Elasticsearch核心技术与实战学习笔记 第三章 13使用分析器进行分词
一 序
本文属于极客时间Elasticsearch核心技术与实战学习笔记系列。
二 理论
1Analysis 与 Analyzer
你只能搜索在索引中出现的词条,所以索引文本和查询字符串必须标准化为相同的格式。分词和标准化的过程称为分析。
Analysis 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词
,Analysis 是通过 Analyzer 来实现的。 Elasticsearch 有多种 内置的分析器,如果不满足也可以根据自己的需求定制化分析器,除了在数据写入时转换词条,匹配 Query 语句时候也需要用相同的分析器对查询语句进行分析。
2、Analyzer 的组成
- Character Filters (针对原始文本处理,例如,可以使用字符过滤器将印度阿拉伯数字( )转换为其等效的阿拉伯语-拉丁语(0123456789))
- Tokenizer(按照规则切分为单词),将把文本 "Quick brown fox!" 转换成 terms [Quick, brown, fox!],tokenizer 还记录文本单词位置以及偏移量。
- Token Filter(将切分的的单词进行加工、小写、刪除 stopwords,增加同义词)
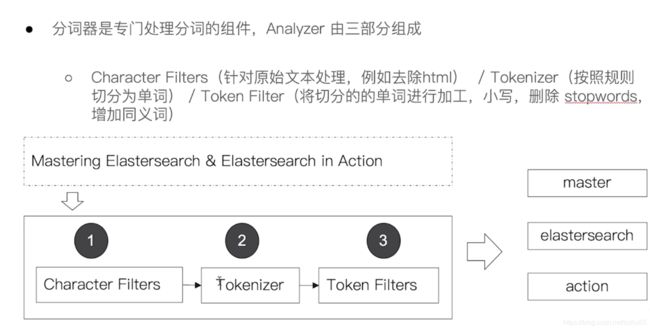
3 内置的分词器
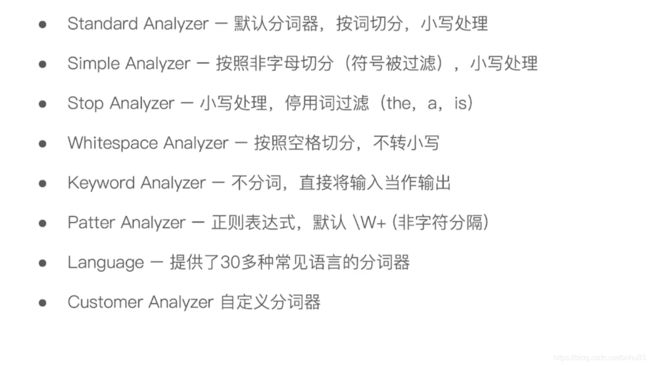

三 操作:
Standard Analyzer
- 默认分词器
- 按词分类
- 小写处理
#standard
GET _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}输出:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "",
"position" : 12
}
]
}
太长了,下面筛选结果。
Simple Analyzer
- 按照非字母切分,非字母则会被去除
- 小写处理
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Stop Analyzer
- 小写处理
- 停用词过滤(the,a, is)
GET _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[quick,brown,foxes,jumped,over,lazy,dog,s,bone]
Whitespace Analyzer
- 按空格切分
#stop
GET _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The,2,QUICK,Brown-Foxes,jumped,over,the,lazy,dog's,bone.]
Keyword Analyzer
- 不分词,当成一整个 term 输出
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.]
atter Analyzer
- 通过正则表达式进行分词
- 默认是 \W+(非字母进行分隔)
GET _analyze
{
"analyzer": "pattern",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[the,2,quick,brown,foxes,jumped,over,the,lazy,dog,s,bone]
Language Analyzer
#english
GET _analyze
{
"analyzer": "english",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
输出:
[2,quick,brown,fox,jump,over,the,lazy,dog,bone]
中文分词要比英文分词难,英文都以空格分隔,中文理解通常需要上下文理解才能有正确的理解,
比如 [苹果,不大好吃]和[苹果,不大,好吃],这两句意思就不一样。

试验下ik分词器.
[root@bad4478163c8 elasticsearch]# bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip
-> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip
[=================================================] 100%??
Exception in thread "main" java.lang.IllegalArgumentException: Plugin [analysis-ik] was built for Elasticsearch version 7.1.0 but version 7.2.0 is running
at org.elasticsearch.plugins.PluginsService.verifyCompatibility(PluginsService.java:346)
at org.elasticsearch.plugins.InstallPluginCommand.loadPluginInfo(InstallPluginCommand.java:718)
at org.elasticsearch.plugins.InstallPluginCommand.installPlugin(InstallPluginCommand.java:793)
at org.elasticsearch.plugins.InstallPluginCommand.install(InstallPluginCommand.java:776)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:231)
at org.elasticsearch.plugins.InstallPluginCommand.execute(InstallPluginCommand.java:216)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.MultiCommand.execute(MultiCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.plugins.PluginCli.main(PluginCli.java:47)一定要注意版本,否则就出现上面那种错误。
对于docker启动的es来说,要先进入docker exec -it es72_01 bash
因为是集群模式,所以对别的节点也是一样安装。
安装完成后重启集群。docker-compose restart
访问:
http://localhost:9200/_cat/plugins
输出:
es72_01 analysis-ik 7.2.0 es72_02 analysis-ik 7.2.0
现在验证下分词器
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
输出:
[他,说,的,确,实,在,理]
换成ik分词器:
POST _analyze
{
"analyzer": "ik_smart",
"text": "他说的确实在理”"
}
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "说",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "的确",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "实",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "在理",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
}
]
}
可见好一些,当然中文分词器很多。老师讲的是通过 ICU Analyzer 对中文分词的效果, 可以自己选择。
四、总结
本篇对 Analyzer 进行详细讲解,ES 内置分词器是如何工作的。如果是中文分词器,还有许多值得学习的地方。能支持自定义分词,结合业务场景来落地。