【读书笔记->推荐系统】02-01 协同过滤
02-01 协同过滤
思维导图纲要
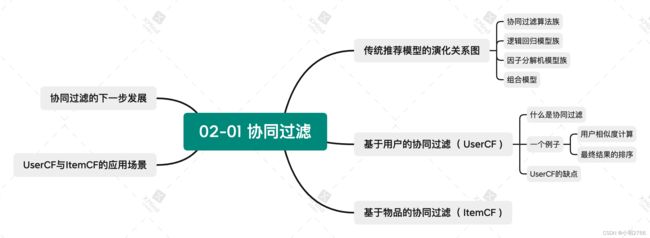
这章主要介绍的是机器学习推荐系统的模型,例如协同过滤( Collaborative Filtering , CF )、逻辑回归( Logistic Regression, LR ), 进化到因子分解机( Factorization Machine, FM )、梯度提升树( Gradient Boosting Decision Tree, GBDT )。
介绍有以下两个原因:
- 传统模型依旧适用很多场景,因为其可解释性强、硬件环境要求低、易于快速训练和部署等优势
- 传统推荐模型是深度学习推荐模型的基础。很多深度学习借鉴了机器学习推荐模型。
传统推荐模型的演化关系图
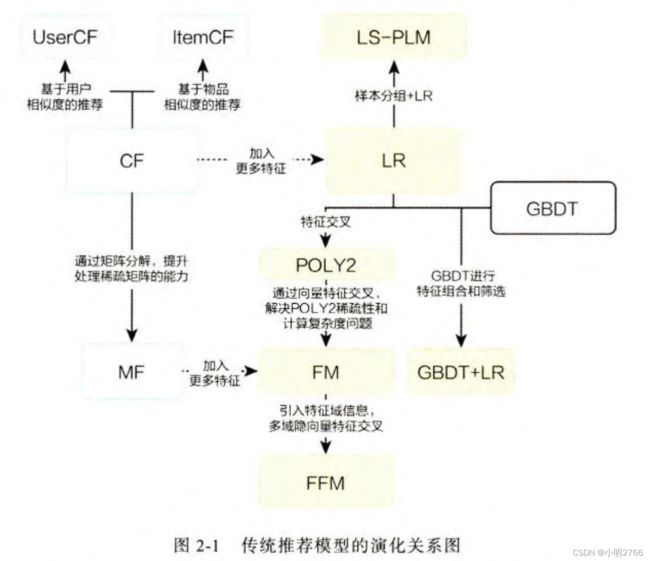
其中主要有以下部分组成。
- 协同过滤算法族。1 协同过滤算法:物品协同过滤、用户协同过滤。2 矩阵分解模型
- 逻辑回归模型族。LR逻辑回归、LS-PLM大规模分片线性模型、FM模型、组合模型等
- 因子分解机模型族。因子分解机、域感知因子分解机
- 组合模型。GBDT梯度提升决策树+LR逻辑回归
基于用户的协同过滤( UserCF )
什么是协同过滤?
这里先对协同过滤给出一个大致介绍。
顾名思义,“协同过滤” 就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。这里用一个商品推荐的例子来说明协同过滤的推荐过程
一个例子
- 电商网站的商品库里一共有 4 件商品:游戏机、某小说、某杂志和某品牌电视机。
- 有一名用户X,为了决定是否推荐电视机给用户X。我们可以利用电商网站上的历史评价数据。图 2-2(b)中用绿色 “点赞”标志表示用户对商品的好评,用红色 “踩”的标志表示差评。可以看到,用户、商品和评价记录构成了带有标识的有向图。
- 为便于计算,将有向图转换成矩阵的形式(被称为 “共现矩阵”),用户作为矩阵行坐标,商品作为列坐标,将“点赞” 和“踩”的用户行为数据转换为矩阵中相应的元素值。这里将“点赞”的值设为 1,将“踩”的值设为-1,“没有数据” 置为 0 ( 如果用户对商品有具体的评分,那么共现矩阵中的元素值可以取具体的评分值,没有数据时的默认评分也可以取评分的均值 )。
- 生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素(图 2-2(d)所示)的值的问题。既然是“协同”过滤,用户理应考虑与自己兴趣相似的用户的意见。因此,预测的第一步就是找到与用户 X 兴趣最相似的n( Top n 用户,这里的n是一个超参数)个用户,然后综合相似用户对“电视机”的评价,得出用户 X对“电视机”评价的预测。
- 从共现矩阵中可知,用户 B 和用户 C 由于跟用户 X 的行向量近似,被选为 Top n ( 这里假设 n 取 2 ) 相似用户,由图 2-2(e)可知,用户 B 和用户 C 对“电视机”的评价都是负面的。
- 相似用户对“电视机”的评价是负面的,因此可预测用户 X 对“电视机”的评价也是负面的。在实际的推荐过程中,推荐系统不会向用户 X 推荐“电视机”这一物品。
以上描述了协同过滤的算法流程,其中关于“用户相似度计算”及“最终结果的排序”过程是不严谨的,下面重点描述这两步的形式化定义。
用户相似度计算
共现矩阵中的行向量代表相应用户的用户向量。那么,计算用户i 和用户 j 的相似度问题,就是计算用户向量i和用户向量y之间的相似度。
两个向量之间常用的相似度计算方法有如下几种。
- 余弦相似度
余弦相似度( Cosine Similarity ) 衡量了用户向量i和用户向量J之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
更详细可以看【推荐系统->相似度算法】余弦相似度。
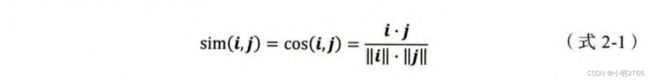
- 皮尔逊相关系数,通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响
待理解知识 ,文末给大家两个参考文献参考

其中, R i , p R_{i,p} Ri,p代表用户i对物品p的评分。 R i ‾ \overline{R_i} Ri代表用户i对所有物品的平均评分,P代表所有物品的集合。
- 基于皮尔逊系数的思路,通过引入物品平均分的方式,减少物品评分偏置对结果的影响
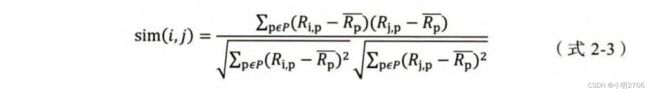
其中, R P ‾ \overline{R_P} RP代表物品p得到所有评分的平均分。
理论上,任何合理的“向量相似度定义方式”都可以作为相似用户计算的标准。
最终结果的排序
假设“目标用户与其相似用户的喜好是相似的”,可根据相似用户的已有评价对目标用户的偏好进行预测。这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。
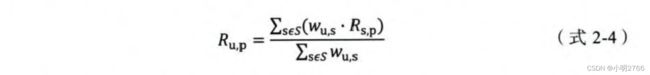
其中,权重 w u , s w_{u,s} wu,s是用户u和用户s的相似度, R S , P R_{S,P} RS,P是用户s对物品p的评分。(个人是这样理解的:分母为权重之和,比如 0.2 + 0.3 + 0.1 + 0.4 0.2+0.3+0.1+0.4 0.2+0.3+0.1+0.4;分子为各个权重乘以相应的评分,比如5分制,4个人分别给了2、3、1、4分, 分 子 = 0.2 ∗ 2 + 0.3 ∗ 3 + 0.1 ∗ 1 + 0.4 ∗ 4 分子=0.2*2+0.3*3+0.1*1+0.4*4 分子=0.2∗2+0.3∗3+0.1∗1+0.4∗4)
在获得用户 U 对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。
以上介绍的协同过滤算法基于用户相似度进行推荐,因此也被称为基于用户的协同过滤( UserCF ),它符合人们直觉上的“兴趣相似的朋友喜欢的物品,我也喜欢”的思想。
UserCF的缺点
- 在互联网应用的场景下,用户数往往远大于物品数,而 UserCF 需要维护用户相似度矩阵以便快速找出 Top 相似用户。该用户相似度矩阵的存储开销非常大,而且随着业务的发展,用户数的增长会导致用户相似度矩阵的空间复杂度以的速度快速增长,这是在线存储系统难以承受的扩展速度。
- 用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的用户来说,找到相似用户的准确度是非常低的,这导致 UserCF 不适用于那些正反馈获取较困难的应用场景( 如酒店预定、大件商品购买等低频应用)。
基于物品的协同过滤( ItemCF )
ItemCF 是基于物品相似度进行推荐的协同过滤算法。通过计算共现矩阵中物品列向量的相似度得到物品之间的相似矩阵,再找到用户的历史正反馈物品的相似物品进行进一步排序和推荐。
ItemCF 的具体步骤如下:
( 1 ) 基于历史数据,构建以用户(假设用户总数为 m ) 为行坐标,物品( 物品总数n) 为列坐标的m x n维的共现矩阵。
( 2 )计算共现矩阵两两列向量间的相似性( 相似度的计算方式与用户相似度的计算方式相同 ),构建维的物品相似度矩阵。
( 3 ) 获得用户历史行为数据中的正反馈物品列表。
( 4 ) 利用物品相似度矩阵,针对目标用户历史行为中的正反馈物品,找出相似的 Top A 个物品,组成相似物品集合。
( 5 )对相似物品集合中的物品,利用相似度分值进行排序,生成最终的推荐列表。
在第 5 步中,如果一个物品与多个用户行为历史中的正反馈物品相似,那么该物品最终的相似度应该是多个相似度的累加,如(式 2-5) 所示。

UserCF与ItemCF的应用场景
- UserCF:其基于用户相似度进行推荐,使其具备更强的社交特性,能够快速得知与自己兴趣相似的人最近喜欢的是什么,即使某个兴趣点以前不在自己的兴趣范围内,也有可能通过“朋友”的动态快速更新自己的推荐列表。这样的特点使其非常适用于新闻推荐场景。因为新闻本身的兴趣点往往是分散的,相比用户对不同新闻的兴趣偏好,新闻的及时性、热点性往往是其更重要的属性,而 UserCF 正适用于发现热点,以及跟踪热点的趋势。
- ItemCF:更适用于兴趣变化较为稳定的应用,比如在 Amazon 的电商场景中,用户在一个时间段内更倾向于寻找一类商品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在 Netflix 的视频推荐场景中,用户观看电影、电视剧的兴趣点往往比较稳定,因此利用 ItemCF 推荐风格、类型相似的视频是更合理的选择。
协同过滤的下一步发展
协同过滤无法将两个物品相似这一信息推广到其他物品的相似性计算上。这就导致了一个比较严重的问题一热门的物品具有很强的头部效应,容易跟大量物品产生相似性;而尾部的物品由于特征向量稀疏,很少与其他物品产生相似性,导致很少被推荐。
为解决上述问题,同时增加模型的泛化能力,矩阵分解技术被提出。该方法在协同过滤共现矩阵的基础上,使用更稠密的隐向量表示用户和物品,挖掘用户和物品的隐含兴趣和隐含特征,在一定程度上弥补了协同过滤模型处理稀疏矩阵能力不足的问题。
另外,协同过滤仅利用用户和物品的交互信息,无法有效地引人用户年龄、性别、商品描述、商品分类、当前时间等一系列用户特征、物品特征和上下文特征,这无疑造成了有效信息的遗漏。为了在推荐模型中引入这些特征,推荐系统逐渐发展到以逻辑回归模型为核心的、能够综合不同类型特征的机器学习模型的道路上。
参考文献
- 期望、方差、协方差
- 皮尔逊相关系数丨Pearson’s correlation coefficient