留DemoRestApplication和HelloController即可。
依赖包只有一个:org.eclipse.microprofile microprofile 4.0.1 pom provided
运行
- 命令行运行
从官网下载payara micro包,例如payara-micro-5.201.jar。在ternimal中通过java -jar payara-micro-5.201.jar可以将服务器启动起来。
假设有一个web项目,打成war包为SimpleService.war, 则以下命令可以将服务部署到payara中:
java -jar payara-micro-5.201.jar --deploy SimpleService.war
- ide中运行
以idea为例,maven的pom文件中配置打包格式为war,然后创建JAR Application启动配置。
在Path to JAR参数中配置payara的jar包,然后在Program arguments中配置需要部署的war包和其他参数,例如:
--deploy $ProjectFileDir$/target/SimpleService --contextroot tt
表示部署生成目录下的SimpleService的war包,根路径为tt。当然还可以设置其他参数,这里不赘述。
注意,这里不要使用5.2021.x版本来部署服务,否则会报错(原因未知):
Unable to perform operation: resolve on fish.payara.microprofile.faulttolerance.service.FaultToleranceServiceImpl
在地址栏输入http://localhost:8080/tt/data/hello,即可看到结果:
Hello World
基本功能
请求过滤器
通过实现ContainerRequestFilter接口可以对请求进行过滤。如下所示:
@Provider
public class TraceEndpointFilter implements ContainerRequestFilter {
@Override
public void filter(ContainerRequestContext requestContext) throws IOException {
Logger.getLogger(TraceEndpoint.class.getName()).log(Level.INFO, "{0} -> {1}",
new Object[]{requestContext.getMethod(), requestContext.getUriInfo().getPath()});
该过滤器可以对请求进行过滤,打印请求相关信息日志。
使用过滤器类需要注意:
- 过滤器类必须用@Provider注解修饰,这样才会被jax-rs执行。
- 如果没有使用注解@NameBinding,则该过滤器作用域是全局的。
- 如果实现类使用@PreMatching注解,将在请求资源(PUT,GET等方法)之前执行过滤,否则在之后执行过滤。
对于第二点,如果想在特定方法上执行过滤,可以实现一个用@NameBinding标注的自定义注解,然后在过滤器和需要过滤的方法上用该注解进行修饰。如下所示:
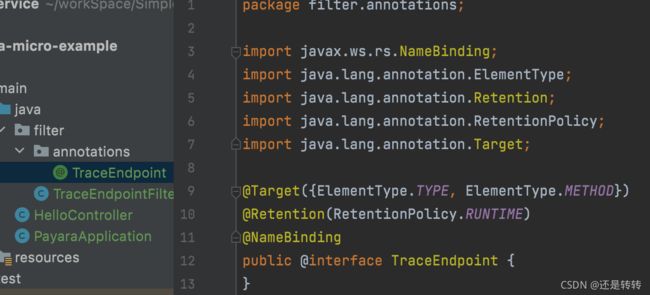

@Path("/hello")
public class HelloController {
@GET
@TraceEndpoint
public String sayHello() {
return "Hello, World!";
}
@GET
@Path("/1")
public String sayHello1() {
return "Hello";
}
}
分别请求两个方法,一个会执行过滤方法,一个不执行。
JPA
引入jakarta依赖包:
jakarta.platform
jakarta.jakartaee-api
8.0.0
provided
通过@PersistenceContext注解引入EntityManager
@ApplicationScoped
public class PersonRepository {
@PersistenceContext(unitName = "SAMPLE_PU")
private EntityManager em;
@Transactional(REQUIRED)
public void create(Person person) {
em.persist(person);
}
public Person find(Long id) {
return em.find(Person.class, id);
}
}
在resources的META-INFO下创建persistence.xml配置文件:
false
然后通过controller进行访问:
@Path("/api/person")
@ApplicationScoped
public class PersonController {
private static final Logger LOG = Logger.getLogger(PersonController.class.getName());
@Inject
private PersonRepository personRepository;
@POST
public Response createPerson(Person person) {
LOG.log(Level.FINE, "rest request to save person : {0}", person);
personRepository.create(person);
return Response.ok(person).build();
}
@GET
@Path("/{id}")
public Response getPerson(@PathParam("id") Long id) {
LOG.log(Level.FINE, "REST request to get Person : {0}", id);
Person person = personRepository.find(id);
if (person == null) {
return Response.status(Response.Status.NOT_FOUND).build();
} else {
return Response.ok(person).build();
}
}
}
这里没有指定具体的数据库,将数据保存到内存中。如果要指定实际的数据库呢?
在persistence.xml文件中persistence-unit节点下添加一行,指定数据源:
java:global/SIMPLE-JPA
然后在webapp目录下WEB-INF文件夹下创建web.xml文件,配置数据源:
java:global/SIMPLE-JPA
org.postgresql.ds.PGConnectionPoolDataSource
localhost
5432
postgres
${dababase.user}
${dababase.password}
person类如下:
@Entity
@Table(name="person")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String address;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "Person{" + "id=" + id + ", name= " + name + ", address=" + address + "}";
}
}
再次调用接口之后,数据就会保存到postgres数据库了。
Spring-data-jpa
首先引入spring-data-jpa的依赖包:
org.springframework.data
spring-data-jpa
2.3.0.RELEASE
org.hibernate
hibernate-core
5.4.15.Final
创建personService和personDao如下:
public class PersonService {
@Inject
private PersonDao personDao;
public void save(Person person) {
personDao.save(person);
}
public Person findById(Long id) {
return personDao.findById(id);
}
}
@Stateless
public class PersonDao {
@Inject
private PersonRepository personRepository;
public void save(Person person) {
personRepository.save(person);
}
public Person findById(Long id) {
return personRepository.findById(id).orElse(null);
}
}
修改personRepository:
@Eager
public interface PersonRepository extends JpaRepository {
}
persistence.xml配置:
org.hibernate.jpa.HibernatePersistenceProvider
java:global/SPRING-DATA
false
在WEB-INF文件夹下创建beans.xml配置文件:
新建实体管理器工厂:
/**
* Factory for Entity Manager.
*/
public class EntityManagerFactory {
@PersistenceContext(unitName = "SAMPLE_PU")
private EntityManager entityManager;
/**
* Get the entity manager.
*
* @return The entity manager.
*/
@Produces
public EntityManager getEntityManager() {
return entityManager;
}
}
然后调用接口即可。
API文档生成
本节其实完全可以是独立的,但api文档管理算是一个基本功能,所以就放进来了。
API文档就跟注释一样,自己讨厌写,但又希望别人写。相比起注释,写API文档甚至还更麻烦一点,因为随着功能的迭代,接口逻辑会发生变更,原来写好的文档可能就不适用了,需要随着代码的更新而更新。
为了减少工作量,可以使用工具,通过代码来生成接口文档,并随着代码的变更而更新,完全自动化生成。这里要介绍的工具是maven-swagger插件。至于什么是swagger,可以看官方文档:https://swagger.io/docs/specification/about/,这里不详细介绍。
以上文中的spring-data-jpa为例,下面介绍api生成插件的使用。
由于本文使用的是jax-rs(Java API for RESTful Web Services),因此使用的是一个支持jax-rs接口的插件:https://github.com/openapi-tools/swagger-maven-plugin。
当然,也可以使用这个插件:https://github.com/kongchen/swagger-maven-plugin,不仅支持jax-rs,还支持springMVC。
如果是Springboot项目,建议使用springdoc-openapi-maven-plugin插件,具体使用方式见官方文档。
在spring-data-jpa的pom文件下配置:
io.openapitools.swagger
swagger-maven-plugin
2.1.6
${project.groupId}.examples.jpa
${basedir}/../api-management/src/main/resources/spring-data-jpa
spring-data-jpa-1.0.0
JSON
true
https://services.exmple.it/base/path
Endpoint URL
spring-data-jpa
1.0.0
API description
[email protected]
My Name
https://google.com
my-custom-field-1
my-custom-field-2
generate-test-resources
generate
该插件会在spring-data-jpa的generate-test-resources阶段执行,根据配置生成api文档。
依赖的swagger包:
io.swagger.core.v3
swagger-annotations
2.1.9
provided
swagger标签如下:
package org.howe.examples.jpa;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.howe.examples.jpa.entity.Person;
import org.howe.examples.jpa.service.PersonService;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import javax.ws.rs.*;
import javax.ws.rs.core.Response;
import java.util.logging.Level;
import java.util.logging.Logger;
@Path("/api/person")
@ApplicationScoped
@Tag(description = "Person API", name = "Person")
public class PersonApi {
private static final Logger LOG = Logger.getLogger(PersonApi.class.getName());
@Inject
private PersonService personService;
@POST
public Response createPerson(Person person) {
LOG.log(Level.FINE, "rest request to save person : {0}", person);
personService.save(person);
return Response.ok(person).build();
}
@GET
@Path("/{id}")
@Operation(summary = "Endpoint that get person")
public Response getPerson(
@PathParam("id")
@Parameter(name = "id") Long id) {
LOG.log(Level.FINE, "REST request to get Person : {0}", id);
Person person = personService.findById(id);
if (person == null) {
return Response.status(Response.Status.NOT_FOUND).build();
} else {
return Response.ok(person).build();
}
}
}
通过maven clean test -f pom.xml来构建项目,在指定的目录生成了api文档,如下所示:
API文档展示
在上一节中介绍了通过swagger插件来生成OpenAPI文档。事实上,即使不使用swagger插件,直接访问http://localhost:8080/openapi/ 接口也可以生成OpenAPI文档。
MicroProfile OpenAPI规范
MicroProfile中的MicroProfile OpenAPI规范扩展了通用OpenAPI规范,并且集成到了MicroProfile应用中。这意味着任何MicroProfile规范的实现都必须拥有/openapi 这个终端,并且通过它来提供OpenAPI文档,而OpenAPI文档实际上就是通过部署的应用来生成的。当你部署一个应用时,OpenAPI文档将根据应用的内容来自动生成[2]。
以上文中的spring-data-jpa为例,启动后访问http://localhost:8080/openapi/ ,结果如下:

这种方式是有效的,但还不够有效。通常情况下,我们可能需要一些特殊的策略来完成定制化需求。有以下几种方式可以实现:
- MicroProfile Config配置文件。通过配置文件可以做很多事情,比如禁用应用扫描,或者在文档中添加额外的服务器。
- 实现OASModelReader,为最终输出提供一个基础的文档。
- 静态OpenAPI文档。和OASModelReader功能一样,但是格式略有不同。
- 方法或类上的注解。这是修改文档的最常用方法。
- OASFilter过滤器。可以通过过滤器来访问文档中的每一个元素,对其进行编辑或者删除。
下面是一个简单的例子:https://github.com/payara/Payara-Examples/tree/master/microprofile/openapi-example。
配置文件
MicroProfile OpenAPI规范包括配置API的一系列属性。
比如src/main/resources/META_INF/microprofile-config.properties 这个配置文件。示例如下:
# 是否禁用应用类扫描
mp.openapi.scan.disable=false
OASModelReader和OASFilter
MicroProfile OpenAPI提供了两个接口供开发者来实现:
- org.eclipse.microprofile.openapi.OASFilter
- org.eclipse.microprofile.openapi.OASModelReader
这两者功能是类似的,但是在不同的时间点生效。OASModelReader实现会创建一个初始的OpenAPI文档,最终的文档会以此为基础。而OASFilter实现则是在OpenAPI文档发布之前来对其进行访问,过滤最终的文档并进行修改。
如果实现了这两个接口,需要在配置文件中指定,通常是microprofile-config.properties中,如下所示
# 配置处理类用于编辑OpenAPI文档
mp.openapi.model.reader=fish.payara.examples.microprofile.openapi.ModelReader
mp.openapi.filter=fish.payara.examples.microprofile.openapi.Filter
静态OpenAPI文件
静态OpenAPI文件可以放在src/main/resources/META-INF目录下,并且命名为openapi.yaml, openapi.yml 或者openapi.json。当有这个文件时,会优先使用这个文件。
这意味着,你可以先获取应用程序生成的文档,然后删除现有的任何OpenAPI注释,根据需要编辑文档,然后将其放入resources文件夹中,以生成相同的输出。
注解
MicroProfile OpenAPI 定义了几种注解,可用于生成OpenAPI文档。详情见MicroProfile OpenAPI 规范。
openapi ui
下面介绍通过openapi ui插件来展示OpenAPI文档。
引入依赖包
org.microprofile-ext.openapi-ext
openapi-ui
1.1.5
或
org.microprofile-ext.openapi-ext
swagger-ui
1.0.3
这两个包基本上可以看作是同一个东西,使用哪一个取决于你的注解包是swagger的还是microprofile的。
注意:这里open-ui只支持java9以上的版本,不支持java8
启动项目后,访问: http://localhost:8080/xxx/openapi-ui接口,就能看到api页面了。其本质是先访问http://localhost:8080/openapi接口,获得openAPI文档,然后通过ui插件 OpenApiUiService进行渲染展示到页面上。
上文介绍过MicroProfile OpenAPI的规范,通过http://localhost:8080/openapi访问得到的OpenAPI实际上是通过OASModelReader,OASFilter,静态OpenAPI文档或者扫描注解生成的。
在上一章节中介绍过通过swagger插件来扫描swagger注解生成api文档。当然,直接使用openapi注解也是可以的。这里还是以swagger插件生成api文档来举例。
要使用swagger插件生成的api文档,也就是使用静态OpenAPI文档,需要将其放到META-INF文件夹下。可以在插件配置的地方加上一个execution:
io.openapitools.swagger
swagger-maven-plugin
2.1.6
${project.groupId}.examples.jpa
https://services.exmple.it/base/path
Endpoint URL
spring-data-jpa
1.0.0
API description
[email protected]
My Name
https://google.com
my-custom-field-1
my-custom-field-2
api-generate
generate-test-resources
generate
${basedir}/../api-management/src/main/resources/spring-data-jpa
spring-data-jpa-1.0.0
JSON
true
openapi
generate-test-resources
generate
src/main/resources/META-INF/
openapi
JSON
true
这样生成的OpenAPI文档实际上是静态文件加上注解扫描的结合体。这里的静态文件已经是希望对外展示的最终版本了,因此可以通过配置文件来禁用额外的注解扫描:
mp.openapi.scan.disable=true
访问http://localhost:8080/sj/jpa/openapi-ui/,可以看到静态OpenAPI渲染出的界面:
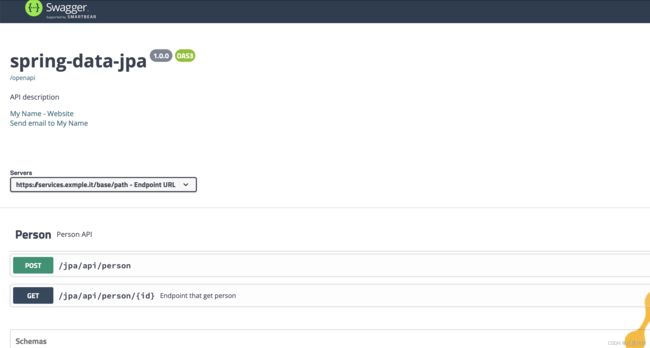
其他的一些可以对ui进行个性化设置的属性如下:
- openapi.ui.copyrightBy:在底部设置版权名称,默认为空
- openapi.ui.copyrightYear:在底部设置版权时间,默认为当前年
- openapi.ui.title:标题,默认为MicroProfile - Open API
- openapi.ui.contextRoot:上下文根路径,默认为当前值
- openapi.ui.yamlUrl:静态OpenAPI文件路径,默认为/openapi
- openapi.ui.swaggerUiTheme:swagger ui主题,默认为flattop
- openapi.ui.swaggerHeaderVisibility: 显示或隐藏wagger的logo头,默认为visible
- openapi.ui.exploreFormVisibility:显示或隐藏搜索表单,默认hidden
- openapi.ui.serverVisibility: 显示或隐藏服务器选择框,默认hidden
- openapi.ui.createdWithVisibility: 显示或隐藏底部栏,默认visible
除此之外,还有一些其他的核心设置如下:
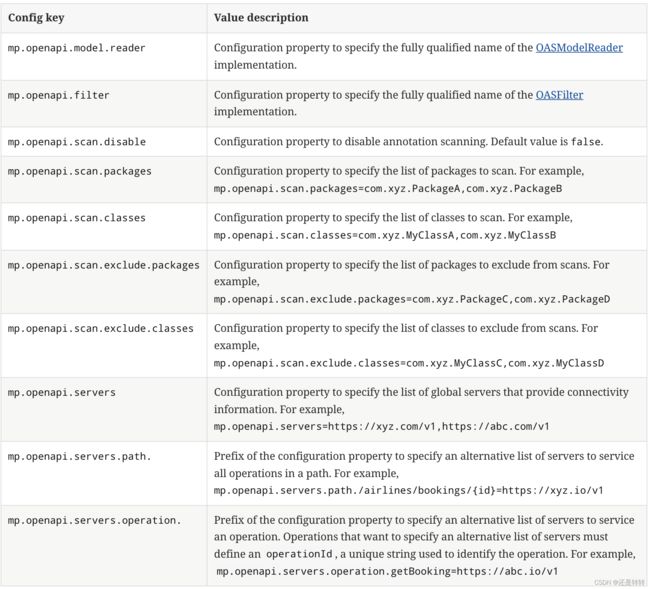
数据库部署
同上一节一样,本节也是独立内容,在所有的maven项目中均适用。
一般情况下,数据库的更改会提交工单交给dba去执行。但这种操作其实会存在一个问题,比如在测试环境更改了数据库,但上线的时候忘记了更改线上的数据库,就会出现线上问题。
通常情况下,一般都会存在多套环境,如开发环境,测试环境,预发布环境,线上环境等。为了保证各个环境的数据库一致,可以使用数据库迁移插件。这里要介绍的是flyway插件。
什么是flyway
Flyway是一款数据库迁移(migration)工具。简单点说,就是在你部署应用的时候,帮你执行数据库脚本的工具。Flyway支持SQL和Java两种类型的脚本,你可以将脚本打包到应用程序中,在应用程序启动时,由Flyway来管理这些脚本的执行,这些脚本被Flyway称之为migration。
在jakarta目录下创建一个子模块,名为db-migrate。在pom文件中添加build元素:
org.flywaydb
flyway-maven-plugin
7.3.1
schema_version
要想flyway插件生效,需要配置
flyway.url,flyway.user,flyway.password
三个属性。因此在父模块中默认生效的profile文件中添加这三个属性:
local
true
dev
jdbc:postgresql://127.0.0.1:5432/postgres?currentSchema=public
postgres
postgres
默认sql文件存放目录为/resources/db/migration下,flyway对sql脚本有命名要求:V版本号__脚本描述.sql。如下图所示:

注意:脚本版本号跟脚本描述之间的__是两个横杠。
在进行数据库部署前需要保证数据库确实存在,同时是一个空库,无已存在的数据。
通过maven命令来部署数据库:
mvn clean compile flyway:migrate -f db-migrate/pom.xml
没有指定profile文件,因为默认激活了id为local的profile。执行完成后,数据库就会生成,同时,新增了一个schema_version表,记录了flyway执行脚本的历史版本信息。
注意:flyway脚本执行后不能更改,但可以新增。脚本每次执行时,会比较已经执行过的脚本的md5值,如果md5发生变更,将会抛出错误。已经执行过的脚本不再执行,新增的脚本将被执行。
单元测试
并不是所有的项目都需要写单元测试。比如互联网行业,项目需求迭代通常都比较快,变化非常频繁,光写业务代码都需要天天加班,这种情况下,一般是没有时间留给开发去写单元测试的。开发写完代码并进行简单的自测后,就丢给测试去负责后续的验证了。
而有些领域则不然,项目开发完成之后变更很少,但对代码的质量和稳定性要求却非常高。这种情况就需要写单元测试,并且单测的代码覆盖率要求会很高。
本节在上文的基础上,简单介绍下单测的使用。以上文中spring-data-jpa为例,创建createPerson的测试用例。
首先引入junit5的依赖包:
org.junit.jupiter
junit-jupiter
5.6.0
test
org.mockito
mockito-junit-jupiter
3.0.0
test
org.mockito
mockito-core
3.7.7
org.glassfish.jersey.core
jersey-common
2.22.2
test
测试用例如下:
@ExtendWith(MockitoExtension.class)
class PersonApiTest {
@InjectMocks
private PersonApi api;
@Mock
private PersonService service;
@Test
void shouldReturnResponseWithStatusOkWhenCreatePerson() {
Person person = new Person();
person.setName("howe");
Response response = api.createPerson(person);
verify(service, only()).save(person);
assertEquals(Response.Status.OK, response.getStatusInfo());
}
}
JUnit与另一个框架 TestNG 占据了 Java领域里单元测试框架的主要市场,其中 JUnit 有着较长的发展历史和不断演进的丰富功能,备受大多数 Java 开发者的青睐。
JUnit 5是 JUnit 单元测试框架的一次重大升级,需要 Java 8 以上的运行环境,虽然在旧版本 JDK 也能编译运行,但要完全使用 JUnit5 的功能, JDK 8 环境是必不可少的。
上面的单测可以直接执行,也可以右键类名,运行当前类下面的所有测试用例。或者通过maven插件来运行,引入surefire插件:
org.apache.maven.plugins
maven-surefire-plugin
2.22.2
执行maven命令:
mvn clean test
即可。
当测试用例比较多时,执行起来比较耗费时间。如果想跳过测试用例执行,可以添加skipTests参数:
mvn clean test -DskipTests
或者
mvn clean test -Dmaven.test.skip=true
skipTests和maven.test.skip的区别是:前者只是不执行测试用例,但还是会编译测试用例的类,而后者都不编译类文件。
代码质量检测
本节仍然是独立章节,与具体的开发框架无关。
通常情况下,代码质量除了通过开发人员自己把控之外,还可以通过自动化工具来进行检测,比如sonarqube。
先安装sonarqube,启动后通过http://localhost:9000/访问首页。
接下来以上文中的单元测试为例。首先引入jacoco插件,用来生成代码分析报告:
org.jacoco
jacoco-maven-plugin
0.8.5
prepare-agent
prepare-agent
report
report
执行maven命令,进行sonarqube分析:
mvn clean verify org.sonarsource.scanner.maven:sonar-maven-plugin:3.4.0.905:sonar -Dsonar.buildbreaker.skip=false
jacoco report目标说明
jacoco:report完整命令:org.jacoco:jacoco-maven-plugin:0.8.9-SNAPSHOT:report
描述:
Creates a code coverage report for tests of a single project in multiple formats (HTML,XML and CSV).
Attributes:
- Requires a Maven project to be executed.
- Since version: 0.5.3.
- Binds by default to the lifecycle phase: verify.
这里默认用的是本地sonarqube。如果是远程的,则需要在命令行中指定host,如:-Dsonar.host.url="http://127.0.0.1:9000"。
另外,如果不指定具体的sonar插件版本,可以直接用sonar:sonar代替org.sonarsource.scanner.maven:sonar-maven-plugin:3.4.0.905:sonar。
分析完成后,可看到结果如下:
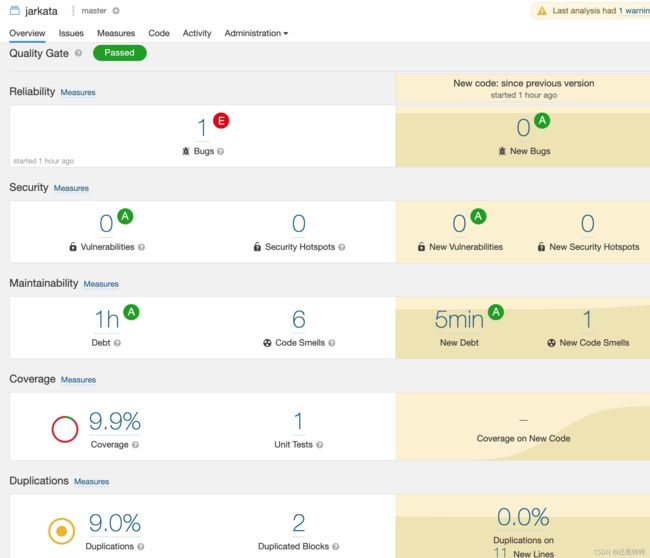
注意,这里实际上涉及到了3个插件。
代码分析中一个很重要的功能是单元测试覆盖率,因此需要执行单元测试用的插件maven-surefire-plugin,该插件在上一节中已经引入。第二个就是sonar-maven-plugin插件,如果只有这两个插件,还是可以通过sonarqube进行代码分析的,可以显示Unit Tests的数量,但是覆盖率是不显示的,始终为0。
mvn执行verify阶段是因为jacoco默认在该阶段生成测试报告,只有在target/jacoco.exec测试报告生成之后,才能将其上传到sonarqube。
要想正确显示单测覆盖率,则还需要上面的jacoco-maven-plugin插件。
sonar
可以在pom文件properties中配置不经过sonar扫描的文件。
- sonar.exclusions 排除文件,如
**/gen/**.java。 - sonar.coverage.exclusions 排除不统计覆盖率的文件。
- sonar.coverage.jacoco.xmlReportPaths 指定统计报告声称路径。
参考资料
[1]. https://blog.csdn.net/chenleiking/article/details/80691750
[2]. https://blog.payara.fish/microprofile-openapi-in-the-payara-platform
[3]. https://download.eclipse.org/microprofile/microprofile-open-api-1.0/microprofile-openapi-spec.html