自媒体项目详述
总体框架
本项目主要着手于获取最新最热新闻资讯,以微服务构架为技术基础搭建校内仅供学生教师使用的校园新媒体app。以文章为主线的核心业务主要分为如下子模块。自媒体模块实现用户创建功能、文章发布功能、素材管理功能。app端用户模块实现文章搜索、文章点赞、关注、商家优惠卷秒杀等功能。业务可以帮助商家引流,增加曝光度,也可以为用户提供查看提供附近消费场所。
主要技术:SpringBoot+Springcloud+MySQL+MyBatisPlus+Redis+ElasticSearch+Kafka+MongoDB+xxl-job
主要职责:
1 采用Redis作缓存,并手动封装了一个工具类,通过互斥锁+逻辑过期的方式解决缓存击穿问题·。

1.1 Redis工具类
我们主要对这部分功能的java代码进行讲解:
@Slf4j //日志
@Component//把bean给Spring维护
public class CacheClient {
private final StringRedisTemplate stringRedisTemplate;
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
//构造函数注入stringRedisTemp,也可以用resource注解
public CacheClient(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
//方法1 把value转为JsonString
public void set(String key, Object value, Long time, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit);
}
//方法2
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {
// 设置逻辑过期
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time)));
// 写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
//方法3 作为工具,返回的是泛型
public R queryWithPassThrough(
//前缀,id,返回值类型,数据库查询的逻辑(有参有返回值的函数),ttl,ttl单位
String keyPrefix, ID id, Class type, Function dbFallback, Long time, TimeUnit unit){
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(json)) {
// 3.存在,直接返回
return JSONUtil.toBean(json, type);
}//不存在
// 判断命中的是否是空值
if (json != null) {
// 返回一个错误信息
return null;
}
// 4.不存在,根据id查询数据库
//how从数据库查?涉及类型,sql语句等逻辑,让调用者写
R r = dbFallback.apply(id);
// 5.不存在,返回错误
if (r == null) {
// 将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 返回错误信息
return null;
}
// 6.存在,写入redis
this.set(key, r, time, unit);//方法1
return r;
}
//方法4
public R queryWithLogicalExpire(
//前缀,id,返回值类型,数据库查询的逻辑(有参有返回值的函数),ttl,ttl单位
String keyPrefix, ID id, Class type, Function dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.存在,直接返回
return null;
}
// 4.命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expireTime = redisData.getExpireTime();
// 5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
// 5.1.未过期,直接返回店铺信息
return r;
}
// 5.2.已过期,需要缓存重建
// 6.缓存重建
// 6.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
// 6.2.判断是否获取锁成功
if (isLock){
// 6.3.成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 查询数据库
R newR = dbFallback.apply(id);
// 重建缓存 方法2
this.setWithLogicalExpire(key, newR, time, unit);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
// 释放锁
unlock(lockKey);
}
});
}
// 6.4.返回过期的商铺信息
return r;
}
//互斥锁 解决缓存击穿
public R queryWithMutex(
String keyPrefix, ID id, Class type, Function dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, type);
}
// 判断命中的是否是空值
if (shopJson != null) {
// 返回一个错误信息
return null;
}
// 4.实现缓存重建
// 4.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
R r = null;
try {
boolean isLock = tryLock(lockKey);
// 4.2.判断是否获取成功
if (!isLock) {
// 4.3.获取锁失败,休眠并重试
Thread.sleep(50);
return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);
}
// 4.4.获取锁成功,根据id查询数据库
r = dbFallback.apply(id);
// 5.不存在,返回错误
if (r == null) {
// 将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 返回错误信息
return null;
}
// 6.存在,写入redis
this.set(key, r, time, unit);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 7.释放锁
unlock(lockKey);
}
// 8.返回
return r;
}
//尝试拿锁
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
//释放锁
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
}
我们可以直接看方法4,这里通过泛型的方式对输入的参数做了以下处理:
1、从redis查询商铺缓存,判断是否存在
2、存在,需要先把json反序列化为对象
3、判断是否过期,没有过期直接返回,过期了进行缓存重建
4、过期了尝试获取锁对象,此处采用Redis中的setnx方法实现分布式锁的功能。使用店铺前缀加商品id作为key
5、没有获取到,返回过期数据。获取到了使用线程池的submit方法开启新的线程去重建缓存(也就是更新过期时间)
6、重建完成释放锁
1.2 ShopServiceImpl 中调用工具类封装的方法三解决缓存穿透
@Resource
private CacheClient cacheClient;//注入
@Override
public Result queryById(Long id) {
// 解决缓存穿透
Shop shop = cacheClient
.queryWithPassThrough(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 互斥锁解决缓存击穿
// Shop shop = cacheClient
// .queryWithMutex(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 逻辑过期解决缓存击穿
// Shop shop = cacheClient
// .queryWithLogicalExpire(CACHE_SHOP_KEY, id, Shop.class, this::getById, 20L, TimeUnit.SECONDS);
if (shop == null) {
return Result.fail("店铺不存在!");
}
// 7.返回
return Result.ok(shop);
}
这里传入缓存击穿工具类的泛型参数包括:
- CACHE_SHOP_KEY:店铺的关键字
- id:商品的id
- Shop.class:店铺的类型-JSON序列化时指定对象的类型
- this::getById:方法的泛型,可以使用dbFallback.apply(传入的参数)调用,这个也可以定义为任何可执行方法
- 20L:逻辑过期时间
- TimeUnit.SECONDS:时间的单位
2 使用Redis作为分布式锁,解决集群下的线程并发安全问题,基于消费者组模式,完成异步下单功能。
2.1 分布式锁的概率和可能出现的问题
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
我们可以怎么描述这个问题呢:
- 1、解决错误删除的问题
- 2、解决释放锁条件判断成功后出现阻塞,把别的线程释放的问题。
基本思路是使用setnx,但是为了防止死锁,我们加入过期时间。但这这样如果一个线程阻塞,会导致别的线程把自己的锁给释放,为此,我们加入了线程id的验证。但是存在一个高并发情况下有可能线程id相同的情况,为此我们加入了UUID保证每个线程的唯一。释放锁的过程必须是原子性,因为如果释放过程,条件判断是自己线程id的时候后出现阻塞的话,也会导致锁的自动释放,等别的进程来了之后刚获取的锁会被这个阻塞的释放锁过程释放,所以我们采用了lua脚本的方式保证了获取锁和释放锁的原子性。最后为了进一步提高响应速度,我们使用了异步下单的方式提高并发能力。


java代码:
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
private string name;//锁的名称
private StringRedisTemplate stringRedisTemplate;
//构造函数 传入参数
public SimpleRedisLock( string name,StringRedisTemplate stringRedisTemplate){
this.name=name;
this.stringRedisTemplate = stringRedisTemplate;
}
private static final String KEY_PREFIX="lock:"//key的统一前缀
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示 对应redis的value 代表 哪个线程获得锁了
String threadId = Thread.currentThread().getId()
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutSec, TimeUnit.SECONDS);
//封装函数 导致返回值 自动拆箱 变成 boolean 但是有null空指针风险所以用.TRUE.equals
return Boolean.TRUE.equals(success);
}
2.2 Redis分布式锁误删问题
2.2.1 误删问题原因:
1、由于为了防止死锁问题,设计过期时间。当过期时间后,又有线程获取了锁对象,之前没有执行完的方法就会释放对象锁。
2、在解决1的情况下,如果释放锁的过程中出现了阻塞,那么该线程会以为自己一直是要释放自己的锁,然而却把别的刚拿到的锁给释放了。

2.2.2 误删解决方法
在获取锁时存入线程标示,在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致。
- 如果一致则释放锁
- 如果不一致则不释放锁
2.2.3 Lua脚本解决多条命令原子性问题
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性
lua脚本
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0
java代码
//泛型Long是返回值类型
private static final DefaultRedisScript UNLOCK_SCRIPT;
static {//静态代码块 初始化
UNLOCK_SCRIPT = new DefaultRedisScript<>();
//设置脚本 位置(ClassPathResource这个类会
(默认去classpath下面找,我们的lua就放在resources下面滴 “文件名称”))
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);//返回值
}
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(
UNLOCK_SCRIPT,//提前读取文件 等到释放锁的时候读取 会产生IO流 降低性能
//.singletonList 把锁的key转化成单元素 集合形式 返回
Collections.singletonList(KEY_PREFIX + name),
ID_PREFIX + Thread.currentThread().getId());//线程表示
}
经过以上代码改造后,我们就能够实现 拿锁比锁删锁的原子性动作了~
2.3分布式锁的总结
以上是我们解决分布式锁的查询的问题,该分布式锁具有以下中重点特性:
1、利用setnx方法满足互斥性
2、利用lua脚本可以实现释放锁的原子性
3、利用逻辑过期时间可以避免死锁,提高安全性
4、利用redis集群具有高可用和高并发特性
2.4 秒杀之异步下单功能
//异步处理线程池 秒杀订单 处理器
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
//在当前 Impl类初始化之后执行 ,因为当这个类初始化好了之后,随时都是有可能要执行的
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
// 用于线程池处理的任务
// 当初始化完毕后,就会去从队列 中去拿信息
private class VoucherOrderHandler implements Runnable{
@Override
public void run() {
while (true){//不断地从队列 取
try {
// 1.获取队列中的订单信息
take() 方法:获取 和删除 该队列的 头部,如果需要则 等待 直到 元素可用
VoucherOrder voucherOrder = orderTasks.take();
// 2.创建订单
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("处理订单异常", e);
}
}
}
private void handleVoucherOrder(VoucherOrder voucherOrder) {
//1.获取用户
Long userId = voucherOrder.getUserId();
// 2.创建锁对象
RLock redisLock = redissonClient.getLock("lock:order:" + userId);
// 3.尝试获取锁
boolean isLock = redisLock.lock();
// 4.判断是否获得锁成功
if (!isLock) {
// 获取锁失败,直接返回失败或者重试
log.error("不允许重复下单!");
return;
}
try {
//注意:由于是spring的事务是放在threadLocal中,此时的是多线程,事务会失效
proxy.createVoucherOrder(voucherOrder);
} finally {
// 释放锁
redisLock.unlock();
}
}
//阻塞队列
private BlockingQueue orderTasks =new ArrayBlockingQueue<>(1024 * 1024);
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
//2.2 为0 有购买资格,把下单信息保存到阻塞队列
VoucherOrder voucherOrder = new VoucherOrder();
// 2.3.订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
// 2.4.用户id
voucherOrder.setUserId(userId);
// 2.5.代金券id
voucherOrder.setVoucherId(voucherId);
// 2.6.放入阻塞队列
orderTasks.add(voucherOrder);
//3.子线程不能获取代理对象,主线程可以 获取了给handler创建订单
proxy = (IVoucherOrderService)AopContext.currentProxy();
//4.返回订单id
return Result.ok(orderId);
}
@Transactional//把他的voucherOrder创建 挪到 seckillVoucher
public void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherOrder.getVoucherId()).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
log.error("用户已经购买过了");
return ;
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
log.error("库存不足");
return ;
}
save(voucherOrder);
}
代码解释:
1、主线程主要在redis中对使用lua脚本对库存、用户id判断,并将创建的订单放到队列中
2、开启线程池,对队列中的数据后台独立线程异步创建订单
2.5 异步下单总结
秒杀业务的优化思路是什么?或者可以问异步下单你做了什么工作
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单,提高并发量
3、基于Redis中的sortedSet的排序功能,实现点赞排行榜,用时间戳作为score,筛选出最早点赞的用户
Redis的sorted_set是有序集合,在set的基础上增加score属性用来排序
点赞功能:
@Override
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 3.如果未点赞,可以点赞
// 3.1.数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2.保存用户到Redis的set集合 zadd key value score
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1.数据库点赞数 -1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2.把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}
private void isBlogLiked(Blog blog) {
//中间没变
String key = "blog:liked:" + blog.getId();
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score != null);
}
点赞列表查询
@Override
public Result queryBlogLikes(Long id) {
String key = BLOG_LIKED_KEY + id;
// 1.查询top5的点赞用户 zrange key 0 4
Set top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (top5 == null || top5.isEmpty()) {//没人点赞
return Result.ok(Collections.emptyList());
}
// 2.解析出其中的用户id
List ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
String idStr = StrUtil.join(",", ids);
//3.0 未实现排序功能的点赞top5 因为传参的是5,1;
// listByIds=in(5,1)是倒着来的, 要用 order by field
/* List userDTOS = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());*/
// 3.根据用户id查询用户 WHERE id IN ( 5 , 1 ) ORDER BY FIELD(id, 5, 1)
List userDTOS = userService.query()//自定义查询
.in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 4.返回
return Result.ok(userDTOS);
}
解析:
redis数据结构都是key-value结构
1、点赞时,使用博客的唯一主键作为zset的key,使用用户id作为value。这样每次点赞或者取消点赞可以把相应的用户添加或者移除。需要注意的是,我们在加入点赞信息的时候,需要加入时间戳,为后面的点赞排序做准备。
2、查看实时点赞列表时,需要查询top5的点赞用户( zrange key 0 4)
4、使用MongoDB记录用户搜索记录,使用ElasticSearch优化搜索功能,提高用户体验和减轻数据库压力。
此处是将黑马头条中的自媒体模块的搜索功能加入到了这个外卖app中。
4.1 MongoDB记录用户搜索记录
4.1.1 实体类
用户搜索记录对应的集合,对应实体类:
```java
package com.heima.search.pojos;
import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
import java.util.Date;
/**
*
* APP用户搜索信息表
*
* @author itheima
*/
@Data
@Document("ap_user_search")
public class ApUserSearch implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
private String id;
/**
* 用户ID
*/
private Integer userId;
/**
* 搜索词
*/
private String keyword;
/**
* 创建时间
*/
private Date createdTime;
}
4.1.2 搜索微服务集成mongodb
①:pom依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
dependency>
②:nacos配置
spring:
data:
mongodb:
host: 192.168.200.130
port: 27017
database: leadnews-history
4.1.3 创建Service中新增insert方法,并设计实现类。在实现方法中添加注解@Async来实现异步调用
@Service
@Slf4j
public class ApUserSearchServiceImpl implements ApUserSearchService {
@Autowired
private MongoTemplate mongoTemplate;
/**
* 保存用户搜索历史记录
* @param keyword
* @param userId
*/
@Override
@Async
public void insert(String keyword, Integer userId) {
//1.查询当前用户的搜索关键词
Query query = Query.query(Criteria.where("userId").is(userId).and("keyword").is(keyword));
ApUserSearch apUserSearch = mongoTemplate.findOne(query, ApUserSearch.class);
//2.存在 更新创建时间
if(apUserSearch != null){
apUserSearch.setCreatedTime(new Date());
mongoTemplate.save(apUserSearch);
return;
}
//3.不存在,判断当前历史记录总数量是否超过10
apUserSearch = new ApUserSearch();
apUserSearch.setUserId(userId);
apUserSearch.setKeyword(keyword);
apUserSearch.setCreatedTime(new Date());
Query query1 = Query.query(Criteria.where("userId").is(userId));
query1.with(Sort.by(Sort.Direction.DESC,"createdTime"));
List<ApUserSearch> apUserSearchList = mongoTemplate.find(query1, ApUserSearch.class);
if(apUserSearchList == null || apUserSearchList.size() < 10){
mongoTemplate.save(apUserSearch);
}else {
ApUserSearch lastUserSearch = apUserSearchList.get(apUserSearchList.size() - 1);
mongoTemplate.findAndReplace(Query.query(Criteria.where("id").is(lastUserSearch.getId())),apUserSearch);
}
}
}
4.1.4 在文章搜索中加入插入搜索历史的记录
/**
* es文章分页检索
*
* @param dto
* @return
*/
@Override
public ResponseResult search(UserSearchDto dto) throws IOException {
//1.检查参数
if(dto == null || StringUtils.isBlank(dto.getSearchWords())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
ApUser user = AppThreadLocalUtil.getUser();
//异步调用 保存搜索记录
if(user != null && dto.getFromIndex() == 0){
apUserSearchService.insert(dto.getSearchWords(), user.getId());
}
4.1.5 加载搜索记录列表,在mongoDb数据中查询前十条,按照时间顺序倒叙展示
实现方法
/**
* 查询搜索历史
*
* @return
*/
@Override
public ResponseResult findUserSearch() {
//获取当前用户
ApUser user = AppThreadLocalUtil.getUser();
if(user == null){
return ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN);
}
//根据用户查询数据,按照时间倒序
List<ApUserSearch> apUserSearches = mongoTemplate.find(Query.query(Criteria.where("userId").is(user.getId())).with(Sort.by(Sort.Direction.DESC, "createdTime")), ApUserSearch.class);
return ResponseResult.okResult(apUserSearches);
}
4.2 使用ElasticSearch优化搜索功能
4.2.1微服务参数配置
1、在父工程pom中添加依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.4.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>7.4.0version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.4.0version>
dependency>
2、nacos配置中心添加搜索微服务配置(ip和端口)
spring:
autoconfigure:
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:
host: 192.168.200.130
port: 9200
4.2.2业务层实现类
@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* es文章分页检索
*
* @param dto
* @return
*/
@Override
public ResponseResult search(UserSearchDto dto) throws IOException {
//1.检查参数
if(dto == null || StringUtils.isBlank(dto.getSearchWords())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.设置查询条件
SearchRequest searchRequest = new SearchRequest("app_info_article");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//关键字的分词之后查询
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);
boolQueryBuilder.must(queryStringQueryBuilder);
//查询小于mindate的数据
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());
boolQueryBuilder.filter(rangeQueryBuilder);
//分页查询
searchSourceBuilder.from(0);
searchSourceBuilder.size(dto.getPageSize());
//按照发布时间倒序查询
searchSourceBuilder.sort("publishTime", SortOrder.DESC);
//设置高亮 title
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//3.结果封装返回
List<Map> list = new ArrayList<>();
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
Map map = JSON.parseObject(json, Map.class);
//处理高亮
if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){
Text[] titles = hit.getHighlightFields().get("title").getFragments();
String title = StringUtils.join(titles);
//高亮标题
map.put("h_title",title);
}else {
//原始标题
map.put("h_title",map.get("title"));
}
list.add(map);
}
return ResponseResult.okResult(list);
}
}
解析:
1、搜索的参数:关键字、时间、第几页,ES中使用must和filter连接多个搜索条件
2、所得到的hit文件中会有单独的一个hightlight属性的值(这里面设置了高亮的信息),我们将其取出后覆盖之前查询的结果,就可以实现高亮显示的效果
3、我们在覆盖是一些细节就是getFragments()来获取查询中的所有结果,结果是一个分片集合。
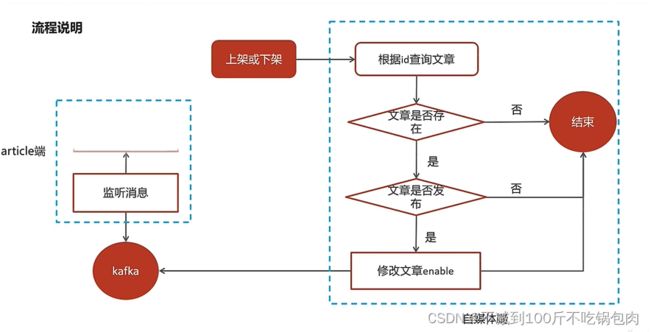
5 使用Kafka完成内部系统的消息通知,起到了削峰填谷及解耦的作用。
因为当时我们两个微服务是分开设计的,自媒体微服务可以先处理完,将信息发送给kafka,让app微服务异步去更新信息。
功能:
1、我们发送的是文章信息,只是topic绑定了app微服务,后期我们可以扩展更多的微服务,例如大数据之类的
2、起到削峰填谷的效果,在这里可能没有提现到。
5.1 导入kafka索引
1.导入kafka依赖
2、在生产者(自媒体端)的nacos配置中,加入生产者配置。在app端的nacos中配置消费者配置
生产者
spring:
kafka:
bootstrap-servers: 192.168.200.130:9092
consumer:
group-id: ${spring.application.name}
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
消费者
spring:
kafka:
bootstrap-servers: 192.168.200.130:9092
consumer:
group-id: ${spring.application.name}
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
5.2 监听消息,进行接下来的业务逻辑-文章上下架的功能
@Component
@Slf4j
public class ArtilceIsDownListener {
@Autowired
private ApArticleConfigService apArticleConfigService;
@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)
public void onMessage(String message){
if(StringUtils.isNotBlank(message)){
Map map = JSON.parseObject(message, Map.class);
apArticleConfigService.updateByMap(map);
log.info("article端文章配置修改,articleId={}",map.get("articleId"));
}
}
}
6 基于Feign熔断降级的功能,编写降级逻辑,防止服务出现雪崩问题。
-
服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃
-
服务降级虽然会导致请求失败,但是不会导致阻塞。
6.1 feign远程调用是什么意思
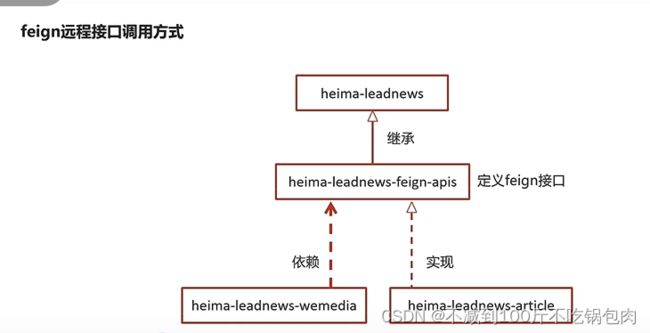
feign只是定义了抽象方法,方便依赖工程可以使用相应方法,以及让别的工程实现它,做具体的事情。类似于动态代理的意思一样,把需要做的事情先抽象出方法来。
可以看到,我们在定义了feign模块,并使用了自媒体模块依赖它,在feign定义了保存接口,并由文章模块的类实现。这样的话,我们通过自动注入调用feign接口的保存方法相当于实际调用的是文章模块中的保存方法。
具体实现过程
1、feign模块定义接口
feign接口
@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}
2、在继承的模块中调用此方法
@Autowired
private IArticleClient articleClient;
ResponseResult responseResult = articleClient.saveArticle(dto);
3、在需要调用的模块中定一个feign接口的实现类,风格为正常controller形式
@RestController
public class ArticleClient implements IArticleClient {
@Autowired
private ApArticleService apArticleService;
@PostMapping("/api/v1/article/save")
@Override
public ResponseResult saveArticle(@RequestBody ArticleDto dto) {
return apArticleService.saveArticle(dto);
}
}
4、在severce的实现类中定义具体的函数功能
@Override
public ResponseResult saveArticle(ArticleDto dto) {
//1.检查参数
if(dto == null){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
6.2 feign降级逻辑的具体编写

实现步骤:
1、编写降级逻辑的微服务,注意这里的降级逻辑是写在feign模块中,自我理解:
因为刚才远程调用其实也是把接口实现了,我们就可以在feign模块中写另外一个实现类,在远程调用不成功的时候就可以运行另外一个实现类,当然这也是feign给我们提供的功能,具体实现是通过
2、自媒体使用feign远程调用
3、在feign远程接口(也就是你在feign中抽象出来的方法上面)中指向降级代码(接口实现类)
4、在自媒体微服务中开启服务降级功能
①:在heima-leadnews-feign-api编写降级逻辑
package com.heima.apis.article.fallback;
/**
* feign失败配置
* @author itheima
*/
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}
在自媒体微服务中添加类,扫描降级代码类的包
package com.heima.wemedia.config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.heima.apis.article.fallback")
public class InitConfig {
}
②:远程接口中指向降级代码
package com.heima.apis.article;
import com.heima.apis.article.fallback.IArticleClientFallback;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}
③:客户端开启降级heima-leadnews-wemedia
在wemedia的nacos配置中心里添加如下内容,开启服务降级,也可以指定服务响应的超时的时间
feign:
# 开启feign对hystrix熔断降级的支持
hystrix:
enabled: true
# 修改调用超时时间
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
6.3 feign远程调用的底层逻辑
底层采用是动态代理的方式实现
1.feign采用的是基于接口的注解
2.feign整合了ribbon,具有负载均衡的能力
3.整合了Hystrix,具有熔断的能力
使用: 1.添加pom依赖。
2.启动类添加@EnableFeignClients
3.定义一个接口
@FeignClient(name=“xxx”)指定调用哪个服务