复现Detectron2-blendmask之冰墩墩雪容融自定义数据集语义分割
第一节——Detectron2-BlendMask论文综述
1-1 Detectron2-BlendMask论文摘要
实例分割是计算机视觉中非常基础的任务。近来,全卷积实例分割方法得到了更多的注意力,因为它们要比双阶段的方法(如Mask R-CNN)更简单、高效。到目前为止,在计算复杂度相同的情况下,几乎所有的方法在掩码准确率上都落后于双阶段的 Mask R-CNN 方法,给了很大的提升空间。本文将实例级别信息和较低细粒度的语义信息结合,提升了掩码的预测。本文主要贡献就是,提出了一个混合模块,它受到自上而下实例分割方法和自下而上方法的启发。BlendMask 仅用少数几个通道,就能有效地预测密集的逐像素点的位置-敏感实例特征,只用一个卷积层就可以学习每个实例的注意力图,因此推理时非常快速。BlendMask 可以很容易地加到 state of the art 的单阶段检测器中,并且在性能上超过 Mask R-CNN,速度要快20 % 20\%20%。在单张1080ti显卡上,BlendMask 的一个轻量级版本取得的mAP 是34.2 % 34.2\%34.2%,速度为25FPS。由于其简洁性和有效性,BlendMask 能够作为一个简单而有效的基线模型,供实例预测任务使用。

图1-1 Detectron2-BlendMask论文
1-2 Detectron2-BlendMask简介
表现最优的目标检测器和分割器都延续了一个双阶段流程。它们由一个全卷积网络、RPN构成,在兴趣区域RoI上进行密集的预测。人们使用了一系列的轻量级网络(head)来重新对齐 RoI 的特征,进行预测。生成掩码的质量和速度与掩码 head 的结构息息相关。此外,各独立的 heads 很难与相关的任务(如语义分割任务)来共享特征,造成网络结构优化很困难。
最近一些单阶段目标检测方法如FCOS证明了它们可以在准确率上超过双阶段方法。在实例分割任务上也能进行单阶段检测就很诱人了:1)仅有卷积操作的模型更简单、更容易进行跨平台部署,2)一个统一的框架可以为多任务网络结构的优化提供便利和灵活度。
密集的实例分割方法可以追溯到 DeepMask,它是一个自上而下的方法,通过滑动窗的方式产生密集的实例掩码。在每个空间位置上,掩码的特征表示被编码为一个一维的向量。尽管结构上很简单,但在训练过程中存在多个障碍,使其无法取得优异的性能:1)特征和掩码之间的局部一致性丢失了;2)特征表示是冗余的,因为每个前景特征都重复编码了掩码信息;3)卷积中的下采样造成位置信息退化。
Dai 等人[8] 探索了第一个问题,他们尝试通过保留多个位置敏感图,保留局部一致性。Chen 等人[7] 研究了这个想法,针对目标实例掩码上的每个位置,提出了一个密集的表征对齐方法。但是,这个方法为了对齐而牺牲了表征的效率,造成第二个问题难以解决。第三个问题造成下采样过多的特征无法提供实例的细节信息。
鉴于这些难点,另一些人提出了一个自下而上的策略。这些方法生成大量的逐像素点的 embedding 特征,然后使用一些技巧来组合它们。取决于 embedding 的特征,这些组合方法包括简单的聚类,以及基于图的算法等。通过逐像素点的预测,局部一致性和位置信息就很好地保留了下来。自下而上方法的缺点有:1)过于依赖密集预测的质量,导致性能不佳,造成掩码的割裂与错误连接;2)对于类别较多的复杂场景泛化能力有限;3)需要非常复杂的后处理技术。
本文中作者将自上而下和自下而上的方法结合起来。作者研究了两个重要的方法:FCIS 和 YOLACT。它们都是预测实例级别的信息,如边框位置,然后利用裁剪手段(FCIS)或加权和(YOLACT)将其与逐像素点的预测结合起来。本文认为,这些过度简化的合并设计可能无法平衡顶层和底层特征表示的能力。
较高层级的特征对应着更大的感受野,可以获取实例的全局信息,如姿势,而较低层级的特征则保留了更好的位置信息,可以提供更精细的细节信息。本文的一个关注点在于,如何以全卷积实例分割的方式,更好地融合这两种特征。更具体点就是,作者把实例级别的信息变得更加丰富,并且进行细粒度更高的位置敏感掩码预测,为基于候选框的掩码方法提供通用性的操作。作者进行了广泛的研究,探索了最优的维度、分辨率、对齐方法,以及特征定位方法等。具体点就是:
对于基于候选框方式的实例掩码生成,设计了一个灵活的方法:Blender,它将实例级别的丰富信息和准确的密集的像素特征融合起来。在COCO 数据集的比较中,该方法的mAP要比 YOLACT 和 FCIS 的融合方法准确率高1.9和1.3分。
提出了一个简单的网络结构,BlendMask,基于目前 state of the art 的单阶段目标检测器 FCOS,在既有的网络结构之上增加了少许的计算量。
BlendMask 一个明显的优势就是,它的推理时间不会像双阶段方法一样,随着预测数量的增加而增加,对实时场景更加地鲁棒。
在COCO数据集上,当BlendMask 在主干网络为 ResNet-50 时,它取得的 mAP 为 37.0 % 37.0\%37.0%,而当主干网络为 ResNet-101 时,它可以取得 38.4 % 38.4\%38.4% 的mAP,这超越了 Mask R-CNN,而且要快20 % 20\%20%。该方法创下了全卷积实例分割的新记录,掩码mAP 要比 TensorMask 高 1.1 1.11.1 个点,而只需一半的训练次数,推理时间也仅为1 / 5 1/51/5。BlendMask 可能是第一个在掩码 AP 和推理效率上超过 Mask R-CNN 的算法。
因为 BlendMask 的底部模块可以同时分割 “things and stuff”,BlendMask 可以自然地解决全景分割问题,而无需改动。
对于 Mask R-CNN 的掩码 head,它的分辨率通常为28 × 28 28\times 2828×28,而由于 BlendMask 更加灵活,底部模块没有严格地绑定到FPN上,其底部模块输出的掩码的分辨率要更高。因此,BlendMask 输出掩码的边界可以更加准确,如图4所示。
BlendMask 非常通用而且灵活。只需稍微的改动,就可以将 BlendMask 应用到实例级别的识别任务上,如关键点检测。
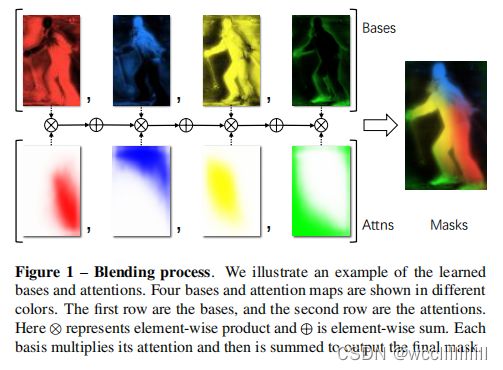
图1-2Detectron2-BlendMask论文
1-3 Detectron2-BlendMask的方法
Top-down 方法:自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:
1、mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask;
2、特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask;
3、下采样(使用步长大于1的卷积)导致的位置信息丢失;
Bottom-up 方法:自下而上的密集实例分割方法的一般套路是,通过生成per-pixel的embedding特征,再使用聚类和图论等后处理方法对其进行分组归类。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:
1、对密集分割的质量要求很高,会导致非最优的分割;
2、泛化能力较差,无法应对类别多的复杂场景;
3、后处理方法繁琐;
本论文中,detectron2-blendmask采取的是混合方法:本文想要结合 top-down和bottom-up两种思路,利用top-down方法生成的instance-level的高维信息(如bbox),对bottom-up方法生成的 per-pixel prediction进行融合。因此,本文基于FCOS提出简洁的算法网络BlendMask。融合的方法借鉴FCIS(裁剪)和YOLACT(权重加法)的思想,提出一种Blender模块,能够更好地融合包含instance-level的全局性信息和提供细节和位置信息的低层特征。
1-4 Detectron2-BlendMask的网络结构
BlendMask 由一个检测网络(detector module)和一个掩码分支(BlendMask module)构成。BlendMask的整体架构如下图所示,掩码分支有三个部分,bottom module用来对底层特征进行处理,是预测得分图的底部模块,生成的score map称为Base;top layer串接在检测器的box head上,一个预测实例注意力的顶部模块,生成Base对应的top level attention;最后是blender来对Base和attention进行融合,即一个将得分和注意力融合起来的混合模块。
底部模块。与其它基于候选框的全卷积网络类似,作者增加了一个底部模块来预测得分图,称之为 bases。作者在实验部分使用 DeepLab V3+作为 decoder。底部模块的输入可以作为主干网络特征,跟传统的语义分割网络,或者YOLACT和全景FPN中的特征金字塔一样。
Top layer 作者在每个检测tower 之上都附加了单个卷积层,预测 top-level 的注意力。
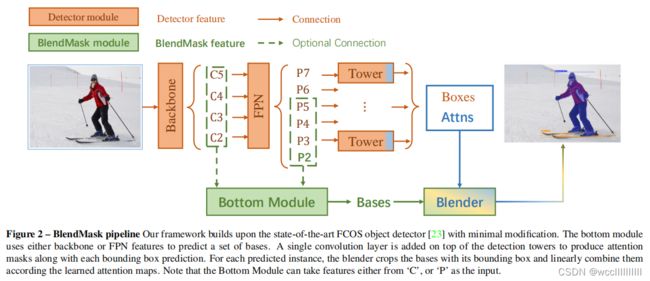
图1-3 Detectron2-BlendMask网络结构
文中使用的是DeeplabV3+的decoder,其他分割网络的decoder同样适用。
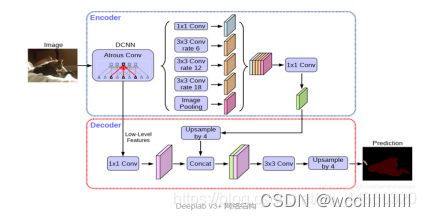
图1-4 DeeplabV3+的decoder
1-5 Detectron2-BlendMask的实验效果
实验结果(参数设置)
BlendMask的超参数共有以下几个:
1、R,bottom-level RoI的分辨率,论文中的设置为56;
2、M,top-level prediction(A)的分辨率,一般比R小得多,论文中的设置为7
3、K,base的数量,论文中的设置为4
4、bottom module的输入特征,来自骨干网络 (C3,C5)or FPN(P3, P5),论文中使用P3,P5
5、bottom bases的采样方法,最近邻池化 or 双线性池化,论文中采用 双线性池化
6、top-level attention的插值方法,最近邻插值法 or 双线性插值,论文中采用双线性插值
这些超参数在后面都会做消融实验,为了与其他模型做合理对比,在消融实验中使用的BlendMask设置如下:R_K_M分别为28, 4, 4;bottom module的输入特征采用来自骨干网络C3和C5;top-level attention使用的是最近邻插值法,与FCIS一致;Bottom level使用双线性池化,与RoIAlign一致。
精度:先来看总体的实验结果。在COCO数据集上,BlendMask的精度和速度超越了其他单阶段实例模型,并且也基本超越了Mask R-CNN(R-50, no aug情况下除外)。

图1-5 blendmask的精度
速度:同时也设置了一个快速版的BlendMask-RT,用以对比速度。快速版的改动如下:
1、prediction head的卷积数量减为3;
2、使用YOLACT中的Proto-FPN作为bottom module,将box tower和classification tower合并为一个(这里存疑);
从结果来看,BlendMask-RT比YOLACT在单张1080Ti上快了7ms,高出3.3AP

图1-6 blendmask的速度
可视化效果:从可视化效果来看,BlendMask的效果明显好于Mask R-CNN,原因是BlendMask采用了更高的分辨率(56 vs 28);相比YOLACT,BlendMask使用到了多次的信息融合,因此对相邻的实例分割效果更好。具体原文中有很详细的分析。

图1-7 blendmask可视化效果
消融实验:从前面的分析可以看出,BlendMask其实是多个模型的优点的融合,因此作者也做了大量的消融实验,来证明所选取的BlendMask结构的优越性。
融合方法:作者将blender改造成YOLACT和FCIS算法的融合方法进行实验,从实验结果可以看出,Blender的融合方法要更好。

图1-8 blendmask融合方法效果
此外,通过可视化中间过程,作者发现 BlendMask 可以编码两种局部信息,一是semantic masks,判断像素是否属于一个物体;二是position-sensitive feaures,判断像素是否在物体的某个部位。
如下图,四个base分别提取出了对不同的位置敏感的特征,这些特征可以帮助更好地分开相邻的实例,这也是比YOLACT更有效率的地方;而semantic masks可以让预测结果更加精细与顺滑。因此,BlendMask可以用更少的base学到更丰富的特征表示的原因。

图1-9 blendmask融合方法
特征分辨率(R)

图1-10 blendmask特征分辨率
base数目(K)

图1-11 base数目
1.6 Detectron2-BlendMask实验总结与讨论
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型综合各种优秀算法的结构,例如YOLACT,FOCS,Mask R-CNN,比较tricky,但是很有参考的价值。BlendMask模型十分精简,效果达到state-of-the-art,推理速度也不慢,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS,论文实验也做得很充足。
第二节——Detectron2-BlendMask实例分割项目
2-1 Anaconda虚拟环境搭建
detectron2 是Facebook开源的CV库,源码和使用方法访问git链接,其安装环境要求(Requirements)如下:python >= 3.6;至少PyTorch 1.3,torchvision 需和torch匹配 ;安装OpenCv;pycocotools;GCC >= 4.9。
我选用的是pycharm+anaconda搭建的环境,使用pip命令安装所需功能包,我的环境如下:python3.8.12+cuda11.1+cudnn-11.1-windows11-x64-v22000.556Windows 1000.22000.556.0+pytorch 1.9.0+cu102 CUDA:0 (GeForce GTX 1650, 4096.0MB)
安装命令大致如下:
1.首先我们anaconda创建新环境
conda create -n blendmask python=3.8
conda activate blendmask

图2-1 conda环境搭建
- 接着我们本地安装环境即可,这是因为conda安装pytorch1.10.0的时候经常会报错httperror,故我们需要进行本地安装,迅雷下载好所需的pytorch安装包。终端输入:conda install E:\anacondalib\pytorch-1.10.1-py3.8_cuda10.2_cudnn7_0.tar.bz2即可。

图2-2 pytorch本地安装
接下来我们激活环境,进入python,打印pytorch版本看一下。
import torch
print(torch.__version__) #注意是双下划线

图2-3 pytorch安装测试
3.然后再安装以下包:
pip install cython opencv-python pillow matplotlib termcolor cloudpickle tabulate tensorboard tqdm yacs mock fvcore pydot wheel future pywin32==225 
图2-4 anaconda安装各种所需库
4.安装pycocotools,直接去下载官方软件包,然后cd进入目录打开cmd命令行进行编译安装。
python setup.py build_ext install
图2-5 anaconda安装pycocotools
5.最后再编译全部文件以安装detectron2
执行命令:
python setup.py build develop

图2-6 anaconda完成detectron2依赖的安装
- 接下来我们还需安装一个工具包
cd AdelaiDet-master
python setup.py build develop
图2-7 anaconda安装adelaiDet
图2-8 我的blendmask环境
2-2自定义语义分割图像数据集
2-2-1 使用labelme标注数据集
我们可以从百度和搜狗图库中下载本次课程实践所需的数据集冰墩墩和雪容融标注图片,我们通过安装好的lableme进入anaconda激活labelme环境后输入lableme,我们的数据集分为两个类别,BingDwenDwen,ShueyRhonRhon。我们采用的是end to end方法进行数据集的标注,即End to end:指的是输入原始数据,输出的是最后结果,应用在特征学习融入算法,无需单独处理。我们要用到标注数据的工具为labelme。
第一步——我们要配置一个labelme的数据标注工具的环境,配置好以后就可以使用该程序进行数据的标注了。Labelme生成的标注文件为json文件

图2-9 激活labelme环境并且启动
第二步——启动labelme进入开始标注。
即可进行数据集的标注。

图2-10 标注冰墩墩数据集 
图2-11 标注冰墩墩数据集 
图2-12 标注冰墩墩数据集 
图2-13 标注好的数据集总览
2-2-2 生成npz格式数据集
第三步——我们还需要分别运行两个文件夹里的文件运行2coco.py生成instances_train2017和instances_val2017的json格式的文件。

图2-14 运行2coco.py生成instances_train2017.json文件
第四步——打开Pycharm进入detectron2-blendmask\AdelaiDet-master目录中打开运行python prepare_thing_sem_from_instance的python代码。这样会生成我们所需的npz格式的数据集文件,这样才可以被我们blendmask框架识别出来。
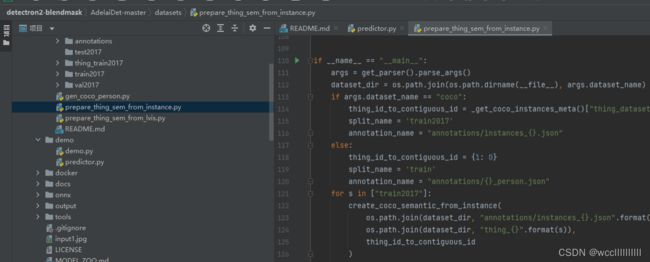
图2-15 运行python prepare_thing_sem_from_instance.py

图2-16 最终生成的npz格式文件
2-2-3 数据集目录格式
我们存放数据集文件夹格式如下图所示——即Detectron2-blendmask下的AdelaiDet-master工具包里面存放Datasets目录。目录里面有test2017、train2017、val2017、thing_train2017、annatations五个文件夹。

图2-17 数据集目录文件夹格式
2-2-4 训练前修改代码
第五步——我们需要在训练自己的模型之前修改模型训练代码中的各项参数指标。
第一处:修改AdelaiDet-master\configs\BlendMask\Base-BlendMask.yaml中的MAX_ITER(定义几张图片更新一次权重)、IMS_PER_BATCH(最大训练迭代次数)这个我设置的是500次、BASE_LR(训练学习率),这三个参数我们需要修改训练的。

图2-18 修改Base-BlendMask.yaml
第二处:修改AdelaiDet-master\tools\train_net.py中的cfg.MODEL.ROI_HEADS.NUM_CLASSES(这里我们只需要写上自己的类别数目就可以了,比如我这里识别两个类别冰墩墩和雪容融那我的类别就是NUM_CLASSES=2)
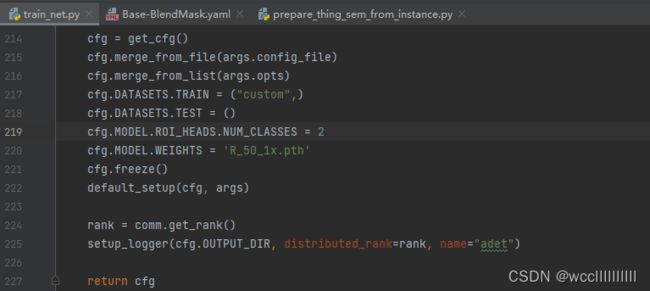
图2-19修改train_net.py
第三处:单gpu的话修改AdelaiDet-master\adet\config\defaults.py _C.MODEL.BASIS_MODULE.NORM = "SyncBN" --> _C.MODEL.BASIS_MODULE.NORM = "BN"
我的电脑只有一块GTX1650的显卡,那么我这里的参数设置当然需要修改为MODEL.BASIS_MODULE.NORM = "BN",用单GPU,device0——CUDA来运行代码。

图2-20 修改defaults.py
2-3训练冰墩墩雪容融pth模型
2-3-1 运行训练代码
第六步——进入pycharm终端运行这行命令——python tools/train_net.py --config-file configs/BlendMask/R_50_1x.yaml --num-gpus 1 OUTPUT_DIR output/blendmask/R_50_1x 运行完以后我们可以看到输出一张预览图,这是我们标注的数据集图片。 
图2-21 运行模型训练代码
2-3-2 可视化训练过程
在pycharm的终端我们能清楚得看到代码运行过程中,最开始运行代码的时候,我们可以看得见的有所采用的数据集的分类(我的CLASSE只有两个BingDwenDwen和ShueyRhonRhon),即显示我们数据集具体有几个类别。接下来开始正式训练以后,我们也可以看见模型正在训练,以及剩余训练所需的时间如eta:0:10:53则表示剩余训练时间10分53秒。还有各种loss函数的值。

图2-22 可视化分类的类别
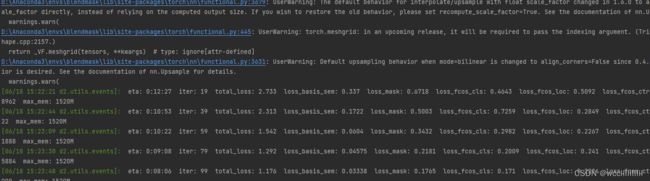
图2-23 可视化训练过程
2-3-2 模型训练完成
第七步——十几分钟以后,我们的设置的训练500次的模型就可以训练完成了。训练完成后会打印total training time(总体训练时长)和overal training speed(训练速度总览)以及我们损失函数的值。

图2-24 模型训练完成
输出的模型会被保存到AdelaiDet-masteroutput目录下
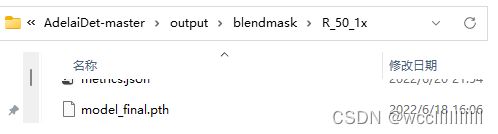
图2-25 输出的final模型
第三节——实验结论
3-1训练过程分析
深度学习中loss 代表训练集的损失值,在网络中用于更新网络参数;不对网络参数做修改,只做测试。
通常回调显示的 loss 有很多种,有时候一个总 loss 是多个子 loss 的加权求和。本次训练中在训练的上一张部分训练过程中我们能够可视化看得到的loss有三个类别tatal_loss、loss_basic_sem、loss_mask和,和一个loss_fcos_cls)。我们如果要衡量loss的变化,则只需要查看total_loss的值就可以了,它反映的是整体的loss。一般训练规律大致上符合如下普遍规律:各种loss数值上都是呈现下降的状态:则这样可以表面我们训练网络正常,最理想情况情况。

图3-1训练过程中展示的loss函数的值
我们可以发现在训练过程中实时输出的各类loss都是在不断变小的,例如图中的total_loss=2.733从这个不断变小再变化到1.176,这足以说明我们的训练基本上是正常进行的
3-2模型推理
我们打开pycharm终端激活blendmask环境后,输入如下命令:python tools/train_net.py --config-file configs/BlendMask/R_50_1x.yaml --num-gpus 1 OUTPUT_DIR output/blendmask/R_50_1x就可以开始推理输入的图片了。

图3-2运行模型推理命令
以下几张图片展示了我们通过输入一张图片,再经过我们训练好的模型处理后输出的图片的结果,我训练处理的模型能实现较高精度的语义分割识别,准确率最高可达到85%左右。由此足以说明我们这次模型训练基本上还是比较成功的。

图3-3 input模型推理的原图

图3-4经过模型处理后的语义分割检测图

图3-5经过模型处理后的语义分割检测图 
图3-6经过模型处理后的语义分割检测图
3-3摄像头实时分割检测
Detectron2-blendmask框架具有许多优秀的特性,其中有一个就是我们可以进行实时的语义分割检测。我们首先打开pycharm进入AdelaiDet-master的目录,然后激活环境再输入如下命令:Python demo/demo.py --config-file configs/BlendMask/R_50_1x.yaml --webcam --output results --opts MODEL.WEIGHTS output/blendmask/R_50_1x/model_final.pth
图3-7经过模型处理后的语义分割检测图 
图3-8模型的实时分割检测

图3-9模型的实时分割检测
3-4模型推理分析
在本次复现中,成功自定义了数据集,得益于Detectron2自底向上的算法和自上而下的blendmask分支的的attns注意力算法,将一张图片中的特征提取出来一一对应,各个元素相乘再相加合成,最终得到的实例分割结果。成功实现了仅仅通过500次迭代训练数据,最终成功输出一个能实现85%左右精度的pth模型。
第四节——参考文献
[1]《PyTorch深度学习》 [印度]毗湿奴·布拉马尼亚(Vishnu Subramanian)人民邮电出版社
[2]《深度学习》 作者: 刘玉良 出版社: 西安电子科技大学出版社
[3]《动手学深度学习》 作者: [美]阿斯顿·张 扎卡里·C. 立顿(Zachary(Aston Zhang) 李沐(Mu Li) 著
[4]《机器学习》作者: 赵卫东 、 董亮。 人民邮电出版社
[5]《面向深度学习的胰腺医学图像分割方法研究进展》曹路洋、李建微 福州大学物理与信息工程学院
[6]《机器学习》作者: [美] 米歇尔 (Mitchell T.M.) 机械工业出版社
[7] 《基于密集连接和特征增强的语义分割算法》 西安邮电大学
[8] 《机器学习》 [英] 弗拉赫(Peter Flach) 著; 段菲 译 / 人民邮电出版社 / 2016-01
[9] 《基于深度卷积网络的人车检测及跟踪算法研究》 张沁怡 北京邮电大学