2023 Meta neurons improve spiking neural networks for efficient spatio-temporal learning
论文下载:
Meta neurons improve spiking neural networks for efficient spatio-temporal learning - ScienceDirect
代码地址:
GitHub - thomasaimondy/MDN-SNN: Meta-Dynamic Neurons improved Spatio-temporal Generalization of Spiking Neural Networks
阅读总结:
文章亮点:
1. 提出元神经元模型,本质是引入四个参数的二阶LIF模型
2. 对模型在时空数据集上分别进行了训练测试,提出时空容量的概念
3. 使用均值聚类找到具有差异性的元神经元,并根据元神经元的放电活动选出具有代表性的神经元。
4. 混合不同元神经元搭建网络,在时空容量上找到平衡点。
缺点:
- 源代码没有找到含卷积层的深层SNN,只存在简单的全连接SNN网络。
- 元神经元模型的提出没给出灵感来源或数学推理,引入了四个参数并未解释原因。
- 混合元神经元的使用描述过于模糊,没有给出结论对应的混合方式,如何设置网络结构也未给出具体的说明。
模型与方法:
- 时空容量定义式
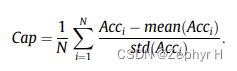
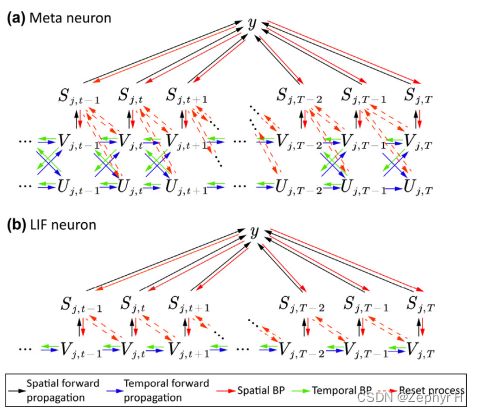
2.元神经元模型

3.脉冲神经元反向传播

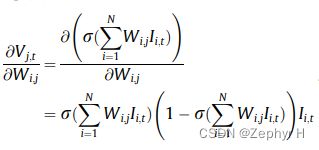
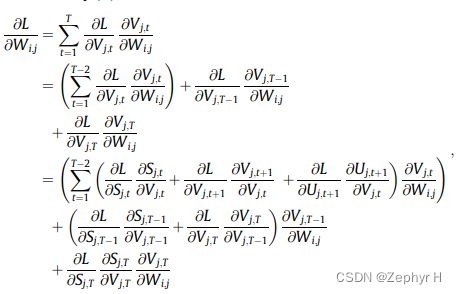
实验:
- MNIST、TIDigits的初步聚类
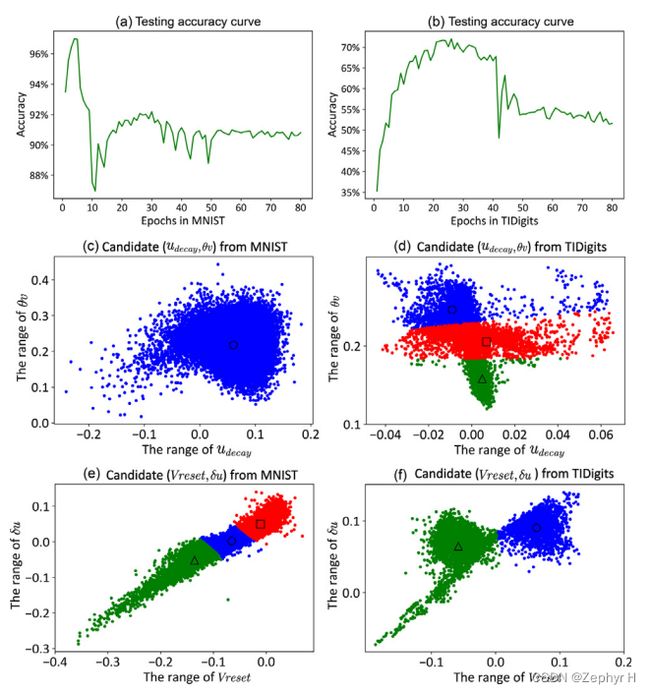
2.根据脉冲发放频率确定保留的元神经元

3.保留元神经元准确率对比

4.元神经元时空能力对比
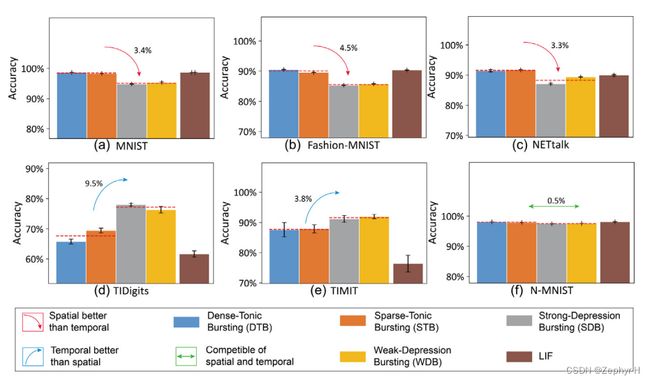
5. 混合元神经元的讨论

代码分析:
dataset.py
from torch.utils.data import DataLoader
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from nettalk import NETtalk
from nmnist import nmnist
from tidigits import Tidigits
from timit import Timit
from tensorboardX import SummaryWriter
def loaddata(task, if_tb):
writer = None
if task == 'M':
if if_tb:
writer = SummaryWriter(comment = '-Mni')
hyperparams = [100, 784, 10, 1e-3, 20, 'MNIST', 1e-3]
train_dataset = dsets.MNIST(root = './data/mnist', train = True, transform = transforms.ToTensor(), download = True)
test_dataset = dsets.MNIST(root = './data/mnist', train = False, transform = transforms.ToTensor())
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
elif task == 'F':
if if_tb:
writer = SummaryWriter(comment = '-Fas')
hyperparams = [100, 784, 10, 1e-3, 20, 'FashionMNIST', 1e-3]
train_dataset = dsets.FashionMNIST(root = './data/fashion', train = True, transform = transforms.ToTensor(), download = True)
test_dataset = dsets.FashionMNIST(root = './data/fashion', train = False, transform = transforms.ToTensor())
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
elif task == 'N':
if if_tb:
writer = SummaryWriter(comment = '-Net')
hyperparams = [5, 189, 26, 1e-3, 20, 'NETtalk', 1e-3]
train_dataset = NETtalk('train', transform=transforms.ToTensor())
test_dataset = NETtalk('test', transform=transforms.ToTensor())
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
elif task == 'C10':
if if_tb:
writer = SummaryWriter(comment = '-Cif')
hyperparams = [100, 3072, 10, 1e-4, 20, 'Cifar10', 1e-3]
train_dataset = dsets.CIFAR10(root = './data/cifar10', train = True, transform = transforms.ToTensor(), download = True)
test_dataset = dsets.CIFAR10(root = './data/cifar10', train = False, transform = transforms.ToTensor())
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
elif task == 'NM':
if if_tb:
writer = SummaryWriter(comment = '-Nmn')
hyperparams = [100, 2592, 10, 1e-3, 20, 'NMNIST', 1e-3]
train_dataset = nmnist(datasetPath = 'nmnist/Train/', sampleFile = 'nmnist/Train.txt', samplingTime = 1.0, sampleLength = 20)
test_dataset = nmnist(datasetPath = 'nmnist/Test/', sampleFile = 'nmnist/Test.txt', samplingTime = 1.0, sampleLength = 20)
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
elif task == 'T':
if if_tb:
writer = SummaryWriter(comment = '-Tid')
hyperparams = [10, 30, 10, 1e-2, 30, 'TiDigits', 1e-4, 1, 30, transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.0,),(1.0,))])]
train_dataset = Tidigits('train', hyperparams[7], hyperparams[8], hyperparams[4], transform = hyperparams[9])
test_dataset = Tidigits('test', hyperparams[7], hyperparams[8], hyperparams[4], transform = hyperparams[9])
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False, drop_last = True)
elif task == 'TM':
if if_tb:
writer = SummaryWriter(comment = '-Tim')
hyperparams = [32, 520, 2, 1e-3, 20, 'Timit', 1e-3]
train_dataset = Timit('TRAIN')
test_dataset = Timit('TEST')
train_loader = DataLoader(dataset = train_dataset, batch_size = hyperparams[0], shuffle = True)
test_loader = DataLoader(dataset = test_dataset, batch_size = hyperparams[0], shuffle = False)
return writer, hyperparams, train_dataset, test_dataset, train_loader, test_loader
Loaddata对数据集导入进行封装。唯一重要的是hyperparams列表,其包含多个超参数,分别表示批处理大小、输入大小、输出大小、学习率、时间窗(训练轮数,不是迭代次数,这里每一次前向传播都会经过多轮训练,取平均值作为最终的输出)、数据集名称、测试学习率、语音采样率、语音截取时间长度、归一化方法。
block.py
import torch
import torch.nn as nn
import numpy as np
from paraset import make_paraset
thresh, lens, decay = (0.5, 0.5, 0.2)
# SNN自定义激活函数
class ActFun(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
return input.gt(thresh).float()
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
grad_input = grad_output.clone()
temp = abs(input - thresh) < lens
return grad_input * temp.float()
act_fun = ActFun.apply
class FC_block(nn.Module):
def __init__(self, hyperparams, input_size, output_size, if_bias = True):
super(FC_block, self).__init__()
self.batch_size = hyperparams[0]
self.input_size = input_size
self.output_size = output_size
self.time_window = hyperparams[4]
self.last_layer = (output_size == hyperparams[2])
self.order = hyperparams[-2]
if self.last_layer:
self.if_print = False
else:
self.if_print = False
self.input = None
self.v = None
self.u = None
self.spike = None
self.sumspike = None
self.ntype = hyperparams[-1]
self.time_counter = 0
self.fc = nn.Linear(self.input_size, self.output_size, if_bias)
# 这里被默认false了
decide = False
hsize = (self.batch_size, self.output_size)
if decide:
if self.ntype != '1':
paraset = make_paraset(self.ntype)
# lens = 4
lens = len(paraset)
# 存储输出所需的所有参数, 一个输出对应四个参数,即每一个输出都有独立的神经元
org = lens * torch.rand((self.output_size))
org = org.floor()
org = org.clamp(0, lens - 1)
num = []
for i in range(lens):
num.append(0)
for i in range(self.output_size):
num[int(org[i].data)] += 1
self.a = None
self.b = None
self.c = None
self.d = None
for i in range(lens):
if self.a is None:
if num[i] != 0:
self.a = paraset[i][0] * torch.ones((self.batch_size, num[i]))
self.b = paraset[i][1] * torch.ones((self.batch_size, num[i]))
self.c = paraset[i][2] * torch.ones((self.batch_size, num[i]))
self.d = paraset[i][3] * torch.ones((self.batch_size, num[i]))
else:
if num[i] != 0:
self.a = torch.cat((self.a, paraset[i][0] * torch.ones((self.batch_size, num[i]))), 1)
self.b = torch.cat((self.b, paraset[i][1] * torch.ones((self.batch_size, num[i]))), 1)
self.c = torch.cat((self.c, paraset[i][2] * torch.ones((self.batch_size, num[i]))), 1)
self.d = torch.cat((self.d, paraset[i][3] * torch.ones((self.batch_size, num[i]))), 1)
self.a = self.a.cuda()
self.b = self.b.cuda()
self.c = self.c.cuda()
self.d = self.d.cuda()
else:
a, b, c, d = [0.02, 0.2, 0, 0.08]
distime = 0
self.a = nn.Parameter(a * (torch.ones(hsize) + distime * (torch.rand(hsize) - 0.5)))
self.b = nn.Parameter(b * (torch.ones(hsize) + distime * (torch.rand(hsize) - 0.5)))
self.c = nn.Parameter(c * (torch.ones(hsize) + distime * (torch.rand(hsize) - 0.5)))
self.d = nn.Parameter(d * (torch.ones(hsize) + distime * (torch.rand(hsize) - 0.5)))
distrue = True
self.a.requires_grad = distrue
self.b.requires_grad = distrue
self.c.requires_grad = distrue
self.d.requires_grad = distrue
# 简单LIF 与 ALIF
def mem_update(self, ops, x):
if self.ntype == '1':
# sigmoid是为了把输入调整到区间(0,1),另外代码是基于 rate coding, 需要频率也位于(0,1)
I = torch.sigmoid(ops(x))
self.v = self.v * decay * (1 - self.spike) + I
self.spike = act_fun(self.v)
self.sumspike = self.sumspike + self.spike
else:
self.v = self.v * (1 - self.spike) + self.spike * self.c
self.u = self.u + self.spike * self.d
I = torch.sigmoid(ops(x))
v_delta = self.v * self.v - self.v - self.u + I
u_delta = self.a * (self.b * self.v - self.u)
self.v = self.v + v_delta
self.u = self.u + u_delta
self.spike = act_fun(self.v)
self.sumspike = self.sumspike + self.spike
def forward(self, input):
if self.time_counter == 0:
self.v = 0 * torch.ones((self.batch_size,self.output_size)).cuda()
self.u = 0.08 * torch.ones((self.batch_size,self.output_size)).cuda()
self.spike = torch.zeros((self.batch_size,self.output_size)).cuda()
self.sumspike = torch.zeros((self.batch_size,self.output_size)).cuda()
self.input = input
self.mem_update(self.fc, self.input)
self.time_counter += 1
if self.time_counter == self.time_window:
self.time_counter = 0
return self.spike类ActFun为SNN自定义的激活函数
前向传播返回1或0,取决于输入是否大于阈值。
反向传播类似于门控,只允许满足abs(input - thresh) < lens的梯度回传,可能是认为只要输入足够接近释放脉冲的神经元都有价值进行更新。
类FC_block为全连接块的自定义
对hyperparams参数提取,初始化输入、膜电位V、模拟超极化短期变量U、输出脉冲spike、当前层总脉冲数量sumspike、meta神经元是否可训练(如果不为1,代表选用paraset训练好的参数直接代入网络作为定值进行训练,否则初始化四个参数,并允许四个参数与网络共同训练)
![]()
这里比较关键,代码中默认decide = False ,如果想使用meta模型,首先要置True。
![]()
这里可能会有个疑问,在dataset中并未给出最后一项,
最后一项在train.py中定义![]() ,
,
而opt.nps在train.py的开头就进行了预置![]()
如果ntype==1,那么就加入四个参数的训练,整个过程下来,会得到一个新的四个参数,这个网络中的所有神经元参数相同。
如果ntype!=1,那么就使用预置的参数完成网络训练,期间参数为定值不参与反向传播。
Mem_update 膜更新函数
根据所选神经元类型,选择不同的更新公式进行计算。引入sigmoid的原因在于,把输入调整到(0,1)区间,另外文章采用频率编码,因此频率也要位于(0,1)。函数记录两点,一是当前时间步的脉冲,二是到目前为止,累计产生的脉冲数。
Forward 前向传播
前向传播的过程夹杂着膜电位的更新,因此调用mem_update函数。返回的是当前时间步的脉冲。
SNN.py
import torch
import torch.nn as nn
from block import FC_block
class SNN(nn.Module):
def __init__(self, hyperparams):
super(SNN, self).__init__()
self.hyperparams = hyperparams
if self.hyperparams[5] == 'Cifar10':
self.hidden_size = 1500
else:
self.hidden_size = 500
self.layers = nn.ModuleList()
self.layers_size = [self.hyperparams[1], self.hidden_size, self.hyperparams[2]]
self.len = len(self.layers_size) - 1
self.error = None
for i in range(self.len):
self.layers.append(FC_block(self.hyperparams, self.layers_size[i], self.layers_size[i + 1]))
def forward(self, input):
for step in range(self.hyperparams[4]):
if self.hyperparams[5] == 'MNIST':
x = input > torch.rand(input.size()).cuda()
elif self.hyperparams[5] == 'FashionMNIST':
x = input > torch.rand(input.size()).cuda()
elif self.hyperparams[5] == 'NETtalk':
x = input.cuda()
elif self.hyperparams[5] == 'Cifar10':
x = input > torch.rand(input.size()).cuda()
elif self.hyperparams[5] == 'NMNIST':
x = input[:, :, :, :, step]
elif self.hyperparams[5] == 'TiDigits':
x = input[:, :, :, step]
elif self.hyperparams[5] == 'Timit':
x = input[:, step, :,]
x = x.float()
x = x.view(self.hyperparams[0], -1)
y = x
for i in range(self.len):
y = self.layers[i](y)
outputs = self.layers[-1].sumspike / self.hyperparams[4]
# debug here : loss ",y"
return outputs, y从代码来看,整个网络由FC块构成,可以认为是全连接层的SNN网络。前向传播根据数据集名称,调整输入格式,返回函数源代码漏掉了返回值y(当前层的电位状态)
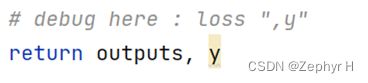
Train.py
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.autograd import Variable
import numpy as np
from SNN import SNN
import time
import os
import shutil
import argparse
from dataset import loaddata
from tensorboardX import SummaryWriter
parser = argparse.ArgumentParser(description='train.py')
parser.add_argument('-gpu', type = int, default = 0)
parser.add_argument('-seed', type = int, default = 3154)
# 使用训练好的参数,还是可学习? 1为可学习
parser.add_argument('-nps', type = str, default = 'C1')
parser.add_argument('-dts', type = str, default = 'M')
opt = parser.parse_args()
torch.cuda.set_device(opt.gpu)
torch.manual_seed(opt.seed)
torch.cuda.manual_seed_all(opt.seed)
torch.backends.cudnn.deterministic = True
# change
num_epoch = 1
# change
find = True
test_scores = []
train_scores = []
ccost_scores = []
if_tb = False
writer, hyperparams, train_dataset, test_dataset, train_loader, test_loader = loaddata(opt.dts, if_tb)
hyperparams.append(opt.nps)
task = hyperparams[5]
# 创建dynamic_data文件夹
path = './dynamic_data/10_' + opt.dts + str(opt.seed) + '_' + str(hyperparams[3]) + '_' + str(hyperparams[6]) # 12 - 8
place = path + '/'
if find:
if not os.path.exists(path):
os.mkdir(path)
print('1234455')
print('Dataset: ' + task)
print('Random Seed: {}'.format(opt.seed))
print('Length of Training Dataset: {}'.format(len(train_dataset)))
print('Length of Test Dataset: {}'.format(len(test_dataset)))
print('Build Model')
print('Params come from ' + hyperparams[-1])
model = SNN(hyperparams)
model.cuda()
loss_function = nn.MSELoss()
for i in range(model.len):
if find:
layer = model.layers[i]
np.save(place + 'layer' + str(i) + '_a0', layer.a.detach().cpu().numpy())
np.save(place + 'layer' + str(i) + '_b0', layer.b.detach().cpu().numpy())
np.save(place + 'layer' + str(i) + '_c0', layer.c.detach().cpu().numpy())
np.save(place + 'layer' + str(i) + '_d0', layer.d.detach().cpu().numpy())
paras = dict(model.named_parameters())
paras_new = []
for k, v in paras.items():
if k[9] == 'f':
paras_new.append({'params': [v], 'lr': hyperparams[3]})
else:
paras_new.append({'params': [v], 'lr': hyperparams[6]})
optimizer = torch.optim.Adam(paras_new)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size = 50, gamma = 0.1)
cossim = torch.nn.CosineSimilarity(dim = 1, eps = 1e-6)
sigmoid = torch.nn.Sigmoid()
norm = torch.nn.BatchNorm2d(1).cuda()
def train(epoch):
model.train()
scheduler.step()
print('Train Epoch ' + str(epoch + 1))
start_time = time.time()
total_loss = 0
for i, (images, labels) in enumerate(train_loader):
if True:
# if i < 60:
if images.size()[0] == hyperparams[0]:
optimizer.zero_grad()
if images.type() == 'torch.DoubleTensor':
images = images.to(torch.float32)
images = Variable(images.cuda())
if task == 'MNIST':
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
elif task == 'FashionMNIST':
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
elif task == 'NETtalk':
labels = labels.float()
labels = Variable(labels.cuda())
elif task == 'Cifar10':
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
elif task == 'NMNIST':
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
elif task == 'TiDigits':
labels = labels.long()
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
elif task == 'Timit':
images = norm(images.unsqueeze(1))
images = images.squeeze(1)
one_hot = torch.zeros(hyperparams[0], hyperparams[2]).scatter(1, labels.unsqueeze(1), 1)
labels = Variable(one_hot.cuda())
outputs, new_potential = model(images)
loss = loss_function(outputs, labels)
total_loss += float(loss)
loss.backward(retain_graph = True)
optimizer.step()
if task != 'Timit':
divide = 40
else:
divide = 1
if (i + 1) % (len(train_dataset) // (hyperparams[0] * divide)) == 0:
print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.6f, Time: %.2f'
% (epoch + 1, num_epoch, i + 1,
len(train_dataset) // hyperparams[0],
total_loss / (hyperparams[0] * 40),
time.time() - start_time))
xs = epoch * 40 + ((i + 1) // (len(train_dataset) // (hyperparams[0] * 40)))
if if_tb:
writer.add_scalar('loss_train', total_loss / (hyperparams[0] * 40), xs)
writer.add_scalar('time_train', time.time() - start_time, xs)
start_time = time.time()
total_loss = 0
def eval(epoch, if_test):
model.eval()
correct = 0
total = 0
if if_test:
print('Test Epoch ' + str(epoch + 1))
loader = test_loader
test_or_train = 'test'
else:
loader = train_loader
test_or_train = 'train'
if task == 'MNIST':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
elif task == 'FashionMNIST':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
elif task == 'NETtalk':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += 1
if outputs.max() >= 0.05:
pos = []
for label in range(26):
if (labels[0, label] != 0) or (outputs[0, label] != 0):
pos.append(label)
tem_out = torch.zeros((1, len(pos)))
tem_lab = torch.zeros((1, len(pos)))
for label in range(len(pos)):
tem_out[0, label] = outputs[0, pos[label]]
tem_lab[0, label] = labels[0, pos[label]]
correct += cossim(tem_out, tem_lab)
else:
correct += 0
elif task == 'Cifar10':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
elif task == 'NMNIST':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
elif task == 'TiDigits':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = labels.long()
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
elif task == 'Timit':
for i, (images, labels) in enumerate(loader):
images = Variable(images.cuda())
labels = Variable(labels.cuda())
outputs, _ = model(images)
total += labels.size(0)
pred = outputs.max(1)[1]
correct += (pred == labels).sum()
correct = correct.item()
ccost = 0
for i in range(model.len):
ccost += model.layers[i].sumspike.sum()
# change .cpu.detach 解决数据在gpu上无法转换成数组、数据可导不能转为numpy的问题
ccost_scores.append(ccost.cpu().detach())
acc = 100.0 * correct / total
print(test_or_train + ' correct: %d accuracy: %.2f%% ccost: %d' % (correct, acc, ccost.data))
if if_tb:
writer.add_scalar('acc_' + test_or_train, acc, epoch + 1)
if if_test:
test_scores.append(acc)
# if acc >= max(test_scores):
# torch.save(model, './' + para[3])
else:
train_scores.append(acc)
for i in range(model.len):
if find:
layer = model.layers[i]
np.save(place + task + 'layer' + str(i) + '_a' + str(epoch + 1), layer.a.detach().cpu().numpy())
np.save(place + task + 'layer' + str(i) + '_b' + str(epoch + 1), layer.b.detach().cpu().numpy())
np.save(place + task + 'layer' + str(i) + '_c' + str(epoch + 1), layer.c.detach().cpu().numpy())
np.save(place + task + 'layer' + str(i) + '_d' + str(epoch + 1), layer.d.detach().cpu().numpy())
#
print('save')
def main():
for epoch in range(num_epoch):
train(epoch)
if (epoch + 1) % 1 == 0:
eval(epoch, if_test = True)
if (epoch + 1) % 20 == 0:
eval(epoch, if_test = False)
if (epoch + 1) % 20 == 0:
print('Best Test Accuracy in %d: %.2f%%' % (epoch + 1, max(test_scores)))
avg = (test_scores[-1] + test_scores[-2] + test_scores[-3] + test_scores[-4] + test_scores[-5] + test_scores[-6] + test_scores[-7] + test_scores[-8] + test_scores[-9] + test_scores[-10]) / 10
print('Average of Last Ten Test Accuracy : %.2f%%' % (avg))
# TypeError:change “ccost_scores” to "ccost_scores.cpu()"
cc_scores = np.array(ccost_scores)
# 没找到路径。需要手动创建文件夹
np.save('./ccs/' + opt.nps + '_' + opt.dts + '_' + str(opt.seed) + '_cc', cc_scores)
tr_scores = np.array(train_scores)
np.save('./trs/' + opt.nps + '_' + opt.dts + '_' + str(opt.seed) + '_tr', tr_scores)
te_scores = np.array(test_scores)
np.save('./tes/' + opt.nps + '_' + opt.dts + '_' + str(opt.seed) + '_te', te_scores)
if if_tb:
writer.close()
if __name__ == '__main__':
main() 
超参数设置,nps的默认值给C1的原因是,提醒读者block块中的decide为false,因为可以发现paraset中并没有C1这个指标,代码却能够运行,说明block块中的paraset选择并没有被运行。
![]() 为True则开启对训练参数的保存
为True则开启对训练参数的保存
![]()
如果置为true,需要手动创建dynamic_data文件夹

这里如果提示没找到路径,就手动创建文件夹
Km.py
import numpy as np
from sklearn.cluster import MeanShift, estimate_bandwidth, AgglomerativeClustering, KMeans
import matplotlib.pyplot as plt
from itertools import cycle
pn = ['a', 'b', 'c', 'd']
plt.figure(1)
task = 'MNIST' #1
# task = 'TiDigits' #2
if task == 'MNIST':
num = '1'
elif task == 'TiDigits':
num = '26'
rplace = './dynamic_data/10_M3154_0.001_0.001/'
splace = './'
for i in range(1):
for j in range(2):
x = str(i)
w = str(i + 1)
y = str(pn[2 * j])
z = str(pn[2 * j + 1])
a1 = np.load(rplace + task + 'layer' + x + '_' + y + num + '.npy')
b1 = np.load(rplace + task + 'layer' + x + '_' + z + num + '.npy')
a2 = np.load(rplace + task + 'layer' + w + '_' + y + num + '.npy')
b2 = np.load(rplace + task + 'layer' + w + '_' + z + num + '.npy')
print('a1 size:', a1.shape)
print('b1 size:', b1.shape)
print('a2 size:', a2.shape)
print('b2 size:', b2.shape)
a1 = a1.reshape((a1.size, 1))
b1 = b1.reshape((b1.size, 1))
a2 = a2.reshape((a2.size, 1))
b2 = b2.reshape((b2.size, 1))
a = np.concatenate((a1, a2), axis=0)
b = np.concatenate((b1, b2), axis=0)
X = np.concatenate((a, b), axis=1)
bandwidth = estimate_bandwidth(X, quantile=0.5)
print(bandwidth)
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
labels_unique = np.unique(labels)
n_clusters = len(labels_unique)
if j == 0 and task == 'TiDigits':
n_clusters = 3
km = KMeans(n_clusters = n_clusters)
km.fit(X)
labels = km.labels_
print(labels)
cluster_centers = km.cluster_centers_
print('cluster_centers', cluster_centers)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters), colors):
my_members = labels == k
cluster_center = cluster_centers[k]
plt.plot(X[my_members, 0], X[my_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=10)
plt.title('Estimated number of clusters: %d' % n_clusters)
plt.savefig(splace + task + num + '_km_' + x + w + '_' + y + z)主要功能是对同层多个神经元的参数进行聚类,以期待找到一个或多个具有代表性的参数作为网络的固定值。
如果想实现混合神经元,请参考下面修改后的代码:
1. paraset.py中添加
# 添加M0、T0,更多也可以
elif nps == 'TM':
paraset = [params_M[0], params_T[0]]2. train.py修改训练模式
parser.add_argument('-nps', type = str, default = 'TM')3. block.py
这里前文对lens的理解有偏差,lens的含义是,混合多少个类型的神经元。
num表示的是,每种神经元占比为多少。文章中是顺序混合,因此paraset中各神经元参数的位置会影响网络。不过经测试,准确率改变不大。
if decide:
if self.ntype != '1':
paraset = make_paraset(self.ntype)
# lens = 1 or 2 or xxx
lens = len(paraset)
# 这里是个mix的过程, 随机混合不同神经元的比例
org = lens * torch.rand((self.output_size))
org = org.floor()
org = org.clamp(0, lens - 1)
# 1:1有序混合
ban = int(self.output_size/2)
# num = [self.output_size,ban]
num = []
for i in range(lens):
num.append(0)
for i in range(ban):
# num[int(org[i].data)] += 1
num[0] += 1
for j in range(self.output_size-ban):
num[1] += 1