机器学习笔记(三)
相关文章链接
机器学习的基本概念
模型的评估与选择
回归分析
决策树与随机森林
支持向量机SVM与隐马尔可夫模型
卷积神经网络CNN与循环神经网络RNN
聚类与集成算法
机器学习笔记(三)
- 回归分析
-
- 线性回归
- 损失函数
- 最小二乘法
-
- 岭回归(Ridge Regression)
- 套索回归(lasso回归)
- 逻辑回归(对数几率回归)
- 范数
- 协方差
- 线性判别分析(LDA)
回归分析
回归分析(Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法 ,是一种预测性的建模技术。
线性回归
线性回归,简单而言,就是将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归包括一元线性回归和多元线性回归。
模型: Y = a + b 1 X 1 + b 2 X 2 + b 3 X 3 + ⋯ + b k X k Y=a+b_1X_1+b_2X_2+b_3X_3+\cdots+b_kX_k Y=a+b1X1+b2X2+b3X3+⋯+bkXk
其中a代表截距, b 1 , b 2 , b 3 , ⋯ , b k b_1,b_2,b_3,\cdots,b_k b1,b2,b3,⋯,bk为回归系数。
线性回归得出的模型不一定是一条直线,在只有一个变量的时候,模型是平面中的一条直线;有两个变量的时候,模型是空间中的一个平面;有更多变量时,模型将是更高维的。
线性回归模型有很好的可解释性,可以从权重W直接看出每个特征对结果的影响程度。
线性回归属于有监督学习,因此方法和监督学习应该是一样的,先给定一个训练集,根据这个训练集学习出一个线性函数,然后测试这个函数训练的好不好(即此函数是否足够拟合训练集数据),挑选出最好的函数(cost function最小)即可。
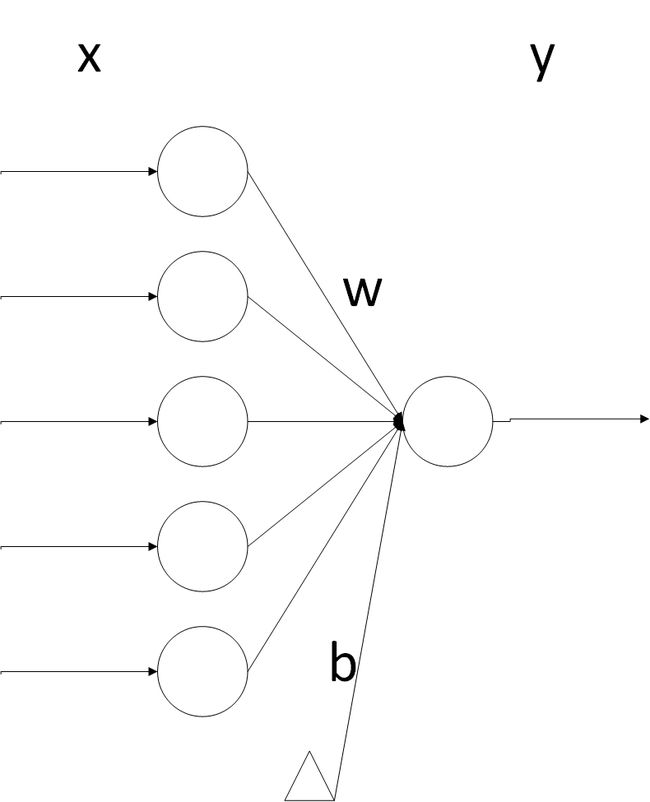
损失函数
是用来估量你模型的预测值 f(x)与真实值 YY 的不一致程度,损失函数越小,模型的效果就越好。
最小二乘法
实际上,线性回归中通常使用残差平方和,即点到直线的平行于y轴的距离而不用垂线距离,残差平方和除以样本量n就是均方误差。均方误差作为线性回归模型的代价函数(cost function)。使所有点到直线的距离之和最小,就是使均方误差最小化,这个方法叫做最小二乘法。
一般使用最小二乘法,真实值 y i y_i yi,预测值 h θ h_{\theta} hθ,则误差平方为 ( y i − h θ ) 2 (y_i-h_{\theta})^{2} (yi−hθ)2,找到合适的参数,使得误差平方和最小。损失函数如下:
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( y i − h θ ) 2 J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^{m}(y_i-h_\theta)^2 J(θ0,θ1)=2m1∑i=1m(yi−hθ)2
其中共有m个样本点,乘以1/2是为了方便计算。
由于线性回归可能出现过拟合的情况,因此有了岭回归和Lasso回归。这两个回归是为了解决线性回归出现的过拟合以及在通过正规方程方法求解回归系数的过程中出现的x转置乘以x不可逆这两类问题的,这两种回归均通过在损失函数中引入正则化项来达到目的。
岭回归(Ridge Regression)
- 岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价,获得回归系数更为符合实际、更可靠的回归方法,对病态数据的耐受性远远强于最小二乘法。
岭回归的损失函数如下:
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( y i − h θ ) 2 + α ∑ j = 1 n θ j 2 J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^{m}(y_i-h_\theta)^2+\alpha\sum_{j=1}^{n}\theta_j^2 J(θ0,θ1)=2m1∑i=1m(yi−hθ)2+α∑j=1nθj2
其中 α \alpha α为正则化参数,如果 α \alpha α选取过大,会把所有参数 θ \theta θ均最小化,造成欠拟合,如果 α \alpha α选取过小,会导致对过拟合问题解决不当。
套索回归(lasso回归)
- Lasso回归于岭回归非常相似,它们的差别在于使用了不同的正则化项,最终都实现了约束参数从而防止过拟合的效果。
- 具体地,岭回归引入的是L2范数惩罚项,Lasso回归引入的是L1范数惩罚项。
套索回归的损失函数如下:
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( y i − h θ ) 2 + α ∑ j = 1 n ∣ θ j ∣ J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^{m}(y_i-h_\theta)^2+\alpha\sum_{j=1}^{n}|\theta_j| J(θ0,θ1)=2m1∑i=1m(yi−hθ)2+α∑j=1n∣θj∣
- Lasso回归能够使得损失函数中的许多θ均变成0,这点要优于岭回归,因为岭回归是要所有的θ均存在的,这样计算量Lasso回归将远远小于岭回归。
岭回归L2正则化:尽可能使自变量回归系数接近于0但不能为0;Lasso回归L1正则化:可以将系数变为0,减少特征变量。
逻辑回归(对数几率回归)
逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,最大的区别就在于它们的因变量不同,如果是连续的,就是多重线性回归;如果是二项分布,就是Logistic回归。实际上是一种分类方法。
预测函数为: h θ ( x ) = 1 1 + e ( − θ T x ) h_θ(x)=\frac{1}{1+e^(−θ^Tx)} hθ(x)=1+e(−θTx)1
也可以对 h θ ( x ) h_\theta(x) hθ(x)取ln值来缓解量级差异。
C o s t ( h θ ( x ) , y ) = { − log ( h θ ( x ) ) i f y = 1 − log ( 1 − h θ ( x ) ) i f y = 0 Cost(h_\theta(x),y)=\begin{cases} -\log(h_\theta(x))\qquad if \; y=1\\ -\log(1-h_\theta(x))\qquad if\; y=0\end{cases} Cost(hθ(x),y)={−log(hθ(x))ify=1−log(1−hθ(x))ify=0
损失函数为: J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x i ) , y i ) = − 1 m [ ∑ i = 1 m ( y i log h θ ( x i ) + ( 1 − y i ) log ( 1 − h θ ( x i ) ) ) ] J(\theta)=\frac{1}{m}\sum_{i=1}^{m}Cost(h_\theta(x_i),y_i)=-\frac{1}{m}[\sum_{i=1}^{m}(y_i\log h_\theta(x_i)+(1-y_i)\log(1-h_\theta(x_i)))] J(θ)=m1∑i=1mCost(hθ(xi),yi)=−m1[∑i=1m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))]
范数
分为向量范数和矩阵范数,向量范数中定义如下:
L0范数: ∥ X ∥ 0 = ∑ i = 0 n X i 0 \rVert X\rVert _0=\sum_{i=0}^{n}X_i^0 ∥X∥0=∑i=0nXi0
其表示向量中非零元素的个数。
L1范数: ∥ X ∥ 0 = ∑ i = 0 n ∣ X i ∣ \rVert X\rVert_0=\sum_{i=0}^{n}\rvert X_i\rvert ∥X∥0=∑i=0n∣Xi∣
L1L1 范数是向量中各个元素绝对值之和。
L2范数: ∥ X ∥ 2 = ∑ i = 0 n X i 2 \rVert X\rVert_2=\sqrt{\sum_{i=0}^{n}X_i^2} ∥X∥2=∑i=0nXi2
Euclid范数(欧几里得范数,常用计算向量长度),即向量元素绝对值的平方和再开方。
协方差
协方差描述的是两个变量间的相关性。
∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) n \sum_{i=1}^{n}\frac{(x_i-\overline{x})(y_i-\overline{y})}{n} ∑i=1nn(xi−x)(yi−y)
或表示为:cov(X, Y) = E[(X-E[X])(Y-E[Y])]
对比方差和协方差的公式可以看出两者很像,但方差的结果是大于等于0的,当等于0时,说明样本的x特征取值唯一,反应的样本的x特征的离散程度;
协方差的取值则可以大于零也可以小于零,
当大于零时,说明对应的两个变量x和y与其均值相比都同大于或同小于,即两个变量的变化趋势相同(正相关);
当小于零时,说明对应的两个变量x和y不同时大于或小于其均值,即两个变量的变化趋势相反(负相关);
而当均方根接近零时,说明两个变量基本没有相关性,接近相互独立。
线性判别分析(LDA)
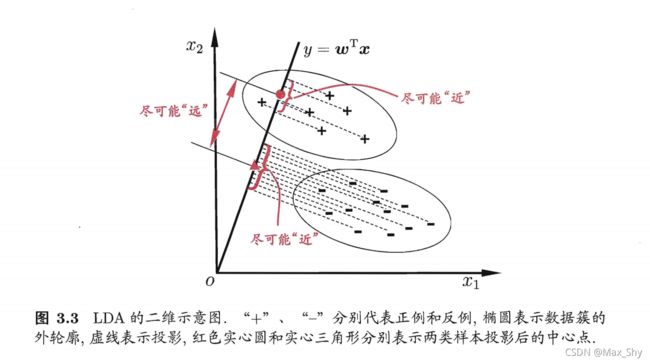
图源网络,侵删
线性判别分析的思想:给定训练样本集,设法将样例投影到一条直线上。使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远;在对新样本进行分类时,将其投影到该直线上,再根据投影点的位置来确定新样本的类别。
原理:
给定数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{(x_i,y_i)\}_{i=1}^m,y_i\in\{0,1\} D={(xi,yi)}i=1m,yi∈{0,1},令 X i 、 μ 、 ∑ i X_i、\mu、\sum_i Xi、μ、∑i分别表示 i ∈ { 0 , 1 } i\in\{0,1\} i∈{0,1}类示例的集合、均值向量、协方差矩阵。若将数据投影到直线 ω \omega ω上,则两类样本的中心在直线上的投影分别为 ω T μ 0 \omega^T\mu_0 ωTμ0和 ω T μ 1 \omega^T\mu_1 ωTμ1;若将所有样本点都投影到直线上,则两类样本的协方差分别为 ω T ∑ 0 ω \omega^T\sum_0\omega ωT∑0ω和 ω T ∑ 1 ω \omega^T\sum_1\omega ωT∑1ω。由于直线处于一维空间,因此 ω T μ 0 、 ω T μ 1 、 ω T ∑ 0 ω \omega^T\mu_0、\omega^T\mu_1、\omega^T\sum_0\omega ωTμ0、ωTμ1、ωT∑0ω和 ω T ∑ 1 ω \omega^T\sum_1\omega ωT∑1ω均为实数。
- 要使得同类样例的投影点尽可能接近,应让同类样例投影点的协方差尽可能小,即 ω T ∑ 0 ω + ω T ∑ 1 ω \omega^T\sum_0\omega+ \omega^T\sum_1\omega ωT∑0ω+ωT∑1ω尽可能小。
- 要使得异类样例的投影点尽可能的远,应让类中心之间的距离尽可能大,即 ∥ ω T μ 0 − ω T μ 1 ∥ 2 2 \rVert\omega^T\mu_0 -\omega^T\mu_1\rVert_2^2 ∥ωTμ0−ωTμ1∥22尽可能大。
同时考虑二者,则需要得到的最大化目标为:
J = ∥ ω T μ 0 − ω T μ 1 ∥ 2 2 ω T ∑ 0 ω + ω T ∑ 1 ω J=\frac{\rVert\omega^T\mu_0 -\omega^T\mu_1\rVert_2^2}{\omega^T\sum_0\omega+ \omega^T\sum_1\omega} J=ωT∑0ω+ωT∑1ω∥ωTμ0−ωTμ1∥22
= ω T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T ω ω T ( ∑ 0 + ∑ 1 ) ω =\frac{\omega^T (\mu_0-\mu_1)(\mu_0-\mu_1)^T \omega}{\omega^T(\sum_0+\sum_1)\omega} =ωT(∑0+∑1)ωωT(μ0−μ1)(μ0−μ1)Tω