CMU15-445 Project1总结2021年
本篇博客是对CMU15-445课程project1的总结,代码的实现借鉴了一些其他前辈的代码,因为自己的C++实在是小白水平,对数据库的实现理解的也不够透彻,就抄了大家的代码,然后理解这些代码之后,再作此篇总结,加深对知识点的理解。
如果本文有纰漏,请多指教。
这里附上借鉴的博客:[已满分]CMU数据库(15-445)实验1-BufferPoolManager。
本次实验的原文要求在这里PROJECT #1 - BUFFER POOL
关于本门课程的知识点总结我推荐[CMU-15445]
总述
Project1要求我们实现一个数据库的缓存池(Buffer Pool),其中,涉及的相关组件(类)主要有:
- LRU Replacer
- Buffer Pool Manager
- Disk Manager
- Page
一些相关概念包括:
- Page(Page Table)
- Frame(Buffer Pool)
- Pin/Unpin
- Latch/Lock
我认为,在开始总结Buffer Pool的各个模块功能之前,有必要先归纳一些各个概念的区别,我自己在写代码的时候,经常弄混这些概念。
概念
Page
有关Page的概念,在《数据库系统概念》(以下简称《概念》)中给出的是,
一个**块(block)是一个逻辑单元,它包含固定数目的连续扇区。块大小在512字节到几KB之间。数据在磁盘和主存储器之间以块为单位传输。术语页(page)**常用来指块,尽管在有些语境(例如闪存)中指的是另外的含义。
在《数据库系统实现》(以下简称《实现》)中给出的是,
磁盘被划分称磁盘块(或就称为块,或者像操作系统称为页),每块的大小是4~64KB。整个块被从一个成为缓冲区的连续内存区域中移进移出。
可以认为,块,页,是对同一概念的不同叫法,取决于场景不同。其表述的概念,都是磁盘上某一柱面上的连续扇区(固定数目),数据在磁盘和缓冲区(内存)之间传输,传输的单位就是块(页)。
Page ID
此外,表示一个页,使用的是Page ID。Page ID是一个逻辑概念,由于数据库中的数据本质上是磁盘上存储的文件,因此,物理上Page ID应该映射到某个文件的某个偏移量上,这种映射是通过某种间接层(indirection layer)实现的。
Frame
Frame称为帧。Frame其实和Page在逻辑上指的是同一个概念,只不过,当Page被读取到缓冲区中,它就换了个名字——帧,它同样也有Frame ID(和Page ID相同)。课程课件中提到
内存区是以定长的页数组的形式组织的,其中每一个数组条目,被称为一个帧(frame)。
当DBMS请求一个页时,被请求页的一份拷贝就被读取进其中一个帧中。
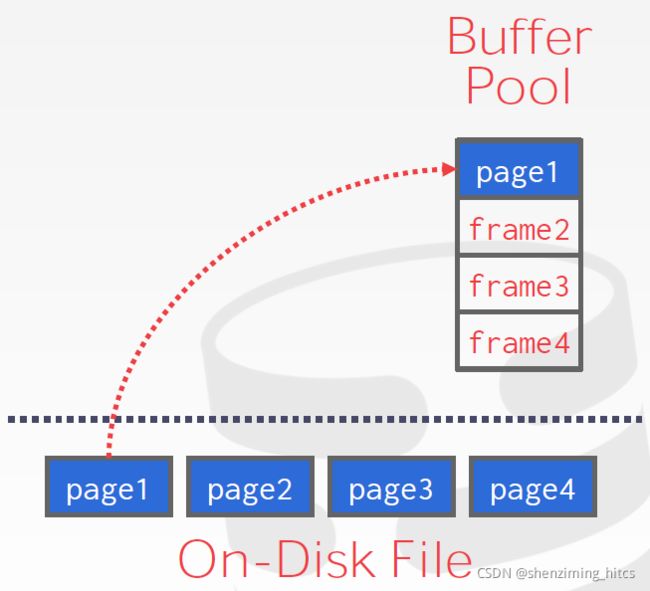
Page Table
至于Page Table,叫做页表。页表是一个字典(映射)结构,它是缓冲区管理器的一个辅助结构。页表的功能,是跟踪磁盘页在缓冲区中的位置,也就是说,它是一个Page ID到Frame ID的映射。
从这一点上来说,Page ID是磁盘页的属性,不同的磁盘页的Page ID不同,当磁盘页被读取进缓冲区时,该磁盘页会在缓冲区中有一个位置,即Frame ID。缓冲区是Frame的定长数组,一共只有buffer_pool_size大小的frame,所以,当磁盘页读进写出,会存在不同的磁盘页先后出现在同一个帧位置的情况,那么这个Page Table,就是保存当前页ID到帧ID的映射。
Pin/Unpin
Pin,叫做钉住(Unpin就是解钉吧~)。它指的是钉住/解钉某个块(或者说是帧,因为这里钉住和解钉是内存区的概念,操作对象应该叫做帧)。为什么要钉住一个块?要知道,我们的DBMS在对磁盘文件进行读入写出时,必须要保证线程的安全,当一个块被读取的同时,块又被修改,这会威胁到线程安全。借用《概念》中的说法:
为了使数据库系统能够从系统崩溃中恢复,限制一个块写回磁盘的时间是十分必要的。例如:当一个块上的更新操作正在进行时,大多数恢复系统不允许将该块写回磁盘。不允许写回磁盘的块被称为被钉住(pinned)的块。尽管很多操作系统不提供对被钉住的块的支持,但是这个特性对可从崩溃中恢复的数据库系统十分重要。
Latch/Lock
Latch和Lock都是数据库中的锁,前者叫闩,后者叫锁,目的都差不多。区别,课程课件中是这么给出的:
Locks:
- 保护数据库的逻辑内容不被其他事务破坏,如元组、表、数据库。
- 事务期间持有。
- 需要能够回滚(rollback)变化。
Latch
- 保护DBMS内部数据结构的关键部分不受其他线程的影响。
- 操作期间持有。
- 不需要能够回滚变化。

说白了,这里latch是在代码层面,保护数据结构不受线程影响;lock是在逻辑层面,保护逻辑对象(元组、表、数据库)不受事务影响。在本次实验的编码中,每个类都有一个自己的latch,在C++中使用mutex实现,通过使用互斥量,达到避免多线程操作混乱的目的。
LRU Replacer
Replacer的作用,是提供一个缓冲区替换策略(buffer replacement strategy),《概念》中提到:
当缓冲区中没有剩余空间时,在新块读入缓冲区之前,必须把一个块从缓冲区移出。多数操作系统使用**最近最少使用(Least Recently Used)**策略,即最近访问最少的块被写回磁盘,并从缓冲区移走。这种简单的方法可以加以改进以用于数据库应用。
本次实验中采取的策略正是LRU(最基础的版本,LRU有很多扩展改进版本)。重点是,LRU只生效于缓冲区没有剩余空间时,如果有剩余空间,那么就直接选用一个空帧,来放置读入的页即可。
在实验代码中,要求我们实现如下几个函数,具体功能见实验要求说明,不赘述了。
Victim(frame_id_t*)Pin(frame_id_t)Unpin(frame_id_t)Size()
说白了,就三件事——选取牺牲帧(最近最少使用的)、钉住一个帧、解钉一个帧,附加一个返回LRU replacer结构中所剩帧的数目函数Size()。
总体实现思路
实现LRU Replacer的总体思路,只是要在这个类里面,加上两个重要的数据结构——双向链表、哈希表。
双向链表中的每一个节点,都表示一个帧,且该链表具有优先性,最近更少被使用的,将在链表的尾部,而每一次帧被访问将被提到链表的头部,表示它最近更多被使用了(你也可以放在头部,这样最近更多被使用的会提到尾部)。
而哈希表是一个辅助搜索的结构,它是Frame ID到ListNode的映射,可以快速定位某一个帧在链表中的位置,免去了O(n)的搜索代价。
struct ListNode {
frame_id_t frame_id{-1};
struct ListNode *prev{nullptr};
struct ListNode *next{nullptr};
explicit ListNode(frame_id_t frame_id) : frame_id(frame_id) {}
};
std::unordered_map<frame_id_t, ListNode *> hashMap{};
接下来对三个函数的讲解,我将以伪代码的形式说明,因为这三个函数确实不难。
bool LRUReplacer::Victim(frame_id_t *frame_id)
latch.lock();
if linkedList is empty:
latch.unlock();
return false;
tailNode = linkedList.tail;
*frame_id = tailNode->frame_id;
linkedList.remove(tailNode);
size_ --;
delete tailNode;
hashMap.erase(*frame_id);
latch.unlock();
return true;
记:驱逐尾节点、删除尾节点内存、删除尾节点hash记录、加闩解闩。
void LRUReplacer::Pin(frame_id_t frame_id)
latch.lock();
tailNode = hashMap.find(frame_id);
if tailNode is not nullptr:
linkedList.remove(tailNode);
hashMap.erase(frame_id);
delete tailNode;
size_ --;
latch.unlock();
记:移除frame_id的帧节点、移出frame_id的哈希表记录
void LRUReplacer::Unpin(frame_id_t frame_id)
latch.lock();
listNode = hashMap.find(frame_id);
if listNode is not nullptr:
while(size_ >= capacity_) {
tail_node = linkedlist.tail;
linkedlist.remove(tail_node);
hashMap.erase(tail_node->frame_id);
delete tail_node;
size_ --;
}
frame_node = new ListNode(frame_id);
linkedlist.addToHead(frame_node);
hashMap[frame_id] = frame_node;
size_ ++;
latch.unlock();
记:查哈希表、有表记录则加入头部(链表若已满,则弹出尾节点直到可以插入新节点);无表记录,则无事发生
Buffer Pool Manager
Buffer Pool Manager(BPM)缓冲区管理器是本次实验的核心内容,详见Task #2. 它是用来管理缓冲区中的帧的。随着磁盘页在磁盘和缓冲区二者之间传输,缓冲区管理器需要记录一些关于缓冲区状态的信息。
其中,缓冲区管理器需要做的事情无非就两件:
- 为一个即将进入缓冲区的磁盘页申请一个帧。
- 为一个即将离开缓冲区的磁盘页清除所在帧。
关于进入缓冲区,BPM需要理清申请哪个帧:
- 缓冲区有没有空帧?
- 没有空帧,提出哪个帧?(调用Replacer策略)
关于离开缓冲区,BPM需要理清如何清除帧:
- 离开帧的磁盘页是否正在被使用(pinned)?
- 离开帧的磁盘页是否是一个脏页(dirty page)?
这里有一些先前就提到过的概念,也有一些新出现的概念:
- Pin/Unpin。如果一个页正在被使用,它就应该是被钉住的(Pinned),直到没有人正在使用它,才能被接触钉住(Unpin)。
- 脏页(Dirty Page)。如果一个页被读入到了缓冲区,并且它的内容(data)被修改了,那么这个页就变脏(dirty)了。脏页意味着,当该页从缓冲区移出时,有必要将其内容写回到磁盘,毕竟数据库/操作系统修改了它的内容,而磁盘上的内容还没同步这些修改,所以需要写回。
笔者在写实验的时候常常混淆一些概念(在代码中),所以笔者认为,还有一件事要提前说明:BPM应该只接受Page ID作为输入,而Frame ID是一个BPM内部的变量(用于表示帧)。
既然如此,那么我们逐一介绍函数原型吧,由于笔者魔改的代码实在太low了,不如大家就移步[已满分]CMU数据库(15-445)实验1-BufferPoolManager,这里就写一些我自己的理解和细节吧。
Page *BufferPoolManagerInstance::FetchPgImp(page_id_t page_id)
在实验给出的代码模板中,有这样的一段注释:
// 1. Search the page table for the requested page (P).
// 1.1 If P exists, pin it and return it immediately.
// 1.2 If P does not exist, find a replacement page (R) from either the free list or the replacer.
// Note that pages are always found from the free list first.
// 2. If R is dirty, write it back to the disk.
// 3. Delete R from the page table and insert P.
// 4. Update P's metadata, read in the page content from disk, and then return a pointer to P.
在编写这个函数的时候,你需要做的有:
- 进入函数,
latch上闩,在离开函数的任何一个出口处,latch解闩。 - 调用官方提供的
AllocatePage(),分配一个page_id_t new_page_id。 - 检查
pages中的每一个page的pin_count_是否为0,如果都不为0,说明所有的帧都被钉住了,直接解闩,返回nullptr。pages是BPM的帧数组。 - 检查
free_list中是否还有空帧,如果有,记空帧为victim_page,空帧ID为victim_frame_id,Goto 7,否则Goto 5。free_list中存放了空帧的Frame ID,只有当帧被删除时(DeletePgImp),帧才会被重新加入到free_list中,也就是说,free_list大部分时间应该都是空的。 free_list中没有空帧,需要驱逐一个缓冲区中的帧。调用replacer.Victim(),返回一个驱逐帧IDvictim_frame_id,并判断是否驱逐成功,如果是,Goto 6,否则,无事发生,没有任何帧可以驱逐,本次获取页失败。- 获取驱逐帧成功,记驱逐帧为
victim_page。判断victim_page是否是脏页,如果是脏页,则需要写回磁盘disk_manager_->WritePage()。 - 至此,已经获取到了目标帧(空帧或驱逐帧)
victim_page和其帧IDvictim_frame_id,注意,目标帧要么是从第4步空闲链表中获取到的空帧,要么是从第5、6步中调用replacer的替换策略,获取到的驱逐帧。 - 更新一些元数据(metadata),包括:
- 清除目标帧的页ID在页表中的记录,
page_table_.erase(victim_page->page_id_)。之所以是删除victim_page->page_id_,而不是victim_frame_id,是因为需要清楚的是(目标帧上的)磁盘页的ID,而不是帧ID。 - 在页表中添加
new_page_id到victim_frame_id的映射记录。 - 更新目标帧的页ID,
victim_page->page_id_=new_page_id。正式替换了目标帧上的页。 - 目标帧的pin计数加一,
victim_page->pin_count_+=1。 - 目标帧的脏页标记为
false。旧目标帧已经不脏了(旧帧如果脏,已经写回了)。 - 调用
replacer,将victim_frame_id钉住。目标帧被获取,使用者加一,要把它钉住。 *page_id=new_page_id。见函数参数,通过参数把新页ID传出去。- 调用
disk_manager_,把新页`victim_page
- 清除目标帧的页ID在页表中的记录,
bool BufferPoolManagerInstance::UnpinPgImp(page_id_t page_id, bool is_dirty)
latch.lock()上闩,在函数退出的任意一个位置都latch.unlock()解闩。- 查找页表
page_table_,如果页表中没有page_id的记录,则无事发生,并返回false。 - 页表中有
page_id的记录,记帧ID为unpin_frame_id,并获得缓冲区中的帧Page *unpin_page = &this->pages_[unpin_frame_id];。如果is_dirty标记为true,将unpin_page的is_dirty_设为true,否则无事发生。 - 如果
unpin_page的pin计数为0,则无需再unpin,无事发生,返回false。 - 否则,
unpin_page的pin计数减一,并且调用replacer->Unpin()将帧ID为unpin_frame_id的节点加入replacer链表。 return true。
bool BufferPoolManagerInstance::FlushPgImp(page_id_t page_id)
latch.lock()上闩,在函数退出的任意一个位置都latch.unlock()解闩。- 在页表
page_table_中搜索页ID的记录page_id,如果搜索不到,或者page_id==INVALID_PAGE_ID,解闩,returnfalse。 - 否则,记
page_id对应的帧ID为flush_flame_id,调用this->disk_manager_->WritePage(flush_frame_id, this->pages_[flush_frame_id].data_)将数据写回。 - 解闩,return
true。
void BufferPoolManagerInstance::FlushAllPgsImp()
latch.lock()上闩,在函数退出的任意一个位置都latch.unlock()解闩。- 遍历大小为
pool_size_的缓冲区pages_,对每一个帧都调用一次this->FlushPgImp(pages_[i].GetPageId())即可。 - 解闩返回。
Page *BufferPoolManagerInstance::NewPgImp(page_id_t *page_id)
本函数官方给出的提示如下:
// 0. Make sure you call AllocatePage!
// 1. If all the pages in the buffer pool are pinned, return nullptr.
// 2. Pick a victim page P from either the free list or the replacer. Always pick from the free list first.
// 3. Update P's metadata, zero out memory and add P to the page table.
// 4. Set the page ID output parameter. Return a pointer to P.
latch.lock()上闩,在函数退出的任意一个位置都latch.unlock()解闩。- 调用
this->AllocatePage(),分配一个新的页,记页ID为new_page_id。 - 检查缓冲区中的所有帧
this->pages_,如果所有帧都被钉住了,无帧可以用,解闩,returnnullptr。 - 调用
this->find_replace(&victim_frame_id),获取一个可用帧,帧ID为victim_frame_id,从this->pages_中获取帧,记为victim_page。 - 更新
victim_page的元数据,包括:victim_page->page_id = new_page_idvictim_page->is_dirty_ = false;victim_page->pin_count_ ++;
- 将
new_page_id到victim_frame_id的映射,加入到页表中。 - 通知replacer,将
victim_frame_id钉住。 - 设置输出参数
*page_id=new_page_id,并调用disk_manager_->WritePage()将victim_page写回。 - 解闩,return
victim_page。
bool BufferPoolManagerInstance::DeletePgImp(page_id_t page_id)
官方给出的注释提示为:
// 0. Make sure you call DeallocatePage!
// 1. Search the page table for the requested page (P).
// 1. If P does not exist, return true.
// 2. If P exists, but has a non-zero pin-count, return false. Someone is using the page.
// 3. Otherwise, P can be deleted. Remove P from the page table, reset its metadata and return it to the free list.
latch.lock()上闩,在函数退出的任意一个位置都latch.unlock()解闩。- 在页表中搜索
page_id,如果没有记录,则解闩,returntrue。 - 否则,记页表中
page_id对应的帧ID为frame_id,获取其在缓冲区的帧为page,如果page的pin计数不为0,则无法删除page,解闩,returnfalse。 - 否则,
page可以被删除。首先判断page是否为脏页,若是,则调用this->FlushPgImp()将其写回,若不是,无事发生。 - 调用
this->DeallocatePage()将page从磁盘上释放。 - 删除页表中
page_id的记录。 - 重置
page的元数据,包括is_dirty_=false,pin_count_=0,page_id_=INVALID_PAGE_ID。 page是一个崭新的帧了,可以被加入到free_list_。- 解闩,返回
true。