20个主流的代码生成LLM大模型及9种常见应用场景
基于生成式AI的代码生成(Code Generation)是一个重要的新领域,用于根据不完整的数据源、用另一种编程语言编写的程序、自然语言描述或执行日志来预测代码或程序结构。
多年来,开发人员经常从博客、帖子、文章和其他网站获取代码,并根据自己的上下文进行调整。 如今,现在可以要求机器使用一些提示来为你生成它,并且性能如此之高,以至于不再需要从这些站点获取此源代码。 现在的问题是是否有可能不真正考虑使用此类技术来加快开发阶段。
在正常使用中,我们使用大型语言模型(LLM)的能力来生成句子的下一个标记。 LLM 估计下一个单元(文本、句子、标记、符号)的概率,系统按照所选策略(温度、前 K 个最有可能的标记或概率的前 p% 等)获取一个标记。 )在代码生成的情况下,我们不仅将这种功能用于文本,而且还用于代码。 值得注意的是,在代码生成方面,为了获得更具确定性的结果(0.2 到 0.8),低温优于高温。 如果要生成多个样品,则优选较高的温度。
如果想详细了解文本生成的工作原理,请参阅我关于生成式AI的文章。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、代码生成器模型简介
自动完成或代码生成功能已在开发工具中存在多年。 早在 1996 年,微软就在 Visual Studio 中为 Visual Basic 引入了这一功能(IntelliSense)。 熟悉 Eclipse 的人可能使用过 Java getter 和 setter 生成函数,以及变量名的字符串导出函数(著名的“public String toString()”函数)。 提供下一行代码仍然是这些 IDE 工具的一个重要功能,通常通过同时按下 Control 和空格键来激活。 在可见性范围内,这种语法导向的编辑仍然可以帮助你完成类、方法、字段、注释和关键字的名称,只需按一下键盘,有时只需单击一下。
不得不说,源代码生成功能并不是LLM的主要目的,因为他们接受的培训主要是从所摄取的大量网页和书籍中生成文本。 结果,GPT-1和GPT-2都没有直接接收到任何与代码相关的数据。 当这一功能在LLM中使用并提供给尽可能广泛的受众时,革命就开始了。 从那时起,我们看到专门针对此特定用例训练的模型数量呈爆炸式增长,并且多代码模型可能提供更好的泛化性,因为不同的编程语言共享相似的关键字和属性。
2021 年 6 月 29 日,GitHub 宣布 GitHub Copilot(“你的 AI 配对程序员”)可在由 OpenAI Codex(GPT-3 的修改版本)支持的 Visual Studio Code 开发环境中进行技术预览。 Copilot 使用的 OpenAI Codex 经过精选的英语数据集、公共 GitHub 存储库和其他可公开访问的源代码的训练。
以下是代码生成器模型的非详尽列表:
-
2020 年,微软发布了 CodeBERT,这是一种针对编程语言的预训练模型 (124M),这是一种在 NL-PL 对上以六种编程语言(Python、Java、JavaScript、PHP、Ruby 和 去)。
-
CuBERT,345M(2020 年 8 月)是一个开源代码理解 BERT 模型。 他们通过在源代码上训练 BERT 模型来获得上下文嵌入。 他们称之为 CuBERT,是代码理解 BERT 的缩写。 该模型主要用于使用代码嵌入来查找代码缺陷和重复块。
PLBART 406M 是一种类似 BART 的模型,可用于执行代码汇总、代码生成和代码翻译任务。 -
CodeParrot 是仅在 180GB Python 代码上训练的 GPT-2 模型,有两种大小:110M 和 1.5B。
-
CodeT5,220M(2021 年 9 月)来自 Salesforce。 该模型具有编码器-解码器架构,可以灵活地在不同模式下运行(即仅编码器、仅解码器和编码器-解码器)。 支持四种生成任务:代码摘要、代码生成、翻译、细化; 以及两个理解任务:代码缺陷和克隆检测。 训练数据包含来自CodeSearchNet数据的六种编程语言:Python、Java、JavaScript、PHP、Ruby、Go; 以及来自 Google BigQuery 数据的另外两种编程语言:C 和 C#。
-
GPT-Neo 由 EleutherAI 于 2021 年生产,提供三种尺寸:125M、1.3B 和 2.7B。 它是一个类似GPT-3的模型和LLM模型,用于生成文本,但它们也可以生成源代码。 GPT-J-6B 经过自然语言和多种编程语言 (12) 代码的混合训练,并且仅提供一种大小:6B。 GPT-NeoX-20B 与 GPT-J-6B 几乎相同。
-
PolyCoder(2021 年 8 月 10 日)来自 CMU,是基于 GPT-2 架构的LLM。 它使用 GPT NeoX 工具包对 12 种编程语言(C、C++、Java、JavaScript、C#、Python 等)的 249GB 代码进行了训练,并提供三种大小:160M、0.4B 和 2.7B。
2022 年 3 月,Salesforce 发布了另一个名为 CodeGen(350M、2.7B、6.1B 和 16.1B)的代码 LLM,这是一种多步程序合成方法,其中通过多轮规范和代码生成来实现程序合成。 -
2023 年 5 月,Salesforce 发布了 CodeT5 的增强版本,称为 CodeT5+(220M、770M、2B、6B 和 16B),具有有趣的检索增强代码生成功能。 通过利用编码器最初获取相关代码片段,模型随后可以将这些片段作为输入的一部分合并到解码器中,从而提高模型生成的代码的质量。
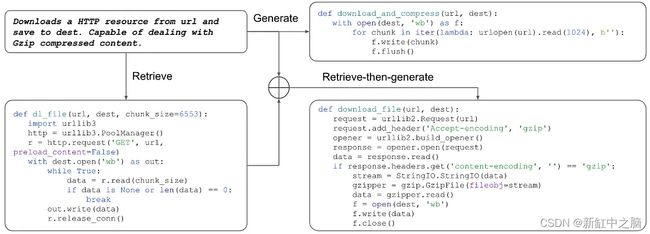
-
Facebook 的 InCoder 1.3B 和 6B 模型(2023 年 4 月)经过训练,可以在双向上下文中生成代码。 这些生成模型能够直接执行无缝代码完成,例如类型推断、注释生成和变量重命名。
-
Codex 是 OpenAI 仅通过 API 提供的模型,是 GPT-3 的后代。 有300M、2.5B、12B三种尺寸可供选择。 GitHub Copilot 背后的驱动力是 Codex,这是一个以其性能而闻名的强大模型。 虽然 OpenAI Codex 在 Python 方面表现出色,但它也表现出对其他各种语言的熟练程度,包括 JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript 甚至 Shell。 与其他模型不同,该模型不可公开下载,因此无法进行研究。 所有者成功地将其用于转译、代码解释和代码重构。
-
2022 年 2 月,DeepMind 宣布推出 AlphaCode,与 Codex 一样,它也采用基于 Transformer 的模型。 它接受了超过 715 GB 的 GitHub 数据以及 Codeforce 问题和解决方案的训练,包括 C++、C#、Go、Java、JavaScript、Lua、PHP、Python、Ruby、Rust、Scala 和 TypeScript 程序。
-
Amazon CodeWhisperer(2022 年 6 月)是一个用于代码生成、参考跟踪和安全扫描的内部模型。 除了 Python、Java 和 JavaScript 之外,它还支持 TypeScript 和 C# 编程语言,并且可以为基于 Lambda、Amazon S3 和弹性计算 (EC2) 服务的编程应用程序提供建议。
-
Replit 3B 由 Replit 提供,是一个专注于代码完成的 2.7B 因果语言模型。 训练混合物包括 20 种不同的语言:Markdown、Java、JavaScript、Python、TypeScript、PHP、SQL、JSX、reStructuredText、Rust、C、CSS、Go、C++、HTML、Vue、Ruby、Jupyter Notebook、R 和 Shell。
-
Google 的 Codey 基于 Google PaLM 2 大语言模型构建,经过专门训练,可以处理与 Google Cloud 相关的编码相关提示和查询。 PaLM 2 的基础源于对可公开访问的源代码的广泛数据集的预训练。 Codey 对 Python 和 JavaScript 等广泛使用的编程语言表现出卓越的熟练程度。 此外,它还能够用 Prolog、Fortran 和 Verilog 等语言生成专用代码。
-
StarCoder 由 HuggingFace 和 ServiceNow 合作发布,来自 BigCode 项目(开放科学合作),是一个经过训练可编写 80 多种编程语言的 15.5B 模型。 StarCoder 的 LLM 使用多查询注意力技术来理解代码内容并生成准确的建议。 该技术包括同时分析多个请求以提供相关答案。
-
GPT4是OpenAI最后一个模型,至少有700B左右的参数(作者猜测)。 OpenAI 的 Code-davinci-02(和 code-cushman-02)现已被 GPT4 取代,但微软仍在其认知服务中使用它。
-
THUDM 的 CodeGeeX 是一种高容量的多语言代码生成模型,拥有令人印象深刻的 13B 参数。 它已经在包含 20 多种编程语言的庞大代码库上进行了预训练。 它处理多种主流编程语言,包括Python、C++、Java、JavaScript、Go等。
IBM Watson Code Assistant(2023 年 5 月)目前仅生成带有 AI 生成建议的 Red Hat® Ansible® 脚本。 它基于Wisdom模型及其350M参数。
2、代码生成的用例和应用
代码完成是一种上下文相关的代码生成功能,可通过减少拼写错误和其他常见错误来加快应用程序编码过程。
使用 replit-code-v1–3b 的代码完成示例可以在此处复制。 使用 ChatGPT 的其他代码示例可以在此处复制。
2.1 代码完成
代码完成(Code completion)是第一个主要用例,允许你完成代码的开头或在中间注入代码。 代码完成似乎是最明显的用例,但代码LLM可以在增强软件“工艺”的背景下涵盖更多用例。
# >>> Model: replit/replit-code-v1-3b - Temperature = 0.2
# >>> Prompt:
def find_best_rsquared(list_of_fits):
"""Return the best fit, based on rsquared"""
# >>> Result:
return min(list_of_fits, key=lambda x: x.rsquared)
2.2 文本生成代码
文本生成代码(Text to code)是据自然语言描述生成代码。
# >>> Model: replit/replit-code-v1-3b - Temperature = 0.2
# >>> Prompt:
"""
double_sum_to_value takes a list of integers as an input.
It returns True if there are two distinct elements in the list that \\
sum to a value given in input, and False otherwise.
Check if the list has at least two elements.
Find all possible combinations of two distinct elements in the list.
Check if any of the combinations sum up to the given value.
"""
# >>> Result:
def double_sum_to_value(list_of_ints, value):
"""
:param list_of_ints: a list of integers
:param value: a value to check if the list has two distinct elements that sum to
:return: True if there are two distinct elements in the list that sum to a value given in input, and False otherwise
"""
# if the list has less than two elements, return False
if len(list_of_ints) < 2:
return False
# if the list has more than two elements, return True
else:
# iterate over the list
for i in range(len(list_of_ints) - 1):
# iterate over the remaining elements
for j in range(i + 1, len(list_of_ints)):
# if the sum of the two elements is equal to the value, return True
if list_of_ints[i] + list_of_ints[j] == value:
return True
# if the list does not have two distinct elements that sum to the value, return False
return False
def main():
# print the return value of double_sum_to_value
print(double_sum_to_value([1, 2, 3, 4, 5], 8))
if __name__ == '__main__':
main()
2.3 测试生成
手动创建单元测试可能是一项乏味的工作。 因此,一些开发人员根本不想编写测试。 使用提示中要测试的功能自动生成测试用例是解决这种缺乏良好实践的一个很好的替代方案。
# >>> Model: replit/replit-code-v1-3b - Temperature = 0.2
# >>> Prompt:
import unittest
def double_sum_to_value(list_of_ints, value):
"""
:param list_of_ints: a list of integers
:param value: a value to check if the list has two distinct elements that sum to
:return: True if there are two distinct elements in the list that sum to a value given in input, and False otherwise
"""
# if the list has less than two elements, return False
if len(list_of_ints) < 2:
return False
# if the list has more than two elements, return True
else:
# iterate over the list
for i in range(len(list_of_ints) - 1):
# iterate over the remaining elements
for j in range(i + 1, len(list_of_ints)):
# if the sum of the two elements is equal to the value, return True
if list_of_ints[i] + list_of_ints[j] == value:
return True
# if the list does not have two distinct elements that sum to the value, return False
return False
class MyTest(unittest.TestCase):
# >>> Result:
def test_example(self):
self.assertTrue(double_sum_to_value([1, 2, 3, 4, 5], 7))
def test_example_2(self):
self.assertFalse(double_sum_to_value([1, 2, 3, 4, 5], 6))
def test_example_3(self):
self.assertTrue(double_sum_to_value([1, 2, 3, 4, 5, 6], 7))
2.4 重构代码
重构代码(Refactoring code)包括在不改变其功能的情况下更改源代码的结构,通常是为了使其更加高效、可读且易于维护。 此功能仅适用于已按指导方式训练的模型。
# >>> Model: ChatGPT
# >>> Prompt:
You are an expert in development.
Rewrite this code to reduce its complexity.
"""
def double_sum_to_value(list_of_ints, value):
if len(list_of_ints) < 2:
return False
else:
for i in range(len(list_of_ints) - 1):
for j in range(i + 1, len(list_of_ints)):
if list_of_ints[i] + list_of_ints[j] == value:
return True
return False
"""
# >>> Result:
def double_sum_to_value(list_of_ints, value):
if len(list_of_ints) < 2:
return False
seen_values = set()
for num in list_of_ints:
complement = value - num
if complement in seen_values:
return True
seen_values.add(complement)
return False
"""
Explanation:
The initial check for the length of list_of_ints is retained to handle
the case where there are fewer than two integers, as the logic wouldn't
work in that scenario. We use a set, seen_values, to keep track of
the complements needed to reach the target value.
Instead of iterating through all combinations of numbers, we iterate
through each number in list_of_ints only once. For each number, we
calculate the complement needed to reach the target value. If the
complement is in seen_values, we have found a pair that sums up to
the target value, and we return True. If we finish iterating through
the list without finding a pair, we return False.
This approach reduces the complexity from O(n^2) to O(n), as we only need
to iterate through the list once to check for the sum condition.
Additionally, it avoids unnecessary duplicate calculations by storing the
complements in a set.
"""
2.5 代码文档和代码摘要
以自然语言描述生成源代码摘要。 此功能仅适用于已按指导方式训练的模型。
# >>> Model: ChatGPT
# >>> Prompt:
You are an expert in development. Adds an explanation of the code between quotations at the end.
"""
def double_sum_to_value(list_of_ints, value):
if len(list_of_ints) < 2:
return False
else:
for i in range(len(list_of_ints) - 1):
for j in range(i + 1, len(list_of_ints)):
if list_of_ints[i] + list_of_ints[j] == value:
return True
return False
"""
# >>> Result:
"""
The given code defines a function named double_sum_to_value that takes
in two parameters: list_of_ints, which is a list of integers, and value,
which is an integer. The function checks if there are any two distinct
integers in the list whose sum is equal to the given value.
Here's a breakdown of how the code works:
The function begins with an initial check to see if the length of the
list_of_ints is less than 2. If it is, it means there are not enough
integers in the list to form a pair, so the function returns False.
If the length of the list is 2 or greater, the function proceeds to
iterate through the list using two nested loops. The outer loop iterates
over each element in the list except the last one, denoted by the variable i.
The inner loop iterates over the elements following the current element
of the outer loop, denoted by the variable j. This ensures that every
possible pair of distinct integers is considered.
Within the nested loops, the function checks if the sum of the current
pair of integers, list_of_ints[i] and list_of_ints[j], is equal to the
given value. If it is, the function immediately returns True to indicate
that a pair with the desired sum has been found.
If no such pair is found after exhausting all possible combinations, the
function exits the nested loops and returns False to indicate that there
are no distinct integers in the list that sum up to the given value.
The code utilizes a brute-force approach by checking all possible pairs
of integers. While it works correctly, it has a time complexity of O(n^2)
due to the nested loops, where n is the length of the input list. This
means the execution time grows quadratically with the size of the input
list, which can be inefficient for large lists.
"""
2.6 代码重写
开发人员必须定期编写相同的功能,但仅更改某些名称。 生成函数使这些修改变得非常容易。 此功能仅适用于已按指导方式训练的模型。
# >>> Model: ChatGPT
# >>> Prompt:
In the following function, change the input variable 'list_of_ints' to 'list_of_revenues' and 'value'' to 'revenue'.
def double_sum_to_value(list_of_ints, value):
if len(list_of_ints) < 2:
return False
else:
for i in range(len(list_of_ints) - 1):
for j in range(i + 1, len(list_of_ints)):
if list_of_ints[i] + list_of_ints[j] == value:
return True
return False
# >>> Result:
def double_sum_to_value(list_of_revenues, revenue):
if len(list_of_revenues) < 2:
return False
else:
for i in range(len(list_of_revenues) - 1):
for j in range(i + 1, len(list_of_revenues)):
if list_of_revenues[i] + list_of_revenues[j] == revenue:
return True
return False
2.7 代码翻译
代码到代码的翻译(Code-to-code)是将一种编程语言编写的代码转换为另一种同功能编程语言的过程。 此过程也称为代码转换、转译、代码迁移或源到源翻译。 此功能仅适用于已按指导方式训练的模型。
# >>> Model: ChatGPT
# >>> Prompt:
Convert this function in 'C' language.
"""
def double_sum_to_value(list_of_ints, value):
if len(list_of_ints) < 2:
return False
else:
for i in range(len(list_of_ints) - 1):
for j in range(i + 1, len(list_of_ints)):
if list_of_ints[i] + list_of_ints[j] == value:
return True
return False
"""
# >>> Result:
#include
bool double_sum_to_value(int list_of_ints[], int length, int value) {
if (length < 2) {
return false;
} else {
for (int i = 0; i < length - 1; i++) {
for (int j = i + 1; j < length; j++) {
if (list_of_ints[i] + list_of_ints[j] == value) {
return true;
}
}
}
return false;
}
}
"""
Explanation:
The function is defined with the return type bool, which represents the
boolean value of True or False in C.
The list_of_ints is passed as an integer array along with its length
length and the target value value.
The condition if (length < 2) is used to check if the length of the
array is less than 2, similar to the Python code.
The nested loops are implemented using for loops in C. The loop
variables i and j iterate over the indices of the array elements.
The condition list_of_ints[i] + list_of_ints[j] == value is checked
to determine if a pair of elements sums up to the target value,
similar to the Python code.
If a pair is found, true is returned, and if no pair is found, false
is returned at the end of the function.
Note: In C, it is important to include the necessary headers, such
as stdbool.h, for using the bool data type.
"""
2.8 代码缺陷检查
这是一个要求LLM检测提示中提供的源代码中的缺陷的过程。 此功能仅适用于已按指导方式训练的模型。
# >>> Model: ChatGPT
# >>> Prompt:
Find defects in this code.
"""
def double_sum_to_value(list_of_ints, value):
for i in range(len(list_of_ints)):
for j in range(i + 1, len(list_of_ints)):
if list_of_ints[i] + list_of_ints[j] == value:
return True
return False
"""
# >>> Result:
"""
There are a few potential defects in the provided code:
Inadequate Input Validation:
The code does not perform sufficient input validation. It assumes that
list_of_ints will always be a list and value will be a valid integer.
If these assumptions are not met, the code may raise exceptions or produce
incorrect results. It's good practice to validate the input types and
handle any potential errors or edge cases.
Lack of Bounds Checking:
The code uses nested loops to iterate over the indices of list_of_ints.
However, it does not perform any bounds checking to ensure that the
indices are within the valid range of the list. This can lead to
out-of-range errors if the input list is empty or has insufficient
elements. It's important to validate the length of list_of_ints before
iterating over its indices.
No Early Termination:
Once a pair of integers is found that satisfies the sum condition, the
code immediately returns True. However, it continues iterating through
the remaining pairs unnecessarily. This can result in unnecessary
computation and reduced performance. Adding a break statement after
the return True statement would optimize the code by terminating the
loops early.
Inefficient Nested Loop:
The code uses a nested loop to compare each pair of integers in list_of_ints.
This approach has a complexity of O(n^2), where n is the length of
list_of_ints. Depending on the size of the list, this can lead to poor
performance for larger inputs. Consider using alternative approaches,
such as utilizing a set to store seen values or sorting the list and
applying binary search, which can potentially reduce the complexity
to O(n) or O(n log n) respectively.
To address these potential defects, here's an improved version of the code:
"""
def double_sum_to_value(list_of_ints, value):
if not isinstance(list_of_ints, list) or not isinstance(value, int):
raise ValueError("Invalid input")
if len(list_of_ints) < 2:
return False
seen_values = set()
for num in list_of_ints:
complement = value - num
if complement in seen_values:
return True
seen_values.add(num)
return False
"""
In the updated code:
Input validation is performed to check the type of list_of_ints and value.
The length of list_of_ints is checked to ensure it has at least two elements
before proceeding with the main logic.
A set, seen_values, is used to store previously seen values for efficient
lookup.
If a pair is found that satisfies the sum condition, True is immediately
returned.
The code raises a ValueError if the input types are invalid, providing
clearer error handling.
The code overall has a reduced complexity of O(n), improving performance
compared to the original nested loop implementation.
"""
2.9 模板化和头脑风暴
对于最后一个用例,我们仅使用这些模型的文本生成功能。 这无疑是最具创意的案例,也是让我们能够快速转向软件框架定义的案例。 它需要最多的架构知识才能对建议进行批判性的审视。
# >>> Model: ChatGPT
# >>> Prompt:
You are a software architect.
Generates the skeleton of a mobile application used to display a map \\
and allow users to write comments at a point on the map.
# >>> Result:
Certainly! Here's a high-level skeleton of a mobile application that
displays a map and allows users to write comments at specific points on
the map:
1. User Interface:
. Map View: This is the primary view that displays the map.
. Annotation View: When the user taps on a specific point on the map,
an annotation view is displayed to allow writing comments.
. Comment List: A list view to display the comments associated with
each point on the map.
. User Authentication: Provide a login/signup feature to authenticate
users and associate comments with their accounts.
2. Components and Modules:
. Map SDK Integration: Integrate a map SDK (e.g., Google Maps, Mapbox)
to display the map and handle user interactions like panning and zooming.
. Annotation Management: Implement functionality to add annotations to
the map when the user taps on a specific point. Each annotation can
have associated comments.
. Comment Management: Implement functionality to allow users to write
and post comments. Comments should be associated with the selected
point on the map.
. User Authentication: Implement user authentication and session
management to associate comments with user accounts and provide a
personalized experience.
. Data Persistence: Use a database or storage system to store and
retrieve annotations and comments. This can be done using a server-side
backend or a local database.
3. Workflow:
. User opens the mobile app and is presented with a login/signup screen.
. After successful authentication, the user is directed to the Map View.
. The user can interact with the map, zoom in/out, and pan to navigate
to desired locations.
. When the user taps on a specific point on the map, an annotation view is
displayed.
. The user can write and post comments in the annotation view.
. The comments are saved and associated with the selected point on the map.
. The user can view the comments by tapping on existing annotations or
accessing a comment list view.
. The user can log out or switch to a different user account if needed.
4. Considerations:
. UI/UX Design: Design a user-friendly interface with intuitive map
interactions and clear annotation/comment presentation.
. Data Security: Implement secure authentication and ensure data privacy
for user accounts and comments.
. Performance Optimization: Consider implementing efficient data
retrieval and rendering mechanisms to ensure smooth map interactions
and quick comment loading.
. Offline Support: Implement offline capabilities, allowing users to
view previously loaded map data and comments when there is no internet
connection.
. Error Handling: Implement proper error handling and feedback
mechanisms to inform users of any issues, such as failed comment
submission or map loading errors.
Please note that this is a high-level overview, and the actual
implementation details and choice of technologies may vary depending
on the specific requirements and platform (iOS, Android, etc.) you
are targeting.
# Complementary prompt:
What would you recommend in terms of technology for this application?
# Result:
In terms of technology recommendations for developing a mobile application
with map functionality and comment features, here are some popular choices:
1. Mobile App Development Frameworks:
- React Native: A popular cross-platform framework that allows building
mobile apps using JavaScript and React. It offers good performance
and code reusability across iOS and Android platforms.
- Flutter: A cross-platform framework developed by Google that uses
the Dart programming language. It provides a rich set of UI components
and offers fast app development with excellent performance.
- Native Development: If you prefer native development for iOS and
Android separately, you can use Swift/Objective-C for iOS and
Java/Kotlin for Android.
2. Map SDKs:
- Google Maps SDK: Provides comprehensive mapping functionality,
including interactive maps, markers, annotations, and user interaction
support.
- Mapbox SDK: Offers powerful mapping tools with customizable styles,
markers, annotations, and support for user interactions.
3. Backend and Database:
- Backend as a Service (BaaS): Services like Firebase or AWS Amplify
provide ready-to-use backend infrastructure, authentication, and
database support, simplifying backend development.
- Custom Backend: You can build your own backend using technologies
like Node.js, Python, Ruby, or Java, along with databases like MySQL,
PostgreSQL, or MongoDB.
4. User Authentication:
- Firebase Authentication: Provides easy integration for user
authentication with various login methods like email/password,
social media logins, etc.
- OAuth Providers: Utilize OAuth providers like Google, Facebook, or
Twitter for seamless authentication and account creation.
5. Additional Considerations:
- Data Storage: Depending on the scale and requirements of your
application, you can choose a database solution such as Firebase
Realtime Database, Cloud Firestore, or a SQL/NoSQL database for
storing comments and other data.
- API Development: If you plan to develop a custom backend, consider
using frameworks like Express.js (Node.js) or Flask (Python) to build
RESTful APIs for communication between the mobile app and the backend.
It's essential to evaluate the specific requirements, scalability needs,
and development expertise of your team when choosing the technology stack.
Additionally, consider factors like community support, documentation, and
ease of integration with your chosen frameworks.
3、提示最佳实践
重要的是要遵循一些实用的技巧和指南,以利用大型语言模型的代码生成来获得最佳结果:
- LLM对上下文非常敏感,用最多信息的纯文本表明你愿意做什么,而且要精确。 请记住,它们经过训练可以预测前一个标记的下一个标记。
- 对于指令调教过的LLM,要求其扮演与其职责密切相关的角色,例如开发人员或测试人员。
- 指明目标语言。 许多模型都是用多种语言训练的,它们有一些相似之处,比如如何注释。
- 请毫不犹豫地指出包名称和版本号。
- 对于文本补全,添加示例可以提高输出的准确性。
- 温度必须很低,因为我们确实希望模型生成危险代码。
4、代码生成评估简介
代码生成模型主要通过将输出与参考解决方案进行比较来评估,如翻译的 BLEU 分数,对应关系可以是精确的,也可以是模糊的。 该方法的局限性在于它无法捕获代码的重要句法和语义特征,并且由于完美精度过于严格,它低估了相同语义逻辑下的不同结果。 该指标将有利于已根据测试数据进行训练的模型或已使用评估数据来匹配输出的模型。
2021 年 7 月,OpenAI 引入了 Codex 和一种名为 HumanEval 的新评估技术,用于衡量从文档字符串合成程序的功能正确性。 OpenAI 发布的 HumanEval 数据集包含 164 个编程问题,其中包括函数签名、文档字符串、正文和多个单元测试。 它们是手写的,以确保不包含在代码生成模型的训练集中。 HumanEval 使用 pass@k 指标。 该指标由 Kulal 等人于 2019 年定义,用于评估功能正确性。 k 是每个问题生成并评估的代码样本的数量。 如果任何样本通过单元测试,则认为问题已解决,然后报告已解决问题的总分数。
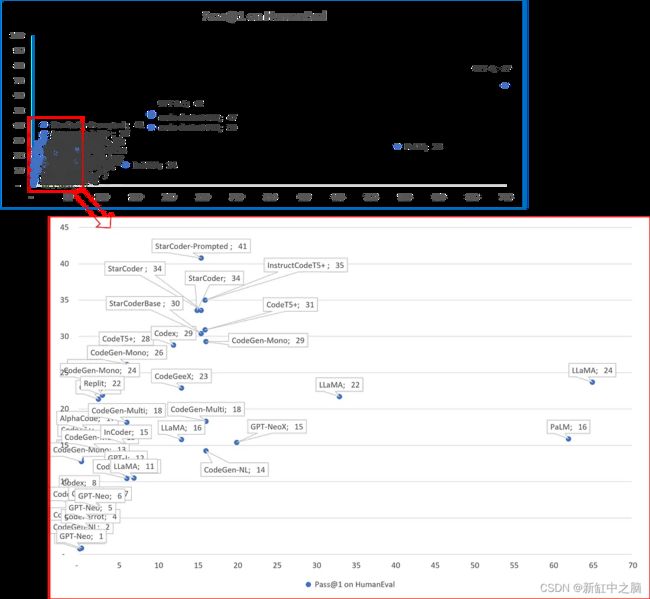
GPT家族在选秀分数方面是最好的。 就每个分数的参数数量而言,StarCoder、CodeT5+ 和 CodeGen 模型目前最有趣。
HumanEval 并不是唯一可用的基准测试,你还可以考虑以下基准测试:
- Salesforce 的 WikiSQL 于 2017 年推出,专门针对 SQL 语言,由 87,726 个手工注释的 SQL 查询和自然语言问题对组成。
- CodeBLEU 于 2020 年开发,利用 BLEU 的强大功能来测量 n 元语法匹配,同时通过抽象语法树 (AST) 合并代码语法,并通过数据流合并代码语义。
- 2021 年,微软推出了 CodeXGLUE(CODE 通用语言理解评估基准)。 它是代码智能任务的集合和模型评估和比较的平台。 它包括 10 个多样化代码智能任务的 14 个数据集,涵盖以下场景:代码到代码(克隆检测、缺陷检测、完形填空测试、代码完成、代码修复和代码到代码翻译); 文本代码(自然语言代码搜索、文本到代码生成); 代码文本(代码摘要); 和文本到文本(文档翻译)。
- 自动编程进度标准(APPS)总共包含 10,000 个编码问题,131,836 个用于检查解决方案的测试用例和 232,444 个由人类编写的真实解决方案。
- MBPP(Mostly Basic Python Problems)是社区提供的约 1000 个 Python 编程问题的基准测试,旨在供新手程序员解决,涵盖编程基础知识、标准库功能……每个问题由任务描述、解决方案代码和三个自动化问题组成。 测试用例。
5、开发人员的生产力是否更高?
2022 年 9 月,Github 进行的一项关于 Github Copilot 应用程序对开发人员生产力和幸福感影响的研究显示了许多有趣的结果:
- 大约 60% 到 75% 的用户表示工作满意度更高,编码挫折感减少,专注于完成任务的能力增强。
- 据开发人员称,事实证明,GitHub Copilot 在维持工作流程 (73%) 和处理重复性任务时节省精力 (87%) 方面发挥了重要作用。
- Github 招募了 95 名专业开发人员,将他们随机分为两组,并对他们用 JavaScript 编写 HTTP 服务器所需的时间进行计时。 一组使用 GitHub Copilot 来完成任务,另一组则没有。 使用 GitHub Copilot 的开发人员的任务效率显着提高,与未使用 GitHub Copilot 的开发人员相比,完成任务的速度提高了 55%。
这是 Github 对 Github 提供的产品进行的一项研究。 需要进行更多的学术研究才能对观察到的成果得出任何结论。 尽管如此,结果还是很有趣,可以公平地说,这些类型的工具在编写源代码中经常遇到的函数方面提供了明确的好处。
6、道德与考量
代码生成带来了许多新的道德问题,并引发了有关开发人员角色的问题。 这些系统并非没有缺点,重要的是要记住与它们相关的一些需要考虑的问题:
- 公平使用:使用开源代码作为底层机器学习模型的训练数据这一有争议的问题仍然需要解决。 通常建议开发人员在源代码中标明他们已重用的代码。 这通常也会在许可证中注明。 生成方法与此背道而驰。
- 自动化偏差:开发人员可能倾向于过于依赖模型生成的结果。 这些系统可能会生成表面上看起来正确的代码,但无法提供预期的服务,要么是因为请求不精确或制定得不好,要么是因为生成的代码由于模型不正确,要么是因为训练代码不正确(垃圾中的垃圾)。 ,垃圾出)。 如果开发人员太快接受这些不正确的代码建议,他们就会面临花费更多时间调试甚至遇到重大安全问题的风险。
- 安全威胁:训练数据可能包含注入或泄露代码(恶意软件)。 控制生成并从功能和安全角度彻底检查代码势在必行。
- 数据、代码和信息泄露:切勿在提示中放入任何机密内容,因为这会构成安全风险。 业务规则、项目代码、数据示例,这些都不应该进入与模型的交互中。 请记住,输入也可用于训练模型,因此部分代码可能最终会出现在输出中。 输入也可能被恶意方分析并未经同意使用。
- 数据集偏差:训练数据集通常是来自开源、可公开访问的 Github 存储库的源代码,还包含用户撰写的评论。 因此,这些数据集可能包含某些刻板印象,例如来自文本注释或源代码(例如变量、函数和类名)的种族和性别。 因此,社会偏见可能本质上被内置到根据这些数据训练的模型中。 上游过滤或输出控制仍然是一项复杂的活动,可以帮助减轻这些偏差,但要完全消除仍然很复杂。
- 计算成本:生成一段代码需要对通常较重的模型进行多次推理。 数十亿参数模型的每次推理都需要大量的电力,然后根据底层系统生成二氧化碳。 简单的复制粘贴肯定会减少能源消耗。
- 知识产权:该模型不能保证代码抄袭和产权保存。 另外,请用户阅读这些模型的精确许可证,这些模型可能是开源的,但禁止用于商业用途。 OpenAI 在他们的论文中“研究发现 Codex 模型很少生成与训练数据内容相同的代码。 在一项检查与训练数据中的代码片段匹配的代码生成频率的研究中,此类发生率 < 0.1%。” 他们发现类似的代码对应于经典的代码元素,这在一定程度上消除了在输出中找到其他人的代码部分的风险。 OpenAI 研究人员认为,这与学习不良(过度拟合)有关。
生成式人工智能系统可能会生成侵犯现有版权作品的输出媒体。 我们认为,这不太可能是结构良好的生成式人工智能系统的意外结果,尽管由于过度拟合或开发人员的意图,这种情况仍然有可能发生。 关于人工智能创新知识产权保护征求意见的意见 — 2020 年 3 月 3 日
- 教育工作者和学生的考虑因素:在《编程很难——或者至少曾经是:人工智能代码生成的教育机会和挑战》论文中,大学假设这些工具将继续可供学生使用,他们的能力将继续提高。 改进,因此采用率将会增加。 他们的结论是,将人工智能生成的代码集成到编程教育中正变得越来越普遍,这既带来了挑战,也带来了好处。 随着软件开发的未来更多地倾向于自动生成代码,因此需要调整实践并专注于代码读取和评估而不是代码生成。
人工智能生成的代码为入门编程和相关课程的学生和教育工作者带来了机遇和挑战。 这些工具突然变得可行且易于访问,这表明教育工作者可能没有意识到或没有准备好应对人工智能生成的代码对教育实践产生的重大影响。 因此,我们迫切需要根据这些新技术来审查我们的教育实践。
7、结束语
代码生成方面的这一新进展彻底改变了人类和机器在一个由人类向机器发出指令的领域中协同工作的方式。 这些技术有望显着提高时间和性能,但我们不应该简单地说它们是针对所有开发人员,尤其是初学者。
诚然,代码解释可以用来更快地输入源代码,但代码生成需要高级的开发知识,以避免将错误引入程序或忘记软件设计不仅仅是编写功能。
这些模型变得越来越高效,但它们仍然对请求的制定方式很敏感,并且取决于多个因素:模型性能、支持技能和应用程序设计技能。 这些因素意味着必须谨慎对待这些技术,并且不要低估事先培训的需要。
一种新方法正在迅速出现,涉及自协作代码生成的使用。 它包括通过生成本身链接从定义到测试用例的多个生成级别。 这个序列显着改善了最终结果并开辟了新的视角。 我们还没有看到这一领域最后的重大进展。
原文链接:Top 20代码生成LLM — BimAnt