[leetcode刷题]汇总(一)
总结:刷题的时间安排的不是很好,每天安排的时间不定,需要定时定量完成任务。题解思路都放在的代码中,为了方便后面复习。
文章没有解题思路和代码,主要记录自己的刷题过程。题解在网站都很容易找到,而且有多种的解法。自己在代码中更多记录每次做题的思想。
力扣英文版链接
力扣中文版链接
英文版网站题解更加全面,解题方式也更多。
文章目录
- 数组
-
- 283 移动零(简单)
- 11 乘最多的水的容器(中等)
- 70 爬楼梯(简单)
- 15 三数之和(中等)
- 链表
-
- 206 反转列表(简单)
- 141 环形链表(简单)
- 24 两两交换链表中的节点(中等)
- 142 环形链表2(中等)
- 25 k个一组翻转链表
- 作业-数组和链表
-
- 26 删除排序数组的重复项
- 189 旋转数组
- 25合并两个有序链表(简单)
- 结束循环后,我们要记得把剩下的挂上去
- 88合并两个有序数组
- 1两数之和 (简单)
- 66 加一(简单)
- 栈、队列、双端队列、优先队列
-
- 20 有效的括号(简单)
- 155最小栈(简单)(需要再考虑不用额外空间的做法)
- 84柱状图中最大的矩形(困难)
- 239 滑动窗口的最大值(困难)
- 641设计循环双端队列
- 哈希表、映射、集合
-
- 242. 有效的字母异位词
- 49字母异位词分组(中等)
- 1两数之和(简单)哈希实现
- 树 二叉树 二叉搜索树
-
- 94二叉树的中序遍历
- 144二叉树的前序遍历
- 590 N叉树的后序遍历 (简单)迭代暂时没有涉及
- 589N叉树的前序遍历(简单)
- 429 N叉树的层序遍历(中等)
- 泛型递归、树的递归
-
- 70 爬楼梯
- 22 括号生成(中等)
- 226 翻转二叉树(简单)
- 98 验证二叉搜索树(中等)
- 104二叉树的最大深度(简单)
- 111 二叉树最小深度(简单)
- 297 二叉树的序列化和反序列化(困难)
- 236 二叉树的最近公共祖先(中等)
- 从前序与中序序列构建二叉树
- 77组合(中等)
- 46 全排列 (中等)
- 回溯和分治
-
- 50 pow(x,n)(中等)
- 78 子集(中等)
- 169 多数元素(简单多频)
- 17 电话号码的字母组合(中等)(多看看 总结一下)
- 51 N皇后问题(困难 大概理解)具体后面再看
- 深度优先搜索和广度优先搜索
-
- 102 二叉树的层次遍历(中等)
- 433最小基因变化(中等)
- 22 括号生成(中等)(重复了)
- 515 在每行树行中找最大值(中等)
- 127 单词接龙(困难)
- 126 单词接龙(困难)高频 升级版本
- 200 岛屿数量(中等)(二叉树的深度遍历到图和网格)
- 贪心算法
-
- 322 零钱兑换(简单)
- 455 分发饼干(简单)
- 在这里插入图片描述
- 122买股票的最佳时机2(简单)
- 860 柠檬水找零(简单)
- 874模拟行走机器人(简单)
- 55跳跃游戏(中等)
- 45 跳跃游戏二(中等)
- 二分查找
![[leetcode刷题]汇总(一)_第1张图片](http://img.e-com-net.com/image/info8/c6d16b347f154158b55b7568cf449cde.jpg)
数组
283 移动零(简单)
// C语言写法
// 双指针写法 移动零改为 非零的放在前面 后面的全部置为0
void moveZeroes(int* nums, int numsSize){
int i=0,j=0;
for(i=0;i<numsSize;i++)
{
if(nums[i]!=0)
{
nums[j++]=nums[i];
}
}
while(j<numsSize)
{
nums[j++]=0;
}
}
11 乘最多的水的容器(中等)
// C++ 写法
//双指针写法 一个指向头 一个指向尾部 移动规则是移动指针指向值较低的向前(后移动)因为求面积是要找更小的边,如果移动更长的 下一次的值一定比上一次小 没有意义
//还需要一个保存当前最优值的
//0716思考的问题有 循环条件 以及先计算面积还是先比较 记得要有返回值
//时间复杂度:O(N)O(N),双指针总计最多遍历整个数组一次。空间复杂度:O(1)O(1),只需要额外的常数级别的空间。
class Solution {
public:
int maxArea(vector<int>& height)
{
//两个指针
int i=0,j=height.size()-1,sum=0;
while(i<j)
{
int area=min(height[i],height[j])*(j-i);
sum=max(area,sum);
if(height[i]<height[j])
{
i++;
}
else
{
j--;
}
}
return sum;
}
};
70 爬楼梯(简单)
//如果是递归的话 可以发现规律 第3阶就是爬2阶和1阶的和
/*
if (n==1)
{return 1}
if (n==2)
{return 2}
return climbStairs(n-1)+climbStairs(n-2)
*/
/*简单的说 下面的方式就是移动数组的方式 需要注意的就是迭代条件 n阶 那就是n次 从1开始*/
/*f(1)=1 f(2)=2 f(3)=3 f(4)=5*/
/*推出 f(0)=1 f(-1)=0*/
/*时间复杂度o(n) 空间复杂度1*/
/*0716 修改写法 这样更好理解
class Solution {
public:
int climbStairs(int n) {
int i=0,j=1,sum=0;
for(int q=1;q<=n;q++)
{
sum=i+j;//第一次f(-1)+f(0)
i=j;
j=sum;
}
return sum;
}
};
*/
class Solution {
public:
int climbStairs(int n) {
int i=0,j=0,sum=1;
for(int q=1;q<=n;q++)
{
i=j;
j=sum;
sum=i+j;
}
return sum;
}
};
15 三数之和(中等)
-
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
-
方法一:三重循环 时间复杂度0(n^3)
-
方法二:双指针法 如下 时间复杂度O(n^2)
-
三个指针 我自己称第一个为绝对的位置从1~n 第二个指针是第一个指针的下一个 第三个指针是最后一个位置的。
-
在
开始循环之前我们做了四个事情- 特判:太短了我们就返回
- 定义了一个符合返回类型的动态数组
- 对数组进行sort排序
- 初始化size=长度
-
第一层循环 做了四件事情
- 第一个判断是如果是大于0的直接结束程序
- 如果当前这个值 和上一个一样 continue
- 定义第二个和第三个指针 left 和 right
- 进入while循环(left
-
第二层循环
- 判断 如果三数之和>0
- 判断 如果三数之和 <0
- 如果 三数之和 =0(这边要注意
不要重复项 要特别判断)首先就是push_back,然后指针收缩 两个while判断当前值是否和前一个一样
-
出现一些细节错误
- 比如left right 前面加int
- 临时变量 == 不是=
当前值和上一个值比较的时候 要注意 i>0 易错 难找
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums)
{
int size = nums.size();
if (size < 3) return {}; // 特判
vector<vector<int> >res; // 保存结果(所有不重复的三元组)
sort(nums.begin(), nums.end());// 排序(默认递增)
for (int i = 0; i < size; i++) // 固定第一个数,转化为求两数之和
{
if (nums[i] > 0) return res; // 第一个数大于 0,后面都是递增正数,不可能相加为零了
// 去重:如果此数已经选取过,跳过
if (i > 0 && nums[i] == nums[i-1]) continue;//太精髓了
// 双指针在nums[i]后面的区间中寻找和为0-nums[i]的另外两个数
int left = i + 1;//第二个指针
int right = size - 1;//第三个指针 经典长度-1
while (left < right) //经典两个指针 while前面指针小于后面指针
{
if (nums[left] + nums[right] +nums[i]>0)
right--; // 三数之和太大,右指针左移
else if (nums[left] + nums[right] + nums[i]<0)
left++; // 两数之和太小,左指针右移
else
{
// 找到一个和为零的三元组,添加到结果中,左右指针内缩,继续寻找
res.push_back(vector<int>{nums[i], nums[left], nums[right]});
left++;//两边都收缩
right--;
// 去重:第二个数和第三个数也不重复选取
// 例如:[-4,1,1,1,2,3,3,3], i=0, left=1, right=5
//后面两个指针的的相同移动 一样的比较的是和之前的
while (left < right && nums[left] == nums[left-1]) left++;
while (left < right && nums[right] == nums[right+1]) right--;
}
}
}
return res;
}
};
链表
206 反转列表(简单)
- 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
- 他的思想就是1指向2 改为1被2指向 就这样重头修改
- 三个值就可以完成翻转,pre(第一个) cur(第二个)next(cur的下一个)关键理解next的含义,他要更换cur的指向 我们要先把下一个保存下来
- 三个值都不是固定的值 是一个动态移动的值
- 在循环前 先定义pre 和 next 特被主义pre初始为空
- 循环(迭代条件是cur不为空)
- 第一步 保存cur的下一个节点
- 更改指向
- 更改前面的值
- 更改后面的值
- 退出循环记得返回结果
注意 两个地方一直弄错- 第一个是迭代条件到底是cur->next为空 还是cur为空,记住cur不为空最后一次cur和前面的pre还没有相连
- 第二个就是返回pre 还是 cur 记住 cur就是一个单独的值 pre是一个串,你想想每次循环里面 cur都是next一个值 之前的串都给了pre了
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* pre = nullptr;//初始的值 第一个为空 就好像第一个变成最后一个了。
ListNode* cur =head;
while(cur!=nullptr)//如果后面的值不为空 那就循环继续
{
ListNode* next= cur->next;//第一步 保存下一个 但是这边特殊 下一个是后面的变量的下一个 也可以理解吧 第一根线断掉
cur->next=pre;//第二步 更改指向
pre=cur;//第三部 更改前面的值
cur=next;//第四部 更新后面的值
}
return pre;
}
};
//
141 环形链表(简单)
- 给定一个链表,判断链表中是否有环。如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
- 解法:快慢指针
- 我思考的问题是为什么一定相遇参考,可以简单的理解成我们之间的相对距离一直缩小一个 所以必然相遇 ,如果速度相差2,数学归纳法就是1+1.快指针是慢指针速度的一倍,所以慢指针一圈必然相遇。
- 循环之前 两件事
- 需要判断头结点为空 以及 头结点下一个为空
- 定义快指针 和慢指针
- 进入循环(循环的迭代条件是快指针不为空 快指针的下一个不为空)
- 判断相等
- 判断不想等
- 退出循环记得返回
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head==nullptr||head->next==nullptr)
{
return false;
}
ListNode* slow=head;
ListNode* quick=head->next;
while(quick!=nullptr&&quick->next!=nullptr)
{
if(quick==slow)
{
return true;
}
else
{
slow=slow->next;
quick=quick->next->next;
}
}
return false;
}
};
24 两两交换链表中的节点(中等)
非常重要第一条:
-
我们常说第一个指向第三个 就是 1->next=3 -
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
-
简单的说就是四个一个整体 修改的是第二个和第三个值的位置交换(时间复杂度O(n) 空间复杂度为1)
-
循环前
- 创建一个temp空的枢纽,这个是确实存在的空间 需要用到他的next指针,所以是new的方法创建
- 第二步就是枢纽和head挂起来
- 第三个就是保存一下这个枢纽 因为这个枢纽的next是要返回的,这个枢纽在实际使用中是不断后移两个位置的。(
换一个解释就是 这个变量对应的地址会变化 但是 我们需要知道创建的这个原始地址)
-
循环(
循环条件就是temp的下一个值 和 下下个值不能为空 因为在循环体内需要操作这两个值)(想着空 1 2 3)- 第一步 就是取出temp的next也就是第二个值1
- 第二部 取出第三个值2
- 第三部 temp指向第三个值(第一个值指向第三个值)空->2
- 第四部 第二个值指向第四个值(第三个值的next) 1->3
- 第五步 第三个值指向第二个值
- 第五步 就是后移两个这边就是 temp=node1 也就是1变成新的枢纽(
想着空指向2)//得到 空->2->1->3 循环结束 返回temp1的next 特别注意
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* temp=new ListNode(0);//在我看来temp更像是枢纽 不是固定的值 他表示的是重复单元的第一个值 但是我需要开辟空间
temp->next=head;//
ListNode* temp1 = temp;//但是我们需要保存第一个值 因为这个值会改变 这个值才能等到 head
//这个的意思就是 4个重复单元 temp后面的两个是修改的量 如果temp后面没有了结束 不是偶数个 不需要修改
while(temp->next!=nullptr&&temp->next->next!=nullptr)
{
//第一步取出第二个值 1
ListNode* node1 = temp->next;//这边是地址 所以没有给指针开辟空间
//第二步取出第三个值 2
ListNode* node2 = temp->next->next;
//第三步 第一个指向第三个 空->2
temp->next=node2;
//第四部 第二个指向第四个 1->3
node1->next=node2->next;
//第五步 第三个指向第二个 2->1
node2->next=node1; //得到 空->2->1->3
//第六部
// node1 是第第一个值 但是他的位置就是后移2个的
temp=node1;
}
return temp1->next;//注意看
}
};
142 环形链表2(中等)
![[leetcode刷题]汇总(一)_第2张图片](http://img.e-com-net.com/image/info8/681313ba697d4eb0be77050df7d4e33b.jpg)
![[leetcode刷题]汇总(一)_第3张图片](http://img.e-com-net.com/image/info8/f98c52a8d40b450cbf76bb660937db95.jpg)
- 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
- 和之前的判断有没有环
//0716修正写法 对比之前的快慢指针
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head==nullptr||head->next==nullptr)
{
return nullptr;
}
ListNode* slow=head;
ListNode* quick=head;
while(quick!=nullptr&&quick->next!=nullptr)
{
slow=slow->next;
quick=quick->next->next;
if(quick==slow)
{
ListNode *ptr = head;
while (ptr != slow)
{
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return nullptr;
}
};
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode *slow = head, *fast = head;
while (fast != nullptr) {
slow = slow->next;
if (fast->next == nullptr) {
return nullptr;
}
fast = fast->next->next;
if (fast == slow) {
ListNode *ptr = head;
while (ptr != slow) {
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return nullptr;
}
};
25 k个一组翻转链表
作业-数组和链表
26 删除排序数组的重复项
- 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
- 双指针法:定义两个指针 \textit{fast}fast 和 \textit{slow}slow 分别为快指针和慢指针,
快指针表示遍历数组到达的下标位置,慢指针表示下一个不同元素要填入的下标位置,初始时两个指针都指向下标 11。 - 循环前
- 如果长度过短,那就直接返回
- 定义慢指针初始为1(
因为慢指针为放入的位置0不是)
- 循环的迭代条件 (for 循环 快指针为迭代条件)
- 判断(如果快指针和前一个值不相同)
- 可能出现的情况一 :我终于找到一个不同了 赶紧把找到的第一个不同注入到漫指针,指针后移
- 可能出现的情况二:初始的时候第一个和第二个不同 那也不过是我覆盖我自己
- 判断(如果快指针和前一个值不相同)
注意我代码的第二种写法是不是更简单理解
- while循环
- 如果快指针和前一个相同 那我就只移动 fast
- 如果 终于找到一个不同了 那我就覆盖和同时移动两个
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int n = nums.size();
if (n == 0) {
return 0;
}
int fast = 1, slow = 1;
while (fast < n) {
if (nums[fast] != nums[fast - 1]) {
nums[slow] = nums[fast];
++slow;
}
++fast;
}
return slow;
}
};
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
if(nums.size()<2)
{
return nums.size();
}
int slow=1;
int fast=1;
while(fast<nums.size())
{
if (nums[fast]==nums[fast-1])
{
fast++;
}
else
{
nums[slow]=nums[fast];
slow++;
fast++;
}
}
return slow;
}
};
189 旋转数组
- 给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
- 输入: nums = [1,2,3,4,5,6,7], k = 3
- 输出: [5,6,7,1,2,3,4]
- 第一种方法很常见 就是时间和空间复杂度都是n
//第一种方法就是 创建一个新的动态数组 然后用 (i+k)%n 的方式确定下标 最后拷贝得旧的数组
class Solution {
public:
void rotate(vector<int>& nums, int k) {
int n = nums.size();
vector<int> new_array(n);
for(int i=0;i<n;i++)
{
new_array[(i+k)%n]=nums[i];
}
nums.assign(new_array.begin(),new_array.end());
}
};
- 第二种方法是利用了数组翻转的方式 时间复杂度O(2n)=O(n) 空间复杂度是O(1)
注意的是数组的翻转方式
![[leetcode刷题]汇总(一)_第4张图片](http://img.e-com-net.com/image/info8/d32248dd57e94be9a2a7891c8a962b87.jpg)
class Solution {
public:
void reverse(vector<int>& nums, int start, int end) {
while (start < end) {
swap(nums[start], nums[end]);
start += 1;
end -= 1;
}
}
void rotate(vector<int>& nums, int k) {
k %= nums.size();
reverse(nums, 0, nums.size() - 1);
reverse(nums, 0, k - 1);
reverse(nums, k, nums.size() - 1);
}
};
25合并两个有序链表(简单)
- 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
- 迭代的方式合并两个有序链表。很经典的题目,简单的说用到了
三个移动节点,其中一个是经典的枢纽(开始需要拷贝一份初始地址需要返回) - 循环开始前
- 创建了一个枢纽
- 同时把这个枢纽拷贝了一份
- 循环的迭代条件是(第二个变量l1 和第三个变量l2不为空)新的感受就是(
如何确定迭代条件呢 虽然在循环体内有->Next操作 但是在next没有新的操作了 所以那就本身不为空)- 如果l1
也就是放在了尾节点的位置 方便挂入下一个)
- 如果l1
-
结束循环后,我们要记得把剩下的挂上去
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* pre =new ListNode(-1);
ListNode* head=pre;
while(l1!=nullptr&&l2!=nullptr)
{
if(l1->val<l2->val)//每次取头节点进行比较
{
pre->next=l1;//头结点挂上
l1=l1->next;//更换头结点位置
pre=pre->next;//可以理解成新链表的最后一个节点 时刻保持我们操作的是最后一个节点
}
else
{
pre->next=l2;
l2=l2->next;//同理
pre=pre->next;//可以理解成新链表的最后一个节点 时刻保持我们操作的是最后一个节点
}
}
//这一步其实就是把剩余的东西拼凑上去
if(l2!=nullptr)
{
pre->next=l2;
}
else
{
pre->next=l1;
}
return head->next;
}
};
88合并两个有序数组
- 给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组
- 方法一:就是合并后排序 时间复杂度是O((m+n)\log(m+n))O((m+n)log(m+n))。
- 方法二就是双指针:时间复杂度:O(m+n)O(m+n)。空间复杂度:O(m+n)O(m+n)。
- 方法三:就是逆向双指针:。因此可以指针设置为从后向前遍历,每次取两者之中的较大者放进 num1的最后面O(m+n)。空间复杂度:O(1)O(1)优点 不需要额外的空间 并且时间复杂度最低 -
- 循环前就是定义三个指针下标
- 进入循环(只要有一个指针还是>=0)
异常情况一定要放在前面如果第一个下标为-1 那就一直放第二个- 如果第二个下标为-1 那就一直放第一个
- 如果第一个小于第二个 那就放第二个(
注意这边 不要下标了 是值) - 如果第二个小于第一个 那就放第一个
- 注意是先放入再–
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int p1 = m-1;//数组一的下标
int p2 = n-1;//数组二的下标
int tail=m+n-1;//new的下标
//int cur;//可有可无
while(p1>=0||p2>=0)
{
if(p1==-1)
{
nums1[tail--]=nums2[p2--];
}
else if(p2==-1)
{
nums1[tail--] =nums1[p1--];
}
else if(nums1[p1]<nums2[p2])
{
nums1[tail--]=nums2[p2--];
}
else
{
nums1[tail--] =nums1[p1--];
}
}
}
};
1两数之和 (简单)
- 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
- 方法一: 就是枚举 o(n^2)
- 方法二:哈希表 (这个没有涉及 后面再补充)
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n = nums.size();
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] + nums[j] == target) {
return {i, j};
}
}
}
return {};
}
};
66 加一(简单)
- 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。你可以假设除了整数 0 之外,这个整数不会以零开头。
- 从后向前遍历 如果加1不等于10就返回,如果等于10,那就置为0 ,移到前面一个
- 如果全部for循环走完了 走出来了还没有返回 那就初始化打一个的空间,把第一个值置为1
class Solution {
public:
vector<int> plusOne(vector<int>& digits) {
for (int i=digits.size()-1;i>=0;i--)
{
digits[i]++;
if(digits[i]!=10)
{
return digits;
}
else
{
digits[i]=0;
}
}
vector<int> res(digits.size()+1);
res[0]=1;
return res;
}
};
欢迎大家相互学习指教。
心体:我可太难了

栈、队列、双端队列、优先队列
20 有效的括号(简单)
- 它的一个解题思想就是用到栈先进去的后背发现,后进去的先被发现,我们把左括号的压入栈,然后右括号的逐个与左括号匹配 匹配就消掉,如果结束了,全部都没了那就成功了。(官方思路)
但是我们代码的思路是:不断去便利这个字符串,不断地想把它放入新创建的栈中,但是在放入之前,我们总是做一件事情就是与栈顶的进行匹配 【】 {} 这种同时出现那就不放入并且删除栈顶元素 并且continue。- 循环之前 创建一个栈
- 循环条件 for循环遍历字符串
- 创建一个临时变量放入字符
- 判断栈不为空,那我们就创建一个临时去栈顶元素 进行比较 如果匹配那就去掉栈顶 continue
- 很巧妙的是(
放入栈中是一直做的事情,所以不放在else 或者if里面,当if中1if满足就不做很巧妙用了continue)
如果不能理解continue的写法 那就全部if else 但是就是要多判断几个地方 第二个代码有
- ’
class Solution {
public:
bool isValid(string s) {
stack<char> stack;
for(int i=0; i<s.length(); ++i)
{
char c = s[i];
if(!stack.empty())
{
char t = stack.top();
if(t=='(' && c==')' || t=='[' && c==']'|| t=='{' && c=='}')
{
stack.pop();
continue;
}
}
stack.push(c);
}
return stack.empty();
}
};
class Solution {
public:
bool isValid(string s) {
stack<char> stack;
for(int i=0;i<s.length();i++)
{
char c =s[i];
if (!stack.empty())
{
char t = stack.top();
if(t=='(' && c==')' || t=='[' && c==']'|| t=='{' && c=='}')
{
stack.pop();
continue;
}
else
{
stack.push(c);
}
}
else
{
stack.push(c);
}
}
return stack.empty();
}
};
155最小栈(简单)(需要再考虑不用额外空间的做法)
- 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
- 设计思想就是利用辅助栈,需要额外的空间
- 辅助栈一直放的都是当前的最小值,每当我们在旧栈放入一个新值,我们就要与辅助栈的顶元素比较,谁小谁放入
- 第二次做这个题就是不知道为什么删除也要删除辅助栈的顶元素,如果我们想这个辅助栈的顶元素是加入我带来的变化是不是就要删除了
class MinStack {
public:
stack<int> stack_1;
stack<int> stack_min;
/** initialize your data structure here. */
MinStack() {
stack_min.push(INT_MAX);
}
void push(int val) {
stack_1.push(val);
stack_min.push(min(stack_min.top(),val));//易错 这边 是stack_min
}
void pop() {
stack_1.pop();
stack_min.pop();
}
int top() {
return stack_1.top();
}
int getMin() {
return stack_min.top();
}
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(val);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->getMin();
*/
84柱状图中最大的矩形(困难)
- 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。求在该柱状图中,能够勾勒出来的矩形的最大面积。
- 暴力写法:第一个就是两个for循环 0-1 0-2 0-3 1-2 1-3 每次更新最优值
- 暴力写法:就是考虑柱子的左右,找到以自己为最高点的情况(找到比我矮就停止) 也要两层循环
- 方法很多,可以再多多了解
![[leetcode刷题]汇总(一)_第5张图片](http://img.e-com-net.com/image/info8/a155ee01f99d4acd917ad0b10432e1bb.jpg)
- 栈的方法解决:很巧妙的方法你看动画演示 -a-1
- 第一次减去的是左边界的值(正常情况下我们要+1 所以初始值设为-1) 第二个减去1是因为遇到右边界我们停止下来我们用右边界计算(但实际右边界比我们要算的那个矩阵边界多一)
这边左边界b和右边界a都是实际矩阵的左边和右边那个 计算也是a-b-1,当我们栈中遇到比前一个小的就说明该计算了,计算后酒吧这个去掉,因为我要保持时刻单调递增,这样子相邻的两个值(就说明左边的一直比我小 左边界就一直是确定了了,因为我是最大)右边界第一个比我小的就确定了
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
int n = heights.size();//求了下数量
vector<int> left(n), right(n, n);//定义了两个动态数组
stack<int> mono_stack;//定义了一个单调递增的栈 栈里面放的是下标
for (int i = 0; i < n; ++i)
{
while (!mono_stack.empty() && heights[mono_stack.top()] >= heights[i])//如果栈不为空,或者栈顶元素最为下标比即将要放入的值大
{
right[mono_stack.top()] = i;//那我们就知道对应元素的右边界了
mono_stack.pop();//并且去掉栈中元素
}
left[i] = (mono_stack.empty() ? -1 : mono_stack.top());//正常情况每个元素的左边界都清楚
mono_stack.push(i);//栈中放入坐标
}
int ans = 0;
for (int i = 0; i < n; ++i) {
ans = max(ans, (right[i] - left[i] - 1) * heights[i]);
}
return ans;
}
};
239 滑动窗口的最大值(困难)
-
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值。
![[leetcode刷题]汇总(一)_第6张图片](http://img.e-com-net.com/image/info8/9276a9ce4e04440fa97666a618c119f8.jpg)
-
暴力求解:for循环 n*k的时间复杂度 大循环控制移动 小循环用于内部比较
-
简单的说就是双向栈解决问题,不断将新的数据从尾部添加(小的留下,大的也留但是要把栈比自己小的去掉),头部用来去除不在当前滑动窗口的数据(利用数据递增排序来实现)
-
代码中做了两个并列的for循环
- 第一个for循环就是只是考虑前三个值,进行递减排序(
为什么是递减呢,因为如果同一个窗口内你坐标比我小,值还比我小递增的那肯定不是取你,不存在递增的关系) - for循环后就创建了一个动态数组,把栈的第一个值放入,这就是第一个滑动窗口的最大值。
- 接着又是一个for循环
- 首先肯定一个while(如果栈不是空的 并且我加入的值比栈最后一个大那我把最后一个删除掉:
我想明白了一个点就是加入的这个值肯定是当前滑动窗口的值,如果它真的比之前的大把之前的都删掉也无所谓。。) - 如果比之前的小那我还是乖乖的加进去吧 (
注意:就算走进了while循环也要也要进行这一步 大的值也要加进去) - 又来一个while循环,如果栈的第一个值坐标在滑动窗口的左边,那就删除掉
,举个例子i=3 k=3 i-k=0 这不就是边界么 小于等于这个删除 刚好符合第二个滑动窗口 - 结束了删除,我们把栈的值加入到动态数组,这个就是一个结果了
- 首先肯定一个while(如果栈不是空的 并且我加入的值比栈最后一个大那我把最后一个删除掉:
- 第一个for循环就是只是考虑前三个值,进行递减排序(
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
int n = nums.size();
deque<int> q;
for (int i = 0; i < k; ++i) {
while (!q.empty() && nums[i] >= nums[q.back()])//如果队列不为空 加入的值比最后一个大 那就把队列最后一个去掉(这里实际上是存储下标)
{
q.pop_back();
}
q.push_back(i);//比他小就直接加进去 比他大也直接加进去
}
vector<int> ans = {nums[q.front()]};//创建一个存储返回值的动态数组
for (int i = k; i < n; ++i) {
while (!q.empty() && nums[i] >= nums[q.back()])
{
q.pop_back();
}
q.push_back(i);
while (q.front() <= i - k)//坐标在滑动窗口左侧 那就直接去掉
{
q.pop_front();
}
ans.push_back(nums[q.front()]);
}
return ans;
}
};
641设计循环双端队列
class MyCircularDeque {
private:
vector<int> q;
public:
int K;
/** Initialize your data structure here. Set the size of the deque to be k. */
MyCircularDeque(int k) {
q.reserve(k);
K=k;
}
/** Adds an item at the front of Deque. Return true if the operation is successful. */
bool insertFront(int value) {
if(!isFull()){
q.insert(q.begin(),value);
return true;
}
return false;
}
/** Adds an item at the rear of Deque. Return true if the operation is successful. */
bool insertLast(int value) {
if(!isFull()){
q.push_back(value);
return true;
}
return false;
}
/** Deletes an item from the front of Deque. Return true if the operation is successful. */
bool deleteFront() {
if(!isEmpty()){
q.erase(q.begin());
return true;
}
return false;
}
/** Deletes an item from the rear of Deque. Return true if the operation is successful. */
bool deleteLast() {
if(!isEmpty()){
q.pop_back();
return true;
}
return false;
}
/** Get the front item from the deque. */
int getFront() {
if(isEmpty())return -1;
return q.front();
}
/** Get the last item from the deque. */
int getRear() {
if(isEmpty())return -1;
return q.back();
}
/** Checks whether the circular deque is empty or not. */
bool isEmpty() {
return q.size()==0;
}
/** Checks whether the circular deque is full or not. */
bool isFull() {
return q.size()>=K;
}
};
/**
* Your MyCircularDeque object will be instantiated and called as such:
* MyCircularDeque* obj = new MyCircularDeque(k);
* bool param_1 = obj->insertFront(value);
* bool param_2 = obj->insertLast(value);
* bool param_3 = obj->deleteFront();
* bool param_4 = obj->deleteLast();
* int param_5 = obj->getFront();
* int param_6 = obj->getRear();
* bool param_7 = obj->isEmpty();
* bool param_8 = obj->isFull();
*/
哈希表、映射、集合
242. 有效的字母异位词
- 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
- 时间复杂度是0(n) 空间复杂度是0(26),需要注意的是一个字符串用来加 一个字符串用来减 需要时刻注意。
两个for循环 一个加一个减(减的时候还不断判断 ),还有一个就是在开始特判 特别注意
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length()!=t.length())
{
return false;
}
vector<int> table(26,0);
for (int i=0;i<s.length();i++)
{
table[s[i]-'a']++;
}
for (int i=0;i<t.length();i++)
{
table[t[i]-'a']--;
if(table[t[i]-'a']<0)
{
return false;
}
}
return true;
}
};
49字母异位词分组(中等)
- 需要注意的是迭代器的使用
- unordered_map和map的区别底层实现的不同
- emplace_back和push_back的区别
- 在解题的时候我们一定要很清楚什么作为键什么作为值,
我们这边排序后的字符串作为键,未排序的作为值。以及这个存放类型unordered_map
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> mp;
for (int i=0;i<strs.size();i++)
{
string sort_new=strs[i];
sort(sort_new.begin(),sort_new.end());
mp[sort_new].emplace_back(strs[i]);
}
//这边用来构建返回值的问题
vector<vector<string>> ans;
//构建迭代器
unordered_map <string,vector<string>>::iterator it;
for (it = mp.begin(); it != mp.end(); ++it)
{
ans.emplace_back(it->second);
}
return ans;
}
};
1两数之和(简单)哈希实现
- 它的一个实现思路就是把数放在map上面,每次放之前都看看差值(
目标减去现在放的值是不是已经在里面了,如果在就准备返回了),map键值对的键是具体的数,值是对应的下标,因为下标是我们要返回的东西 - 时间复杂度是o(n) 查找的时间复杂度是0(1)
- 空间复杂度:O(N)O(N),其中 NN 是数组中的元素数量。主要为哈希表的开销。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
map<int,int> map_a;
vector<int> vector_b(2,-1);
for(int i=0;i<nums.size();i++)
{
if(map_a.find(target-nums[i])!=map_a.end())//这个键已经存在
{
vector_b[0]=map_a[target-nums[i]];//那我们就或许他的下标也就是值
vector_b[1]=i;
break;
}
else
{
map_a[nums[i]]=i;//这个键不存在 我同时插入键和值
}
}
return vector_b;
}
};
树 二叉树 二叉搜索树
![[leetcode刷题]汇总(一)_第7张图片](http://img.e-com-net.com/image/info8/9a4e59b4f2b349a692de53533dd9e65a.jpg)
94二叉树的中序遍历
- 这个题有三种做法(第三种是最好理解了 很厉害的方法)
- 方法一:递归 时间复杂度和空间复杂度都是0(n)
class Solution {
public:
void inorder(TreeNode* root, vector<int>& res) {
if (!root) {
return;
}
inorder(root->left, res);
res.push_back(root->val);
inorder(root->right, res);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
inorder(root, res);
return res;
}
};
- 方法二:迭代时间复杂度和空间复杂度和上面一样:方法一的递归函数我们也可以用迭代的方式实现,两种方式是等价的,区别在于递归的时候隐式地维护了一个栈,而我们在迭代的时候需要显式地将这个栈模拟出来,其他都相同,具体实现可以看下面的代码。
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
stack<TreeNode*> stk;
while (root != nullptr || !stk.empty()) {
while (root != nullptr) {
stk.push(root);
root = root->left;
}
root = stk.top();
stk.pop();
res.push_back(root->val);
root = root->right;
}
return res;
}
};
-
方法三 颜色标记法,本质上也是维护栈来实现
-
它的
思想是- 使用颜色标记节点的状态,新节点为白色,已访问的节点为灰色。
- 如果遇到的节点为白色,则将其标记为灰色,然后将其右子节点、自身、左子节点依次入栈。
- 如果遇到的节点为灰色,则将节点的值输出。
-
我们需要理解的几个点首先开始永远是把根放进去的,只要第一次放入栈都是白色的,第二个需要注意的是存在取出白色 放入红色 取出红色 输出的。看看注释和自己花的图
-
区别pair 和make_pair的区别(自动确定类型),类型是结构体类型 -
auto可以在声明变量的时候根据变量初始值的类型自动为此变量选择匹配的类型: -
栈加入数据是push -
在开始循环前
- 需要创建一个动态数组和栈(类型 是pair<第一个是节点 第二个是整形>)
- 开始就把把第一个节点放进去
-
开始循环(栈不为空)
- 每次一开始就从栈取出一个 返回值用auto接受
- 取出就给他删除
- 特判 如果节点是空的 直接continue
- 如果类型是0 那就按照需要push添加 自己的节点二次记得类型是1
- 如果类型不是0 那就直接把 节点的值取出来放入vector中
![[leetcode刷题]汇总(一)_第8张图片](http://img.e-com-net.com/image/info8/bf31f3d355a54ccbbac7c4183e9f6dfd.jpg)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
**/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<pair<TreeNode*, int> > stk; //放入的这个类型 第一个是节点用来取值 第二个用来标记颜色
stk.push((make_pair(root, 0)));//一开始先把根放入 颜色是白色
while(!stk.empty())//如果栈不是空的就一直变量 知道全部处理好变灰色 然后取出来了
{
auto [node, type] = stk.top();//每次都取出看看
stk.pop();//取出记得删除
if(node == nullptr) continue;
if(type == 0)//如果是白色的 根据中序 先序后续放入
{
stk.push(make_pair(node->right, 0));
stk.push(make_pair(node, 1));
stk.push(make_pair(node->left, 0));
}
else result.emplace_back(node->val);//否则灰色的我就输出
}
return result;
}
};
144二叉树的前序遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
**/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
stack<pair<TreeNode*, int> > stk; //放入的这个类型 第一个是节点用来取值 第二个用来标记颜色
stk.push((make_pair(root, 0)));//一开始先把根放入 颜色是白色
while(!stk.empty())//如果栈不是空的就一直变量 知道全部处理好变灰色 然后取出来了
{
auto [node, type] = stk.top();//每次都取出看看
stk.pop();//取出记得删除
if(node == nullptr) continue;
if(type == 0)//如果是白色的 根据中序 先序后续放入
{
stk.push(make_pair(node->right, 0));
stk.push(make_pair(node->left, 0));
stk.push(make_pair(node, 1));//当前这个节点已经是取出放入的 而且一直都是中间那一个
}
else result.emplace_back(node->val);//否则灰色的我就输出
}
return result;
}
};
//递归写法
class Solution {
public:
void preorder(TreeNode *root, vector<int> &res) {
if (root == nullptr) {
return;
}
res.push_back(root->val);
preorder(root->left, res);
preorder(root->right, res);
}
vector<int> preorderTraversal(TreeNode *root) {
vector<int> res;
preorder(root, res);
return res;
}
};
590 N叉树的后序遍历 (简单)迭代暂时没有涉及
- 怎么说了,解答都是递归和迭代,代码在下面给出了,暂时不管,我看看颜色标记法如何解决
自己尝试用颜色标记法 非常的快 一下子就好了 就是需要注意取出儿子放入的顺序 倒这来的
class Solution {
public:
// 后序遍历,首先最简单的做法是 记住前序 翻转就实现 (直接利用 1.前序遍历 2.翻转)
// 后插入
// 第一种:递归
vector<int> postorder1(Node* root) {
vector<int> ve;
if (!root) return ve;
recursivePreorder(root, ve);
return ve;
}
void recursivePreorder(Node *node, vector<int>& ve) {
if (!node) return;
for (int i=0; i < node->children.size(); i ++) {
Node *n = node->children[i];
if (n) recursivePreorder(n,ve);
}
ve.emplace_back(node->val);
}
// 第二种:迭代
vector<int> postorder(Node* root) {
vector<int> ve;
if (!root) return ve;
stack<Node*> st;
st.push(root);
while (!st.empty()) {
Node *node = st.top();
st.pop();
if (node) {
ve.emplace_back(node->val);
vector<Node*> chs = node->children;
if (!chs.empty()) {
int size = chs.size();
for (int i =0; i< size; i++) {
Node *n = chs[i];
if (n) st.push(n);
}
}
}
}
reverse(ve.begin(),ve.end());
return ve;
}
};
/*
// Definition for a Node.
class Node {
public:
int val;
vector children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<int> postorder(Node* root) {
vector<int> result;//用于接收返回结果
stack<pair<Node*,int>> stk;//
stk.push(make_pair(root, 0));//老规矩吧跟放入栈中
while(!stk.empty())
{
auto [node,type] =stk.top();
stk.pop();
if(node == nullptr) continue;
if(type == 0)//不管什么情况 就是改中间这边
{
stk.push(make_pair(node, 1));
vector<Node*> childrens=node->children;
for (int i=childrens.size()-1;i!=-1;i--)//注意这边的顺序
{
stk.push(make_pair(childrens[i], 0));
}
}
else
{
result.emplace_back(node->val);
}
}
return result;
}
};
589N叉树的前序遍历(简单)
- 掌握思想 其实都一样 后面关注一下其他两种写法
/*
// Definition for a Node.
class Node {
public:
int val;
vector children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<int> preorder(Node* root) {
vector<int> result;//用于接收返回结果
stack<pair<Node*,int>> stk;//
stk.push(make_pair(root, 0));//老规矩吧跟放入栈中
while(!stk.empty())
{
auto [node,type] =stk.top();
stk.pop();
if(node == nullptr) continue;
if(type == 0)//不管什么情况 就是改中间这边
{
//vector childrens=node->children;
for (int i=node->children.size()-1;i!=-1;i--)//注意这边的顺序
{
stk.push(make_pair(node->children[i], 0));
}
stk.push(make_pair(node, 1));
}
else
{
result.emplace_back(node->val);
}
}
return result;
}
};
429 N叉树的层序遍历(中等)
-
因为我们从根节点开始遍历树,然后向下搜索最接近根节点的节点,这是广度优先搜索。我们使用队列来进行广度优先搜索,队列具有先进先出的特性。 -
队列确实是解决这个问题的好方法,你想一个队列 模拟放入的场景 不就是按照顺序的 7-6-5-4-3-2-1,它这个代码巧妙的地方就是- 首先它设计了两个数组 一个数组是一层的 一个是二层的。一层的那个总是能及时清空
- 第二个巧妙的地方是 他设置了标记位,总能及时(这一层的加入完了 停止 发送到二维层 把一维层清空)
-
在循环前
- 进行了特判 root直接为空 直接返回
- 把根节点放入队列 这个和颜色标记一样
- 特别在于设置了flag=1 开始就是一个(每次循环一次就–)
- 然后还初始化了两个数组 注释很全不多说了
- 进入循环老样子 while 不为空
- 进入循环每次取一个 记得删除
- 直接把这个结点的值取出来了
- 然后小循环 把孩子节点 放入队列中
- flag–
- 如果flag==0 说明这一层处理好了 (值都放入数组了 并且下一层的节点都放入队列了) 那我们就重新确定flat的大小,把数组放入大数组中 清空小数组
/*
// Definition for a Node.
class Node {
public:
int val;
vector children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public:
vector<int> subans;//这个是用来存放放一层的数据 会随时清空
vector<vector<int>> ans;//这个是用来存放汇总的数据
queue<Node*> que;//广度优先 使用队列
vector<vector<int>> levelOrder(Node* root)
{
if(root ==NULL) return {};//特判 如果为空 直接返回
Node* p = root;//在循环开始前 总是把根节点加进去队列
que.push(p);
int flag =1;//初始标记 1 表示当前队列放入了一个
while(!que.empty())//如果队列不为空
{
p = que.front();//那我就每次从队列头部取出一个(最旧的元素 )
que.pop();//老规矩 取出 就要删除
subans.push_back(p->val);//取出就要放入数组内
/**不常见写法
for(auto c:p->children)//遍历他的孩子 孩子放入队列
{
que.push(c);
}
**/
for(int i=0;i<p->children.size();i++)
{
que.push(p->children[i]);
}
--flag; //用于记录当前层次的节点个数
if(flag == 0)
{
flag = que.size();//这边就是统计队列剩余的数量 也就是下一层的数目了
ans.push_back(subans);//把当前层的数组加入总结果
subans.clear();//一定要记得及时清空
}
}
return ans;
}
};
泛型递归、树的递归
![[leetcode刷题]汇总(一)_第9张图片](http://img.e-com-net.com/image/info8/8f4246ee861c42a59e9b94754115aace.jpg)
![[leetcode刷题]汇总(一)_第10张图片](http://img.e-com-net.com/image/info8/98b6a35353654f6a925cee43f943f8ca.jpg)
![[leetcode刷题]汇总(一)_第11张图片](http://img.e-com-net.com/image/info8/8cb54f89f61c4d808c739899dd035750.jpg)
![[leetcode刷题]汇总(一)_第12张图片](http://img.e-com-net.com/image/info8/2cea72f84e884d27b459797861a1004d.jpg)
![[leetcode刷题]汇总(一)_第13张图片](http://img.e-com-net.com/image/info8/fbbd6ef83aeb423cbbdf8dc8099d7484.jpg)
![[leetcode刷题]汇总(一)_第14张图片](http://img.e-com-net.com/image/info8/510bb2096bab4f33a069aecf8bf9bc44.jpg)
- 第一步就是递归的终止条件
- 处理当前层的逻辑代码
- 下探到下一层
- 清理当前层
![[leetcode刷题]汇总(一)_第15张图片](http://img.e-com-net.com/image/info8/57ed8663f32247d28e68abf7bcf1c43e.jpg)
思维要点
- 不要人肉递归
- 找最近可重复性性
- 数学归纳法的思维
70 爬楼梯
- 我们之前是迭代的方法做的,3个变量,第三个就是前两个相加
- 傻规划
- 动态规划
- 二维矩阵
22 括号生成(中等)
-
回朔实现
- 我一开始就是思考为什么传入一个空当前值,能返回那么多结果,后来我发现了它就是通过pop_back这个东西。
每次数量满足了,就执行一次去掉一个字母,如果函数结束了(三个if都执行完了也去掉一个 就存在一次性去掉很多的情况比如n=3自己看看第二个是怎么生成的) - 需要注意vector push_back做的事情是拷贝 所以就算是引用也不影响。
注意第二种写法 不是引用 是拷贝。原因就好像 你进去函数前是(( 进去后是(()你退出函数 之前那个声明周期都结束了。所以你用的还是((- 给我一种很特别的感觉就是,递归就是加左括号 加右括号这种所有的都会走你懂么 就是本来走左的 左退出来就走右了 这样
- 我一开始就是思考为什么传入一个空当前值,能返回那么多结果,后来我发现了它就是通过pop_back这个东西。
-
注意模板(四步走:正常情况 这样写全部输出 特殊点就是去除哪些不符合条件的加了if)
-
第一步就是结束条件:==2n
-
第二步就是当前层的逻辑:
- s1=加左括号
- s2= 加右括号
-
第三部:进入下一层
- 调用函数 左
- 调用函数 右
-
第四部: 清理当前层 (
第一种方法有 第二种方法没有)
![[leetcode刷题]汇总(一)_第16张图片](http://img.e-com-net.com/image/info8/022bc136660945ad9346edef7157b180.jpg)
核心思想:=2n终止 左括号小于n就可以一直添加 如果右括号小于左括号就可以添加右括号
class Solution {
void backtrack(vector<string>& ans, string& cur, int open, int close, int n) {
if (cur.size() == n * 2) //结束条件
{
ans.push_back(cur);
return;
}
if (open < n) {
cur.push_back('(');//步二
backtrack(ans, cur, open + 1, close, n);//步三
cur.pop_back();//步四
}
if (close < open) {
cur.push_back(')');
backtrack(ans, cur, open, close + 1, n);
cur.pop_back();
}
}
public:
vector<string> generateParenthesis(int n) {
vector<string> result;
string current;
backtrack(result, current, 0, 0, n);
return result;
}
};
、
class Solution {
void backtrack(vector<string>& ans, string cur, int open, int close, int n) {
if (cur.size() == n * 2) //步一
{
ans.push_back(cur);
return;
}
if (open < n)
{
cur.push_back('(');//步二
backtrack(ans, cur, open + 1, close, n);//步三
//cur.pop_back();
}
if (close < open) {
cur.push_back(')');
backtrack(ans, cur, open, close + 1, n);
//cur.pop_back();
}
}
public:
vector<string> generateParenthesis(int n) {
vector<string> result;
string current;
backtrack(result, current, 0, 0, n);
return result;
}
};
226 翻转二叉树(简单)
- 标志:重复 树形 很容易想到树形递归
- 这个题用标准的四步走能写完
- 第一步:
结束条件(因为我们要做的是不断走进跟节点去交换他的左右节点) - 第二部:
当前层的逻辑操作(就是做了一个左右节点的交换) - 第三部:
就是进入下一层,把左右子树节点作为根节点传入 - 第四部没有
- 返回 :就是返回root 因为以一个
- 第一步:
- 这个代码主要看我自己写的 官方的流程不咋地,还有就是有空关注一下别人写的 下面也有
![[leetcode刷题]汇总(一)_第17张图片](http://img.e-com-net.com/image/info8/d26ff6b5d7f14a509408d48d817ec66f.jpg)
- 官方写法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == nullptr) {
return nullptr;
}
TreeNode* left = invertTree(root->left);
TreeNode* right = invertTree(root->right);
root->left = right;
root->right = left;
return root;
}
};
- 我的写法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root)
{
//终止条件
if (root == nullptr)
{
return nullptr;
}
//当前层的逻辑处理
TreeNode* temp=root->left;
root->left=root->right;
root->right=temp;
//进入下一层 分别进入左子树和右子树
invertTree(root->right);
invertTree(root->left);
return root;
}
};
- 网友解答
/**
* 递归方式遍历反转
*/
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTree(root.left);
invertTree(root.right);
return root;
}
/**
* 层序遍历方式反转
*/
public TreeNode invertTreeByQueue(TreeNode root) {
if (root == null) {
return null;
}
Queue<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
TreeNode temp = node.left;
node.left = node.right;
node.right = temp;
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
return root;
}
/**
* 深度优先遍历的方式反转
*/
private TreeNode invertTreeByStack(TreeNode root) {
if (root == null) {
return null;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
int size = stack.size();
for (int i = 0; i < size; i++) {
TreeNode cur = stack.pop();
TreeNode temp = cur.left;
cur.left = cur.right;
cur.right = temp;
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
}
return root;
}
98 验证二叉搜索树(中等)
![[leetcode刷题]汇总(一)_第18张图片](http://img.e-com-net.com/image/info8/d7860a2275bd4f86b2fac239d28a2eab.jpg)
- 方法一:颜色标记法+递增判断
其实这个题一看到就想到了中序遍历,如果是递增的不就好了,看了题解 算是其中一种方法。开始我是把结果进行遍历比较,但是时间超时,后来修改成x - 方法二:思路和方法都写在了下面
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isValidBST(TreeNode* root) {
vector<int> result;
stack<pair<TreeNode*, int> > stk; //放入的这个类型 第一个是节点用来取值 第二个用来标记颜色
stk.push((make_pair(root, 0)));//一开始先把根放入 颜色是白色
while(!stk.empty())//如果栈不是空的就一直变量 知道全部处理好变灰色 然后取出来了
{
auto [node, type] = stk.top();//每次都取出看看
stk.pop();//取出记得删除
if(node == nullptr) continue;
if(type == 0)//如果是白色的 根据中序 先序后续放入
{
stk.push(make_pair(node->right, 0));
stk.push(make_pair(node, 1));
stk.push(make_pair(node->left, 0));
}
else
{
result.emplace_back(node->val);//否则灰色的我就输出
if(result.size()>=2)
{
if( result[result.size()-1]<=result[result.size()-2])
return false;
}
}
}
return true;
}
};
- 方法二,递归的方法
:他这个跟我想的不是很一样,我一直想把一个三角形作为一个部分进行一次比较,但是它不是,他就是把当前节点的值作为一个传入参数,传入左子树是放在大值那边,传入右子树是作为小值那边,对于另外一个参数用极大LONG_MAX和极小来表示LONG_MIN来表示 (非常巧妙)。 不过你想想也合理,我们对树进行递归的时候,不都是传入当前节点到(值或者数据到下个节点,也只能一边的比较也算合理)另外一个需要注意的是,我们这个结果一个返回值,和之前的不一样,不再是把递归的方程放在return前面而是放在return上面,return调用了两次的函数非常的巧妙,值得注意。
![[leetcode刷题]汇总(一)_第19张图片](http://img.e-com-net.com/image/info8/8d44005321e6462e8072630b326c1895.jpg)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isValidBST(TreeNode* root) {
bool ret = helper(root,LONG_MIN,LONG_MAX);
return ret;
}
bool helper(TreeNode* root,long long lower, long long upper)
{
if (root==nullptr)//迭代的结束条件
{
return true;
}
//当前层的逻辑事件
if (root -> val <= lower || root -> val >= upper)
{
return false;
}
//进入到下一层 这个不像之前每一层都有获得一些东西 把函数调用放在return前面 这边只要一个return 对或者错 所以把函数调用放在return
return helper(root -> left, lower, root -> val) && helper(root -> right, root -> val, upper);
}
};
104二叉树的最大深度(简单)
- 题目
![[leetcode刷题]汇总(一)_第20张图片](http://img.e-com-net.com/image/info8/a79e65e3fc1c4a30a831eccd4cc99eb6.jpg)
![[leetcode刷题]汇总(一)_第21张图片](http://img.e-com-net.com/image/info8/cb5dbf09f41440279c5de1c69bfed408.jpg)
个人领悟 感觉非常有道理
我怎么觉的这个更像是从最底层往上算的,函数一层一层往下铺开,但是计算结果从下网上一层一层传上来- 这个结束条件不是简单的返回层数,而是返回0, 因为返回上来才是得到结果
- 当前层的逻辑 , 就是比较下一层反传上来的结果的最大值+1,(刚好吧进入下一层也给做了)
- 返回值表示当前层及以下的高度。
- 在下面代码 第二个是修改的有注释的版本
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if (root == nullptr) return 0;
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
class Solution {
public:
int maxDepth(TreeNode* root)
{
if (root == nullptr)
{
return 0; //迭代结束条件
}
//当前层的逻辑事件 是不是可以理解成 把下一层的高度中大的+1(刚好把进入下一层给做完了)
int ret = max(maxDepth(root->left), maxDepth(root->right))+1;
//因为我就要一个返回值,所以函数调用放在最下面
//返回结果是把当前层的高度返回给上一层
return ret;
}
};
//其他人的写法
class Solution {
public int maxDepth(TreeNode root) {
if(root==null)
return 0;
int result1=1;
int result2=1;
result1+=maxDepth(root.left);
result2+=maxDepth(root.right);
if(result1>result2)
return result1;
else
return result2;
}
}
111 二叉树最小深度(简单)
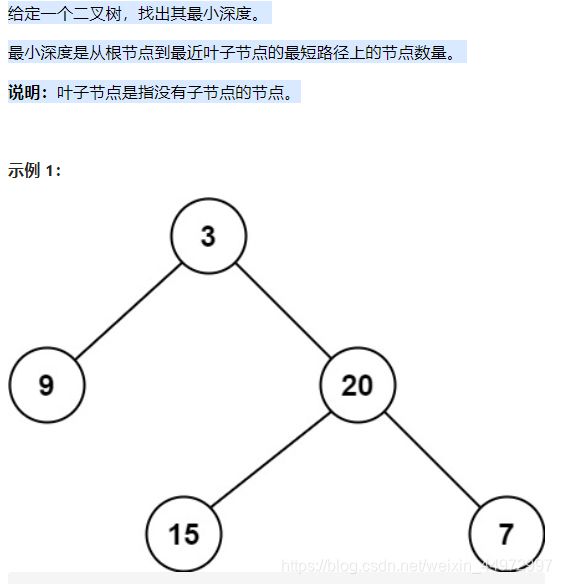
-
首先可以想到使用深度优先搜索的方法,遍历整棵树,记录最小深度。对于每一个非叶子节点,我们只需要分别计算其左右子树的最小叶子节点深度。这样就将一个大问题转化为了小问题,可以递归地解决该问题。
-
官方写法如下,同时我也把我的写法也放在下面了,更好理解
-
这个一定要区别最大深度,最大深度可以三步解决,最小深度不可以主要原因是(比如左子树为空 右字树很深 最大深度我们可以max 直接忽略深度为0的 但是最小深度直接min得到结果0 那是不行的(与定义不符合:根节点到最近叶结点的距离)。) -
所以这个题分成了很多种情况考虑非常重要
- 首先写出终止条件,如果节点为空,返回0,如果节点的左子树和右子树都为空,那就返回一(开始我也想不明白 但是你看我代码的注释,把实际的例子带进去就好理解了)
- 情况三:如果左子树空,右子树不为空,那高度就被右子树决定,可以直接返回右子树的高度+1
- 情况四:如果右子树为空,左子树不为空,那高度就被左子树决定,可以直接返回左子树的高度+1
- 情况五:都不为空,那就去左子树和右子树的最小值。调用两次,返回值是min+1
-
四步思考
-
步二:逻辑事件 就是返回当前层的最小高度(分成多种情况考虑)看上面,你要获得当前层的高度就要知道下一层的 所以返回值是min下一层+1 逻辑事件和进入下一层都考虑了
class Solution {
public:
int minDepth(TreeNode *root) {
if (root == nullptr) {
return 0;
}
if (root->left == nullptr && root->right == nullptr) {
return 1;
}
int min_depth = INT_MAX;
if (root->left != nullptr) {
min_depth = min(minDepth(root->left), min_depth);
}
if (root->right != nullptr) {
min_depth = min(minDepth(root->right), min_depth);
}
return min_depth + 1;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int minDepth(TreeNode *root) {
if (root == nullptr) {
return 0;
//你想想根节点传入的情况 是不是根节点都没有 不就是表示当前层为0
}
if (root->left == nullptr && root->right == nullptr)
//如果传入根节点,是不是左右节点都是空的 是不是表示当前层为1
{
return 1;
}
int min_depth = INT_MAX;
if (root->left != nullptr&&root->right==nullptr)//如果左节点为空,那就只能考虑右节点了 不能简单看做1,看看题目的例二
{
// min_depth = min(minDepth(root->left), min_depth);
min_depth= minDepth(root->left);
}
if (root->right != nullptr&&root->left==nullptr)//如果右节点为空,那就只能考虑左节点了
{
//min_depth = min(minDepth(root->right), min_depth);
min_depth=minDepth(root->right);
}
if(root->right!=nullptr&&root->left!=nullptr)
{
min_depth=min(minDepth(root->right),minDepth(root->left));
}
return min_depth + 1;
}
};
297 二叉树的序列化和反序列化(困难)
- 难度太高 暂时跳过
236 二叉树的最近公共祖先(中等)
-
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
-
当前层的逻辑条件就是看看
-
主要看第一个版本跟我想的是最相近的,首先我们一定要明确深度优先的迭代,就深到浅(
一定要明确 比如下面的图 先遍历左子树 再右子树顺序就是 3 5 6 2 7 4 1 0 8) -
当前层的逻辑就是
- 1 我们看看左子树是不是祖先,我的右子树是不是祖先(
所以需要进入下一层,通过返回结果判断)。是的话我就一层一层返回上去(这边通过设置了found标记为,如果在左子树找到了,右子树都不用判进去了,直接再次return), - 2 如果左子树就是那个点(p or q),我就把那个点(p or q)的值修改成跟的值
- 3 如果终于当前层的函数 p 和 q终于相同了 我就把found 改成true 返回这个节点
补充:就是真的很难想(就是你不断把p换成跟 推导上一层函数 它又发现子树就是是p 又把p换成跟实现了一种上传 。found是引用 全局唯一的 注意 。最后就变成当前层的函数传入的p和q是不是一样了)(你看他分的情况 基本上就是左子树不为空 右子树不为空 这两种情况 如果分成你空我不空应该也是可以的)
![[leetcode刷题]汇总(一)_第22张图片](http://img.e-com-net.com/image/info8/e56986f14e534a63b4a3fdcc088d71b6.jpg)
![[leetcode刷题]汇总(一)_第23张图片](http://img.e-com-net.com/image/info8/9bda1a24d52d4b1b8af8527d7344db9a.jpg)
![[leetcode刷题]汇总(一)_第24张图片](http://img.e-com-net.com/image/info8/afd520ad23e941bb9fce1edeccd041f5.jpg)
- 1 我们看看左子树是不是祖先,我的右子树是不是祖先(
![[leetcode刷题]汇总(一)_第25张图片](http://img.e-com-net.com/image/info8/f0d8b8a140f44494b2d1137ca2042873.jpg)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* search(TreeNode* root,TreeNode*p,TreeNode*q,bool &found)
{
if (root->left==NULL&&root->right==NULL)//迭代终止条件
{
return NULL;
}
//当前层的逻辑条件就是
if(root->left!=NULL)
{
TreeNode* nleft=search(root->left,p,q,found);
if(found) return nleft;//注意看这边 他返回的就是上一层的结果 可能是上上层的结果 反正就是一层一层返回上来的
if(root->left->val==p->val) p->val=root->val;
if(root->left->val==q->val) q->val=root->val;
if(p->val==q->val){found=true;return root;}//注意看这边
}
if(root->right!=NULL)
{
TreeNode* nright=search(root->right,p,q,found);
if(found) return nright;
if(root->right->val==p->val) p->val=root->val;
if(root->right->val==q->val) q->val=root->val;
if(p->val==q->val){found=true;return root;}
}
return NULL;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
bool found=false;
return search(root,p,q,found);
}
};
//评论写法
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root==p||root==q)//终止条件 就是找到了
{
return root;
}
if (root!=null)//跟节点不为空
{
TreeNode lNode=lowestCommonAncestor(root.left,p,q);//左节点传进去
TreeNode rNode=lowestCommonAncestor(root.right,p,q);//右节点传进去
if (lNode!=null&&rNode!=null)
return root;//表示找到了这个
else if(lNode==null)//左子树为空 右子树不为空 那就说明都在右子树
{//两个都在右子树
return rNode;
}
else { //两个都在左子树里面
return lNode;
}
}
return null;
}
}
//官方写法
class Solution {
public:
TreeNode* ans;
bool dfs(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == nullptr) return false;
bool lson = dfs(root->left, p, q);
bool rson = dfs(root->right, p, q);
if ((lson && rson) || ((root->val == p->val || root->val == q->val) && (lson || rson))) {
ans = root;
}
return lson || rson || (root->val == p->val || root->val == q->val);
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
dfs(root, p, q);
return ans;
}
};
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//这里是思考难点。定义规则:比如在某一棵子树上先找到了p,则无需继续遍历这棵子树,因为即使这棵子树有q,p也一定是q的祖先,也就是它们两个的最近公共祖先。
if(null == root || root.val == p.val || root.val == q.val) return root;
//按照上述规则,找到root的左子树的最近公共祖先。
TreeNode left = lowestCommonAncestor(root.left, p, q);
//按照上述规则,找到root的右子树的最近公共祖先。
TreeNode right = lowestCommonAncestor(root.right, p, q);
//一边找到了,一边没找到,根据上述规则,找到的就是最近公共祖先。
if(null == left) return right;
if(null == right) return left;
//如果在左右子树分别找到了p和q,则说明root是它们两个的最近公共祖先。
return root;
}
}
从前序与中序序列构建二叉树
![[leetcode刷题]汇总(一)_第26张图片](http://img.e-com-net.com/image/info8/28e6bacfdc04473bbd1ffba47dc21b1a.jpg)
- 其实这个题目呢怎么说呢看解法就很简单
说说当前层的逻辑事件吧 你想想最简单的三角形是不是创建一个root根节点 然后root挂上左节点和右接点 返回值就是一个当前层到以下的root地址。这边挂上节点就是挂上函数也就是进入了下一层 - 时间复杂度是0n 空间复杂度0n除了返回的空间大小 还有就是构建了哈西表方便01查询 中序序列的值作为键 下标作为值 每次我们知道前序的第一个为跟就去找中序的地址。
class Solution {
private:
unordered_map<int, int> index;
public:
TreeNode* myBuildTree(const vector<int>& preorder, const vector<int>& inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) {
if (preorder_left > preorder_right) {
return nullptr;
}
// 前序遍历中的第一个节点就是根节点
int preorder_root = preorder_left;
// 在中序遍历中定位根节点
int inorder_root = index[preorder[preorder_root]];
// 先把根节点建立出来
TreeNode* root = new TreeNode(preorder[preorder_root]);
// 得到左子树中的节点数目
int size_left_subtree = inorder_root - inorder_left;
// 递归地构造左子树,并连接到根节点
// 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素
root->left = myBuildTree(preorder, inorder, preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1);
// 递归地构造右子树,并连接到根节点
// 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素
root->right = myBuildTree(preorder, inorder, preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n = preorder.size();
// 构造哈希映射,帮助我们快速定位根节点
for (int i = 0; i < n; ++i) {
index[inorder[i]] = i;
}
return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);
}
};
77组合(中等)
-
给你一个n和k 从1-n中抽取k个有几种取法
-
回溯做的(听网上说 递归+for+取出,)
-
时间复杂度和空间复杂度如下
![[leetcode刷题]汇总(一)_第27张图片](http://img.e-com-net.com/image/info8/a801ec7a9e884f9f9b10cea0a4d218e4.jpg)
-
终止条件 个数达到要求
-
当前层的逻辑事件就是向数组里加一个数
具体实现就是一个for循环 内部加数字的 一个进入下一层的 还有一个就是删除一个pop,好好理解这个删除,每次满了退到上一层删除一个 然后又加一个
class Solution {
public:
vector<vector<int>> combine(int n, int k) {
dfs(n,k,1);
return Res;
}
vector<int> res;//这边的两个设为全局变量
vector<vector<int>> Res;
void dfs(int n, int k,int start)
{
if(res.size()==k)//终止条件
{
Res.push_back(res);
return;
}
for (int i = start;i<=n;i++)//
{
res.push_back(i);//添加数据
dfs(n,k,i+1);//注意第三个参数 就好像 1 那你只能从2 3 4后面选一个。好像2 你只能从 3 4中选择
res.pop_back();
}
}
};
46 全排列 (中等)![[leetcode刷题]汇总(一)_第28张图片](http://img.e-com-net.com/image/info8/17bfcc649d1c4dd88159c5083b2fb80c.png)
- 这个题我一看就觉的和组合是一样的 只不过push的不再是i 可以是a[i]不就好了,后来发现并不是
- 下面写了两个解法,注意关注第一个写法。
- 多了一个维护状态的数组,以及每次从0遍历
- 举个例子 0 1 2(表示下标 )第一次放入0 1 2很顺利,然后满了回复2的状态(并且删除2 这个时候for循环到顶了这个函数也结束了,回到1那一层函数(首先肯定也是清除1的状态 然后放入 2 进入下一层 下一层遍历从0开始 发现1没有标记 放入 满了 结束 就这样反反复复))

class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
class Solution {
public:
void backtrack(vector<vector<int>>& res, vector<int>& output, int first, int len){
// 所有数都填完了
if (first == len) {
res.emplace_back(output);
return;
}
for (int i = first; i < len; ++i) {
// 动态维护数组
swap(output[i], output[first]);
// 继续递归填下一个数
backtrack(res, output, first + 1, len);
// 撤销操作
swap(output[i], output[first]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > res;
backtrack(res, nums, 0, (int)nums.size());
return res;
}
};
回溯和分治
- 回溯和分治都是一种特别的递归
- 典型的回溯就是 22的括号生成
![[leetcode刷题]汇总(一)_第29张图片](http://img.e-com-net.com/image/info8/c4a94c0bd2e8486a8d0782bf7154ba52.jpg)
![[leetcode刷题]汇总(一)_第30张图片](http://img.e-com-net.com/image/info8/0faf87b78ccd4eb39f4802423a6ff58a.jpg)
![[leetcode刷题]汇总(一)_第31张图片](http://img.e-com-net.com/image/info8/05293acbba814849991ea7309adba1a0.jpg)
50 pow(x,n)(中等)
![[leetcode刷题]汇总(一)_第32张图片](http://img.e-com-net.com/image/info8/39c098b516354567835b621f5953ea67.png)
- 方法一就是一个for循环,时间复杂度就是0(n)
- 分治递归时间复杂度是0(logn)空间复杂度是0(logn)
- 四步走 :具体看下面注释 终止条件特别注意,不固定
- 比较奇怪的终止条件改成 ==1 会在提交报错
class Solution {
public:
double quickMul(double x, long long N) {
if (N == 0)//终止条件 等于1或许更好理解 可以改成1 一样的结果(下面的return 改成x)
{
return 1.0;
}
double y = quickMul(x, N / 2);//当前层的逻辑 获取上一层的结果(并且进入上一层了)
if (N % 2==0) //合并 偶数合并
{
return y*y;
}
else//奇数都乘x
{
return y*y*x;
}
}
double myPow(double x, int n) {
long long N = n;
if(N>0)//技术处理 如果n是负数的情况
{
double res = quickMul(x, N) ;
return res;
}
else
{
double res = 1.0/quickMul(x, -N);
return res;
}
}
};
78 子集(中等)
- 思想就是距离长度为3,每个位置有两种可能,选或者不选,让我们联想括号的那个题目(那个括号确实选择左括号或者右括号 通过回溯的办法,走了左括号 退回来了 又走了右括号)
- 定义了两个动态数组,传入参数是当前下标(位置)已经nums数据集
- 结束条件就是当前位置走到了头==size
- 当前层的逻辑就是(两种情况 放入-进入下一层 不放入进入下一层(就是啥都不做进入就可以了)。不需要if判断 但是需要在放入的那种情况下 ,
删除这层放入的)(模拟一下 一开始放入1 2 3然后立马执行进入dfs 判断发现满了 退出这个dfs 就走到了pop删除 把3删除了。然后走第二个dfs发现不放入,1 2 这个函数走完了,退出上一层也结束了(第二个dfs所以退出到底了),再推到上一层(回到第一个dfs),开始删除2了)所以是删除当前层
![[leetcode刷题]汇总(一)_第33张图片](http://img.e-com-net.com/image/info8/b227cd172709416baaad0d2adb4be6b9.png)
切记 放入和不放入位置可以互换
![[leetcode刷题]汇总(一)_第34张图片](http://img.e-com-net.com/image/info8/7e0b2971e0cb495696d392280da300bc.png)
class Solution {
public:
vector<int> t;//全局变量
vector<vector<int>> ans;//全局变量
void dfs(int cur, vector<int>& nums) {
if (cur == nums.size())//终止条件 当前位置等于总长度
{
ans.push_back(t);//cur 表示的是当前位置
return;
}
//选择考虑当前位置
t.push_back(nums[cur]);
dfs(cur + 1, nums);//进入下一层(下一个位置)
t.pop_back();//什么时候删除,走出来函数就删除
//考虑不走当前位置
dfs(cur + 1, nums);
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(0, nums);
return ans;
}
};
169 多数元素(简单多频)
- 题目:给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
- 方法一:哈希
- 具体的数值作为键。数量作为值,创建两个变量去维护(最大值值 最大值键 到时候好直接返回)或者结束了再返回也行。时间复杂度和空间复杂度都是o(n)
class Solution {
public:
int majorityElement(vector<int>& nums) {
unordered_map<int, int> counts;
int majority = 0, cnt = 0;
for (int num: nums) {
++counts[num];
if (counts[num] > cnt) {
majority = num;
cnt = counts[num];
}
}
return majority;
}
};
- 方法二:这个更绝了,因为数量多出一半,所以排序完 中间的那个数一定是多数
class Solution {
public:
int majorityElement(vector<int>& nums) {
sort(nums.begin(), nums.end());
return nums[nums.size() / 2];
}
};
- 方法三:分治(找他子问题的众数来判断我的众数,判断准则如下)
- 情况一:如果两个子序列的众数相同,说明这个序列的众数就是这个
- 情况二:如果两个序列的众数不同,那就分别在当前序列遍历,统计这两个子序列的众数谁多作为当前序列的众数。
- 迭代结束条件,子序列的头和尾都是同一个,也就是只有一个,他的众数就是本身直接返回。
- 本层的逻辑就是,重新确定子序列的头尾,
- 进入下一层,进入左 进入右
- 汇总子结果(
这边通过子结果来判断确定当前层的结果,这不就是分治要的么)
class Solution {
int count_in_range(vector<int>& nums, int target, int l, int r)
//辅助函数,用来统计一个数在一个序列中出现的次数
{
int count = 0;
for (int i = l; i <= r; ++i)//注意这边是《=
if (nums[i] == target)
++count;
return count;
}
int helper(vector<int>& nums, int l, int r) {
if (l == r)//迭代结束条件
return nums[l];
int mid = (l + r) / 2;//逻辑事件
int left_majority = helper(nums, l, mid);
int right_majority = helper(nums, mid + 1, r);
//memgr 汇总子结果
//如果子序列众数相同 直接返回
if (left_majority==right_majority) return left_majority;
//否则谁在本序列多 谁就是本序列的众数 注意这边的l和r边界
int left_count = count_in_range(nums, left_majority, l, r);
int right_count = count_in_range(nums, right_majority, l, r) ;
return left_count>right_count?left_majority:right_majority;
}
public:
int majorityElement(vector<int>& nums) {
return helper(nums, 0, nums.size() - 1);
}
};
17 电话号码的字母组合(中等)(多看看 总结一下)
- 视频说道这个和左括号 右括号的很像(和子集也很像),就是两个格子 不是a就是b或者c,只不过这边有3个或者4个选项。
不能是两个if 而是一个for循环,理解一下这边,本质上是一样的。还有全排列都是一样的
![[leetcode刷题]汇总(一)_第35张图片](http://img.e-com-net.com/image/info8/03a10ce93bfb43da978b47b060503da8.jpg)
cclass Solution {
public:
vector<string> letterCombinations(string digits) {
vector<string> combinations;//最终返回的结果集
if (digits.empty()) //特判
{
return combinations;
}
unordered_map<char, string> phoneMap//构建一hash树
{
{'2', "abc"},
{'3', "def"},
{'4', "ghi"},
{'5', "jkl"},
{'6', "mno"},
{'7', "pqrs"},
{'8', "tuv"},
{'9', "wxyz"}
};
string combination;//一维的数据结果集
//参数一是结果集 参数二是树 参数三是题目的数据集 参数四是第几个放入位置了 参数五是 一维数据结果集
backtrack(combinations, phoneMap, digits, 0, combination);
return combinations;
}
//注意这边传入的都是引用 对同一个对象进行操作 所以每次都要pop回溯
void backtrack(vector<string>& combinations, const unordered_map<char, string>& phoneMap, const string& digits, int index, string& combination)
{
if (index == digits.length()) //如果当前放入的位置=长度(从0开始)放入 直接return 结束就好
{
combinations.push_back(combination);
return ;
}
//这两步就是为了下面for循环服务
char digit = digits[index];//取出数字
const string& letters = phoneMap.at(digit);//取出英文
for (int i=0;i<letters.size();i++)//遍历英文
{
combination.push_back(letters[i]);//经典 放入 函数 删除
backtrack(combinations, phoneMap, digits, index + 1, combination);//位置记得+1
combination.pop_back();
}
}
};
51 N皇后问题(困难 大概理解)具体后面再看
- 做到这边谈谈对回朔的几个理解
- 第一个版本 for +递归+判断 不要for的每一个情况都走
- 第二个版本:撤销重复 对同一个变量
- 这个题就好像一格一格往下移动,不可以跳过,可以深入,下次回溯。
- 代码随想录里面有讲解
- 题目是:任意两个棋子不能同行 同列 同斜线
参考链接
视频参考
- 回溯算法其实就是暴力搜索
class Solution {
private:
vector<vector<string>> result;
// n 为输入的棋盘大小
// row 是当前递归到***的第几行了
void backtracking(int n, int row, vector<string>& chessboard) {
if (row == n) {
result.push_back(chessboard);
return;
}
for (int col = 0; col < n; col++) {
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
chessboard[row][col] = 'Q'; // 放置皇后
backtracking(n, row + 1, chessboard);
chessboard[row][col] = '.'; // 回溯,撤销皇后
}
}
}
bool isValid(int row, int col, vector<string>& chessboard, int n) {
int count = 0;
// 检查列
for (int i = 0; i < row; i++) { // 这是一个剪枝
if (chessboard[i][col] == 'Q') {
return false;
}
}
// 检查 45度角是否有皇后
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
// 检查 135度角是否有皇后
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
public:
vector<vector<string>> solveNQueens(int n) {
result.clear();
std::vector<std::string> chessboard(n, std::string(n, '.'));
backtracking(n, 0, chessboard);
return result;
}
};
补充
![[leetcode刷题]汇总(一)_第36张图片](http://img.e-com-net.com/image/info8/74bb20802a5046fca2f1c0b02d5d23e1.jpg)
深度优先搜索和广度优先搜索
102 二叉树的层次遍历(中等)
- 其实这个和之前我们做n叉树的层次遍历一样,但是注意这次的写法,比如说没有标记位了 用 for循环来替代了,很多细节需要注意的地方
- 比如一维用来存放的临时变量 每一次for循环之前都重新创建
- 还有就是很多在注释都有
同时可以看看我修改的flat的版本,区别在于 第一个版本是for循环结束吧一维答案放入二维 第二个版本是在标志位识别到了。全局 和局部变量
//代码随想录写法
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root)
{
queue<TreeNode*> que;//创建了一个队列存放节点
if (root != NULL)//初始把跟节点放入
{
que.push(root);
}
vector<vector<int>> result;//存放一个放返回值的
while (!que.empty())//队列不为空
{
int size = que.size();//统计队列的大小
//这边创建的是临时变量 就不用清空了 每一次执行for循环之前
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++)
{
TreeNode* node = que.front();//取出
que.pop();//删除
vec.push_back(node->val);//把值放入
if (node->left) que.push(node->left);//把左节点放入
if (node->right) que.push(node->right);//把右节点放入
}
result.push_back(vec);
}
return result;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root)
{
vector<vector<int>> ret;
queue<TreeNode*> que;
vector<int> vec;
int flat=1;
if(root!=NULL)
{
que.push(root);
}
while(!que.empty())
{
TreeNode* node = que.front();//每次取出来一个
que.pop();
vec.push_back(node->val);//把值放入
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
flat--;
if(flat==0)
{
ret.push_back(vec);//二维存入一维
flat=que.size();
vec.clear();
}
}
return ret;
}
};
433最小基因变化(中等)
- 先不要看这个题,你先去看看单词接龙的那个题,一模一样的,唯一的区别在于这边是返回变化的次数,单词那个是返回长度,所以这边初始值都为0
![[leetcode刷题]汇总(一)_第37张图片](http://img.e-com-net.com/image/info8/5acd95e0467d496e875c26f2a1f41f50.png)
class Solution {
public:
int minMutation(string start, string end, vector<string>& bank) {
// 将vector转成unordered_set,提高查询速度
unordered_set<string> wordSet(bank.begin(), bank.end());
// 如果end没有在wordSet出现,直接返回0
if (wordSet.find(end) == wordSet.end()) return -1;
// 记录word是否访问过
unordered_map<string, int> visitMap; // 22 括号生成(中等)(重复了)
- 第二次复习l,出现在这边是希望用广度优先来实现一下,
- 我们认真看看深度优先回溯的步骤(代码随想录的) 反正我就感觉这种子集 切割 组合 全排列。每一个字符都是一个待填入的各自,选择非a就是b 有时候多个就是for循环 非a就b要不c,看看下面的三步走
- 这边的两个if 不就是for循环的两个可能么
void back(参数)
{
if(终止结果)
存放结果
return
for(选择 本层集合中的元素)
{
处理节点;一般不就是放入:
back()递归
回溯 pop 撤销
}
}
class Solution {
void backtrack(vector<string>& ans, string& cur, int open, int close, int n) {
if (cur.size() == n * 2) //结束条件
{
ans.push_back(cur);
return;
}
if (open < n) {
cur.push_back('(');//步二
backtrack(ans, cur, open + 1, close, n);//步三
cur.pop_back();//步四
}
if (close < open) {
cur.push_back(')');
backtrack(ans, cur, open, close + 1, n);
cur.pop_back();
}
}
public:
vector<string> generateParenthesis(int n) {
vector<string> result;
string current;
backtrack(result, current, 0, 0, n);
return result;
}
};
515 在每行树行中找最大值(中等)
这个体和之前的没有任何区别,多一个判断,很常见的方法多哦一个变量 int maxValue = INT_MIN;
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);//老样子 初始把值放入
vector<int> result;//这次不需要二维了
while (!que.empty())
{
int size = que.size();
int maxValue = INT_MIN; // 取每一层的最大值 这个也是临时变量 每次for循环之前都要初始化
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
if(node->val>maxValue)
{
maxValue=node->val;
}
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(maxValue); // 把最大值放进数组
}
return result;
}
};
127 单词接龙(困难)
- 代码随想录的代码讲解很不错哦
- 根据别人写的总结,自己来捋一捋
![[leetcode刷题]汇总(一)_第38张图片](http://img.e-com-net.com/image/info8/369193dd85ad42a8ada6c6c7e7ea1ff2.jpg)
- 所以这道题要解决两个问题:
- 图中的线是如何连在一起的
- 起点和终点的最短路径长度
- 首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个,所以
判断点与点之间的关系,要自己判断是不是差一个字符,如果差一个字符,那就是有链接。 然后就是求起点和终点的最短路径长度,这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径。因为广搜就是以起点中心向四周扩散的搜索。这边我说说自己的想法:第一层只有一个单词,第二层是修改了一个字母的单词,第三层再修改了一个字母的单词,如果深搜右边的路径比左边的多很不对,如果是广搜,第几层就是第几步(你想想我们广搜用队列是不是一层一层的处理的,在那一层不是很容易知道)- 需要注意的点
- 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
- 本题给出集合是数组型的,可以转成set结构,查找更快一些
广搜的一般步骤,我自己写的看看我写伪代码,有一个不同就是size的含义变了,之前表示一层的数量,现在一个单词就是单独的一次,因为有map记录他的路径(第几层),不怕他乱掉了
在开始可能初始一些数组(比较常见的层次遍历就是练两个数组) 或者 map(这边就是map);
首先就是把根节点放入队列;
一个while(队列不为空)
{
每次取出一个;
删除这个;
//如果是树层次遍历;
我们常常这边统计size(这个size就是一层的数量呗)
通过size构建for循环
{
进行操作
}
}
![[leetcode刷题]汇总(一)_第39张图片](http://img.e-com-net.com/image/info8/24ac1e1b1e16458d98a5a92cb473ba29.jpg)
//我们这题的伪代码
1 创建了一个unordered_set 存放wordlist(方便后期查询在不在这边)
2 进行特判,wordSet.find(endWord) == wordSet.end()。如果最终要的单词不在这边那就直接结束
3 unordered_map<string, int> visitMap;创建map用来存储修改的单词和路径,同时可以用来判断走没走过
4 初始化队列 que
5 队列放入初始的beginword 根
6 把beginword 和 路径长度1插入 map中
7 while(队列非空)
8 取出队列中的一个
9 删除队列最前面的那个
10 通过map输出这个单词的路径方便后面通过他的改造都+1
11 两个for循环 第一次for循环遍历的是单词的起始位到尾巴,第二个循环是字母a到z的选择(这次这个size不用写在for之前,因为它不会变化了,但是之前的会 需要注意)
12 把修改的字母判断是不是结果是的化直接返回path+1
13 判断这个单词是不是在set中,出现了,并且没出现在map中(新单词并且是在字典里面)(同时满足,那就添加到map中并且路径+1 )
14 队列中添加这个单词
15 特别注意这个,如果全部便利完了都没找到 while退出记得返回0
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
// 将vector转成unordered_set,提高查询速度
unordered_set<string> wordSet(wordList.begin(), wordList.end());
// 如果endWord没有在wordSet出现,直接返回0
if (wordSet.find(endWord) == wordSet.end()) return 0;
// 记录word是否访问过
unordered_map<string, int> visitMap; // ![[leetcode刷题]汇总(一)_第40张图片](http://img.e-com-net.com/image/info8/a21105d844c746a4bb5fd0df46696a6b.png)
126 单词接龙(困难)高频 升级版本
![[leetcode刷题]汇总(一)_第41张图片](http://img.e-com-net.com/image/info8/90cb171e6c534d078704178af2e320dc.png)
- 主要看看上一个的解法
- 这个也太长了,选择放弃,感觉知道长度还要知道那个路径太复杂了
#include 200 岛屿数量(中等)(二叉树的深度遍历到图和网格)
![[leetcode刷题]汇总(一)_第42张图片](http://img.e-com-net.com/image/info8/5e8b4acb0a5645c7bb448d099fa88d6b.png)
![[leetcode刷题]汇总(一)_第43张图片](http://img.e-com-net.com/image/info8/7406251e33c746a9ac04d760e5546aec.png)
- 一个方法就是遇到一个1 ,就是把1旁边的陆地都炸为0,最后遍历一遍,还剩下几个1. 深度优先的方法。
参考链接 - 第一个代码写的非常好,我自己根据别人写的修改的,符合深度优先的框架。
- 迭代终止条件就是: 当前坐标点超出边界直接返回,
- 当前层的逻辑就是,如果遇到海或者走过的直接返回就行,如果遇到1岛屿就把他标记成海(但是这边不用0 是为了防止一直转圈圈,文章有写),
- 进入下一层,开始探索四个方向(
对比一下二叉树深度优先进入左右) - 还有一个不同的就是两个for循环走遍一个网格,遇到岛屿就开始深度搜索,这不是一个二叉树,你可以理解成一个网格数量的二叉树
非常重要,好好看下面的
![[leetcode刷题]汇总(一)_第44张图片](http://img.e-com-net.com/image/info8/52e8b1d337bd4c43b721e57724e93643.jpg)
![[leetcode刷题]汇总(一)_第45张图片](http://img.e-com-net.com/image/info8/ce54899316c149dba47bf7c533d31529.jpg)
![[leetcode刷题]汇总(一)_第46张图片](http://img.e-com-net.com/image/info8/18b6e73268d2413aa7ee187e801a7673.jpg)
![[leetcode刷题]汇总(一)_第47张图片](http://img.e-com-net.com/image/info8/0a79d461c7dc4709830b1e3331b6d56d.jpg)
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
dfs(grid, r, c);
}
}
}
return num_islands;
}
bool inArea(vector<vector<char>>& grid,int r,int c)
{
return 0 <= r && r < grid.size() && 0 <= c && c < grid[0].size();
}
void dfs(vector<vector<char>>& grid, int r, int c)
{
if (!inArea(grid,r,c))//如果到达边界直接返回
{
return;
}
if(grid[r][c] != '1')//表示是海或者标记过了 注意这边 设置为2 就是为了防止一直转圈圈
{
return;
}
grid[r][c]=2;//把格子标记位已遍历过的 当前层的逻辑 就是
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
};
class Solution {
private:
void dfs(vector<vector<char>>& grid, int r, int c) {
int nr = grid.size();
int nc = grid[0].size();
grid[r][c] = '0';
if (r - 1 >= 0 && grid[r-1][c] == '1') dfs(grid, r - 1, c);
if (r + 1 < nr && grid[r+1][c] == '1') dfs(grid, r + 1, c);
if (c - 1 >= 0 && grid[r][c-1] == '1') dfs(grid, r, c - 1);
if (c + 1 < nc && grid[r][c+1] == '1') dfs(grid, r, c + 1);
}
public:
int numIslands(vector<vector<char>>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
dfs(grid, r, c);
}
}
}
return num_islands;
}
};
贪心算法
![[leetcode刷题]汇总(一)_第48张图片](http://img.e-com-net.com/image/info8/5a921c7769cd4a0e928233d90a024df8.jpg)
![[leetcode刷题]汇总(一)_第49张图片](http://img.e-com-net.com/image/info8/4c1b9747b1d443fd9b6d1eb0aa9fa928.jpg)
- 例如求最小生成树,求哈夫曼编码等。
![[leetcode刷题]汇总(一)_第50张图片](http://img.e-com-net.com/image/info8/3ec9ba169d574288b968ce018e1ff3ab.jpg)
322 零钱兑换(简单)
![[leetcode刷题]汇总(一)_第51张图片](http://img.e-com-net.com/image/info8/b5a73581c477457d9d27e2334e1ce1b2.png)
![[leetcode刷题]汇总(一)_第52张图片](http://img.e-com-net.com/image/info8/d249ba63234a497a87d978b6dd59292a.jpg)
455 分发饼干(简单)
- 贪心,每阶段选取局部最优,最后达到一个全局最优
- 这边有代码随想录的,好好看
- 这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩。
- 可以尝试使用贪心策略,先将饼干数组和小孩数组排序。然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
- 从代码中可以看出我用了一个index来控制饼干数组的遍历,遍历饼干并没有再起一个for循环,而是采用自减的方式,这也是常用的技巧。有的同学看到要遍历两个数组,就想到用两个for循环,那样逻辑其实就复杂了。
- 注意一下这边的
时间复杂度和空间复杂度,两次排序都是nlogn 然后便利是n 相加取大的,那就是nlogn
![[leetcode刷题]汇总(一)_第53张图片](http://img.e-com-net.com/image/info8/b4b185978b3c48468885c852e2cae804.jpg)
// 时间复杂度:O(nlogn)
// 空间复杂度:O(1)
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s) {
sort(g.begin(), g.end());
sort(s.begin(), s.end());
int index = s.size() - 1; // 饼干数组的下表
int result = 0;
//这边遍历的是孩子,其实饼干没必要走完,假设最大的饼干没有一个符合,那你有必要找次小的遍历么
for (int i = g.size() - 1; i >= 0; i--)
{
if (index >= 0 && s[index] >= g[i])//如果饼干比胃口大并且饼干没遍历完 就是把饼干分配完了 这边 要注意
{
result++;//符合+1
index--;//饼干前移
}
}
return result;
}
};
122买股票的最佳时机2(简单)
![[leetcode刷题]汇总(一)_第54张图片](http://img.e-com-net.com/image/info8/43fa970e89974445928953636b11d8f7.png)
- 需要注意的是你要在买入之前卖出去之前那个
![[leetcode刷题]汇总(一)_第55张图片](http://img.e-com-net.com/image/info8/18e61ed8d9af4dcaa97ab605bfbc7ade.jpg)
![[leetcode刷题]汇总(一)_第56张图片](http://img.e-com-net.com/image/info8/666177228cb340eaabe91f662d939ae9.jpg)
- 我觉的评论有一个解释很合理,就是, 简单理解就是如果今天股票跌了, 那就就取昨天的最大利润, 如果今天涨了那就是把昨天的卖掉今天再买进, 两种情况取个最大值
class Solution {
public:
int maxProfit(vector<int>& prices) {
int ans = 0;
int n = prices.size();
//这个就是不断对比今天比昨天涨了还是亏了 如果涨了,哪怕昨天卖掉了,那我就当作买回来,今天卖(这个差价相加就等于第一天买 第三天卖)
for (int i = 1; i < n; ++i)
{
ans += max(0, prices[i] - prices[i - 1]);
}
return ans;
}
};
860 柠檬水找零(简单)
![[leetcode刷题]汇总(一)_第57张图片](http://img.e-com-net.com/image/info8/6362bb2f4ce145d4b8f6f11c2c1c987f.png)
![[leetcode刷题]汇总(一)_第58张图片](http://img.e-com-net.com/image/info8/dff0f309a09d4553869636ad9b9e807d.jpg)
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0;
for (auto& bill: bills) {
if (bill == 5) {
five++;
} else if (bill == 10) {
if (five == 0) {
return false;
}
five--;
ten++;
} else {
if (five > 0 && ten > 0) {
five--;
ten--;
} else if (five >= 3) {
five -= 3;
} else {
return false;
}
}
}
return true;
}
};
874模拟行走机器人(简单)
- 其实这个题看不出贪心算法不知道他们怎么想的
- 思想
- ①:构造dir_x、dir_y,表示向当前方向前进一步时,x,y坐标的变化情况;
- ②:用status记录当前状态,初始值为0,表示向正北方前进,当指令command=-1时,status+1;当command=-2时,status+3(保证不会出现负数的情况);通过取余操作(%4)获取当前状态;
- ③用set记录所有障碍点,如果向前前进一步遇到障碍点时,则进行下一次指令,否则更新坐标。
class Solution {
public:
int robotSim(vector<int>& commands, vector<vector<int>>& obstacles) {
int dir_x[4] = {0, 1, 0, -1};//这边分别表示 北 东 南 西 方向 走一步坐标变化
int dir_y[4] = {1, 0, -1, 0};
int x = 0;
int y = 0;
int status = 0;
int max_distance = 0;
//这边还是有点讲究的,你用map存入两个值怎么比较呢 应该也可以 但是吧pair看做一个值用set就简单了
set<pair<int, int>> obstacleSet;
for (vector<int> obstacle: obstacles)//把障碍放在hash里面
obstacleSet.insert(make_pair(obstacle[0], obstacle[1]));
for (int i;i<commands.size();i++)//遍历每一个指令
{
if (commands[i] == -2)//调整方向
status = (status + 3) % 4;
else if (commands[i] == -1)//调整方向
status = (status + 1) % 4;
else //只走 修改坐标
{
for (int k = 0; k < commands[i]; ++k)//一步一步走
{
int next_x = x + dir_x[status];//根据状态选择 x 是+1-1还是不变
int nexr_y = y + dir_y[status];//根据状态选择 y 是+1-1还是不变
//判断有没有遇到障碍
if (obstacleSet.find(make_pair(next_x, nexr_y)) == obstacleSet.end())
{
x = next_x;
y = nexr_y;
//不断比对最大距离
max_distance = max(max_distance, x*x + y*y);
}
}
}
}
return max_distance;
}
};
55跳跃游戏(中等)
![[leetcode刷题]汇总(一)_第59张图片](http://img.e-com-net.com/image/info8/efe65d5c0d72443d90e1526b3d01b96e.png)
- 这边有代码随想录的讲解,我觉的讲的很好
- 其实跳几步无所谓,关键在于可跳的覆盖范围!不一定非要明确一次究竟跳几步,每次取最大的跳跃步数,这个就是可以跳跃的覆盖范围。这个范围内,别管是怎么跳的,反正一定可以跳过来。
那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!- 每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点,但是有一个很重要的:就是在代码中你要判断当前的最大距离能不能支持走到下一个点,毕竟可以走0。
class Solution {
public:
bool canJump(vector<int>& nums) {
int size = nums.size() ;
if (size == 1) return true; // 只有一个元素,就是能达到
int max_instance=0;
for (int i = 0; i <= size; i++)
{ // 注意这里是小于等于cover
if(i<=max_instance)
{
max_instance = max(i + nums[i], max_instance);
if (max_instance >= nums.size() - 1) return true; // 说明可以覆盖到终点了
}
}
return false;
}
};
45 跳跃游戏二(中等)
- 和上一题不一样的是多了一个要求,使用最少的跳跃次数到达数组的最后一个位置。
![[leetcode刷题]汇总(一)_第60张图片](http://img.e-com-net.com/image/info8/186f8a3538184b4785884449b74e2a10.png)
-
- 这个不是官方题解,但是沿用1的思路,我们第一次跳跃范围都可以第二次起跳的点。然后我们就看看第几题起跳能到达终点,很棒的思路
int jump(vector<int>& nums)
{
int ans = 0;
int end = 0;
int maxPos = 0;
for (int i = 0; i < nums.size() - 1; i++)
{
maxPos = max(nums[i] + i, maxPos);
if (i == end)
{
end = maxPos;
ans++;
}
}
return ans;
}
![[leetcode刷题]汇总(一)_第61张图片](http://img.e-com-net.com/image/info8/80c9db1e24024b00b35182795f489246.jpg)
- 没有优化的版本如下
int jump(vector<int> &nums)
{
int ans = 0;
int start = 0;
int end = 1;
while (end < nums.size())
{
int maxPos = 0;
for (int i = start; i < end; i++)
{
// 能跳到最远的距离
maxPos = max(maxPos, i + nums[i]);
}
start = end; // 下一次起跳点范围开始的格子
end = maxPos + 1; // 下一次起跳点范围结束的格子
ans++; // 跳跃次数
}
return ans;
}
作者:ikaruga
链接:https://leetcode-cn.com/problems/jump-game-ii/solution/45-by-ikaruga/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二分查找
