简述聚类、分类、回归、关联分析的不同,需要分析常见算法并用现实应用场景说明
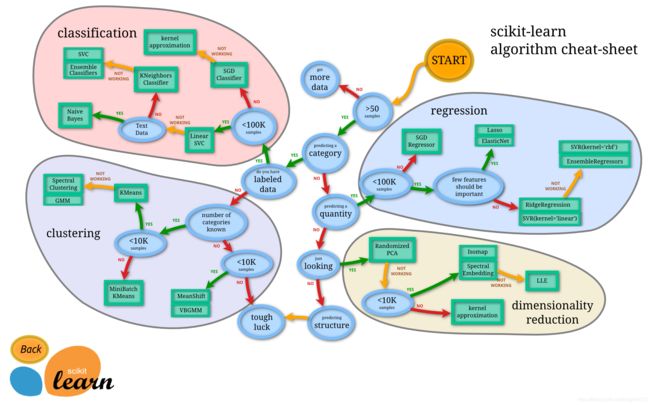
聚类、分类、回归、关联分析
classification (分类)。
分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。
regression (回归)。
回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。
clustering (聚类)。
聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。
association rule (关联规则)。
关联规则就是支持度与置信度分别满足用户给定阈值的规则。所谓关联,反映一个事件与其他事件间关联的知识。支持度揭示了A和B同时出现的频率。置信度揭示了B出现时,A有多大的可能出现。关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二阶段为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。
聚类、分类、回归、关联分析的不同与区别
1,给定一个样本特征 , 我们希望预测其对应的属性值 , 如果 是离散的, 那么这就是一个分类问题,反之,如果 是连续的实数, 这就是一个回归问题。
2,如果给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在 二维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
聚类(clustering)
无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
没有标准参考的学生给书本分的类别,表示自己认为这些书可能是同一类别的(具体什么类别不知道,没有标签和目标,即不是判断书的好坏(目标,标签),只能凭借特征而分类)。
分类(classification)
有监督学习的两大应用之一,产生离散的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。(即有目标和标签,能判断目标特征是属于哪一个类型)
回归(regression)
有监督学习的两大应用之一,产生连续的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断此人20年后今后的经济能力”的结果,结果是连续的,往往得到一条回归曲线。当输入自变量不同时,输出的因变量非离散分布(不仅仅是一条线性直线,多项曲线也是回归曲线)。
classification & regression:分类与回归
无论是分类还是回归,都是想建立一个预测模型 ,给定一个输入 , 可以得到一个输出 : 不同的只是在分类问题中, 是离散的; 而在回归问题中 是连续的。所以总得来说,两种问题的学习算法都很类似。所以在这个图谱上,我们看到在分类问题中用到的学习算法,在回归问题中也能使用。分类问题最常用的学习算法包括SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble, KNN 等。而回归问题也能使用 SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
clustering:聚类
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道到底有几个类别, 而聚类是不知道属性的范围的。所以 classification 也常常被称为 supervised learning(有监督学习)分类和回归都是监督学习, 而clustering就被称为unsupervised learning(无监督学习)常见的有聚类和关联规则。
clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。