从EMNLP 2022速览信息检索领域最新研究进展
每天给你送来NLP技术干货!
© 作者|任瑞阳
机构|中国人民大学高瓴人工智能学院
来自 | RUC AI Box
本文梳理并介绍了自然语言处理顶会EMNLP 2022(主会长文)中信息检索领域的12篇论文,速览信息检索领域最新的研究进展,重点关注一阶段检索(召回)阶段相关的研究工作。
点击这里进群—>加入NLP交流群
1、DuReader: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.357.pdf
作者:Yifu Qiu, Hongyu Li, Yingqi Qu, Ying Chen, QiaoQiao She, Jing Liu, Hua Wu, Haifeng Wang
本文提出了一个中文的段落检索数据集DuReader,该数据集的数据包括了百度搜索引擎中的9万条查询和800万个段落。为了解决开发集和测试集中的假负例问题,作者请了内部数据团队来人工检查并重标注了多个检索模型返回的头部检索结果;为了降低测试集信息的数据泄露,作者使用了一个现有的查询匹配模型来识别并移除训练集中与开发集、测试集中相似的查询。

2、Large Dual Encoders Are Generalizable Retrievers
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.669.pdf
作者:Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, Yinfei Yang
本文针对双塔模型(dual-encoder)缺乏在其他领域的泛化性的问题,提出增大模型的参数规模,以及多阶段训练的方法来提高双塔模型的领域泛化性。其在多个检索任务,尤其是跨领域泛化性上带来了显著的提升,作者还发现该方法具有很高的数据效率。

3、RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.35.pdf
作者:Shitao Xiao, Zheng Liu, Yingxia Shao, Zhao Cao
本文针对稠密检索提出了一种高效的面向检索的预训练方法。该预训练方法基于掩码自动编码器(Masked Auto-Encoder),对于输入文本,使用较大的解码器掩码率(50∼90%),而对编码器使用常用的15%掩码率,任务目标是重建输入文本。实验证明所提出的方法取得了强大的检索性能,同时也具有较强的跨领域泛化能力。

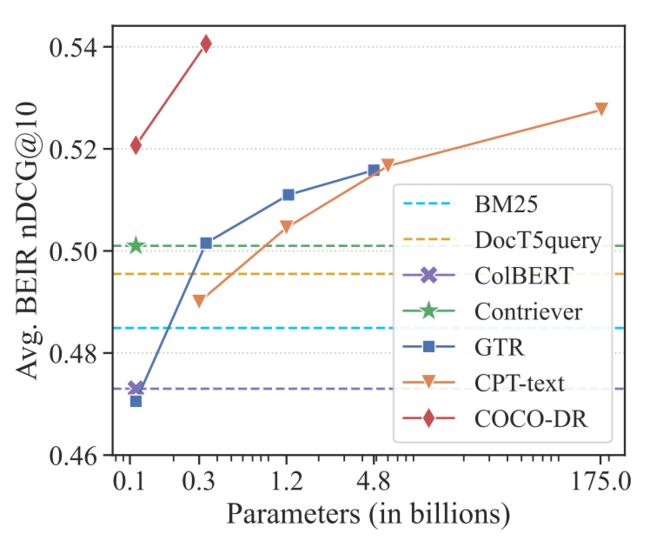
4、COCO-DR: Combating the Distribution Shift in Zero-Shot Dense Retrieval with Contrastive and Distributionally Robust Learning
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.95.pdf
作者:Yue Yu, Chenyan Xiong, Si Sun, Chao Zhang, Arnold Overwijk
本文提出对抗源领域训练任务和目标领域场景间的文档分布变化,来提高稠密检索模型跨领域泛化能力。作者使用持续对比学习在目标领域语料库上对模型进行持续预训练,另外,使用隐式分布式鲁棒优化(implicit Distributionally Robust Optimization)对来自不同源领域的查询类进行重新加权,提高模型在微调期间对出现率低的查询的鲁棒性。
5、ConvTrans: Transforming Web Search Sessions for Conversational Dense Retrieval
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.190.pdf
作者:Kelong Mao, Zhicheng Dou, Hongjin Qian, Fengran Mo, Xiaohua Cheng, Zhao Cao
本文研究了对话搜索场景下的稠密检索。由于大规模真实的对话搜索会话和标注数据很难获得,而稠密检索模型的训练往往依赖于大规模的标注数据,作者提出了一种数据增强方法,可以自动将网络搜索会话转换成对话搜索会话,来缓解数据稀缺的问题。

6、Explicit Query Rewriting for Conversational Dense Retrieval
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.311.pdf
作者:Hongjin Qian, Zhicheng Dou
本文同样对对话搜索场景下的稠密检索进行研究。在对话搜索场景下,查询可能具有上下文相关的特性,即部分词在其它内容中出现而省略。针对该特性,本文作者提出在统一框架下对查询进行重写和上下文建模,使用查询重写的监督信号来对上下文建模进行进一步增强。

7、Pseudo-Relevance for Enhancing Document Representation
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.800.pdf
作者:Jihyuk Kim, Seung-won Hwang, Seoho Song, Hyeseon Ko, Young-In Song
本文主要研究如何在稠密文档检索中增强双塔模型的文档表示。作者基于ColBERT的模型架构进行了改进,在不影响其效果的情况下,降低了其中多向量表示的大小,并使用查询日志进行监督学习。所提出的方法最高将延迟和内存占用分别减少了8倍和3倍。

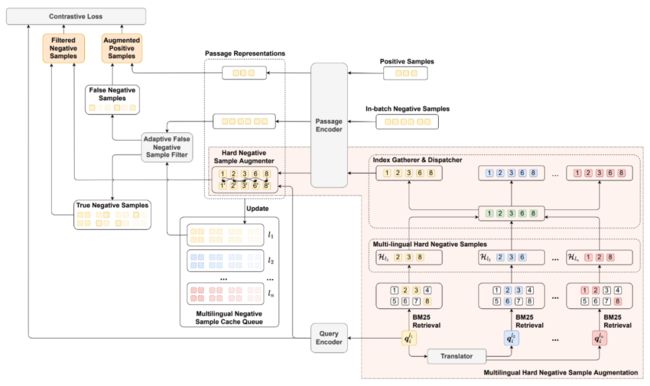
8、Recovering Gold from Black Sand: Multilingual Dense Passage Retrieval with Hard and False Negative Samples
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.730.pdf
作者:Tianhao Shen, Mingtong Liu, Ming Zhou, Deyi Xiong
本文主要研究多语言稠密检索中的负采样问题。作者提出多语言强负例采样增广,通过对查询和现有的强负例进行插值,来合成新的强负例;使用多语言负例缓存队列来存储每种语言先前批次中的负例,以增加用于寻来看的多语言负例的数量;提出一个轻量化的自适应假负例筛选器,利用伪标签区分假负例,并转化为用于训练的正例。
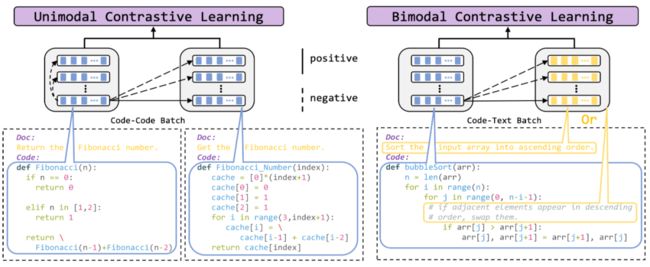
9、CodeRetriever: Large-scale Contrastive Pre-training for Code Search
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.187.pdf
作者:Xiaonan Li, Yeyun Gong, Yelong Shen, Xipeng Qiu, Hang Zhang, Bolun Yao, Weizhen Qi, Daxin Jiang, Weizhu Chen, Nan Duan
本文主要研究代码检索的问题,提出通过大规模的代码文本对比学习预训练,来学习函数级别的代码语义表示。作者采用了两种对比学习方案,单模态对比学习和双模态对比学习,分别对文档-函数名称的语义关系和文档-代码内联注释的语义关系进行学习,并利用大规模代码语料库进行预训练。
10、Exploring Representation-Level Augmentation for Code Search
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.327.pdf
作者:Haochen Li, Chunyan Miao, Cyril Leung, Yanxian Huang, Yuan Huang, Hongyu Zhang, Yanlin Wang
本文针对现有代码检索工作中,源代码数据增强方法通常需要额外的处理成本的问题进行了探索。作者提出了一种统一现有方法的表示级别增广的通用格式,并基于通用格式提出了三种新的增强方法(线性外推、二进制插值和高斯缩放)。此外,作者从理论上分析了所提出的增强方法相对于传统代码搜索对比学习方法的优势。

11、Efficient Document Retrieval by End-to-End Refining and Quantizing BERT Embedding with Contrastive Product Quantization
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.54.pdf
作者:Zexuan Qiu, Qinliang Su, Jianxing Yu, Shijing Si
文档检索往往依赖于语义哈希技术,而现有的语义哈希方法大多建立在传统的TF-IDF特征之上,并没有包含很多关于文档的语义信息。本文提出利用BERT表示基于乘积量化实现高效检索,具体地,为每个文档分配一个来自代码册的实型代码字以具有更多语义信息,而不是语义哈希中的二进制代码。作者还基于互信息最大化来提高代码字的表示能力,更准确地对文档进行量化。

12、Generative Multi-hop Retrieval
文章链接:https://preview.aclanthology.org/emnlp-22-ingestion/2022.emnlp-main.92.pdf
作者:Hyunji Lee, Sohee Yang, Hanseok Oh, Minjoon Seo
本文主要研究多条场景下使用生成式的方法实现检索。作者基于现有的自回归的实体链接工作进行了扩展,从生成短实体变为生成长的文本序列,使用编码器-解码器的模型架构,让查询和文档获得更充分的交互。该方法使用了前缀树的数据结构,让模型解码的序列为语料库内的文本,并提出了LM momorization和multi-hop memorization两个策略让模型能更好地对语料库进行记忆。

最近文章
深入理解Pytorch中的分布式训练
点击这里进群—>加入NLP交流群