caas k8s主控节点如何查询_容器架构 K8s 集群如何规划工作节点的大小?

欢迎来到小巧的Kubernetes学习——一个定期的专栏,讨论我们在网上看到的最有趣的问题,以及Kubernetes专家在我们的研讨会上回答的问题。
今天的答案由Daniel Weibel策划。Daniel是一名软件工程师,也是Learnk8s的讲师。
如果你想在下一集节目中提出你的问题,请通过电子邮件联系我们,或者你可以通过@learnk8s发推给我们。
你错过前几集了吗?你可以在这里找到它们。
当您创建Kubernetes集群时,首先出现的问题之一是:“我应该使用什么类型的工作节点以及它们的数量?”
如果您正在构建一个本地集群,您应该订购一些上一代的power服务器,还是使用数据中心中闲置的十几台旧机器?
或者,如果您正在使用托管的Kubernetes服务,如谷歌Kubernetes引擎(GKE),您应该使用8个n1-standard-1或两个n1-standard-4实例来实现您想要的计算能力吗?
集群能力
一般来说,Kubernetes集群可以被看作是将一组单独的节点抽象为一个大的“超级节点”。
这个超级节点的总计算能力(以CPU和内存计算)是所有组成节点的能力的总和。
有多种方法可以实现集群的理想目标容量。
例如,假设您需要一个总容量为8个CPU内核和32 GB RAM的集群。
例如,因为您希望在集群上运行的应用程序集需要此数量的资源。
下面是设计集群的两种可能的方法:

这两个选项都会产生具有相同容量的集群——但是左边的选项使用4个较小的节点,而右边的选项使用2个较大的节点。
哪个更好?
为了解决这个问题,让我们来看看“大节点少”和“小节点多”这两个相反方向的利弊。
注意,本文中的“节点”总是指工作节点。主节点的数量和大小的选择是一个完全不同的主题。
几个大节点
这方面最极端的情况是只有一个工作节点提供所需的整个集群容量。
在上面的示例中,这将是一个具有16个CPU核心和16 GB RAM的工作节点。
让我们看看这种方法可能具有的优势。
1 减少管理开销
简单地说,管理少量的机器比管理大量的机器更省力。
更新和补丁可以更快地应用,机器可以更容易地保持同步。
此外,机器数量少的情况下预期失败的绝对数量比机器数量多的情况下要少。
但是,请注意,这主要适用于裸机服务器,而不是云实例。
如果您使用云实例(作为托管Kubernetes服务或您自己在云基础设施上安装的Kubernetes的一部分),您将底层机器的管理外包给云提供商。
因此,管理云中10个节点并不比管理云中一个节点多多少。
2 降低每个节点的成本
虽然功能更强大的机器比低端机器更贵,但价格上涨不一定是线性的。
换句话说,一台拥有10个CPU核和10 GB RAM的机器可能比10台拥有1个CPU核和1 GB RAM的机器更便宜。
但是,请注意,如果使用云实例,这可能不适用。
目前主流云提供商Amazon Web Services、谷歌云平台、Microsoft Azure的定价方案中,实例价格随容量呈线性增长。
例如,在谷歌云平台上,64个n1-standard-1实例的开销与一个n1-standard-64实例的开销完全相同,而且这两个选项都提供64个CPU核心和240 GB内存。
因此,在云计算中,使用更大的机器通常无法节省成本。
3 允许运行需要资源的应用程序
对于希望在集群中运行的应用程序类型来说,拥有大型节点可能只是一种需求。
例如,如果您有一个需要8 GB内存的机器学习应用程序,那么您就不能在只有1 GB内存的节点的集群上运行它。
但是您可以在具有10gb内存的节点的集群上运行它。
看了优点之后,让我们看看缺点。
1 每个节点有大量的荚
在更少的节点上运行相同的工作负载自然意味着在每个节点上运行更多的pods。
这可能会成为一个问题。
原因是每个pod在运行在节点上的Kubernetes代理上引入了一些开销——比如容器运行时(例如Docker)、kubelet和cAdvisor。
例如,kubelet对节点上的每个容器执行定期的活性和准备性探测——容器越多,意味着kubelet在每次迭代中要做的工作就越多。
cAdvisor收集节点上所有容器的资源使用统计信息,kubelet定期查询这些信息并在其API上公开——同样,这意味着在每次迭代中cAdvisor和kubelet都要做更多的工作。
如果Pod的数量变大,这些事情可能会开始降低系统的速度,甚至使系统变得不可靠。

由于常规的kubelet运行状况检查花费了太长的时间来遍历节点上的所有容器,因此有些节点被报告为未准备好。
由于这些原因,Kubernetes建议每个节点的最大容量为110个pods。
在此数字之前,Kubernetes已经过测试,可以在常见节点类型上可靠地工作。
取决于节点的性能,您可能能够成功地为每个节点运行更多的pods——但是很难预测事情是否会顺利运行,或者您会遇到问题。
大多数托管的Kubernetes服务甚至对每个节点的pods数量施加了硬性限制:
在Amazon Elastic Kubernetes服务(EKS)上,每个节点的最大pods数量取决于节点类型,从4个到737个不等。
在谷歌Kubernetes引擎(GKE)上,限制是每个节点100个pods,不管节点的类型是什么。
在Azure Kubernetes服务(AKS)上,默认限制是每个节点30个pods,但可以增加到250个。
因此,如果您计划为每个节点运行大量的pods,那么您可能应该事先测试是否一切正常。
2 有限的复制
少量节点可能会限制应用程序的有效复制程度。
例如,如果一个高可用性应用程序包含5个副本,但只有2个节点,那么该应用程序的有效复制程度将减少到2。
这是因为5个副本只能分布在2个节点上,如果其中一个出现故障,可能会同时取消多个副本。
另一方面,如果至少有5个节点,则每个副本可以在单独的节点上运行,单个节点的故障最多会导致一个副本失效。
因此,如果您有高可用性需求,您可能需要集群中的某个最小节点数。
3 高爆炸半径
如果只有几个节点,那么失败节点的影响要大于有很多节点时的影响。
例如,如果只有两个节点,其中一个失败了,那么大约一半的pods消失了。
Kubernetes可以将失败节点的工作负载重新安排到其他节点。
但是,如果只有几个节点,那么剩余节点上没有足够的备用容量来容纳故障节点的所有工作负载的风险就会更高。
其结果是,应用程序的某些部分将永久关闭,直到再次启动失败的节点。
因此,如果希望减少硬件故障的影响,可能需要选择更多的节点。
4 大的增量伸缩
Kubernetes为云基础设施提供了一个集群自动存储器,允许根据当前需求自动添加或删除节点。
如果您使用大节点,那么您将有一个大的伸缩增量,这使得伸缩更加笨拙。
例如,如果您只有2个节点,那么添加一个额外的节点意味着将集群的容量增加50%。
这可能比您实际需要的要多得多,这意味着您需要为未使用的资源付费。
因此,如果您计划使用集群自动缩放,那么较小的节点允许更灵活、更经济的伸缩行为。
在讨论了少数大节点的优缺点之后,让我们转向许多小节点的场景。
许多小的节点
这种方法由许多小节点组成集群,而不是由几个大节点组成。
这种方法的优点和缺点是什么?
使用许多小节点的优点主要对应于使用少数大节点的缺点。
1 减少爆炸半径
如果您有更多的节点,那么每个节点上的pods自然会更少。
例如,如果你有100个荚和10个节点,那么每个节点平均只包含10个荚。
因此,如果其中一个节点发生故障,其影响将限制在总工作负载中较小的比例。
很有可能只有你的一些应用程序受到影响,而且可能只有少量的副本,所以应用程序作为一个整体保持正常运行。
此外,在剩余的节点上很可能有足够的空闲资源来容纳故障节点的工作负载,因此Kubernetes可以重新安排所有pods,从而使您的应用程序相对快速地返回到功能完整的状态。
2 允许高复制
如果已经复制了高可用性应用程序和足够多的可用节点,那么Kubernetes调度器可以将每个副本分配到不同的节点。
您可以通过节点亲和性、荚果亲和性/反亲和性、污染和容忍影响调度器的荚果放置。
这意味着,如果一个节点失败,最多只有一个副本受到影响,并且您的应用程序仍然可用。
在了解了使用许多小节点的优点之后,有什么缺点呢?
1 节点数大
如果使用较小的节点,则自然需要更多节点来实现给定的集群容量。
但是大量的节点对于库伯涅茨控制飞机来说是一个挑战。
例如,每个节点都需要能够与其他节点通信,这使得可能通信路径的数量以节点数量的平方增长——所有这些都必须由控制平面管理。
Kubernetes控制器管理器中的节点控制器定期遍历集群中的所有节点来运行运行状况检查——节点越多意味着节点控制器的负载越大。
节点越多,etcd数据库的负载也就越多——每个kubelet和kube-proxy都会产生一个etcd的监视客户端(通过API服务器),etcd必须将对象更新广播到该客户端。
一般来说,每个工作节点都会对主节点上的系统组件施加一些开销。
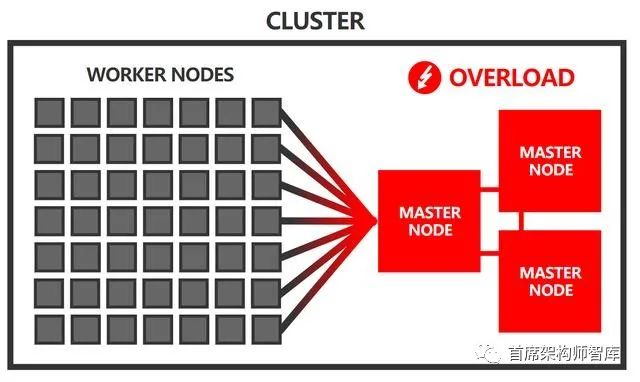
Kubernetes官方宣称支持最多5000个节点的集群。
然而,在实践中,500个节点可能已经带来了不小的挑战。
大量工作节点的影响可以通过使用更多的性能主节点来减轻。
这就是在实践中所做的——下面是kubeup在云基础设施上使用的主节点大小:
谷歌云平台5个工作节点→n1-standard-1主节点500个工作节点→n1-标准-32主节点
亚马逊网络服务5个工人节点→m3。中主节点500个工作节点→c4.8xlarge主节点
如您所见,对于500个工作节点,使用的主节点分别有32个和36个CPU内核,以及120 GB和60 GB内存。
这些都是相当大的机器!
所以,如果你打算使用大量的小节点,有两件事你需要记住:
您拥有的工作节点越多,您需要的性能主节点就越多
如果您计划使用超过500个节点,那么您可能会遇到一些性能瓶颈,需要付出一些努力才能解决
像Virtual Kubelet这样的新开发允许绕过这些限制,允许具有大量工作节点的集群。
2 更多的系统开销
Kubernetes在每个工作节点上运行一组系统守护进程——这些守护进程包括容器运行时(例如Docker)、kube-proxy和kubelet(包括cAdvisor)。
cAdvisor被合并到kubelet二进制文件中。
所有这些守护进程一起消耗固定数量的资源。
如果使用许多小节点,那么这些系统组件所使用的资源部分就会更大。
例如,假设单个节点的所有系统守护进程一起使用0.1个CPU核和0.1 GB内存。
如果您有一个有10个CPU核心和10 GB内存的节点,那么守护进程将消耗集群容量的1%。
另一方面,如果您有1个CPU核心和1 GB内存的10个节点,那么守护进程将消耗集群容量的10%。
因此,在第二种情况下,你的账单的10%用于运行系统,而在第一种情况下,它只有1%。
因此,如果您想最大化基础设施支出的回报,那么您可能会选择更少的节点。
3 较低的资源利用率
如果您使用较小的节点,那么您最终可能会得到大量的资源片段,这些资源片段太小,无法分配给任何工作负载,因此仍未使用。
例如,假设所有的pods都需要0.75 GB内存。
如果你有10个节点和1 GB内存,那么你可以运行10个这样的pods -你最终会有0.25 GB内存块在每个节点上,你不能再使用。
这意味着,集群的总内存有25%被浪费了。
另一方面,如果你使用一个10gb内存的节点,那么你可以运行13个这样的pods——最终你只能运行一个0.25 GB的内存块,这是你无法使用的。
在这种情况下,您只浪费了2.5%的内存。
因此,如果您希望将资源浪费最小化,那么使用较大的节点可能会提供更好的结果。
4 Pod限制小节点
在一些云基础设施上,对小节点上允许的最大pods数量的限制比您预期的更严格。
Amazon Elastic Kubernetes服务(EKS)就是这种情况,其中每个节点的最大pods数量取决于实例类型。
比如t2。培养基实例,t2的最大荚果数为17个。小的是11,对于t2。微是4。
这些是非常小的数字!
任何超出这些限制的pods都不能被Kubernetes调度器调度,并无限期地保持挂起状态。
如果您不知道这些限制,这可能会导致难以发现的错误。
因此,如果您计划在Amazon EKS上使用小节点,请检查相应的每个节点的podcast限制,并计算两次节点是否能够容纳所有的pods。
结论
那么,您应该在集群中使用少数大节点还是许多小节点呢?
一如既往,没有明确的答案。
要部署到集群的应用程序类型可能会指导您的决策。
例如,如果您的应用程序需要10gb的内存,那么您可能不应该使用小节点——集群中的节点至少应该有10gb的内存。
或者,如果您的应用程序需要10倍的复制才能实现高可用性,那么您可能不应该仅仅使用2个节点——您的集群应该至少有10个节点。
对于中间的所有场景,这取决于您的特定需求。
以上哪个优点和缺点与你有关?哪些是不?
也就是说,没有规则要求所有节点必须具有相同的大小。
没有什么可以阻止您在集群中混合使用不同大小的节点。
Kubernetes集群的工作节点可以是完全异构的。
这可能允许您权衡两种方法的优点和缺点。
最后,Pod的好坏要靠吃来检验——最好的方法就是去尝试,找到最适合你的组合!
本文:http://jiagoushi.pro/node/1186
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
| 微信公众号 | 【首席架构师智库】 适合物业仔细反复阅读。 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 |
 |
| 微信小号 | 50000人社区,激烈深度讨论:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. |  |
| QQ群 | 深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 |
|
| 视频号 | 【首席架构师智库】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 |
|
| 知识星球 | 向大咖提问,近距离接触,或者获得私密资料分享。 | 知识星球【首席架构师圈】 |
| 微信圈子 | 志趣相投的同好交流。 | 微信圈子【首席架构师圈】 |
| 喜马拉雅 | 路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |

