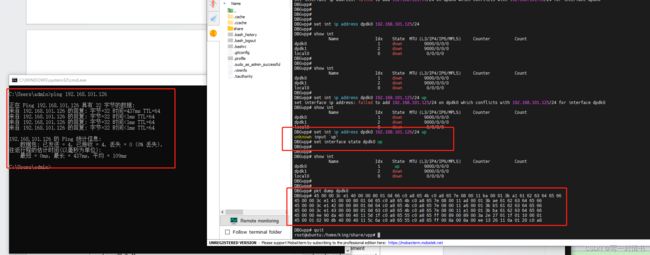
三、VPP-添加一个自定义节点
## vpp 中的重要结构体解析
1.1 _vlib_node_registration
_vlib_node_registration 结构体是 VPP(Vector Packet Processing)中的一个关键结构体,用于在系统中注册和管理节点的信息。它的主要作用如下:
节点函数和处理: _vlib_node_registration 中的 function 字段指向节点的处理函数,定义了节点在数据包处理过程中要执行的操作。
节点名称和索引: name 字段记录了节点的名称,用于在节点图中标识节点。index 字段是由注册系统分配的节点索引,用于唯一标识每个节点。
节点类型和标志: type 字段指定了节点的类型,可以是输入节点、中间节点等。flags 字段包含了节点的一些标志信息,用于控制节点的行为。
错误处理: error_strings 和 error_counters 字段用于记录节点相关的错误字符串和错误计数器,方便错误处理和诊断。
输入和输出: n_next_nodes 和 next_nodes 字段用于定义节点的下一个节点,指示数据包在节点之间的流向。
数据格式和验证: _vlib_node_registration 中包含了格式化、验证等函数指针,用于处理数据包的格式和验证。
节点构造和销毁: _vlib_node_registration 通过构造和析构函数链接成链表,从而实现节点的注册和注销。
总之,_vlib_node_registration 结构体在 VPP 中用于定义、注册和管理节点的信息,帮助实现了节点图的构建和数据包的高效处理。
typedef struct _vlib_node_registration {
vlib_node_function_t *function; /**< 节点处理函数 */
vlib_node_fn_registration_t *node_fn_registrations; /**< 节点函数候选注册 */
char *name; /**< 节点名称 */
char *sibling_of; /**< 兄弟节点名称 */
u32 index; /**< 节点索引 */
vlib_node_type_t type; /**< 节点类型 */
char **error_strings; /**< 与错误代码相关的错误字符串 */
vlib_error_desc_t *error_counters; /**< 与错误代码相关的错误计数器 */
format_function_t *format_buffer; /**< 缓冲区格式化函数 */
unformat_function_t *unformat_buffer; /**< 缓冲区解析函数 */
format_function_t *format_trace; /**< 跟踪格式化函数 */
unformat_function_t *unformat_trace; /**< 跟踪解析函数 */
u8 *(*validate_frame)(struct vlib_main_t *, struct vlib_node_runtime_t *, struct vlib_frame_t *); /**< 帧验证函数 */
void *runtime_data; /**< 节点运行时数据 */
u16 process_log2_n_stack_bytes; /**< 进程堆栈大小的对数 */
u8 runtime_data_bytes; /**< 每个节点运行时数据的字节数 */
u8 state; /**< 节点状态(适用于输入节点) */
u16 flags; /**< 节点标志 */
u8 protocol_hint; /**< 进入分发函数时的协议提示 */
u8 vector_size, aux_size; /**< 标量和矢量参数的大小,以及辅助数据的大小 */
u16 scalar_size; /**< 标量参数的大小 */
u16 n_errors; /**< 使用的错误代码数量 */
u16 n_next_nodes; /**< 后续节点名称的数量 */
struct _vlib_node_registration *next_registration; /**< 下一个注册节点的指针 */
char *next_nodes[]; /**< 后续节点的名称数组 */
} vlib_node_registration_t;
1.2 vlib_frame_t
vlib_frame_t 结构体在 VPP(Vector Packet Processing)中扮演着重要的角色,用于在节点之间传递数据包(packet)并支持高效的数据包处理。其主要作用如下:
数据包传递和传输: vlib_frame_t 结构体用于在节点之间传递数据包。每个 vlib_frame_t 表示一个数据包传递的“帧”,其中包含了要传递的数据包的信息。
帧元数据: 结构体中的成员记录了帧的各种信息,如标量数据、向量数据、辅助数据的偏移量,以及向量中数据包的数量等。
向量数据处理: vlib_frame_t 用于支持向量数据处理。向量中可以包含多个数据包,这样可以在单次处理中同时处理多个数据包,提高处理效率。
帧标志和用户标志: 结构体中的成员用于标识帧的标志和用户自定义标志。这些标志可以用于传递提示或信息给下一个节点。
帧的管理和处理: VPP 使用 vlib_frame_t 进行数据包的处理和传递。在节点处理过程中,从帧中取出数据包,进行处理,然后将数据包放入下一个节点的帧中。
总之,vlib_frame_t 结构体在 VPP 中用于支持数据包的高效传递和处理,是节点之间数据交换的关键元素,帮助实现了 VPP 强大的数据包处理能力
/* Calling frame (think stack frame) for a node. */
typedef struct vlib_frame_t
{
u16 frame_flags; /**< 帧的标志位 */
u16 flags; /**< 用户标志位,用于向下一个节点发送提示或标志信息 */
u16 scalar_offset; /**< 标量数据在帧中的偏移量 */
u16 vector_offset; /**< 向量数据在帧中的偏移量 */
u16 aux_offset; /**< 辅助数据在帧中的偏移量 */
u16 n_vectors; /**< 当前帧中的向量元素数量,即处理的数据包数量 */
u8 arguments[0]; /**< 占位数组,用于存储下一个节点的标量和向量参数 */
} vlib_frame_t;
1.3 vlib_main_t
vlib_main_t 结构体是 VPP(Vector Packet Processing)中的一个关键数据结构,它用于管理整个系统的运行时状态、配置信息和性能统计。具体来说,它的主要作用包括:
时间管理和性能统计: 记录与时间相关的信息,如主循环进入时间、节点调度时间等,以及性能统计数据,如向量数、节点调用次数等。
节点图管理: 维护 VPP 的节点图,包括节点运行时信息、边缘等,以便进行数据包的高效处理。
缓冲区和物理内存管理: 管理缓冲区和物理内存的分配、回收,确保数据包在处理过程中得到有效的管理。
错误处理: 管理错误信息和错误处理函数,以便在发生错误时进行适当的处理。
事件跟踪和日志: 记录和管理节点调用、错误等事件的跟踪信息,以及日志的生成和管理。
控制平面 API: 管理控制平面 API 的队列、信号和回调函数,用于与外部系统进行交互。
多播和随机数管理: 多播相关的流索引分配,以及随机数生成器的种子和缓冲区。
线程和 CPU 信息: 记录当前线程和 CPU 的索引、ID 等信息,用于线程和 CPU 管理。
工作线程回调和屏障同步: 管理工作线程的回调函数,以及用于线程同步的屏障相关信息。
RPC 请求和缓冲区分配: 管理 RPC 请求、缓冲区分配成功的种子和率。
总之,vlib_main_t 结构体在 VPP 中起到了整个系统运行的核心管理和协调作用,负责跟踪和管理系统各个方面的信息,从而实现高效的数据包处理和系统运行
typedef struct vlib_main_t
{
CLIB_CACHE_LINE_ALIGN_MARK (cacheline0); /**< 缓存行对齐标记 */
clib_time_t clib_time; /**< 用于指令级时间计时的数据结构 */
f64 time_offset; /**< 与主线程时间的偏移量,用于计算时间差 */
f64 time_last_barrier_release; /**< 上次屏障释放的时间 */
u64 cpu_time_last_node_dispatch; /**< 上次节点调度的CPU时间戳 */
u64 cpu_time_main_loop_start; /**< 进入主循环时的CPU时间戳 */
volatile u32 main_loop_count; /**< 每个主循环递增的计数,用于统计主循环次数 */
u32 main_loop_vectors_processed; /**< 当前主循环中处理的向量数,用于性能统计 ,以一个数据包为单位*/
u32 main_loop_nodes_processed; /**< 当前主循环中处理的节点数,用于性能统计 */
u64 internal_node_vectors; /**< 内部节点向量数的累计,用于性能统计 */
u64 internal_node_calls; /**< 内部节点调用次数的累计,用于性能统计 */
u64 internal_node_vectors_last_clear; /**< 上次清除内部节点向量数的时间戳 */
u64 internal_node_calls_last_clear; /**< 上次清除内部节点调用次数的时间戳 */
u32 internal_node_last_vectors_per_main_loop; /**< 上次主循环的瞬时向量速率 */
vlib_node_runtime_perf_callback_set_t vlib_node_runtime_perf_callbacks; /**< 节点运行时性能回调集合 */
vlib_node_function_t *dispatch_wrapper_fn; /**< 调度封装函数,用于节点调度 */
u32 main_loop_exit_set; /**< 设置用于退出主循环的跳转目标 */
volatile u32 main_loop_exit_now; /**< 是否立即退出主循环的标志 */
volatile int main_loop_exit_status; /**< 退出进程时返回的状态 */
clib_longjmp_t main_loop_exit; /**< 主循环退出的 longjmp 信息 */
#define VLIB_MAIN_LOOP_EXIT_NONE 0 /**< 无退出 */
#define VLIB_MAIN_LOOP_EXIT_PANIC 1 /**< PANIC 退出 */
#define VLIB_MAIN_LOOP_EXIT_CLI 2 /**< CLI 退出 */
clib_error_t *main_loop_error; /**< 退出主循环时使用的错误标记 */
vlib_buffer_main_t *buffer_main; /**< 缓冲区主结构,用于管理缓冲区 */
vlib_physmem_main_t physmem_main; /**< 物理内存主结构,用于管理物理内存 */
vlib_node_main_t node_main; /**< 节点图主结构,用于管理节点和边缘 */
vlib_trace_main_t trace_main; /**< 包跟踪缓冲区,用于存储跟踪信息 */
vlib_error_main_t error_main; /**< 错误处理主结构,用于管理错误 */
void (*os_punt_frame) (struct vlib_main_t * vm,
struct vlib_node_runtime_t * node,
vlib_frame_t * frame); /**< 用于处理操作系统下无法处理的数据包 */
u32 mc_stream_index; /**< 多播启用时用于分配的流索引 */
uword *worker_init_functions_called; /**< 记录已调用的工作线程初始化函数 */
vlib_one_time_waiting_process_t *procs_waiting_for_mc_stream_join; /**< 等待加入多播组的进程 */
int elog_trace_api_messages; /**< 是否跟踪 API 消息的标志 */
int elog_trace_cli_commands; /**< 是否跟踪 CLI 命令的标志 */
int elog_trace_graph_dispatch; /**< 是否跟踪节点图调度的标志 */
int elog_trace_graph_circuit; /**< 是否跟踪节点图电路的标志 */
u32 elog_trace_graph_circuit_node_index; /**< 跟踪节点图电路时的节点索引 */
elog_event_type_t *node_call_elog_event_types; /**< 节点调用事件类型数组 */
elog_event_type_t *node_return_elog_event_types; /**< 节点返回事件类型数组 */
elog_event_type_t *error_elog_event_types; /**< 错误事件类型数组 */
uword random_seed; /**< 随机数生成器的种子 */
clib_random_buffer_t random_buffer; /**< 随机数据缓冲区 */
u32 thread_index; /**< 线程索引 */
u32 cpu_id; /**< CPU 核心 ID */
u32 numa_node; /**< NUMA 节点索引 */
volatile u32 queue_signal_pending; /**< 控制平面 API 队列信号是否挂起的标志 */
volatile u32 api_queue_nonempty; /**< 控制平面 API 队列是否非空的标志 */
void (*queue_signal_callback) (struct vlib_main_t *); /**< 队列信号回调函数 */
void (**volatile worker_thread_main_loop_callbacks)
(struct vlib_main_t *, u64 t); /**< 工作线程主循环回调函数集合 */
void (**volatile worker_thread_main_loop_callback_tmp)
(struct vlib_main_t *, u64 t); /**< 临时工作线程主循环回调函数集合 */
clib_spinlock_t worker_thread_main_loop_callback_lock; /**< 工作线程主循环回调函数锁 */
volatile int parked_at_barrier; /**< 是否在屏障处等待 */
u64 loops_this_reporting_interval; /**< 本次报告间隔内的循环次数 */
f64 loop_interval_end; /**< 报告间隔结束时的时间 */
f64 loop_interval_start; /**< 报告间隔开始时的时间 */
f64 loops_per_second; /**< 每秒循环次数 */
f64 seconds_per_loop; /**< 每次循环耗时 */
f64 damping_constant; /**< 阻尼常数,用于循环频率计算 */
f64 barrier_epoch; /**< 屏障的时间戳,用于屏障同步 */
f64 barrier_no_close_before; /**< 最早可以再次关闭屏障的时间 */
void (**volatile barrier_perf_callbacks)
(struct vlib_main_t *, u64 t, int leave); /**< 屏障性能回调函数集合 */
void (**volatile barrier_perf_callbacks_tmp)
(struct vlib_main_t *, u64 t, int leave); /**< 临时屏障性能回调函数集合 */
volatile uword check_frame_queues; /**< 是否需要检查帧队列的标志 */
uword *pending_rpc_requests; /**< 待处理的 RPC 请求,仅在主线程中使用 */
uword *processing_rpc_requests; /**< 正在处理的 RPC 请求,仅在主线程中使用 */
clib_spinlock_t pending_rpc_lock; /**< RPC 请求锁 */
u32 buffer_alloc_success_seed; /**< 缓冲区分配成功的种子 */
f64 buffer_alloc_success_rate; /**< 缓冲区分配成功率 */
#ifdef CLIB_SANITIZE_ADDR
void *asan_stack_save; /**< 地址检查器堆栈保存 */
#endif
} vlib_main_t;
1.4 vlib_buffer_t
vlib_buffer_t 结构体在 VPP(Vector Packet Processing)中扮演着关键角色,用于表示和管理数据包的信息。它的作用如下:
数据包存储和表示: vlib_buffer_t 结构体定义了数据包在内存中的存储结构,包括数据、头部、元数据等。它支持灵活的数据包表示,适用于各种数据包处理需求。
缓冲区标志和元数据: 结构体中的成员记录了缓冲区的标志,如是否跟踪、是否是多块缓冲区等。此外,结构体中的 opaque 和 opaque2 数组可以用于存储用户自定义的元数据,以便在数据包处理过程中使用。
数据包处理支持: vlib_buffer_t 结构体支持数据包的链式处理,其中的 next_buffer 字段用于链接多个缓冲区,形成数据包链。这样的链式表示方便了数据包在处理过程中的传递和连接。
数据包引用计数和释放: ref_count 字段用于记录缓冲区的引用计数,确保在多个节点之间传递数据包时能够正确地释放内存,避免资源泄漏。
数据包流标识和错误处理: flow_id 字段用于标识数据包所属的流,方便在数据包处理中进行流级别的操作。error 字段记录了与缓冲区相关的错误信息,用于将错误的数据包传递到错误处理机制。
数据包跟踪和调试: trace_handle 字段用于标识数据包的跟踪句柄,可用于数据包的调试和跟踪。此外,支持在缓冲区中存储数据包的轨迹信息,有助于调试复杂场景。
数据包头部和数据: 结构体中的 pre_data 和 data 成员用于存储数据包的头部和数据内容。pre_data 用于在数据包头部前插入数据,支持数据包重写操作。
SIMD支持: 如果支持SIMD指令集,如SSE、AVX等,结构体中的 as_u8x16、as_u8x32、as_u8x64 成员将用于对缓冲区的数据进行矢量化处理,提高数据包处理性能。
总之,vlib_buffer_t 结构体在 VPP 中用于表示和管理数据包的各种信息,是数据包处理的基本单元,支持高效的数据包传递、处理和管理。
/** VLIB缓冲区表示。 */
typedef union
{
struct
{
CLIB_CACHE_LINE_ALIGN_MARK (cacheline0); /**< 第一个缓存行对齐标记 */
/** 当前正在处理的数据[]、pre_data[]中的有符号偏移量。如果为负,则当前头部指向predata区域。 */
i16 current_data;
/** 当前数据与此缓冲区末尾之间的字节数。 */
u16 current_length;
/** 缓冲区标志:
VLIB_BUFFER_FREE_LIST_INDEX_MASK: 用于存储空闲列表索引的位,
VLIB_BUFFER_IS_TRACED: 跟踪此缓冲区。
VLIB_BUFFER_NEXT_PRESENT: 这是一个多块缓冲区。
VLIB_BUFFER_TOTAL_LENGTH_VALID: 如其所说
VLIB_BUFFER_EXT_HDR_VALID: 缓冲区包含有效的外部缓冲区管理器头部,
设置以避免将其添加到流报告
VLIB_BUFFER_FLAG_USER(n): 用户定义的位N
*/
u32 flags;
/** 通用流标识符 */
u32 flow_id;
/** 该缓冲区的引用计数。 */
volatile u8 ref_count;
/** 缓冲池索引,指示此缓冲区所属的缓冲池。 */
u8 buffer_pool_index;
/** 用于将缓冲区入队到错误处理程序的错误代码。 */
vlib_error_t error;
/** 下一个缓冲区,用于链接缓冲区链表。仅在设置了VLIB_BUFFER_NEXT_PRESENT标志时有效。 */
u32 next_buffer;
/** 以下字段可以在联合中,因为一旦数据包进入punt路径,它就不再位于特性弧上 */
union
{
/** 由特性子图弧使用以访问已启用的特性节点 */
u32 current_config_index;
/* 数据包被punt的原因 */
u32 punt_reason;
};
/** 子图用于其自身目的的不透明数据。 */
u32 opaque[10];
/** 缓冲区元数据的部分,在分配结束时初始化。 */
STRUCT_MARK (template_end);
/** 第二半部分的开始(在缓存行大小为64的系统上是第二个缓存行) */
CLIB_ALIGN_MARK (second_half, 64);
/** 如果设置了VLIB_PACKET_IS_TRACED标志,则指定跟踪缓冲区句柄。 */
u32 trace_handle;
/** 仅对链中的第一个缓冲区有效。当前长度加上此处给出的总长度,给出缓冲区链中的总字节数。 */
u32 total_length_not_including_first_buffer;
/**< 更多不透明数据,见../vnet/vnet/buffer.h */
u32 opaque2[14];
#if VLIB_BUFFER_TRACE_TRAJECTORY > 0
/** 跟踪轨迹数据 - 在编译时将其编译到缓冲区中的特定缓存行中 */
#define VLIB_BUFFER_TRACE_TRAJECTORY_MAX 31
#define VLIB_BUFFER_TRACE_TRAJECTORY_SZ 64
#define VLIB_BUFFER_TRACE_TRAJECTORY_INIT(b) (b)->trajectory_nb = 0
CLIB_ALIGN_MARK (trajectory, 64);
u16 trajectory_nb;
u16 trajectory_trace[VLIB_BUFFER_TRACE_TRAJECTORY_MAX];
#else /* VLIB_BUFFER_TRACE_TRAJECTORY */
#define VLIB_BUFFER_TRACE_TRAJECTORY_SZ 0
#define VLIB_BUFFER_TRACE_TRAJECTORY_INIT(b)
#endif /* VLIB_BUFFER_TRACE_TRAJECTORY */
/** 缓冲区头部余量的开始 */
CLIB_ALIGN_MARK (headroom, 64);
/** 在缓冲区开始之前插入数据的空间。数据包重写字符串将向后重写,可能会扩展到
buffer->data[0] 之前。必须直接位于数据包数据之前。 */
u8 pre_data[VLIB_BUFFER_PRE_DATA_SIZE];
/** 数据包数据 */
u8 data[];
};
#ifdef CLIB_HAVE_VEC128
x16 as_u8x16[4];
#endif
#ifdef CLIB_HAVE_VEC256
u8x32 as_u8x32[2];
#endif
#ifdef CLIB_HAVE_VEC512
u8x64 as_u8x64[1];
#endif
} vlib_buffer_t;
vpp node处理过程中 重要函数解析
2.1vlib_frame_vector_args
vlib_frame_vector_args 是一个内联函数,用于从给定的帧(vlib_frame_t 结构体)中获取数据包的向量数据的起始地址。这个函数在 VPP 中用于从帧中提取数据包的索引数组,以便在数据包处理过程中进行批量处理。
always_inline void *
vlib_frame_vector_args (vlib_frame_t * f)
{
ASSERT (f->vector_offset);
return (void *) f + f->vector_offset;
}
vlib_frame_t *f: 这是一个指向 vlib_frame_t 结构体的指针,表示一个帧,其中存储了要处理的数据包的信息。
ASSERT (f->vector_offset): 这是一个断言语句,用于确保帧的向量偏移量不为零。在 VPP 中,帧的向量偏移量表示数据包向量
数据的位置在帧内的偏移。
return (void *) f + f->vector_offset;: 如果断言成功,此行代码将返回一个指向数据包向量数据的起始地址的指针。它使用帧
的指针 f 加上帧的向量偏移量 f->vector_offset 来计算数据包向量数据的位置,并将其转换为 void * 类型的指针。
总之,vlib_frame_vector_args 函数用于从给定的帧中提取数据包的向量数据的起始地址,以便在数据包处理过程中批量处理多个
数据包。
2.2 vlib_get_next_frame
获取下一个节点的帧和向量,然后将当前节点处理的数据包添加到这个帧中,
以便后续的节点可以处理这些数据包
void vlib_get_next_frame(vlib_main_t *vm,
vlib_node_runtime_t *node,
u32 next_index,
u32 *to_next,
u32 n_left_to_next);
vm: 指向 vlib_main_t 结构体的指针,表示 VPP 的主数据结构,用于管理整个系统的状态和配置信息。
node: 指向 vlib_node_runtime_t 结构体的指针,表示当前节点的运行时信息,包括节点索引、状态等。
next_index: 下一个节点的索引,表示数据包将传递到哪个节点进行进一步处理。
to_next: 一个数组,表示指向下一个节点帧的指针。该数组存储下一个节点要处理的数据包的索引。
n_left_to_next: 表示数组 to_next 中剩余可用的空间数,即下一个节点还能处理多少数据包。
该函数的作用是为下一个节点获取一个帧,用于存储即将传递给下一个节点处理的数据包。它将数据包的索引存储在 to_next 数组
中,并更新剩余空间的计数器 n_left_to_next。在数据包处理过程中,VPP会不断调用这个函数,将数据包传递给下一个节点,直到
帧中的空间用完或数据包处理完成。
这个函数是 VPP 中数据包传递和处理的关键部分,它确保数据包按照正确的流程传递给下一个节点,实现了高效的数据包处理。
2.3 vlib_get_buffer
这个函数的作用是通过缓冲区的索引获取对应的缓冲区指针,以便在数据包处理过程中操作和访问缓冲区的内容
/** \brief 将缓冲区索引转换为缓冲区指针
@param vm - (vlib_main_t *) 指向 vlib 主数据结构的指针
@param buffer_index - (u32) 缓冲区索引
@return - (vlib_buffer_t *) 缓冲区指针
*/
always_inline vlib_buffer_t *
vlib_get_buffer (vlib_main_t * vm, u32 buffer_index)
{
vlib_buffer_main_t *bm = vm->buffer_main;
vlib_buffer_t *b;
b = vlib_buffer_ptr_from_index (bm->buffer_mem_start, buffer_index, 0);
vlib_buffer_validate (vm, b);
return b;
}
vm: 指向 vlib_main_t 结构体的指针,表示 VPP 主数据结构。
buffer_index: 缓冲区的索引,用于在缓冲区池中定位特定的缓冲区。
vlib_buffer_main_t *bm = vm->buffer_main;: 获取缓冲区主结构的指针,通过 vm 指向的主数据结构的 buffer_main 成员。
vlib_buffer_t *b;: 声明一个指向缓冲区的指针。
b = vlib_buffer_ptr_from_index (bm->buffer_mem_start, buffer_index, 0);: 使用 vlib_buffer_ptr_from_index 函数将
缓冲区索引转换为缓冲区指针。buffer_mem_start 表示缓冲区内存的起始位置,buffer_index 是要转换的缓冲区的索引,最后一个
参数为额外的字节偏移量,通常为 0。
vlib_buffer_validate (vm, b);: 对转换后的缓冲区指针进行验证,确保它指向有效的内存区域。
return b;: 返回转换后的缓冲区指针,供调用者使用。
2.4 vlib_buffer_get_current
获取要进行处理的当前数据的指针,以便在数据包处理过程中对数据进行操作和访问。
/** \brief 获取要处理的当前数据的指针
@param b - (vlib_buffer_t *) 缓冲区的指针
@return - (void *) (b->data + b->current_data) 的指针
*/
always_inline void *
vlib_buffer_get_current (vlib_buffer_t * b)
{
/* 检查边界。 */
ASSERT ((signed) b->current_data >= (signed) -VLIB_BUFFER_PRE_DATA_SIZE);
return b->data + b->current_data;
}
b: 指向 vlib_buffer_t 结构体的指针,表示一个缓冲区。
ASSERT ((signed) b->current_data >= (signed) -VLIB_BUFFER_PRE_DATA_SIZE);: 这是一个断言语句,用于检查当前数据的偏
移量是否在合法的范围内。current_data 表示当前数据在缓冲区中的偏移量,而 -VLIB_BUFFER_PRE_DATA_SIZE 表示允许的最小偏
移量(通常是负的预留空间大小)。
return b->data + b->current_data;: 返回一个指向要处理的当前数据的指针,这个指针是通过将缓冲区的数据指针 b->data 与
当前数据的偏移量 b->current_data 相加得到的。
2.5 vlib_validate_buffer_enqueue_x1
这段代码定义了一个宏,用于完成将一个缓冲区在图中向前入队的操作
/** \brief 完成将一个缓冲区在图中向前入队的操作。
标准的单循环模板元素。这是一个宏,具有多个副作用。
在理想情况下,
next_index == next0,
这意味着在单循环的顶部进行的推测性入队已经正确处理了手头的数据包。在这种情况下,宏什么都不做。
@param vm vlib_main_t 指针,根据线程而变
@param node 当前节点的 vlib_node_runtime_t 指针
@param next_index 用于两个数据包的猜测性下一个索引
@param to_next 用于两个数据包的猜测性向量指针
@param n_left_to_next 猜测性向量中剩余的槽数量
@param bi0 第一个缓冲区的索引
@param next0 第一个数据包实际要使用的下一个索引
@return @c next_index -- 用于未来数据包的猜测性下一个索引
@return @c to_next -- 用于未来数据包的猜测性帧
@return @c n_left_to_next -- 猜测性帧中剩余的槽数量
*/
#define vlib_validate_buffer_enqueue_x1(vm,node,next_index,to_next,n_left_to_next,bi0,next0) \
do { \
ASSERT (bi0 != 0); \
if (PREDICT_FALSE (next0 != next_index)) \
{ \
vlib_put_next_frame (vm, node, next_index, n_left_to_next + 1); \
next_index = next0; \
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next); \
\
to_next[0] = bi0; \
to_next += 1; \
n_left_to_next -= 1; \
} \
} while (0)
vm: 指向 vlib_main_t 结构体的指针,表示 VPP 主数据结构。
node: 指向 vlib_node_runtime_t 结构体的指针,表示当前节点。
next_index: 用于两个数据包的猜测性下一个索引,即预测的下一个处理节点的索引。
to_next: 用于两个数据包的猜测性向量指针,表示预测的下一个处理节点的向量数据指针。
n_left_to_next: 猜测性向量中剩余的槽数量,表示预测的下一个处理节点的向量数据中还剩下多少个槽位。
bi0: 第一个缓冲区的索引,即要进行入队操作的缓冲区的索引。
next0: 第一个数据包实际要使用的下一个索引,表示实际的下一个处理节点的索引。
宏的作用是在标准的单循环模板中完成缓冲区的入队操作。如果预测的下一个节点索引与实际的下一个节点索引不相等,宏会先将之前的帧放回到下一个节点,然后获取新的帧,将数据包索引加入其中,并更新相应的信息。
这个宏的目的是优化在循环中的入队操作,以提高数据包处理的效率
添加一个node
当VPP启动时,它会初始化各种组件,包括节点系统。在这个初始化过程中,VPP会遍历全局的节点注册列表,然后调用每个节点的处理函数,从而启动节点的数据包处理逻辑。
这里我们只需要通过VLIB_REGISTER_NODE填充节点信息,vpp启动后就会自动完成初始化工作,关于怎么初始化的流程在另一篇文章VPP启动流程分析
node.function
这里我们只需要通过VLIB_REGISTER_NODE填充节点信息,vpp启动后就会自动完成初始化工作,关于怎么初始化的流程在另一篇文章VPP启动流程分析
VLIB_REGISTER_NODE(ck_sample_node) = {
.name = "ck_sample", /**< 节点名称 */
.function = ck_sample_node_fn, /**< 节点处理函数 */
.vector_size = sizeof(u32), /**< 向量大小,每个元素的大小 */
.format_trace = format_ck_sample_trace, /**< 跟踪格式化函数 */
.type = VLIB_NODE_TYPE_INTERNAL, /**< 节点类型,内部节点 */
.n_errors = ARRAY_LEN(ck_sample_error_strings), /**< 错误字符串数量 */
.error_strings = ck_sample_error_strings, /**< 错误字符串数组 */
.n_next_nodes = CK_SAMPLE_NEXT_N, /**< 后续节点数量 */
.next_nodes = {
[CK_SAMPLE_NEXT_IP4] = "ip4-lookup", /**< 下一步操作为 IP4 查找节点 */
[CK_SAMPLE_DROP] = "error-drop", /**< 下一步操作为丢弃节点 */
},
};
这篇文章只是为了演示添加一个node的过程,node实际功能这里只实现对到来的数据流进行打印每个包的前34个字节
下面是完整的代码,写了注释就不再解释了
pktdump.c
#include 表示这个命令接受一个接口名称作为参数,而 [disable]
表示还可以加上 "disable" 参数
*/
.path = "pkt dump",
.short_help =
"pkt dump [disable]" ,
.function = ck_sample_enable_disable_command_fn,//命令被调用时会执行的函数
};
VLIB_PLUGIN_REGISTER() = {
.version = CK_SAMPLE_PLUGIN_BUILD_VER,
.description = "Sample of VPP Plugin",
};
static clib_error_t *ck_sample_init(vlib_main_t * vm)
{
ck_sample_main.vnet_main = vnet_get_main();
return 0;
}
VLIB_INIT_FUNCTION(ck_sample_init);
VNET_FEATURE_INIT(ck_sample, static) =
{
.arc_name = "ip4-unicast", //特性所属的特性弧名称,指定了特性所在的功能弧,这里为IPv4单播弧(ip4-unicast)。
.node_name = "ck_sample", //特性的节点名称,这里为 "ck_sample"
.runs_before = VNET_FEATURES("ip4-lookup"),//指定在哪个特性之前运行,这里运行在 "ip4-lookup" 特性之前
};
pktdump.h
#ifndef __included_ck_sample_h__
#define __included_ck_sample_h__
#include pktdump_node.c 节点功能在这里
#include 最后可以看到,当运行vpp后,我们已经实现了打印数据包ip头部的功能