kubernetes源码分析-pod创建流程
前言
首先放一张kubernetes的架构图。其中apiserver是整个架构的信息交互中心。所有组件都会与apisever交互。
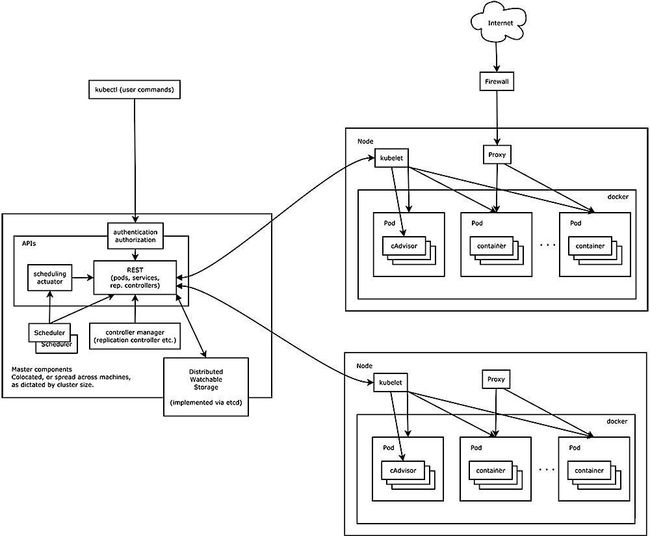
kubernetes中,每个node都部署了一个kubelet,通过kubelet实现对pod的创建、删除、更新等操作。
Pod正式创建前的操作
那么kubelet是怎么知道何时需要创建/删除一个pod以及对应的业务容器的呢?
在kubernetes中,用户通过kubectl create/run 来部署各种应用、deployment等。
kubectl接收到请求后,首先会执行一些客户端的验证操作,以确保不合法的操作/请求将会快速失败,也不会发送给api-server。以此减少不必要的操作负载,提高系统性能。
验证通过之后,Kubectl 开始将发送给 Kube-Apiserver 的 HTTP 请求进行封装。Kube-Apiserver 与 Etcd 进行通信,所有尝试访问或更改 Kubernetes 系统状态的请求都会通过 Kube-Apiserver 进行,Kubectl 也不例外。Kubectl 使用生成器(Generators)来构造 HTTP 请求。这个生成器就是进行序列化的工作。代码如下所示:
/pkg/kubectl/cmd/create/create.go
func (o *CreateOptions) RunCreate(f cmdutil.Factory, cmd *cobra.Command) error {
// raw only makes sense for a single file resource multiple objects aren't likely to do what you want.
// the validator enforces this, so
if len(o.Raw) > 0 {
return o.raw(f)
}
if o.EditBeforeCreate {
return RunEditOnCreate(f, o.PrintFlags, o.RecordFlags, o.IOStreams, cmd, &o.FilenameOptions)
}
schema, err := f.Validator(cmdutil.GetFlagBool(cmd, "validate"))
if err != nil {
return err
}
cmdNamespace, enforceNamespace, err := f.ToRawKubeConfigLoader().Namespace()
if err != nil {
return err
}
r := f.NewBuilder().
Unstructured().
Schema(schema).
ContinueOnError().
NamespaceParam(cmdNamespace).DefaultNamespace().
FilenameParam(enforceNamespace, &o.FilenameOptions).
LabelSelectorParam(o.Selector).
Flatten().
Do()
err = r.Err()
if err != nil {
return err
}该函数调用了NewBuilder、Schema等一系列函数,这段代码所做的事情是将命令行接收到的参数转化为一个资源的列。它使用了Builder模式的变种,使用独立的函数做各自的数据初始化工作。函数Schema、ContinueOnError、NamespaceParam、DefaultNamespace、FilenameParam、SelectorParam和Flatten都引入了一个指向Builder结构的指针,执行一些对它的修改,并且将这个结构体返回给调用链中的下一个方法来执行这些修改。Do函数最终调用了helper.go中的createResource函数来向api-server发送请求,代码如下:
/staging/src/k8s.io/cli-runtime/pkg/genericclioptions/resource/helper.go
func (m *Helper) createResource(c RESTClient, resource, namespace string, obj runtime.Object, options *metav1.CreateOptions) (runtime.Object, error) {
return c.Post().
NamespaceIfScoped(namespace, m.NamespaceScoped).
Resource(resource).
VersionedParams(options, metav1.ParameterCodec).
Body(obj).
Do().
Get()
}其中Post方法就是具体向APi-server发送请求的。
api-server收到请求后,进行认证、授权、准入控制。通过后,api-server将http请求进行反序列化,然后利用得到的结果构建运行时对象,并存储在etcd中。比如stke的StatefulSet、StatefulSetPlus和deployment对象。
接着各种controller开始工作,包括deploy、sts controller以及其他类型的controller等。这些controller会根据http的请求,构建pod对象,逐步将系统状态从当前状态修正为期待状态。
当controller正常运行后,etcd会保存StatefulSet、pod的资源记录。然而这些pod状态还处于pending状态,因为没有被调度分配到具体node上创建,这个过程依靠scheduler来解决。调度策略包括预选策略以及优选策略。
当分配到具体node后,就是kubelet的工作了。在k8s集群中,每个node节点都会启动一个kubelet进程,用于处理scheduler分配到node上的任务,管理pod的生命周期等。
Pod创建—kubelet创建过程
在分析kubelet处理pod流程之前,先分析kubelet的创建过程。
/pkg/kubelet/kubelet.go
/ NewMainKubelet instantiates a new Kubelet object along with all the required internal modules.
// No initialization of Kubelet and its modules should happen here.
func NewMainKubelet(kubeCfg *kubeletconfiginternal.KubeletConfiguration,
......
if kubeDeps.PodConfig == nil {
var err error
kubeDeps.PodConfig, err = makePodSourceConfig(kubeCfg, kubeDeps, nodeName, bootstrapCheckpointPath)
if err != nil {
return nil, err
}
}PodConfig是pod信息的来源,kubelet支持文件、URL和apiserver三种方式获取pod信息,通过 makePodSourceConfigh函数来获取来源。
继续往下看,这段代码主要包括设置container的GC策略,image 的GC策略,以及强行驱逐(Eviction)的策略(阈值、时限等)。
containerGCPolicy := kubecontainer.ContainerGCPolicy{
MinAge: minimumGCAge.Duration,
MaxPerPodContainer: int(maxPerPodContainerCount),
MaxContainers: int(maxContainerCount),
}
daemonEndpoints := &v1.NodeDaemonEndpoints{
KubeletEndpoint: v1.DaemonEndpoint{Port: kubeCfg.Port},
}
imageGCPolicy := images.ImageGCPolicy{
MinAge: kubeCfg.ImageMinimumGCAge.Duration,
HighThresholdPercent: int(kubeCfg.ImageGCHighThresholdPercent),
LowThresholdPercent: int(kubeCfg.ImageGCLowThresholdPercent),
}
//如果不强制逐出,不要为逐出阈值提供kubecfg.enforcenodeallocatable字段
enforceNodeAllocatable := kubeCfg.EnforceNodeAllocatable
if experimentalNodeAllocatableIgnoreEvictionThreshold {
// Do not provide kubeCfg.EnforceNodeAllocatable to eviction threshold parsing if we are not enforcing Evictions
enforceNodeAllocatable = []string{}
}
thresholds, err := eviction.ParseThresholdConfig(enforceNodeAllocatable, kubeCfg.EvictionHard, kubeCfg.EvictionSoft, kubeCfg.EvictionSoftGracePeriod, kubeCfg.EvictionMinimumReclaim)
if err != nil {
return nil, err
}
//逐出参数设置
evictionConfig := eviction.Config{
PressureTransitionPeriod: kubeCfg.EvictionPressureTransitionPeriod.Duration,
MaxPodGracePeriodSeconds: int64(kubeCfg.EvictionMaxPodGracePeriod),
Thresholds: thresholds,
KernelMemcgNotification: experimentalKernelMemcgNotification,
PodCgroupRoot: kubeDeps.ContainerManager.GetPodCgroupRoot(),
}继续往下看,这段代码主要是利用reflector反射器将list watch得到的信息同步到kubelet自己的store中。这个store的作用是能够避免多次与apiserver通信来获得pod信息,减少apiserver的压力。
//使用reflector将list watch得到的服务同步到servicestore中
serviceIndexer := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})
if kubeDeps.KubeClient != nil {
serviceLW := cache.NewListWatchFromClient(kubeDeps.KubeClient.CoreV1().RESTClient(), "services", metav1.NamespaceAll, fields.Everything())
r := cache.NewReflector(serviceLW, &v1.Service{}, serviceIndexer, 0)
go r.Run(wait.NeverStop)
}
serviceLister := corelisters.NewServiceLister(serviceIndexer)
//使用reflector将list watch得到的节点信息同步到nodestore对象中
nodeIndexer := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{})
if kubeDeps.KubeClient != nil {
fieldSelector := fields.Set{api.ObjectNameField: string(nodeName)}.AsSelector()
nodeLW := cache.NewListWatchFromClient(kubeDeps.KubeClient.CoreV1().RESTClient(), "nodes", metav1.NamespaceAll, fieldSelector)
r := cache.NewReflector(nodeLW, &v1.Node{}, nodeIndexer, 0)
go r.Run(wait.NeverStop)
}
nodeInfo := &predicates.CachedNodeInfo{NodeLister: corelisters.NewNodeLister(nodeIndexer)}
继续往下看,这段代码是创建kubelet实例,并进行一系列的初始化工作,包括podmanager、runtime对象等。
klet := &Kubelet{
hostname: hostname,
hostnameOverridden: len(hostnameOverride) > 0,
nodeName: nodeName,
kubeClient: kubeDeps.KubeClient,
csiClient: kubeDeps.CSIClient,
heartbeatClient: kubeDeps.HeartbeatClient,
onRepeatedHeartbeatFailure: kubeDeps.OnHeartbeatFailure,
......
// podManager负责管理当前节点上的pod信息。
klet.podManager = kubepod.NewBasicPodManager(kubepod.NewBasicMirrorClient(klet.kubeClient), secretManager, configMapManager, checkpointManager)
if remoteRuntimeEndpoint != "" {
// remoteImageEndpoint is same as remoteRuntimeEndpoint if not explicitly specified
if remoteImageEndpoint == "" {
remoteImageEndpoint = remoteRuntimeEndpoint
}
}
// TODO: These need to become arguments to a standalone docker shim.
pluginSettings := dockershim.NetworkPluginSettings{
HairpinMode: kubeletconfiginternal.HairpinMode(kubeCfg.HairpinMode),
NonMasqueradeCIDR: nonMasqueradeCIDR,
PluginName: crOptions.NetworkPluginName,
PluginConfDir: crOptions.CNIConfDir,
PluginBinDirString: crOptions.CNIBinDir,
MTU: int(crOptions.NetworkPluginMTU),
}
接下来创建runtime对象,probe manager对象(用于管理探针),还有volume manager等。
runtime, err := kuberuntime.NewKubeGenericRuntimeManager(
kubecontainer.FilterEventRecorder(kubeDeps.Recorder),
klet.livenessManager,
seccompProfileRoot,
containerRefManager,
machineInfo,
klet,
kubeDeps.OSInterface,
klet,
httpClient,
imageBackOff,
kubeCfg.SerializeImagePulls,
float32(kubeCfg.RegistryPullQPS),
int(kubeCfg.RegistryBurst),
kubeCfg.CPUCFSQuota,
kubeCfg.CPUCFSQuotaPeriod,
runtimeService,
imageService,
kubeDeps.ContainerManager.InternalContainerLifecycle(),
legacyLogProvider,
klet.runtimeClassManager,
)
......
klet.probeManager = prober.NewManager(
klet.statusManager,
klet.livenessManager,
klet.runner,
containerRefManager,
kubeDeps.Recorder)
......
// setup volumeManager
klet.volumeManager = volumemanager.NewVolumeManager(
kubeCfg.EnableControllerAttachDetach,
nodeName,
klet.podManager,
klet.statusManager,
klet.kubeClient,
klet.volumePluginMgr,
klet.containerRuntime,
kubeDeps.Mounter,
klet.getPodsDir(),
kubeDeps.Recorder,
experimentalCheckNodeCapabilitiesBeforeMount,
keepTerminatedPodVolumes)
最后,设置podworker和eviction manager。podworker是具体的执行者,也就是每次pod需要更新都会发送给podworker处理。
klet.podWorkers = newPodWorkers(klet.syncPod, kubeDeps.Recorder, klet.workQueue, klet.resyncInterval, backOffPeriod, klet.podCache)
klet.backOff = flowcontrol.NewBackOff(backOffPeriod, MaxContainerBackOff)
klet.podKillingCh = make(chan *kubecontainer.PodPair, podKillingChannelCapacity)
// setup eviction manager
evictionManager, evictionAdmitHandler := eviction.NewManager(klet.resourceAnalyzer, evictionConfig, killPodNow(klet.podWorkers, kubeDeps.Recorder), klet.podManager.GetMirrorPodByPod, klet.imageManager, klet.containerGC, kubeDeps.Recorder, nodeRef, klet.clock)
klet.evictionManager = evictionManager
klet.admitHandlers.AddPodAdmitHandler(evictionAdmitHandler)这里的worker设置为syncPod,该函数是处理pod的具体方法,会在接下来详细描述。
至此,kubelet对象创建完毕。
Pod创建—kubelet运行
回到kubelet的分析,接下来是kubelet的运行,也就是kebelet的Run方法
/pkg/kubelet/kubelet.go
ps:对函数的解读都在代码中的注释里
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
......
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
if kl.kubeClient != nil {
// 定时向apiserver更新node的信息。
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
// start syncing lease
if utilfeature.DefaultFeatureGate.Enabled(features.NodeLease) {
go kl.nodeLeaseController.Run(wait.NeverStop)
}
}
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Start loop to sync iptables util rules
if kl.makeIPTablesUtilChains {
go wait.Until(kl.syncNetworkUtil, 1*time.Minute, wait.NeverStop)
}
// 删除podworker没有正常处理的pod
go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
// 开启readiness 和liveness 的manager.
kl.statusManager.Start()
kl.probeManager.Start()
// Start syncing RuntimeClasses if enabled.
if kl.runtimeClassManager != nil {
go kl.runtimeClassManager.Run(wait.NeverStop)
}
// 开启 pod lifecycle event generator.并进入syncLoop方法中进行具体的工作
kl.pleg.Start()
kl.syncLoop(updates, kl)
}可以看到,最主要的入口就是sysLoop函数。接下来具体分析该函数。
Pod创建—循环控制(sysLoop)
/pkg/kubelet/kubelet.go
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
glog.Info("Starting kubelet main sync loop.")
// The resyncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
for {
if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 {
glog.Infof("skipping pod synchronization - %v", rs)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}syncLoop从不同的通道(文件、URL、apiserver)监听变化,主逻辑是for的无限循环,不断调用syncLoopIteration方法,在函数最开始,定义了两个定时器,syncTicker和housekeepingTicker,这两个定时器的作用是即使没有需要更新的pod,也会定时去同步和清理,前者的同步周期是1秒,后者的清理周期是2秒。
在for循环中,每次会先调用runtimeErrors函数来判断是否遇到了错误,如果遇到了错误,则会sleep一段时间(duration),然后继续continue for循环,sleep的时间最开始是base 100ms,然后如果一直遇到错误,则sleep时间以2倍速度递增,最大sleep时间为5秒。
Pod创建—循环监听Pod变化(sysLoopIteration)
一旦没有错误,则将duration时间重新设置为base。然后调用syncLoopIteration方法。继续看这个方法:
/pkg/kubelet/kubelet.go
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
glog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
glog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
glog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
glog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
glog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
glog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.RESTORE:
glog.V(2).Infof("SyncLoop (RESTORE, %q): %q", u.Source, format.Pods(u.Pods))
// These are pods restored from the checkpoint. Treat them as new
// pods.
handler.HandlePodAdditions(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
glog.Errorf("Kubelet does not support snapshot update")
}
if u.Op != kubetypes.RESTORE {
// If the update type is RESTORE, it means that the update is from
// the pod checkpoints and may be incomplete. Do not mark the
// source as ready.
// Mark the source ready after receiving at least one update from the
// source. Once all the sources are marked ready, various cleanup
// routines will start reclaiming resources. It is important that this
// takes place only after kubelet calls the update handler to process
// the update to ensure the internal pod cache is up-to-date.
kl.sourcesReady.AddSource(u.Source)
}
case e := <-plegCh:
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
glog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
glog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// Sync pods waiting for sync
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
glog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
glog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
glog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
// If the sources aren't ready or volume manager has not yet synced the states,
// skip housekeeping, as we may accidentally delete pods from unready sources.
glog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
glog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
glog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}这个方法就是对多个管道做遍历(利用select channel的方式)。一旦发现有消息就交给对应的handler处理。这里会处理五种管道:
syncCh:定时器管道,也就是上面的syncTicker.C参数传入的。每隔1秒就同步最新保存的pod状态。
houseKeepingCh:pod清理工作的管道。
plegCh:也就是Pod Lifecycle Event Generator的状态通道,如果pod状态发生改变(由于内部原因,与configCh不同,比如出错而被强杀、暂停等),则需要处理,处理逻辑具体如下:
case e := <-plegCh:
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
glog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
glog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}首先调用isSyncPodWorthy函数,该函数判断该pod是否需要同步,如果pod已经被移除,则不需要同步,返回false,否则返回true。如果不是pod被移除的情况,则需要同步,然后二次判断该pod是否存在,若存在则同步该pod。若pod的状态是ContainerDied,则清除该Container。
回到管道,第四种管道是liveness manager:如果健康检查发现某个pod不可用,则也会进行重启。具体处理逻辑类似pleg,不再赘述。
configCh:监听pod配置改变,读取配置事件的管道,也就是前面说过的通过文件、URL和apiserver汇聚的事件。add、update、delete。该管道是最重要的。处理逻辑如下:
switch u.Op {
case kubetypes.ADD:
glog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
glog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
glog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
glog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
glog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.RESTORE:
glog.V(2).Infof("SyncLoop (RESTORE, %q): %q", u.Source, format.Pods(u.Pods))
// These are pods restored from the checkpoint. Treat them as new
// pods.
handler.HandlePodAdditions(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
glog.Errorf("Kubelet does not support snapshot update")
}这里对事件的类型做了分类,包括add、update、remove、delete、restore等事件。我们分析最为常见的用户通过apiserver添加新的pod情况。调用的是handler.HandlePodAdditions(u.Pods)方法。
Pod创建—处理新增Pod(HandlePodAdditions)
/pkg/kubelet/kubelet.go
unc (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
// Responsible for checking limits in resolv.conf
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubepod.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}代码处理流程如下:
首先,利用sort.Sort(sliceutils.PodsByCreationTime(pods))方法将所有pod按创建日期排序,保证最先创建的pod最先处理。
将pod加入到podmanager中,因为podmanager是kubelet的信任的根基(source of truth)。如果podmanager找不到该pod,认为该pod被删除了。
如果是mirror pod则调用其方法进行处理:kl.handleMirrorPod(pod, start)。
mirror pod是静态pod的一个镜像。静态pods直接由特定节点上的kubelet进程来管理,不通过主控节点上的API服务器。静态pod不关联任何replication controller,它由kubelet进程自己来监控,当pod崩溃时重启该pod。对于静态pod没有健康检查。静态pod始终绑定在某一个kubelet,并且始终运行在同一个节点上。因此可以在API服务器查询到该pod,但是不被API服务器控制(例如不能删除)。
然后调用canAdmitPod方法判断pod是否能在该node上运行,如果不可以则拒绝。如果可以运行,则调用dispatchWork方法将pod创建分配给具体的worker异步处理。然后调用probeManager.AddPod方法为pod进行探针的定期检查(前提是pod的yaml中定义了liveness或readiness的检查)。
Pod创建—下发工作任务(dispatchWork)
接下来分析dispatchWork方法深入分析pod创建流程:
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
if kl.podIsTerminated(pod) {
if pod.DeletionTimestamp != nil {
// If the pod is in a terminated state, there is no pod worker to
// handle the work item. Check if the DeletionTimestamp has been
// set, and force a status update to trigger a pod deletion request
// to the apiserver.
kl.statusManager.TerminatePod(pod)
}
return
}
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(&UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
OnCompleteFunc: func(err error) {
if err != nil {
metrics.PodWorkerLatency.WithLabelValues(syncType.String()).Observe(metrics.SinceInMicroseconds(start))
}
},
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}代码处理流程如下:
首先判断pod的状态是否为终止的:podIsTerminated。
然后调用podWorkers的UpdatePod方法对pod进行创建。并传入pod的一些参数,封装成UpdatePodOptions。
UpdatePod方法位于pkg/kubelet/pod_workers.go中:
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
// We need to have a buffer here, because checkForUpdates() method that
// puts an update into channel is called from the same goroutine where
// the channel is consumed. However, it is guaranteed that in such case
// the channel is empty, so buffer of size 1 is enough.
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
// Creating a new pod worker either means this is a new pod, or that the
// kubelet just restarted. In either case the kubelet is willing to believe
// the status of the pod for the first pod worker sync. See corresponding
// comment in syncPod.
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}处理逻辑如下:
首先对该worker上锁,p.podLock.Lock(),保证处理期间不会被其他进程调用。这个操作很细节。
然后利用podUpdates字典判断,pod id作为key,如果当前pod还没有启动过go routine,则启动一个,并创建一个channel用于传递pod信息,go runtine中调用了managePodLoop方法,对pod进行处理。
Pod创建—同步Pod(managePodLoop)
注意:从managePodLoop方法开始,启动一个新的协程进行,也就是异步操作。
/pkg/kubelet/pod_workers.go
managePodLoop
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
// This is a blocking call that would return only if the cache
// has an entry for the pod that is newer than minRuntimeCache
// Time. This ensures the worker doesn't start syncing until
// after the cache is at least newer than the finished time of
// the previous sync.
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
// This is the legacy event thrown by manage pod loop
// all other events are now dispatched from syncPodFn
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
glog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}处理逻辑:
首先判断pod的cache要比上一次同步的状态要新,才会进行更新。
更新操作是syncPodFn方法,该方法实际上调用的是kubelet.syncPod方法。
Pod创建—完成创建Pod前的准备工作(syncPod)
接下来分析syncPod方法,由于该方法的代码过长,会截取重要的代码段进行分析。
/pkg/kubelet/kubelet.go
syncPod
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
killPodOptions := o.killPodOptions
if killPodOptions == nil || killPodOptions.PodStatusFunc == nil {
return fmt.Errorf("kill pod options are required if update type is kill")
}
apiPodStatus := killPodOptions.PodStatusFunc(pod, podStatus)
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// we kill the pod with the specified grace period since this is a termination
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}首先判断是否为删除pod事件,如果是,则立即执行并返回。删除pod会在后续详细说明,这里不赘述。
然后判断pod是否能够运行在本节点:
runnable := kl.canRunPod(pod)
if !runnable.Admit {
// Pod is not runnable; update the Pod and Container statuses to why.
apiPodStatus.Reason = runnable.Reason
apiPodStatus.Message = runnable.Message
// Waiting containers are not creating.
const waitingReason = "Blocked"
for _, cs := range apiPodStatus.InitContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
for _, cs := range apiPodStatus.ContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
}调用canRunPod方法,该方法实现如下:
func (kl *Kubelet) canRunPod(pod *v1.Pod) lifecycle.PodAdmitResult {
attrs := &lifecycle.PodAdmitAttributes{Pod: pod}
// Get "OtherPods". Rejected pods are failed, so only include admitted pods that are alive.
attrs.OtherPods = kl.filterOutTerminatedPods(kl.podManager.GetPods())
for _, handler := range kl.softAdmitHandlers {
if result := handler.Admit(attrs); !result.Admit {
return result
}
}
// TODO: Refactor as a soft admit handler.
if err := canRunPod(pod); err != nil {
return lifecycle.PodAdmitResult{
Admit: false,
Reason: "Forbidden",
Message: err.Error(),
}
}
return lifecycle.PodAdmitResult{Admit: true}
}可以看到,最终调用canRunPod方法进行判断。该方法位于/pkg/kubelet/util.go。主要判断否能使用主机网络模式,是否可以以 privileged 权限运行等。
然后回到SyncPod方法。
if !runnable.Admit || pod.DeletionTimestamp != nil || apiPodStatus.Phase == v1.PodFailed {
var syncErr error
if err := kl.killPod(pod, nil, podStatus, nil); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
if !runnable.Admit {
// There was no error killing the pod, but the pod cannot be run.
// Return an error to signal that the sync loop should back off.
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
}
return syncErr
}如果canRunPod方法返回失败,即不能运行。则删除本地旧的pod(如果有的话),并返回错误信息。
如果成功则继续,为pod创建cgroup。
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
glog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
if err := pcm.EnsureExists(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToCreatePodContainer, "unable to ensure pod container exists: %v", err)
return fmt.Errorf("failed to ensure that the pod: %v cgroups exist and are correctly applied: %v", pod.UID, err)
}
}
}这里要注意的是,在创建cgroup的时候,首先进行了一个判断,不会为只运行一次的pod创建cgroup,因为当前的策略是如果kubelet重启,并不会重启那些只运行一次的pod。因此不会为只运行一次并且之前被kill过的pod创建cgroup。
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever)
接着,为pod创建mirror pod,如果该pod是static pod类型。
if kubepod.IsStaticPod(pod) {
podFullName := kubecontainer.GetPodFullName(pod)
deleted := false
if mirrorPod != nil {
if mirrorPod.DeletionTimestamp != nil || !kl.podManager.IsMirrorPodOf(mirrorPod, pod) {
// The mirror pod is semantically different from the static pod. Remove
// it. The mirror pod will get recreated later.
glog.Warningf("Deleting mirror pod %q because it is outdated", format.Pod(mirrorPod))
if err := kl.podManager.DeleteMirrorPod(podFullName); err != nil {
glog.Errorf("Failed deleting mirror pod %q: %v", format.Pod(mirrorPod), err)
} else {
deleted = true
}
}
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
glog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
glog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
glog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}创建mirror pod处理流程如下:
if mirrorPod.DeletionTimestamp != nil || !kl.podManager.IsMirrorPodOf(mirrorPod, pod)
首先判断mirror pod是否已经存在,如果存在,判断该mirror pod是否被用户声明删除过,或者该mirror pod是否属于该pod。如果两个判断有一个失败,则判定mirror pod与当前static pod不符,需要重新创建。
如果mirror pod不存在或者被删除。则需要创建新的mirror pod,在创建之前需要判断node是否正常运行:
if err != nil || node.DeletionTimestamp != nil
如果node不存在集群中,则无需创建mirror pod。
如果node正常运行,则调用CreateMirrorPod方法创建mirror pod。
创建mirror pod的目的在于,由于static pod完全由kubelet自己掌握,mirror pod能够使得用户利用kubectl通过api server查看对应的pod,并且可以直接通过kubectl logs查看pod log信息。
创建完mirror pod后继续往下走:创建pod的数据目录,存放volume
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
glog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to mount volumes for pod %q: %v", format.Pod(pod), err)
glog.Errorf("Unable to mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}源码中利用WaitForAttachAndMount方法,等待所有的volume 都挂载完成。
在WaitForAttachAndMount方法中,会不断对挂载操作进行循环判断,300ms判断一次,超时时间为2min。
挂载volume后,开始拉取镜像,对image secrets进行判断,如果定义了secrets iamge,就去api server获取对应的secret数据。
代码如下:
pullSecrets := kl.getPullSecretsForPod(pod)getPullSecretsForPodh函数如下:
pkg/kubelet/kubelet_pods.go
func (kl *Kubelet) getPullSecretsForPod(pod *v1.Pod) []v1.Secret {
pullSecrets := []v1.Secret{}
for _, secretRef := range pod.Spec.ImagePullSecrets {
secret, err := kl.secretManager.GetSecret(pod.Namespace, secretRef.Name)
if err != nil {
glog.Warningf("Unable to retrieve pull secret %s/%s for %s/%s due to %v. The image pull may not succeed.", pod.Namespace, secretRef.Name, pod.Namespace, pod.Name, err)
continue
}
pullSecrets = append(pullSecrets, *secret)
}
return pullSecrets
}可以看到,该函数调用了GetSecret方法获得secret,GetSecret方法实际上调用了client的Get方法,以http的方式向api server请求secret数据。
获得secret数据后,会在接下来的容器创建中使用该secret,也就是根据secret去拉取镜像。
回到SyncPod方法,继续往下分析,这里是SyncPod最后的处理逻辑了:
调用containerRuntime.SyncPod去实现真正的容器创建逻辑。传入的参数包括了pullSecrets。
result := kl.containerRuntime.SyncPod(pod, apiPodStatus, podStatus, pullSecrets, kl.backOff)以上,SyncPod方法的全部逻辑就处理完了。可以看到kubelet中的SyncPod方法的所有逻辑都和具体的容器创建没关系,可以看作是提前的准备工作,最重要的工作就是调用Runtime的SyncPod方法,来创建具体的container创建。
Pod创建—容器创建(containerRuntime.SyncPod)
接下来具体分析containerRuntime.SyncPod方法。
pkg/kubelet/kuberuntime/kuberuntime_manager.go
该方法可细分为6步,按照每步贴上代码分析:
step1:比较传递的pod信息和实际运行的pod,两者之间的差别,即需要更新的地方。
podContainerChanges := m.computePodActions(pod, podStatus)
glog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
glog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf(ref, v1.EventTypeNormal, events.SandboxChanged, "Pod sandbox changed, it will be killed and re-created.")
} else {
glog.V(4).Infof("SyncPod received new pod %q, will create a sandbox for it", format.Pod(pod))
}
}通过computePodAction方法获得pod的container改变的地方,用podContainerChanges变量存储。接着判断podContainerChanges结构体,如果CreateSandbox字段为true,则需要创建新的sandbox。接着继续判断,利用GetReference构造该pod的reference,也就是引用。该引用一般用于event的记录中。然后判断如果SandboxID字段不为空,意味着是pod的sandbox发生改变,需要杀掉然后重新创建。否则认为是新创建的pod,则只需要新建sandbox。
step2:删除sandbox变化的pod
if podContainerChanges.KillPod {
if !podContainerChanges.CreateSandbox {
glog.V(4).Infof("Stopping PodSandbox for %q because all other containers are dead.", format.Pod(pod))
} else {
glog.V(4).Infof("Stopping PodSandbox for %q, will start new one", format.Pod(pod))
}
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if killResult.Error() != nil {
glog.Errorf("killPodWithSyncResult failed: %v", killResult.Error())
return
}
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}这个主要是当sandbox变化,比如切换了pause镜像,则会触发KillPod操作,删除pod,重新创建。而在代码中,会进一步判断,CreateSandbox字段,即当不需要创建sandbox,而又需要killpod,这说明是pod的容器出现了问题。否则则认为是sandbox变化,需要重新创建。
接着调用killPodWithSyncResult方法,杀死一个运行中的pod,并返回同步结果。
killPodWithSyncResult方法中,首先杀掉所有运行的container,然后杀掉sandbox。这个方法也是kubelet删除pod事件时会调用到的方法,非常值得研究,会在后续介绍删除pod文章中详细分析。
step3:如果step2没有执行,也就是不需要删除pod,那就是要删除一些container。
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
glog.V(3).Infof("Killing unwanted container %q(id=%q) for pod %q", containerInfo.name, containerID, format.Pod(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
glog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}也就是凡是具有ContainersToKill状态字段的container,都会被删除。
具体调用了killContainer方法,killContainer杀Container主要包含两个步骤:第一,运行pre-stop lifestyle hooks来预先stop,这个是优雅的停止。第二则是调用sigkill进行强行杀掉。
该方法也是也是kubelet删除pod事件时会调用到的方法,会在后续介绍删除pod文章中详细分析。
step4:创建sandbox,也就是pause容器,该容器包含了CNI网络组件等基础组件,是一个pod的基础。
if podContainerChanges.CreateSandbox {
var msg string
var err error
glog.V(4).Infof("Creating sandbox for pod %q", format.Pod(pod))
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
createSandboxResult.Fail(kubecontainer.ErrCreatePodSandbox, msg)
glog.Errorf("createPodSandbox for pod %q failed: %v", format.Pod(pod), err)
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
glog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), referr)
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedCreatePodSandBox, "Failed create pod sandbox: %v", err)
return
}调用createPodSandbox方法进行具体的sandbox构建。
pkg/kubelet/kuberuntime/kuberuntime_sandbox.go
// createPodSandbox creates a pod sandbox and returns (podSandBoxID, message, error).
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
if err != nil {
message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err)
glog.Error(message)
return "", message, err
}
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
if err != nil {
message := fmt.Sprintf("Create pod log directory for pod %q failed: %v", format.Pod(pod), err)
glog.Errorf(message)
return "", message, err
}
runtimeHandler := ""
if utilfeature.DefaultFeatureGate.Enabled(features.RuntimeClass) && m.runtimeClassManager != nil {
runtimeHandler, err = m.runtimeClassManager.LookupRuntimeHandler(pod.Spec.RuntimeClassName)
if err != nil {
message := fmt.Sprintf("CreatePodSandbox for pod %q failed: %v", format.Pod(pod), err)
return "", message, err
}
if runtimeHandler != "" {
glog.V(2).Infof("Running pod %s with RuntimeHandler %q", format.Pod(pod), runtimeHandler)
}
}
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
if err != nil {
message := fmt.Sprintf("CreatePodSandbox for pod %q failed: %v", format.Pod(pod), err)
glog.Error(message)
return "", message, err
}
return podSandBoxID, "", nil
}这个操作和上面的删除方法一样,调用相应的runtime去完成操作:runtimeService.RunPodSandbox。详细看下这个方法:
该方法在/pkg/kubelet/dockershim/docker_sandbox.go
func (ds *dockerService) RunPodSandbox(ctx context.Context, r *runtimeapi.RunPodSandboxRequest) (*runtimeapi.RunPodSandboxResponse, error) {
config := r.GetConfig()
// Step 1: Pull the image for the sandbox.
image := defaultSandboxImage
podSandboxImage := ds.podSandboxImage
if len(podSandboxImage) != 0 {
image = podSandboxImage
}
// NOTE: To use a custom sandbox image in a private repository, users need to configure the nodes with credentials properly.
// see: http://kubernetes.io/docs/user-guide/images/#configuring-nodes-to-authenticate-to-a-private-repository
// Only pull sandbox image when it's not present - v1.PullIfNotPresent.
if err := ensureSandboxImageExists(ds.client, image); err != nil {
return nil, err
}
// Step 2: Create the sandbox container.
if r.GetRuntimeHandler() != "" {
return nil, fmt.Errorf("RuntimeHandler %q not supported", r.GetRuntimeHandler())
}
createConfig, err := ds.makeSandboxDockerConfig(config, image)
if err != nil {
return nil, fmt.Errorf("failed to make sandbox docker config for pod %q: %v", config.Metadata.Name, err)
}
createResp, err := ds.client.CreateContainer(*createConfig)
if err != nil {
createResp, err = recoverFromCreationConflictIfNeeded(ds.client, *createConfig, err)
}
if err != nil || createResp == nil {
return nil, fmt.Errorf("failed to create a sandbox for pod %q: %v", config.Metadata.Name, err)
}
resp := &runtimeapi.RunPodSandboxResponse{PodSandboxId: createResp.ID}
ds.setNetworkReady(createResp.ID, false)
defer func(e *error) {
// Set networking ready depending on the error return of
// the parent function
if *e == nil {
ds.setNetworkReady(createResp.ID, true)
}
}(&err)
// Step 3: Create Sandbox Checkpoint.
if err = ds.checkpointManager.CreateCheckpoint(createResp.ID, constructPodSandboxCheckpoint(config)); err != nil {
return nil, err
}
// Step 4: Start the sandbox container.
// Assume kubelet's garbage collector would remove the sandbox later, if
// startContainer failed.
err = ds.client.StartContainer(createResp.ID)
if err != nil {
return nil, fmt.Errorf("failed to start sandbox container for pod %q: %v", config.Metadata.Name, err)
}
// Rewrite resolv.conf file generated by docker.
// NOTE: cluster dns settings aren't passed anymore to docker api in all cases,
// not only for pods with host network: the resolver conf will be overwritten
// after sandbox creation to override docker's behaviour. This resolv.conf
// file is shared by all containers of the same pod, and needs to be modified
// only once per pod.
if dnsConfig := config.GetDnsConfig(); dnsConfig != nil {
containerInfo, err := ds.client.InspectContainer(createResp.ID)
if err != nil {
return nil, fmt.Errorf("failed to inspect sandbox container for pod %q: %v", config.Metadata.Name, err)
}
if err := rewriteResolvFile(containerInfo.ResolvConfPath, dnsConfig.Servers, dnsConfig.Searches, dnsConfig.Options); err != nil {
return nil, fmt.Errorf("rewrite resolv.conf failed for pod %q: %v", config.Metadata.Name, err)
}
}
// Do not invoke network plugins if in hostNetwork mode.
if config.GetLinux().GetSecurityContext().GetNamespaceOptions().GetNetwork() == runtimeapi.NamespaceMode_NODE {
return resp, nil
}
// Step 5: Setup networking for the sandbox.
// All pod networking is setup by a CNI plugin discovered at startup time.
// This plugin assigns the pod ip, sets up routes inside the sandbox,
// creates interfaces etc. In theory, its jurisdiction ends with pod
// sandbox networking, but it might insert iptables rules or open ports
// on the host as well, to satisfy parts of the pod spec that aren't
// recognized by the CNI standard yet.
cID := kubecontainer.BuildContainerID(runtimeName, createResp.ID)
err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations)
if err != nil {
errList := []error{fmt.Errorf("failed to set up sandbox container %q network for pod %q: %v", createResp.ID, config.Metadata.Name, err)}
// Ensure network resources are cleaned up even if the plugin
// succeeded but an error happened between that success and here.
err = ds.network.TearDownPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID)
if err != nil {
errList = append(errList, fmt.Errorf("failed to clean up sandbox container %q network for pod %q: %v", createResp.ID, config.Metadata.Name, err))
}
err = ds.client.StopContainer(createResp.ID, defaultSandboxGracePeriod)
if err != nil {
errList = append(errList, fmt.Errorf("failed to stop sandbox container %q for pod %q: %v", createResp.ID, config.Metadata.Name, err))
}
return resp, utilerrors.NewAggregate(errList)
}
return resp, nil
}这段代码很长,梳理总结流程如下:
1. 为sandbox拉取镜像,镜像名称为:"k8s.gcr.io/pause:3.1"
2. 创建sandbox的container。调用CreateContainer方法,该方法调用了ContainerCreate方法,该方法会向docker daemon 发送creat请求,用于创建container。
3. 启动start container。调用StartContainer方法,该方法调用了ContainerStart方法,该方法在/vendor/github.com/docker/docker/client/container_start.go中,会利用http向docker deamon发送start 请求。
4. 设置sandbox的网络,采用CNI插件。利用SetUpPod方法,该方法最终调用/pkg/kubelet/dockershim/network/cni/cni.go的SetUpPod方法,实现cni组件安装。
func (plugin *cniNetworkPlugin) SetUpPod(namespace string, name string, id kubecontainer.ContainerID, annotations map[string]string) error {
if err := plugin.checkInitialized(); err != nil {
return err
}
netnsPath, err := plugin.host.GetNetNS(id.ID)
if err != nil {
return fmt.Errorf("CNI failed to retrieve network namespace path: %v", err)
}
// Windows doesn't have loNetwork. It comes only with Linux
if plugin.loNetwork != nil {
if _, err = plugin.addToNetwork(plugin.loNetwork, name, namespace, id, netnsPath, annotations); err != nil {
glog.Errorf("Error while adding to cni lo network: %s", err)
return err
}
}
_, err = plugin.addToNetwork(plugin.getDefaultNetwork(), name, namespace, id, netnsPath, annotations)
if err != nil {
glog.Errorf("Error while adding to cni network: %s", err)
return err
}
return err
}在CNI安装组件时,CNI会首先判断network的namespace的path是否存在,也就是是否正常挂载了network。然后调用addToNetwork方法中的AddNetworkList完成安装。
vendor/github.com/containernetworking/cni/libcni/api.go
func (c *CNIConfig) AddNetworkList(list *NetworkConfigList, rt *RuntimeConf) (types.Result, error) {
var prevResult types.Result
for _, net := range list.Plugins {
pluginPath, err := invoke.FindInPath(net.Network.Type, c.Path)
if err != nil {
return nil, err
}
newConf, err := buildOneConfig(list, net, prevResult, rt)
if err != nil {
return nil, err
}
prevResult, err = invoke.ExecPluginWithResult(pluginPath, newConf.Bytes, c.args("ADD", rt))
if err != nil {
return nil, err
}
}
return prevResult, nil
}该方法执行了CNI 的 ADD 命令来创建网络。
至此,RunPodSandbox方法分析完毕,创建好了一个Sandbox。包括启动容器、CNI网络创建等。
回到containerRuntime.SyncPod方法,继续分析step 5。
step 5:启动init 容器。init容器是为业务容器做初始化工作的。比如可以预见加载一些动态资源。
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
glog.V(4).Infof("Backing Off restarting init container %+v in pod %v", container, format.Pod(pod))
return
}
glog.V(4).Infof("Creating init container %+v in pod %v", container, format.Pod(pod))
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeInit); err != nil {
startContainerResult.Fail(err, msg)
utilruntime.HandleError(fmt.Errorf("init container start failed: %v: %s", err, msg))
return
}
// Successfully started the container; clear the entry in the failure
glog.V(4).Infof("Completed init container %q for pod %q", container.Name, format.Pod(pod))
}具体调用了startContainer方法来实现init容器的创建。注意,这里的startContainer和sandbox创建时调用的StartContainer不同。
Pod创建—容器启动(startContainer)
这里的startContainer方法包括如下四个步骤:
1. 根据secret拉取镜像
2. 创建container,调用CreateContainer方法,这个方法与sandbox中创建容器的方法相同:即该方法调用了ContainerCreate方法,该方法会向docker daemon 发送creat请求,用于创建container。
3. 启动container,调用StartContainer方法,该方法与sandbox中启动容器的方法相同:该方法调用了ContainerStart方法,该方法在/vendor/github.com/docker/docker/client/container_start.go中,会利用http向docker deamon发送start 请求。
4. 启动post start lifestyle hook。这个hook的作用可以理解为,用户可在外部给启动的container发送命令,即操作container做一些初始化的操作。
以上就完成了init容器的启动。接下来就是SyncPod的最后一步,也就是创建pod的最后一步。
step 6:启动业务容器
for _, idx := range podContainerChanges.ContainersToStart {
container := &pod.Spec.Containers[idx]
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
glog.V(4).Infof("Backing Off restarting container %+v in pod %v", container, format.Pod(pod))
continue
}
glog.V(4).Infof("Creating container %+v in pod %v", container, format.Pod(pod))
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeRegular); err != nil {
startContainerResult.Fail(err, msg)
// known errors that are logged in other places are logged at higher levels here to avoid
// repetitive log spam
switch {
case err == images.ErrImagePullBackOff:
glog.V(3).Infof("container start failed: %v: %s", err, msg)
default:
utilruntime.HandleError(fmt.Errorf("container start failed: %v: %s", err, msg))
}
continue
}
}就是通过读取podContainerChanges.ContainersToStart通道中的信息,对每一个需要启动的容器,都调用startContainer方法进行创建。由于startContainer方法在启动init容器的时候已经分析过,这里不再分析。
至此,SyncPod的代码全部分析完毕。也就是pod创建完成。
Pod创建—探测检测处理(prober_manager)
然后回到kubelet.go的HandlePodAdditions方法,在调用完dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)方法处理好pod的创建后。调用probeManager.AddPod(pod),将创建好的pod加入探针管理中。
AddPod代码如下:pkg/kubelet/prober/prober_manager.go
func (m *manager) AddPod(pod *v1.Pod) {
m.workerLock.Lock()
defer m.workerLock.Unlock()
key := probeKey{podUID: pod.UID}
for _, c := range pod.Spec.Containers {
key.containerName = c.Name
if c.ReadinessProbe != nil {
key.probeType = readiness
if _, ok := m.workers[key]; ok {
glog.Errorf("Readiness probe already exists! %v - %v",
format.Pod(pod), c.Name)
return
}
w := newWorker(m, readiness, pod, c)
m.workers[key] = w
go w.run()
}
if c.LivenessProbe != nil {
key.probeType = liveness
if _, ok := m.workers[key]; ok {
glog.Errorf("Liveness probe already exists! %v - %v",
format.Pod(pod), c.Name)
return
}
w := newWorker(m, liveness, pod, c)
m.workers[key] = w
go w.run()
}
}
}这段代码会利用for扫描pod的所有container,检查他们是否设置了readiness或liveness probe。如果设置了,则创建一个worker,然后启动一个go routine运行该worker的run方法。
在run方法中,会周期性调用doProbe方法进行周期探测,探测周期时间可以由用户在yaml文件中设置。
doProbe方法:/pkg/kubelet/prober/worker.go
该方法代码比较多,分段进行分析
如果pod没被创建或者被删除了,则跳过检测,但是会继续检测。
status, ok := w.probeManager.statusManager.GetPodStatus(w.pod.UID)
if !ok {
// Either the pod has not been created yet, or it was already deleted.
glog.V(3).Infof("No status for pod: %v", format.Pod(w.pod))
return true
}如果pod已经退出(phase),无论是成功还是失败,直接返回,并终止worker(返回false,终止worker)。
if status.Phase == v1.PodFailed || status.Phase == v1.PodSucceeded {
glog.V(3).Infof("Pod %v %v, exiting probe worker",
format.Pod(w.pod), status.Phase)
return false
}如果container没有创建或者已经被删除了,则直接返回,但是会继续检测。
c, ok := podutil.GetContainerStatus(status.ContainerStatuses, w.container.Name)
if !ok || len(c.ContainerID) == 0 {
// Either the container has not been created yet, or it was deleted.
glog.V(3).Infof("Probe target container not found: %v - %v",
format.Pod(w.pod), w.container.Name)
return true // Wait for more information.
}如果pod更新了容器,导致当前的w.containerID.String() != c.ContainerID,则等待最新的容器信息再次进行probe。利用w.onHold标识位。
if w.containerID.String() != c.ContainerID {
if !w.containerID.IsEmpty() {
w.resultsManager.Remove(w.containerID)
}
w.containerID = kubecontainer.ParseContainerID(c.ContainerID)
w.resultsManager.Set(w.containerID, w.initialValue, w.pod)
// We've got a new container; resume probing.
w.onHold = false
}
if w.onHold {
// Worker is on hold until there is a new container.
return true
}如果容器失败退出,并且不会再重启,则终止worker。
if c.State.Running == nil {
glog.V(3).Infof("Non-running container probed: %v - %v",
format.Pod(w.pod), w.container.Name)
if !w.containerID.IsEmpty() {
w.resultsManager.Set(w.containerID, results.Failure, w.pod)
}
// Abort if the container will not be restarted.
return c.State.Terminated == nil ||
w.pod.Spec.RestartPolicy != v1.RestartPolicyNever
}
容器时间太短,没有超时配置的初始化等待时间 InitialDelaySeconds,则过会再进行probe。
if int32(time.Since(c.State.Running.StartedAt.Time).Seconds()) < w.spec.InitialDelaySeconds {
return true
}调用prober.probe方法进行容器状态的检测。
result, err := w.probeManager.prober.probe(w.probeType, w.pod, status, w.container, w.containerID)
if err != nil {
// Prober error, throw away the result.
return true
}对探测结果进行判断:如果上次的结果和这次一样,则resultRun字段递增1,否则则将resultRun重置为1。
如果探测失败,且resultRun没有超过失败数的门槛,则继续检测。或者如果探测成功,且resultRun没有超过成功数的门槛,则继续检测。
if w.lastResult == result {
w.resultRun++
} else {
w.lastResult = result
w.resultRun = 1
} if (result == results.Failure && w.resultRun < int(w.spec.FailureThreshold)) ||
(result == results.Success && w.resultRun < int(w.spec.SuccessThreshold)) {
// Success or failure is below threshold - leave the probe state unchanged.
return true
}
这里可能会对成功数的门槛有些不理解,SuccessThreshold字段是这样解释的:
Minimum consecutive successes for the probe to be considered successful after having failed
失败后认为成功的探测的最小连续成功次数。默认为1。
也就是只要在探测失败后,连续探测成功1次,则认为成功探测了。也就是resultRun为1的情况,这种情况肯定是成功的。
如果连续两次失败了,则resultRun为2。那么不满足判断条件,则继续往下走。
保存最新的结果
w.resultsManager.Set(w.containerID, result, w.pod)如果探测类型是liveness,并且失败了,则需要删除容器重新创建。否则如果成功,或者探测类型为readness,则返回true,继续检测。
if w.probeType == liveness && result == results.Failure {
// The container fails a liveness check, it will need to be restarted.
// Stop probing until we see a new container ID. This is to reduce the
// chance of hitting #21751, where running `docker exec` when a
// container is being stopped may lead to corrupted container state.
w.onHold = true
w.resultRun = 0
}
return true对于liveness而言,它的处理逻辑在kubelet中,因为它关系着pod的生死,所以在kubelet的代码逻辑中:
syncLoopIteration
liveness probe处理逻辑:会调用HandlePodSyncs对pod进行处理。
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
glog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
glog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}而对于readiness,即使失败也不会重启pod,其代码在
pkg/kubelet/prober/prober_manager.go
func (m *manager) updateReadiness() {
update := <-m.readinessManager.Updates()
ready := update.Result == results.Success
m.statusManager.SetContainerReadiness(update.PodUID, update.ContainerID, ready)
}
在probermanager最开始启动时,也就是上述的kubelet.go的Run方法的kl.probeManager.Start()中,该方法代码如下:
func (m *manager) Start() {
// Start syncing readiness.
go wait.Forever(m.updateReadiness, 0)
}
可以看出一直在循环运行updateReadiness。也就是会定期从readinessManager.Updates()管道中读数据,然后将数据交给statusManager.SetContainerReadiness去处理,主要是更新缓存的pod信息,并且更新apiserver中的pod状态信息。负责 Service 逻辑的组件获取到了这个状态,就能根据不同的值来决定是否需要更新 endpoints 的内容,也就是 service 的请求是否发送到这个 pod。也即是readiness探针如果失败,虽然不会删除pod,但会导致服务请求不会发送到该pod。
以上就是容器探针的分析。
至此就是pod创建流程的所有分析。
概括总结
最后对以上内容进行概括总结,帮助理清思路:
1. kubelet的控制循环(syncloop)
syncLoop 中首先定义了一个 syncTicker 和 housekeepingTicker,即使没有需要更新的 pod 配置,kubelet 也会定时去做同步和清理 pod 的工作。然后在 for 循环中一直调用 syncLoopIteration,如果在每次循环过程中出现比较严重的错误,kubelet 会记录到 runtimeState 中,遇到错误就等待 5 秒中继续循环。
2. 监听pod变化(syncLoopIteration)
- syncLoopIteration 这个方法就会对多个管道进行遍历,发现任何一个管道有消息就交给 handler 去处理。它会从以下管道中获取消息:
- configCh:该信息源由 kubeDeps 对象中的 PodConfig 子模块提供,该模块将同时 watch 3 个不同来源的 pod 信息的变化(file,http,apiserver),一旦某个来源的 pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 pod 信息和更新的具体操作。
- syncCh:定时器管道,每隔一秒去同步最新保存的 pod 状态。
- houseKeepingCh:housekeeping 事件的管道,做 pod 清理工作。
- plegCh:该信息源由 kubelet 对象中的 pleg 子模块提供,该模块主要用于周期性地向 container runtime 查询当前所有容器的状态,如果状态发生变化,则这个 channel 产生事件。
- livenessManager.Updates():健康检查发现某个 pod 不可用,kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作
3. 处理新增的pod(HandlePodAddtions)
对于事件中的每个 pod,执行以下操作:
- 把所有的 pod 按照创建日期进行排序,保证最先创建的 pod 会最先被处理
- 把它加入到 podManager 中,podManager 子模块负责管理这台机器上的 pod 的信息,pod 和 mirrorPod 之间的对应关系等等。所有被管理的 pod 都要出现在里面,如果 podManager 中找不到某个 pod,就认为这个 pod 被删除了
- 如果是 mirror pod 调用其单独的方法
- 验证 pod 是否能在该节点运行,如果不可以直接拒绝
- 通过 dispatchWork 把创建 pod 的工作下发给 podWorkers 子模块做异步处理
- 在 probeManager 中添加 pod,如果 pod 中定义了 readiness 和 liveness 健康检查,启动 goroutine 定期进行检测
4. 下发任务(dispatchWork)
dispatchWorker 的主要作用是把某个对 Pod 的操作(创建/更新/删除)下发给 podWorkers。
5. 更新事件的channel(UpdataPod)
podWorkers 子模块主要的作用就是处理针对每一个的 Pod 的更新事件,比如 Pod 的创建,删除,更新。而 podWorkers 采取的基本思路是:为每一个 Pod 都单独创建一个 goroutine 和更新事件的 channel,goroutine 会阻塞式的等待 channel 中的事件,并且对获取的事件进行处理。而 podWorkers 对象自身则主要负责对更新事件进行下发。
6. 调用syncPodFn方法同步pod(managePodLoop)
managePodLoop 调用 syncPodFn 方法去同步 pod,syncPodFn 实际上就是kubelet.SyncPod。在完成这次 sync 动作之后,会调用 wrapUp 函数,这个函数将会做几件事情:
- 将这个 pod 信息插入 kubelet 的 workQueue 队列中,等待下一次周期性的对这个 pod 的状态进行 sync
- 将在这次 sync 期间堆积的没有能够来得及处理的最近一次 update 操作加入 goroutine 的事件 channel 中,立即处理。
7. 完成创建容器前的准备工作(SyncPod)
在这个方法中,主要完成以下几件事情:
- 如果是删除 pod,立即执行并返回
- 同步 podStatus 到 kubelet.statusManager
- 检查 pod 是否能运行在本节点,主要是权限检查(是否能使用主机网络模式,是否可以以 privileged 权限运行等)。如果没有权限,就删除本地旧的 pod 并返回错误信息
- 创建 containerManagar 对象,并且创建 pod level cgroup,更新 Qos level cgroup
- 如果是 static Pod,就创建或者更新对应的 mirrorPod
- 创建 pod 的数据目录,存放 volume 和 plugin 信息,如果定义了 pv,等待所有的 volume mount 完成(volumeManager 会在后台做这些事情),如果有 image secrets,去 apiserver 获取对应的 secrets 数据
- 然后调用 kubelet.volumeManager 组件,等待它将 pod 所需要的所有外挂的 volume 都准备好。
- 调用 container runtime 的 SyncPod 方法,去实现真正的容器创建逻辑
这里所有的事情都和具体的容器没有关系,可以看到该方法是创建 pod 实体(即容器)之前需要完成的准备工作。
8. 创建容器
containerRuntime(pkg/kubelet/kuberuntime)子模块的 SyncPod 函数才是真正完成 pod 内容器实体的创建。
syncPod 主要执行以下几个操作:
- 计算 sandbox 和 container 是否发生变化
- 创建 sandbox 容器
- 启动 init 容器
- 启动业务容器
initContainers 可以有多个,多个 container 严格按照顺序启动,只有当前一个 container 退出了以后,才开始启动下一个 container。
9. 启动容器
最终由 startContainer 完成容器的启动,其主要有以下几个步骤:
- 拉取镜像
- 生成业务容器的配置信息
- 调用 docker api 创建容器
- 启动容器
- 执行 post start hoo