深度学习之PyTorch物体检测实战,读书笔记(一)
一.深度学习与计算机视觉
机器学习的思想是让机器自动地从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。
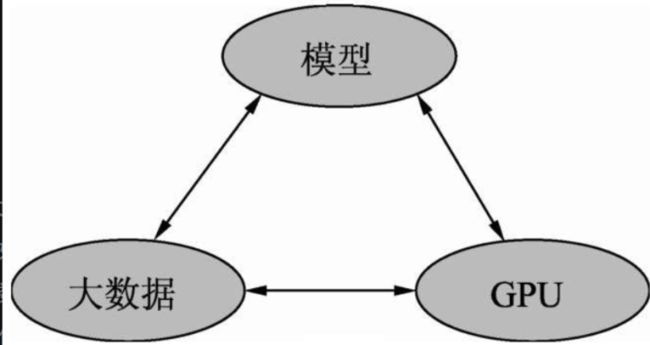
深度学习的发展离不开
编辑切换为居中
添加图片注释,不超过 140 字(可选)
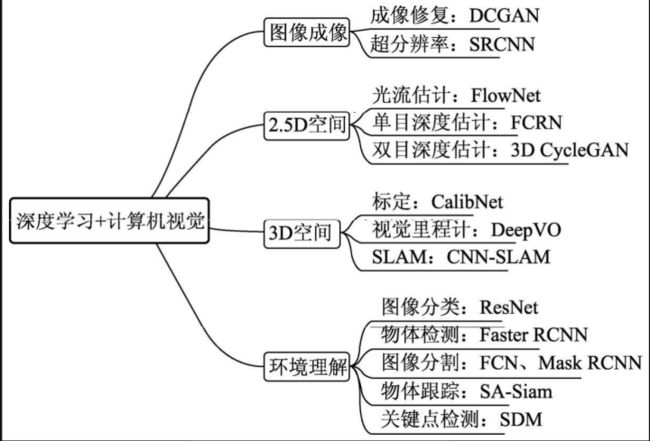
深度学习在计算机视觉中的应用
编辑切换为居中
添加图片注释,不超过 140 字(可选)
1.传统的物体检测算法思路

编辑切换为居中
添加图片注释,不超过 140 字(可选)
2014年的RCNN(Regions with CNN features) 算是使用深度学习实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。
在RCNN基础上,2015年的Fast RCNN实现了端到端的检测与卷积共享,Faster RCNN提出了锚框(Anchor)这一划时代的思想,将物体检测推向了第一个高峰。
在2016年,YOLO v1实现了无锚框(Anchor-Free)的一阶检测,SSD实现了多特征图的一阶检测。
两阶段算法
两阶:两阶的算法通常在第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率,然后在第二个阶段专注于对建议框进行分类,寻找更精确的位置,典型算法如Faster RCNN。
一阶段算法
一阶:一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特征融合,典型算法如SSD、YOLO系列等
2.物体检测在工业界的应用
安防,自动驾驶,机器人,搜索推荐和医疗诊断
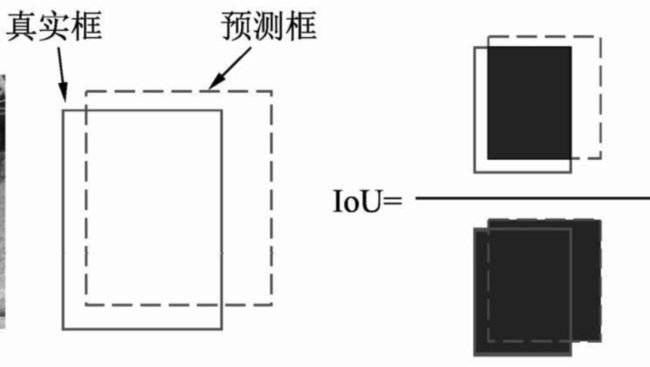
3.对于一个检测器的好坏,我们需要用一个IOU也就是预测框和真实框的贴合程度来预测,来量化这个检测器的好坏,
IOU的缺点:IOU为0,Loss也为0,那么网络梯度不回传,无法进行训练,因此IoU作为 loss函数在回归任务中的表现并不好。
计算公式如下:

编辑
添加图片注释,不超过 140 字(可选)
编辑切换为居中
python实现如下:
# 置信度的算法推导,IOU=交集/并集
# 这里我们把交集设置为A1,把并集设置为A2
# 那么A2=s1(box1)+s2(box2)-A1
# 此时IOU=A1/s1+s2-A1
# 假设box1的两个坐标分别为(Xa1,Ya1),(Xa2,Ya2)
# 假设box2的两个坐标分别为(Xb1,Yb1),(Xb2,Yb2)
# 那么box1的面积就是s1=(Xa2-Xa1)*(Ya2-Ya1)
# 那么box2的面积就是s2=(Xb2-Xb1)*(Yb2-Yb1)
def area(box):
x1, y1, x2, y2 = box
return (max(x1, x2) - min(x1, x2)) * (max(y1, y2) - min(y1, y2))
# 以上为计算box面积的代码实现
# 计算A1
# 相交于左上角的坐标为:x1=max(xa1,xb1),y1=max(ya1,yb1)
# 相交于右下角的坐标为:x2=min(xb1,xb2),y2=min(yb1,yb2)
# 所以A1=max(x2-x1,0)*max(y2-y1,0),与0相比较的是因为,如果交集相减为-,与0比较就是0
def IOU(box1, box2):
s1 = area(box1)
s2 = area(box2)
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
A1 = max(x2 - x1, 0) * max(y2 - y1, 0)
A2 = s1 + s2 - A1
return A1 / A2
# 测试代码
bbox1 = [100, 100, 200, 200]
bbox2 = [120, 120, 200, 200]
IOU1 = IOU(bbox1, bbox2)
print("测试的IOU为:{}".format(IOU1))C++实现如下:
#include//标准输入输出流,可以理解为一个字符序列
#include//一个集合的概念或者是数组
#include//定义了C++ STL标准中的基础性的算法(均为函数模板)。
//定义了设计用于元素范围的函数集合。任何对象序列的范围可以通过迭代器或指针访问。
#include//主要声明了常用的数学库函数
#define pi 3.1415926//宏定义
//定义一个矩形框的对角坐标
struct Box
{
double x1;
double y1;
double x2;
double y2;
};
//计算IOU
double IOU(Box& a, Box& b)
{
double iou = 0;
//计算交集面积
double s1_w = std::min(a.x2, b.x2) - std::max(a.x1, b.x1);
s1_w = std::max(s1_w, 0.000);
double s1_h = std::min(a.y2, b.y2) - std::max(a.y1, b.y1);
s1_h = std::max(s1_h, 0.000);
double A1 = s1_h * s1_w;
double A2 = (a.x2 - a.x1) * (a.y2 - a.y1) + (b.x2 - b.x1) * (b.y2 - b.y1) - A1;
iou = A1 / A2;
return iou;
}
using namespace std;
int main()
{
//测试代码
Box a = { 100,100,200,200 };
Box b = { 120,120,200,200 };
double iou = IOU(a, b);
cout << "测试代码的置信度为" << iou << endl;
return 0;
} 
编辑切换为居中
添加图片注释,不超过 140 字(可选)
TP(true positive)正确预测框,如右下角:预测框和标签框正确匹配,且IOU>0.5
FP(false positive):误检框,如左下角:把背景预测成物体
TN(true nagative):正确背景,如右上:本来就是背景,模型也没有检测出来
FN(false negative):漏检框,如左上,本身是物体,但是模型却没有检测出来。
这样就可以理解另外几个概念
召回率:

编辑
添加图片注释,不超过 140 字(可选)
即所有的正确预测框和所有的标签框的比值;
准确率:

编辑
添加图片注释,不超过 140 字(可选)
即正确预测框与所有预测框的比值(包括正确和错误的预测框);
编辑切换为居中
添加图片注释,不超过 140 字(可选)
.一.直接用pytorch的框架调用网络模型,例:vgg
from torch import nn # 模板库
from torchvision import models
# 通过torchvision.models直接调用VGG16的模型
vgg = models.vgg16()2.以及加载预训练模型
vgg = models.vgg16(pretrained=True)#加载预训练模型3.对于不同的检测任务,卷积层的前两三层的作用都是相同的,都是提取图像的边缘信息,因此为了提高模型训练中的稳定性,前两三层一般不进行参数的学习,比如VGG,设置前三层不进行网络的学习,代码实现:4.
for layer in range(10):
for p in vgg[layer].parameters():
p.requires_grad = False.4.模型保存
通过torch.save()实现