Spark的转换算子和操作算子
1 Transformation转换算子
1.1 Value类型
1)创建包名:com.shangjack.value
1.1.1 map()映射
参数f是一个函数可以写作匿名子类,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函数,从而产生一个新的RDD。即,这个新RDD中的每一个元素都是原来RDD中每一个元素依次应用f函数而得到的。
1)具体实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class Test01_Map {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 需求:每行结尾拼接||
// 两种写法 lambda表达式写法(匿名函数)
JavaRDD
// 匿名函数写法
JavaRDD
@Override
public String call(String v1) throws Exception {
return v1 + "||";
}
});
for (String s : mapRDD.collect()) {
System.out.println(s);
}
// 输出数据的函数写法
mapRDD1.collect().forEach(a -> System.out.println(a));
mapRDD1.collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.2 flatMap()扁平化
1)功能说明
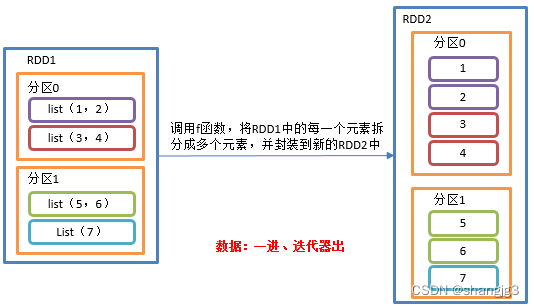
与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。
2)需求说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。
4)具体实现:
package com.shangjack.value;
import org.apache.commons.collections.ListUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class Test02_FlatMap {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
ArrayList
arrayLists.add(Arrays.asList("1","2","3"));
arrayLists.add(Arrays.asList("4","5","6"));
JavaRDD
// 对于集合嵌套的RDD 可以将元素打散
// 泛型为打散之后的元素类型
JavaRDD
@Override
public Iterator
return strings.iterator();
}
});
stringJavaRDD. collect().forEach(System.out::println);
// 通常情况下需要自己将元素转换为集合
JavaRDD
JavaRDD
@Override
public Iterator
String[] s1 = s.split(" ");
return Arrays.asList(s1).iterator();
}
});
stringJavaRDD1. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.3 groupBy()分组
1)功能说明:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
2)需求说明:创建一个RDD,按照元素模以2的值进行分组。
3)具体实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test03_GroupBy {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 泛型为分组标记的类型
JavaPairRDD
@Override
public Integer call(Integer v1) throws Exception {
return v1 % 2;
}
});
groupByRDD.collect().forEach(System.out::println);
// 类型可以任意修改
JavaPairRDD
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
groupByRDD1. collect().forEach(System.out::println);
Thread.sleep(600000);
// 4. 关闭sc
sc.stop();
}
}
- groupBy会存在shuffle过程
- shuffle:将不同的分区数据进行打乱重组的过程
- shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
1.1.4 filter()过滤
1)功能说明
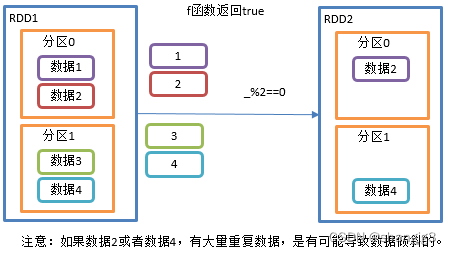
接收一个返回值为布尔类型的函数作为参数。当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。
2)需求说明:创建一个RDD,过滤出对2取余等于0的数据
3)代码实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test04_Filter {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
JavaRDD
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
filterRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.1.5 distinct()去重
1)功能说明:对内部的元素去重,并将去重后的元素放到新的RDD中。
2)代码实现
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test05_Distinct {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 底层使用分布式分组去重 所有速度比较慢,但是不会OOM
JavaRDD
distinct. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
注意:distinct会存在shuffle过程。
1.1.6 sortBy()排序
1)功能说明
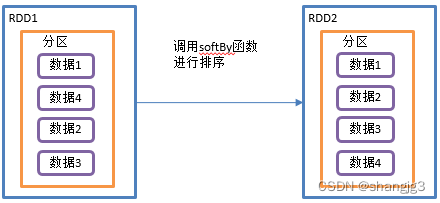
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。Spark的排序结果是全局有序。
2)需求说明:创建一个RDD,按照数字大小分别实现正序和倒序排序
3)代码实现:
package com.shangjack.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
public class Test6_SortBy {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// (1)泛型为以谁作为标准排序 (2) true为正序 (3) 排序之后的分区个数
JavaRDD
@Override
public Integer call(Integer v1) throws Exception {
return v1;
}
}, true, 2);
sortByRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2 Key-Value类型
1)创建包名:com.shangjack.keyvalue
要想使用Key-Value类型的算子首先需要使用特定的方法转换为PairRDD
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test01_pairRDD{
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(integer, integer);
}
});
pairRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.1 mapValues()只对V进行操作
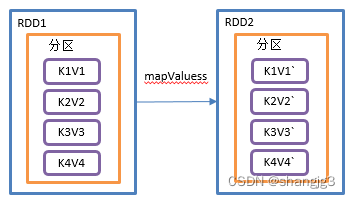
1)功能说明:针对于(K,V)形式的类型只对V进行操作
2)需求说明:创建一个pairRDD,并将value添加字符串"|||"
4)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import scala.Tuple2;
import java.util.Arrays;
public class Test02_MapValues {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD
// 只修改value 不修改key
JavaPairRDD
@Override
public String call(String v1) throws Exception {
return v1 + "|||";
}
});
mapValuesRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
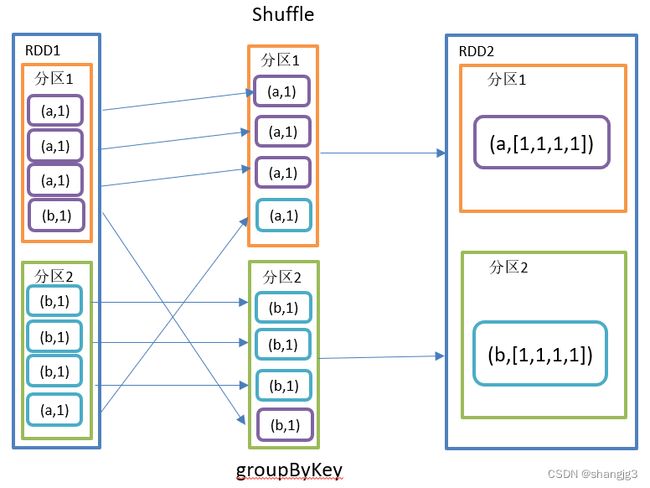
1.2.2 groupByKey()按照K重新分组
1)功能说明
groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合。
该操作可以指定分区器或者分区数(默认使用HashPartitioner)
2)需求说明:统计单词出现次数
4)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test03_GroupByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 统计单词出现次数
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(s, 1);
}
});
// 聚合相同的key
JavaPairRDD
// 合并值
JavaPairRDD
@Override
public Integer call(Iterable
Integer sum = 0;
for (Integer integer : v1) {
sum += integer;
}
return sum;
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}}
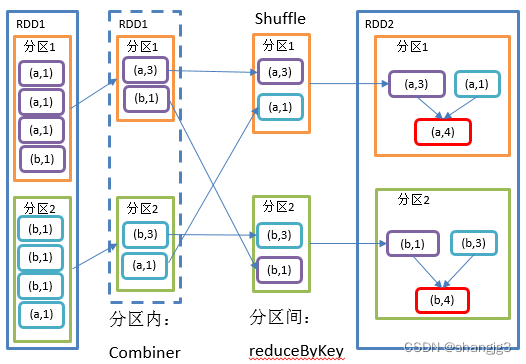
1.2.3 reduceByKey()按照K聚合V
1)功能说明:该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。其存在多种重载形式,还可以设置新RDD的分区数。
2)需求说明:统计单词出现次数
3)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test04_ReduceByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 统计单词出现次数
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(s, 1);
}
});
// 聚合相同的key
JavaPairRDD
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
1.2.4 reduceByKey和groupByKey区别
1)reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
2)groupByKey:按照key进行分组,直接进行shuffle。
3)开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。影响业务逻辑时建议先对数据类型进行转换再合并。
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Test06_ReduceByKeyAvg {
public static void main(String[] args) throws InterruptedException {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD
// ("hi",(96,1))
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(v1, 1);
}
});
// 聚合RDD
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(v1._1 + v2._1, v1._2 + v2._2);
}
});
// 相除
JavaPairRDD
@Override
public Double call(Tuple2
return (new Double(v1._1) / v1._2);
}
});
result. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
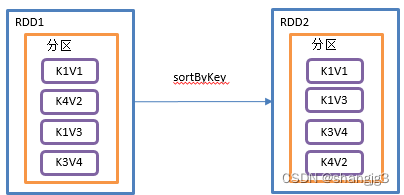
1.2.5 sortByKey()按照K进行排序
1)功能说明
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD。
2)需求说明:创建一个pairRDD,按照key的正序和倒序进行排序
3)代码实现:
package com.shangjack.keyValue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class Test05_SortByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD
// 填写布尔类型选择正序倒序
JavaPairRDD
pairRDD. collect().forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
2 Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
1)创建包名:com.shangjack.action
2.1 collect()以数组的形式返回数据集
1)功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素。
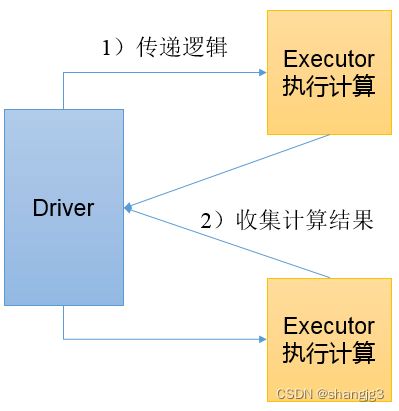
注意:所有的数据都会被拉取到Driver端,慎用。
2)需求说明:创建一个RDD,并将RDD内容收集到Driver端打印
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class Test01_Collect {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
List
for (Integer integer : collect) {
System.out.println(integer);
}
// 4. 关闭sc
sc.stop();
}
}
2.2 count()返回RDD中元素个数
1)功能说明:返回RDD中元素的个数
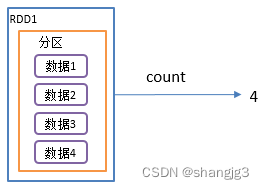
3)需求说明:创建一个RDD,统计该RDD的条数
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test02_Count {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
long count = integerJavaRDD.count();
System.out.println(count);
// 4. 关闭sc
sc.stop();
}
}
2.3 first()返回RDD中的第一个元素
1)功能说明:返回RDD中的第一个元素
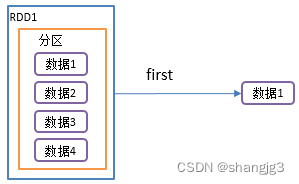
2)需求说明:创建一个RDD,返回该RDD中的第一个元素
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class Test03_First {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
Integer first = integerJavaRDD.first();
System.out.println(first);
// 4. 关闭sc
sc.stop();
}
}
2.4 take()返回由RDD前n个元素组成的数组
1)功能说明:返回一个由RDD的前n个元素组成的数组
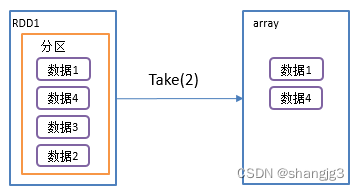
2)需求说明:创建一个RDD,取出前两个元素
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class Test04_Take {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
List
list.forEach(System.out::println);
// 4. 关闭sc
sc.stop();
}
}
2.5 countByKey()统计每种key的个数
1)功能说明:统计每种key的个数
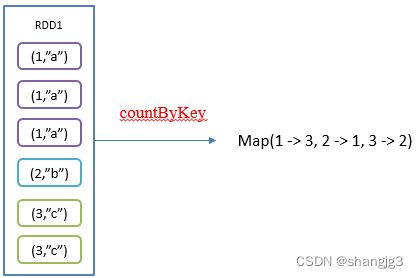
2)需求说明:创建一个PairRDD,统计每种key的个数
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Map;
public class Test05_CountByKey {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaPairRDD
Map
System.out.println(map);
// 4. 关闭sc
sc.stop();
}
}
2.6 save相关算子
1)saveAsTextFile(path)保存成Text文件
功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
2)saveAsObjectFile(path) 序列化成对象保存到文件
功能说明:用于将RDD中的元素序列化成对象,存储到文件中。
3)代码实现
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class Test06_Save {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
integerJavaRDD.saveAsTextFile("output");
integerJavaRDD.saveAsObjectFile("output1");
// 4. 关闭sc
sc.stop();
}
}
2.7 foreach()遍历RDD中每一个元素
2)需求说明:创建一个RDD,对每个元素进行打印
package com.shangjack.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
public class Test07_Foreach {
public static void main(String[] args) {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
integerJavaRDD.foreach(new VoidFunction
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
});
// 4. 关闭sc
sc.stop();
}
}
2.8 foreachPartition ()遍历RDD中每一个分区
package com.shangjack.spark.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
import java.util.Iterator;
public class Test08_ForeachPartition {
public static void main(String[] args) {
// 1. 创建配置对象
SparkConf conf = new SparkConf().setAppName("core").setMaster("local[*]");
// 2. 创建sc环境
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
JavaRDD
// 多线程一起计算 分区间无序 单个分区有序
parallelize.foreachPartition(new VoidFunction
@Override
public void call(Iterator
// 一次处理一个分区的数据
while (integerIterator.hasNext()) {
Integer next = integerIterator.next();
System.out.println(next);
}
}
});
// 4. 关闭sc
sc.stop();
}
}