nginx总结
nginx总结
文章目录
- nginx总结
-
-
- 1.简介
- 2.安装
- 3.性能调优
-
-
- 3.1 zero copy
- 3.2 多路复用器
- 3.3 nginx并发处理机制
- 3.4 全局模块下调优
- 3.5 event模块下的调优
- 3.6 http模块下的调优
-
- 4.请求定位
-
-
- **4.1资源访问**
- **4.2路径匹配优先级**
- 4.3 缓存配置
-
- 5.日志管理
- 6.静态代理
-
-
- 6.1扩展名拦截
- 6.2目录名拦截
- 6.3 页面压缩
-
- 7.反向代理
- 8.负载均衡
- 9.动静分离
- 10.虚拟主机
- 11.nginx高可用
-
1.简介
1.1 正向代理
如:
1.2 反向代理
分布式路由、负载均衡、动静分离、数据缓存
1.3 特点
1)高并发
一个nginx不做任何配置的情况下,可以处理1000个并发请求;
硬件允许的情况下,可以处理5-10万个并发请求;
而tomcat默认的并发量为150;
2)低消耗
1000个非活跃链接仅消耗2.5M内存;
可防一般的Dos攻击(短时间恶意发送大量请求到服务器,导致被攻击者资源耗尽,无法正常提供服务);
Nginx采用分阶段资源分配技术,使得它的CPU和内存消耗非常低;
Nginx采用异步非阻塞的方式处理请求,可以同时处理上万的请求;
3)热部署
nginx -s reload
4)高可用
一个master线程,多个worker线程
5)高扩展
C语言/LUA脚本语言扩展模块
1.4 其他
1)session粘滞
nginx+tomcat+redis实现session共享
为什么要持久化session(共享session)呢?因为在客户端每个用户的Session对象存在Servlet容器中,如果Tomcat服务器重启或者宕机的话,那么该session就会丢失,而客户端的操作会由于session丢失而造成数据丢失;如果当前用户访问量巨大,每个用户的Session里存放大量数据的话,那么就很占用服务器大量的内存,进而致使服务器性能受到影响。数据库持久化session,分为物理数据库和内存数据库。
2)失效转移
Nginx 负载均衡技术默认情况下已经对于 connect refused(状态码表现为 502)和 time out(状态码表现为 504)做了失效转移,使用的是 upstream 模块的 proxy_next_upstream 指令(这个选项默认是启动的)来实现。
对于 http GET 请求,当这个请求转发到上游服务器发生断路,或者读取响应超时则会将同样的请求转发到其他上游服务器来处理,如果所有服务器都超时或者断路,则会返回 502 或者 504 错误。
对于http POST 请求,当这个请求转发到上游服务器发生断路,则会将请求转发到其他上游服务器来处理,但是如果这个请求发生了读取超时,则不会做失效转移,会返回 504 错误,Nginx 之所以这么做应该是为了防止同一个请求发送两次,比如涉及到银行的充值等操作就会发生很严重的 bug。
2.安装
https://www.cnblogs.com/panxianhao/p/14659444.html
3.性能调优
3.1 zero copy
一个储存空间到另一个储存空间的copy没有cpu参与,由DMA实现
1)传统copy
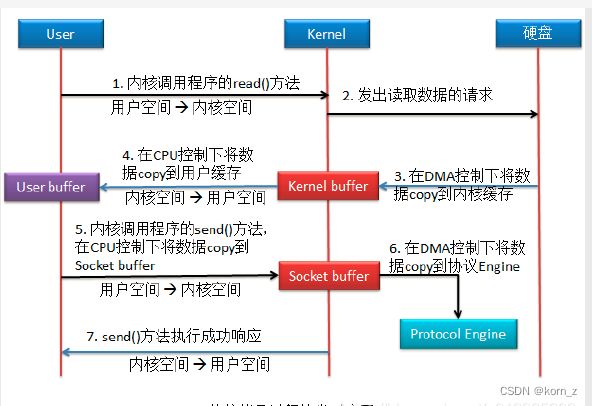
该拷贝方式共进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝,其中
两次拷贝存在 CPU 参与。
我们发现一个很明显的问题:应用程序的作用仅仅就是一个数据传输的中介,最后将
kernel buffer 中的数据传递到了 socket buffer。显然这是没有必要的。所以就引入了零拷贝。
2)zero copy
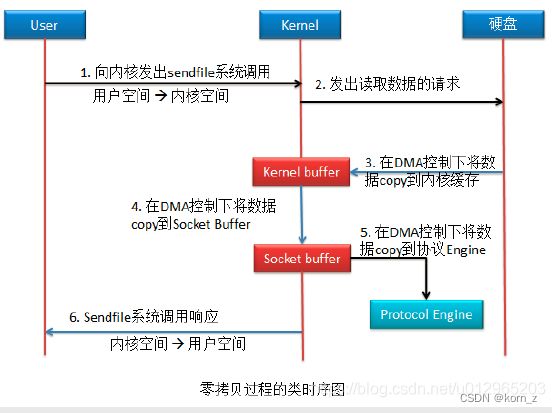
该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 3 次数据拷贝,但整
个拷贝过程均没有 CPU 的参与,这就是零拷贝。
3)gather copy DMA

该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝,并且
整个拷贝过程均没有 CPU 的参与。
该拷贝方式的系统效率是高了,但与传统相比,也存在有不足。传统拷贝中 user buffer
中存有数据,因此应用程序能够对数据进行修改等操作;零拷贝中的 user buffer 中没有了数
据,所以应用程序无法对数据进行操作了。Linux 的 mmap 零拷贝解决了这个问题
4)mmap copy
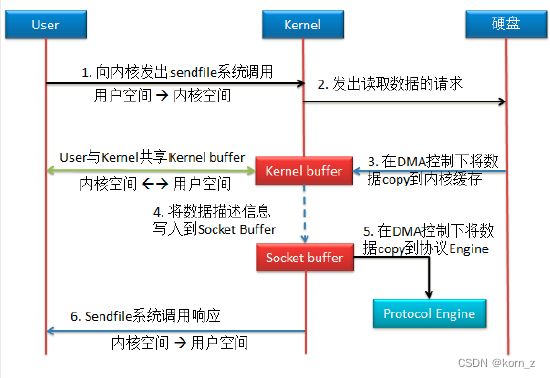
该方式与零拷贝的唯一区别是,应用程序与内核共享了 Kernel buffer。由于是共享,所
以应用程序也就可以操作该 buffer 了。当然,应用程序对于 Kernel buffer 的操作,就会引发
用户空间与内核空间的相互切换
3.2 多路复用器
什么是多路复用?
在该模型下,应用程序进程应该执行哪个内核进程事务呢?谁的准备
就绪了,app 进程就执行哪个。但 app 进程怎么知道哪个内核进程就绪了呢?需要通过“多
路复用器”来获取各个内核进程的状态信息
多路复用器:
不同的多路复用器,其算法不同。
常见的有三种:select、poll 与 epoll
select:
该多路复用器的缺陷有以下几点:
对所有内核进程采用轮询方式效率会很低。因为对于大多数情况下,内核进程都不属于
就绪状态,只有少部分才会是就绪态。所以这种轮询结果大多数都是无意义的。
由于就绪队列底层由数组实现,所以其所能处理的内核进程数量是有限制的,即其能够
处理的最大并发连接数量是有限制的。
从内核空间到用户空间的复制,系统开销大。
poll :
poll 多路复用器的工作原理与 select 几乎相同,不同的是,由于其就绪队列由链表实现,
所以,其对于要处理的内核进程数量理论上是没有限制的,即其能够处理的最大并发连接数
量是没有限制的(当然,要受限于当前系统中进程可以打开的最大文件描述符数 ulimit)
epoll:
epoll 多路复用是对 select 与 poll 的增强与改进。其不再采用轮询方式了,而是采用回
调方式实现对内核进程状态的获取:一旦内核进程就绪,其就会回调 epoll 多路复用器,进
入到多路复用器的就绪队列(由链表实现)。所以 epoll 多路复用模型也称为 epoll 事件驱动
模型,且,应用程序所使用的数据,也不再从内核空间复制到用户空间了,而是使用 mmap
零拷贝机制,大大降低了系统开销
3.3 nginx并发处理机制
一般情况下并发处理机制有三种:多进程、多线程,与异步机制。Nginx 对于并发的处
理同时采用了三种机制。当然,其异步机制使用的是异步非阻塞方式。
Nginx 的进程分为两类:master 进程与 worker 进程。每个 master 进程可以生
成多个 worker 进程,所以其是多进程的。每个 worker 进程可以同时处理多个用户请求,每
个用户请求会由一个线程来处理,所以其是多线程的。
worker 进程采用的就是 epoll 多路复用机制来对后端服务器进行处理的。当后端服务器
返回结果后,后端服务器就会回调 epoll 多路复用器,由多路复用器对相应的 worker 进程进
行通知。此时,worker 进程就会挂起当前正在处理的事务,拿 IO 返回结果去响应客户端请
求。响应完毕后,会再继续执行挂起的事务。这个过程就是“异步非阻塞”的
3.4 全局模块下调优
1.worker_processes
worker_processes,工作进程,用于指定 Nginx 的工作进程数量。其数值一般设置为 CPU
内核数量,或内核数量的整数倍。
不过需要注意,该值不仅仅取决于 CPU 内核数量,还与硬盘数量及负载均衡模式相关。
在不确定时可以指定其值为 auto
2.worker_cpu_affinity 01 10
将 worker 进程与具体的内核进行绑定。不过,若指定 worker_processes 的值为 auto,
则无法设置 worker_cpu_affinity。
3.worker_rlimit_nofile 65535
用于设置一个 worker 进程所能打开的最多文件数量。其默认值与当前 Linux 系统可以打
开的最大文件描述符数量相同
3.5 event模块下的调优
1.worker_connections 1024
设置每一个 worker 进程可以并发处理的最大连接数。该值不能超过 worker_rlimit_nofile
的值
2.accept_mutex on
on:默认值,表示当一个新连接到达时,那些没有处于工作状态的 worker 将以串行方
式来处理;
off:表示当一个新连接到达时,所有的 worker 都会被唤醒,不过只有一个 worker 能获
取新连接,其它的 worker 会重新进入阻塞状态,这就是“惊群”现象
3.accept_mutex_delay 500ms
设置队首 worker 会尝试获取互斥锁的时间间隔。默认值为 500 毫秒
4.multi_accept on
off:系统会逐个拿出新连接按照负载均衡策略,将其分配给当前处理连接个数最少的
worker。
on:系统会实时的统计出各个 worker 当前正在处理的连接个数,然后会按照“缺编”
最多的 worker 的“缺编”数量,一次性将这么多的新连接分配给该 worker。
5.use epoll
设置worker与客户端连接的处理方式。Nginx会自动选择适合当前系统的最高效的方式。
当然,也可以使用 use 指令明确指定所要使用的连接处理方式。user 的取值有以下几种:
select | poll | epoll | rtsig | kqueue | /dev/poll
3.6 http模块下的调优
1.非调优属性讲解
1)include mime.types 将当前目录(conf 目录)中的 mime.types 文件包含进来;
2)default_type application/octet-stream 对于无扩展名的文件,默认其为 application/octet-stream 类型,即 Nginx 会将其作为一
个八进制流文件来处理;
3)charset utf-8 设置请求与响应的字符编码
2.sendfile on
设置为 on 则开启 Linux 系统的零拷贝机制,否则不启用零拷贝。当然,开启后是否起
作用,要看所使用的系统版本。CentOS6 及其以上版本支持 sendfile 零拷贝
3.tcp_nopush on
on:以单独的数据包形式发送 Nginx 的响应头信息,而真正的响应体数据会再以数据包
的形式发送,这个数据包中就不再包含响应头信息了。
off:默认值,响应头信息包含在每一个响应体数据包中
4.tcp_nodelay on
on:不设置数据发送缓存,即不推迟发送,适合于传输小数据,无需缓存。
off:开启发送缓存。若传输的数据是图片等大数据量文件,则建议设置为 off。
5.keepalive_timeout 60
设置客户端与Nginx间所建立的长连接的生命超时时间,时间到达,则连接将自动关闭。
单位秒。
6.keepalive_requests 10000
设置一个长连接最多可以发送的请求数
7.client_body_timeout 10
设置客户端获取 Nginx 响应的超时时限,即一个请求从客户端发出到接收到 Nginx 的响
应的最长时间间隔。若超时,则认为本次请求失败。
4.请求定位
4.1资源访问
必须要在 root 属性指定的目录下存在 location 指定的 URI 路径目录
4.2路径匹配优先级
优先级规则
普通匹配 < 长路径匹配 < 正则匹配 < 短路匹配 < 精确匹配
当一个请求路径既可以与一个长路径相匹配,又可以与一个短路径相匹配时,长路径优
先级高
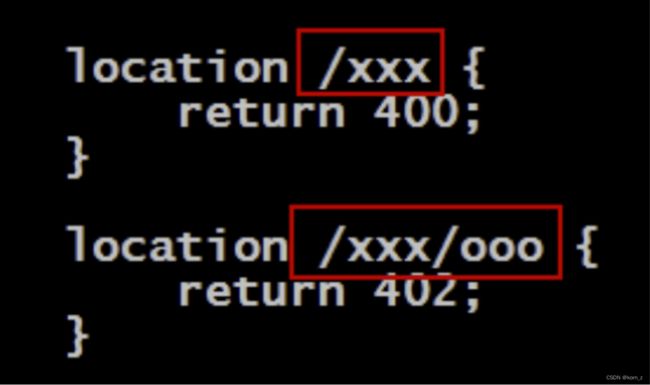
正则匹配
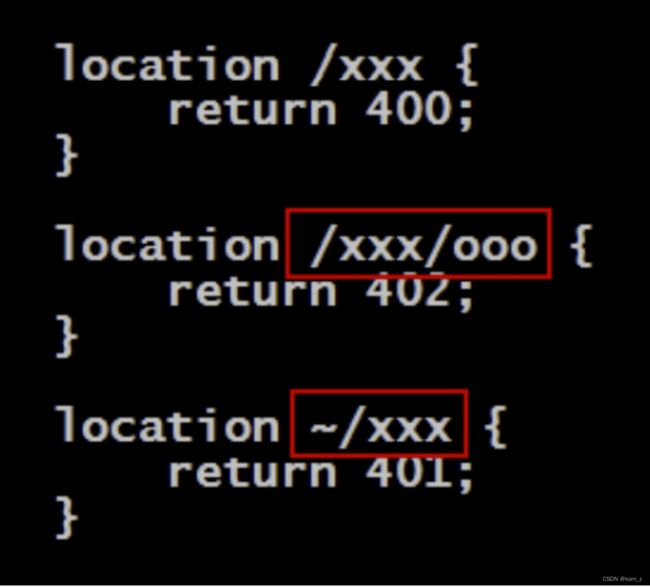
~表示这里是正则表达式,默认匹配是区分大小写的
~后跟上*号,表示这是不区分大小写的正则表达式
短路匹配
以^~开头的匹配路径称为短路匹配,表示只要匹配上,就不再匹配其它的了,即使是正
则匹配也不再匹配了。即其优先级要高于正则匹配的
精确匹配
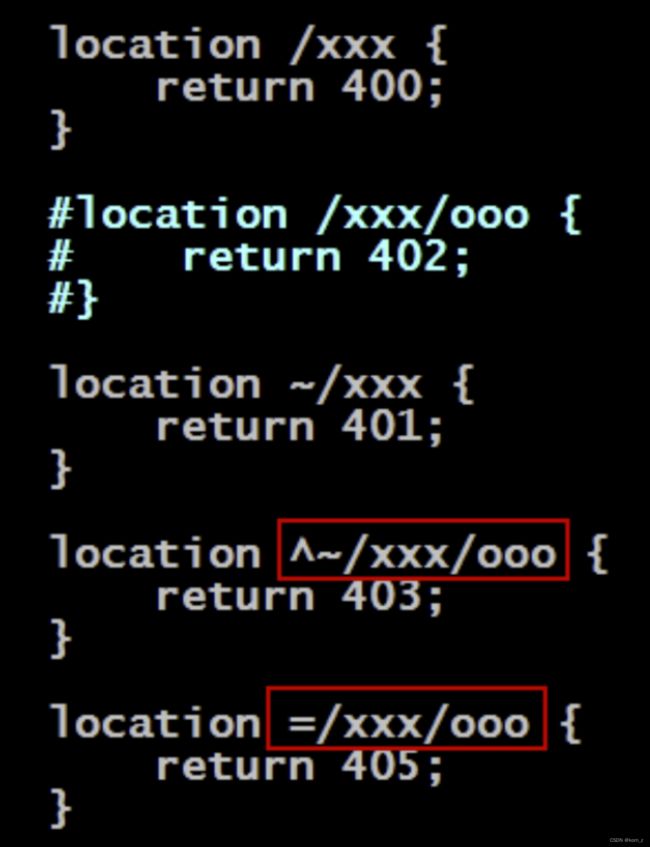
以等号(=)开头的匹配称为精确匹配,其是优先级最高的匹配
4.3 缓存配置
Nginx具有很强大的缓存功能,可以对请求的response进行缓存,起到类似CDN的作用,甚至有比 CDN 更强大的功能。同时,Nginx 缓存还可以用来“数据托底”,即当后台 web 服务器挂掉的时候,Nginx 可以直接将缓存中的托底数据返回给用户。此功能就是 Nginx 实现“服务降级”的体现。
Nginx 缓存功能的配置由两部分构成:全局定义与局部定义。在 http{}模块的全局部分中进行缓存全局定义,在 server{}模块的各个 location{}模块中根据业务需求进行缓存局部定义。
1)http{}模块的缓存全局定义
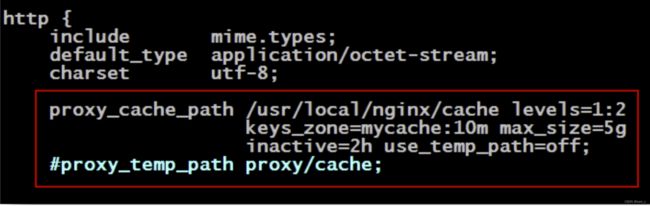
proxy_cache_path:用于指定 Nginx 缓存的存放路径及相关配置。
proxy_temp_path:指定 Nginx 缓存的临时存放目录。若 proxy_cache_path 中的 use_temp_path 设置为了 off,
则该属性可以不指定
2)location{}模块的缓存局部定义
proxy_cache mycache: 指定用于存放缓存 key 内存区域名称。其值为 http{}模块中proxy_cache_path 中的keys_zone 的值
expires 3m: 为请求的静态资源开启浏览器端的缓存
3) nginx 变量
$args 请求中的参数;
$binary_remote_addr 远程地址的二进制表示
$body_bytes_sent 已发送的消息体字节数
$content_length HTTP 请求信息里的"Content-Length"
$content_type 请求信息里的"Content-Type"
$document_root 针对当前请求的根路径设置值
$document_uri 与$uri 相同
$host 请求信息中的"Host",如果请求中没有 Host 行,则等于设置
的服务器名;
$http_cookie cookie 信息
$http_referer 来源地址
$http_user_agent 客户端代理信息
$http_via 最后一个访问服务器的 Ip 地址
$http_x_forwarded_for 相当于网络访问路径。
$limit_rate 对连接速率的限制
$remote_addr 客户端地址
$remote_port 客户端端口号
$remote_user 客户端用户名,认证用
$request 用户请求信息
$request_body 用户请求主体
$request_body_file 发往后端的本地文件名称
$request_filename 当前请求的文件路径名
$request_method 请求的方法,比如"GET"、"POST"等
$request_uri 请求的 URI,带参数
$server_addr 服务器地址,如果没有用 listen 指明服务器地址,使用这个变
量将发起一次系统调用以取得地址(造成资源浪费)
$server_name 请求到达的服务器名
$server_port 请求到达的服务器端口号
$server_protocol 请求的协议版本,"HTTP/1.0"或"HTTP/1.1"
$uri 请求的 URI,可能和最初的值有不同,比如经过重定向之类的
5.日志管理
日志管理范围
这些日志相关属性可以配置在任意模块。在不同的模块,记录的是不同请求的日志信息。即,日志记录的请求范围是不同的。Nginx 日志一般可以指定三个范围:
http{}模块范围、server{}模块范围,与 location{}模块范围
1)http{}模块范围

只要有请求通过 http 协议访问该 Nginx,就会有日志信息写入到这里的日志文件
2)server{}模块范围

只要有请求访问当前 Server,就会有日志信息写入到这里的日志文件
3)location{}模拟范围

只要有请求访问当前 location,就会有日志信息写入到这里的日志文件
6.静态代理
6.1扩展名拦截

6.2目录名拦截
6.3 页面压缩
浏览器中最常见的压缩算法有:
deflate:是一种过时的压缩算法,是 huffman 编码的一种加强。
gzip:是目前大多数浏览器都支持的一种压缩算法,是对 deflate 的改进。
sdch:谷歌开发的一种压缩算法,一种全新的压缩思路。deflate 与 gzip 的的压缩思想是,
修改传输数据的编码格式以达到减少体量的目的,其最终传输的数据并没有减少。而
sdch 压缩算法的思想是,让冗余的数据仅出现一次,其最终传输的数据减少了。
Zopfli:谷歌开发的一种压缩算法,Deflate 压缩算法的改进。比标准的gzip -9要小 3%-8%,
但压缩用时是 gzip -9 的 80 多倍。
br:即 Brotli,谷歌开发的一种压缩算法,是一种全新的数据格式。与 Zopfli 相比,压
缩率能够降低 20%-26%。Brotli -1 有着与 Gzip -9 相近的压缩比和更快的压缩解压速度。
Nginx压缩功能详解:
https://blog.csdn.net/dichengyan0013/article/details/102347230
7.反向代理
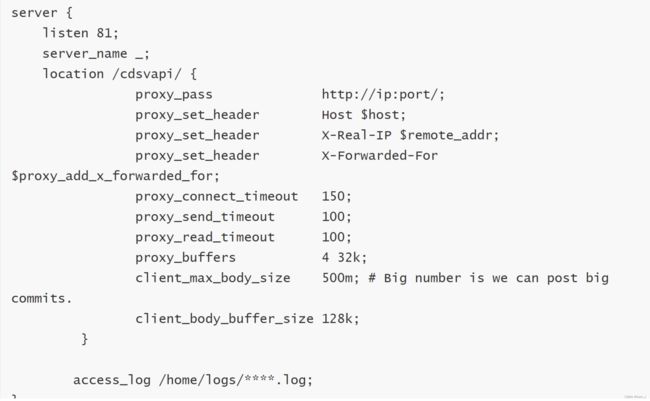
通过在 location{}中添加通行代理 proxy_pass可以指定当前Nginx 所要代理的真正服务器
8.负载均衡
- 轮询(默认)
默认的负载均衡策略,其是按照各个主机的权重比例依次进行请求分配的

backup:表示当前服务器为备用服务器。
down:表示当前服务器永久停机。
fail_ timeout:表示当前主机被 Nginx 认定为停机的最长失联时间,默认为 10 秒。常与
max_fails 联合使用。
max_fails:表示在 fail_timeout 时间内最多允许的失败次数
- ip_hash
指定负载均衡器按照基于客户端 IP 的分配方式
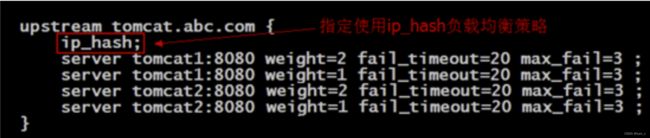
在 nginx1.3.1 版本之前,该策略中不能指定 weight 属性。
该策略不能与 backup 同时使用。
此策略适合有状态服务,比如 session。
当有服务器宕机,必须手动指定 down 属性,否则请求仍是会落到该服务器。
- least_conn
把请求转发给连接数最少的服务器

把请求转发给连接数最少的服务器
9.动静分离
动静分离是将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问
动静分离的一种常用做法:将静态资源部署在nginx上,后台项目部署到应用服务器上,根据一定规则静态资源的请求调度到nginx服务器,达到动静分离的目标
10.虚拟主机
1)基于域名
不同的域名 相同的IP

2)基于IP
不使用域名、IP来区分不同站点的内容,而是用不同的TCP端口号
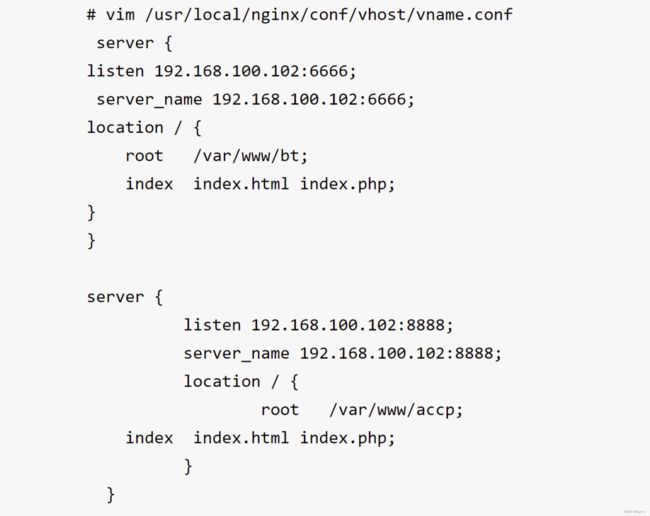
11.nginx高可用
vip
keepalived+主备