使用Pytorch的一些小细节(一)
文章目录
- 前言
- 数据结构-张量
-
- max函数
- 索引函数
- 赋值函数
- 拼接函数
前言
由于不经常动手写代码,所以对于python语言中的常见数据结构的用法也不是很熟悉,对于pytorch中的数据结构就更加不熟悉了。之前的代码基础是基于C语言的,属性都是自己定义,值传递或者引用传递都是自己定义,而在python中就没有区分的这么清楚,所以让我对一些概念或者数据结构用法存在疑惑,尤其是使用pytorch的过程中,所以专门做个笔记。
ChatGPT有句话说的很好,“小心使用,以确保结果符合您的预期。”为了确保结果符合我们心中的预期,所以在编写代码的过程中需要对每个函数的输入与输出进行验证,而在每个函数中我们又使用了别的API函数,层层嵌套,所以我们要想验证一个函数的输入输出符合预期,就需要对输入输出进行验证。每一步都是为了结果符合预期。
数据结构-张量
max函数
torch.max函数对于一个二维张量size=(a,b)的效果为:
torch.max(next_q_values,dim=1)
#返回值
torch.return_types.max(
values=tensor([0.1055, 0.0693, 0.1055, 0.1071, 0.0456, 0.0544, 0.0671, 0.0859, 0.0946,
0.0770]),
indices=tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1]))
#后面加上索引1
torch.max(next_q_values,dim=1)[1]
#结果:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
也就是说torch.max函数当参数dim为多少时,它的取极大值的过程就是针对这个维度进行的,让其他维度保持不变的情况下,取max,然后让其他维度递增,再取max。
索引函数
对于张量来说,索引加括号与不加括号差别也很大。使用加括号的形式叫做花式索引,花式索引(Fancy Indexing)是一种在NumPy和其他类似的数组库比如Pytorch中常见的索引方式,它允许您使用一个数组来索引另一个数组的元素。常见的索引方式就是给每个维度赋值然后索引D[a,b],花式索引就是在每个维度的位置上,用数组来赋值D[[ ],[ ]],可以把第一个维度当作希望生成的形状,并且把对应元素的行标上去,然后第二个维度的形状不用发生变化,只用把对应元素的列标上去即可,比如说我们想从原始数据中生成一个新的数组尺寸为(2,3),新数组B中各个位置的元素与原数组A的关系为:

那么我们可以使用如下的命令:A[[[2,1,2],[1,0,0]],[[1,1,2],[1,2,1]]]。注意我们的索引第一个维度就是每个元素所对应的行的重新排列,索引的第二个维度就是每个元素所对应的列的重新排列。同时需要注意,这种索引形式得到的值都是相当于值引用。如果我们对索引出来的值进行赋值操作,就会导致原来数组中的元素发生变化,因为它就相当于索引赋值。
提起索引不得不提到Python中臭名昭著的赋值语句,赋值语句时常让我迷惑他究竟是值传递还是引用传递。目前看来只有整数和浮点数数据类型是值传递,其他的一律是引用传递,哪怕是GPT宣称列表也是值传递也是假的,列表也是引用传递。比如:
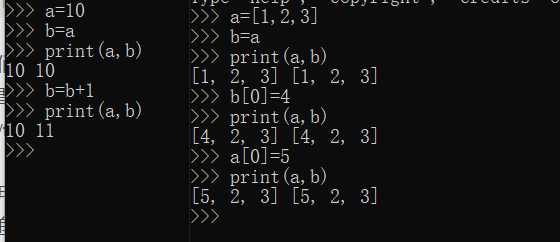
对于非整数或者浮点数的合成数据类型,就更是引用传递了,哪怕是torch.tensor(1)也是引用传递。
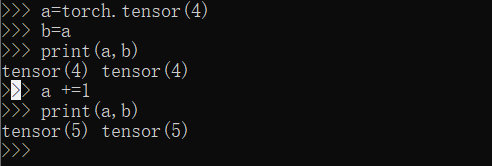
对于Pytorch中的张量数组来说也是这样:
b=torch.tensor([[1.1,2.2,3.3,4.4],[0.1,0.2,0.3,0.4],[-1,-2,-3,-4]])
print(b[0,1].shape)
#结果 torch.Size([])
print(b[[0],[1]].shape)
#结果 torch.Size([1])
print(b[[0,1],[1,0]].shape)
#结果 torch.Size([2])
其实引用传递往往要与原地修改相辅相成,如果两个变量是同一引用,但是其中一个变量修改的时候并不是原地修改,就不会导致另一个变量发生同步变化。所以要想同步改变,我们就要使用原地修改。
原地修改的常见类型有:索引赋值,简写递推(+=、-=、*=、/=)等。
如果我们不希望同步变化,那么我们有两种办法:第一不使用引用,或者说使用引用克隆;第二不使用原地修改,对于指向同一引用的对象,在更新对象的值时,不使用原地修改的函数。第二种方法稍微难做一点,因为我们在pytorch中处理张量数据时,很容易就会对张量进行索引赋值,而这种方式恰恰是会造成原地修改的,也就是会导致同步变化的。所以在保存变量时,尽量保存变量的克隆,这样就会避免同步变化。
在pytorch中不使用引用可以分为两种情况。第一种是不保存梯度的detach()方法,但是数据区共享,所以还是有引用的,只不过没有梯度了;第二种数据区也不共享,梯度也不保存的是clone()方法,数据区不共享,梯度应该也不会受到影响。可以是
赋值函数
赋值函数或者可以叫做索引函数,毕竟是先找到位置才能进行赋值的。对于张量来说,对第一个维度进行索引,就会得到第一个维度所对应的那些数据。如果我们在两个维度都用列表来索引,得到的就是单个元素所拼接的张量
对于一个二维张量size=(a,b),相对其中某些位置上的元素进行赋值的操作为:
target_q_values[range(batch_size),actions]=rewards+0.9*(1-dones)*torch.max(next_q_values,dim=1)[0]
其实为了分清楚究竟是引用传递还是值传递,我们应该用这样的提示词进行搜索:python中数组的原地修改的操作有哪些?python中numpy数组的原地修改的操作有哪些?pytorch的tensor张量的原地修改操作有哪些??
以下是chatGPT的回答:
在PyTorch中,张量(tensor)是核心数据结构,提供了许多原地修改的操作。以下是一些常见的原地修改操作:
-
索引赋值运算:
直接对张量的元素进行赋值操作,会原地修改张量。import torch my_tensor = torch.tensor([1, 2, 3]) my_tensor[0] = 4 # 原地修改,不创建新对象 -
add_()、sub_()等方法:
类似于赋值运算,这些方法在原地执行加法、减法等操作。import torch my_tensor = torch.tensor([1, 2, 3]) my_tensor.add_(1) # 原地修改,不创建新对象,等价于+= my_tensor +=1 -
mul_()、div_()等方法:
类似于add_(),这些方法在原地执行乘法、除法等操作。import torch my_tensor = torch.tensor([1, 2, 3]) my_tensor.mul_(2) # 原地修改,不创建新对象 -
zero_()方法:
将张量所有元素设为零。import torch my_tensor = torch.tensor([1, 2, 3]) my_tensor.zero_() # 将所有元素设为零,原地修改 -
fill_()方法:
将张量所有元素填充为指定值。import torch my_tensor = torch.tensor([1, 2, 3]) my_tensor.fill_(5) # 将所有元素填充为5,原地修改
这些方法都是在原地修改PyTorch张量,而不是创建新的张量对象。原地操作可以有效地减少内存开销,并提高代码的执行效率。
所以,在代码中,我们需要注意哪些是引用传递对,然后注意引用传递对中变量的运算是不是原地修改,如果不是,就需要再修改。
拼接函数
拼接函数torch.cat作用是把列表list中的张量按照第一个维度拼在一起。不论列表中第一个张量的第一个维度是多少,拼接的时候,总是在第一个张量的第一个维度后拼接,按照顺序,每个张量的第一个维度的值都是累加的。