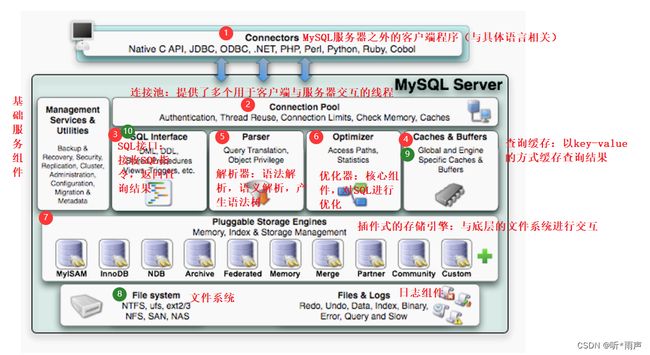
MySQL
MySQL的服务器模型采用的是I/O复用+可伸缩的线程池(select+线程池),是实现网络服务器的经典模型
众所周知epoll的性能是比select的性能好太多的。但是为什么Mysql使用select而不使用epoll呢?
答:mysql进行数据操作的时候不仅仅是在内存中,还涉及磁盘IO。磁盘IO是很慢的,因此就涉及到网络IO接收请求特别快,数据操作涉及磁盘IO是却很慢,db层业务处理很慢。因此网络层效率不需要很高,只需要网络IO和磁盘IO匹配上就可以。
1.Mysql数据类型
12_MySQL数据类型
简单的理解就是,数据类型只要能存下数据就可以,选择越大越好,不容易出错,但是真真正正做后台开发的时候,业务层一般都是在内存上工作的,效率速度很快,最先达到性能瓶颈的一般都是数据库,因为数据库涉及磁盘IO操作,而磁盘IO速度较慢。因此在定义表结构的时候,每一个字段的数据类型就至关重要。
磁盘IO次数少,意味着效率,性能高
2.表的设计
10_创建和管理表
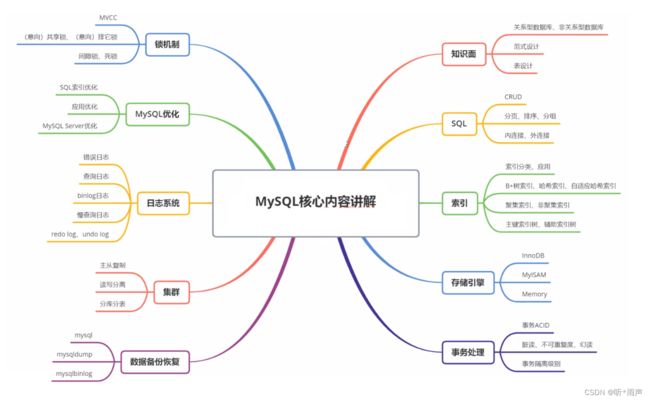
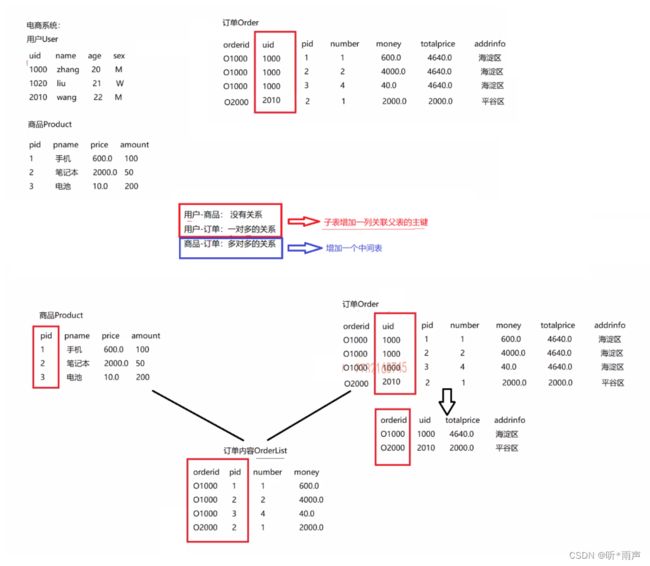
一张表就对应一个实体,表与表的关系就是实体与实体的关系,实体间的关系有三种:
-
一对一
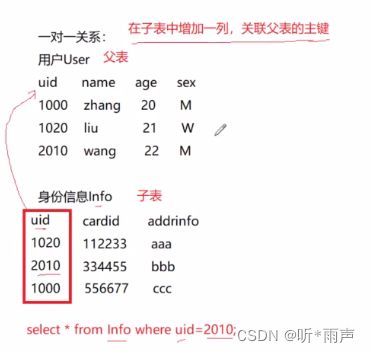
-
一对多
-
多对多
3.范式设计
11_数据库的设计规范
使用最简洁的表述指导了我们在设计表结构的时候所遵守的规则。
一对一,一对多,多对多是告诉我们怎么样去产生表与表之间的关联,不产生数据冗余。遵循范式设计目的也是减少数据冗余
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
- 1)减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
- 2)消除异常(插入异常,更新异常,删除异常)
- 3)让数据组织的更加和谐
但是数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就越大,SQL的效率就变低。
第一范式
每一列保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。
例如表中的地址字段,可以再细分为省,市,区等不可再分割(即原子特性)的字段
第二范式
属性完全依赖于主键-主要针对联合主键
非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
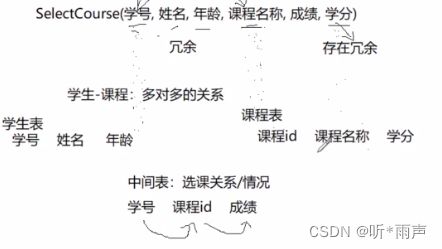
例如:选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合
第二范式。
第三范式
属性不依赖于其它非主属性
要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
示例:学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),学号是主键,但是学院电话只依赖于所在学院,并不依赖于主键学号,因此该设计不符合第三范式,应该把学院专门设计成一张表,学生表和学院表,两个是一对多的关系。
注意:一般关系型数据库满足第三范式就可以了。
遵循范式就意味着拆分为更多的表,就表明业务操作的时候需要多表查询,多表查询就是再优化也比单表查询效率低。所以某些时候在业务上为了提高效率会增加冗余字段
因此在性能允许的情况下,杜绝冗余存储。因为冗余存储会产生更新异常,删除异常等等
BC范式
每个表中只有一个候选键
简单的说,BC范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的noNF表(上面图3)中可以看出,每一个员工的email都是唯一的(不可能两个人用同一个email),则此表不符合BC范式,
第四范式
消除表中的多值依赖
简单来说,第四范式就是要消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。比如图4中的noNF表中的skill技能这个字段,有的人是“java,mysql”,有的人描述的是“Java,MySQL”,这样数据就不一致了,解决办法就是将多值属性放入一个新表
4.SQL分类
MySQL的逻辑架构
SQL查询的次数远远大于增加和删除的次数,单表的查询,多表的查询,带in的子查询,多表的有内连接查询,外连接的左连接查询,外连接的右连接查询,查询时是如何写SQL语句的?注意些什么?SQL语句写出来的效率怎么样?给多表联合查询的SQL加一些索引,该如何加?如何分析有没有使用到索引?效率究竟如何?如何优化SQL?如何优化索引?
SQL语言在功能上主要分为如下3大类:
- DDL (Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。
主要的语句关键字包括CREATE、DROP、ALTER等。
CREATE:从无到有的去建立一个东西。建表,建库…
ALTER:修改表(增加一个列,删除一个列…
DROP:删除一个表结构…
RENAME:重命名一个表
TRUNCATE:清空一个表,但是表结构还在
- DML (Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。
主要的语句关键字包括INSERT、DELETE、UPDATE、SELECT 等。SELECT是SQL语言的基础,最为重要。
INSERT:插入一条记录
DELETE(区别DROP):删除一条记录
UPDATE:原有记录上修改记录
SELECT :查询操作
- DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。
主要的语句关键字包括GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等。
控制语言:控制操作
COMMIT(针对事务):提交操作。修改记录后紧接着进行提交操作后,对数据库的修改就是永久性的
ROLLBACK(针对事务):撤销操作,回滚。
SAVEPOINT:回滚到具体的保存点上
GRANT:赋予相应的权限
REVOKE:回收相应的权限
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。
还有单独将COMMIT、ROLLBACK取出来称为TCL (Transaction Control Language,事务控制语言)。
4.1 一条SQL的执行顺序
SQL的执行原理
08_聚合函数- 4

4.2 单次SQL和多次SQL的效率区别
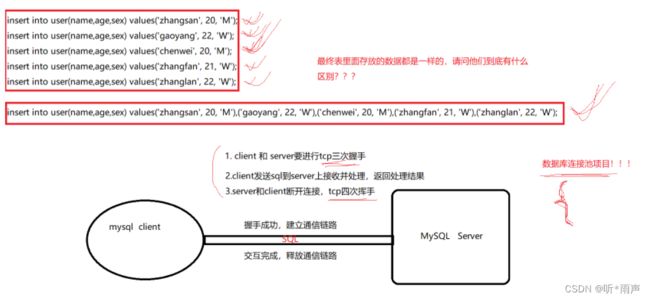
4.3 select后面出现的列
select后面出现的列需要具体问题具体分析,涉及到SQL优化和索引优化,是否存在回表
4.4 limit只是限制select显式的结果还是对查询效率有影响?


select对于后面的列,如果该列有索引,那么查表就不是全表扫描,反之如果该列没有索引,则会进行全表扫描,对于一张存储有成千上百万行的表进行全表扫描效率是极低的,因此加limit后,mysql服务器会对sql进行优化,查询的行就不是全表扫描,效率也会提升很多。
explain是不解释mysql服务器的优化操作的,对于limit的优化,explain同样表现不出来,但是效率的的确确是提高了
4.5 limit分页操作

4.6 order by
08_聚合函数-2

order by的字段涉及外排序(常见的8大排序都是内存数据的排序,简称内排序),磁盘IO,效率太低了,需要进行优化。
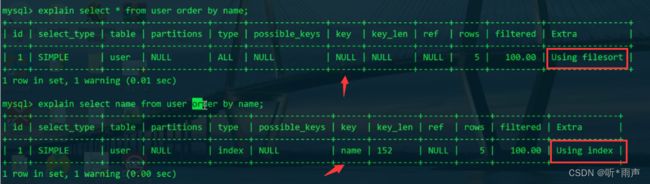
可见使用索引列和不使用索引列进行排序,效率是不一样的
order by SQL优化?
回答:某某业务使用到了order by,发现数据量一多效率非常低。使用explain分析了SQL语句,发现在Extra列有 Using filesort,是一个外排序,涉及磁盘IO,数据量较大,一次性无法全部放入内存,所以比较慢。故就需要优化了。首先对order by的字段加索引,其次还得考虑select选择哪些列也有关系,因为这个涉及到SQL语句回不回表查询。
4.7 group by
08_聚合函数-2


group by会自动按照需要分组的列进行排序。刚开始优化SQL语句的时候我认为group by不是order by,觉得它不涉及排序,但是实际上使用explain进行查看的时候Extra里面也显式了 Using filesort,还显式了Using temporary,创建了临时表,group by根据分组的数据放在临时表里面排序 。因此group by默认就order by了。所以group by后面的字段加索引也是很有必要的
4.8 DCL中COMMIT与ROLLBACK的使用

4.9 TRUNCATE TABLE or DELETE FROM ?
一张表,表中的数据全部都不想要了,问此时是应该使用TRUNCATE TABLE还是使用DELETE FROM? why?
首先这两个操作都可以实现表数据的全部删除。TRUNCATE TABLE不能实现回滚,使用DELETE FROM可以实现回滚。以回滚和不能回滚为代表就是该操作后台占用资源的多少;
TRUNCATE TABLE每一次清除表数据后根本不考虑是否要进行回滚,该操作默认就是不能回滚的,所以在数据删除的同时不会进行备份,所以使用的系统资源和事务日志资源比较少;DELETE FROM一边删除,一边还得考虑回滚,数据删除的同时要进行备份,以防用户进行回滚操作,所以使用的系统资源和事务日志资源比较多。所以从资源使用上来说TRUNCATE TABLE是优于DELETE FROM的,更加节省资源。但是实际开发场景中使用TRUNCATE TABLE是极有可能造成事故的,在一张表没有做备份的情况下使用TRUNCATE TABLE是真的就没有的,所以和造成事故相比,占用点资源是小事。所以实际开发中使用DELETE FROM 更为稳妥。
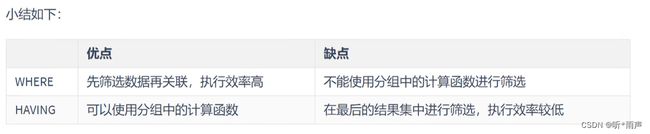
4.10 WHERE和HAVING的对比?
08_聚合函数-3
- 从适用范围上来讲,HAVING的适用范围更广。
- 如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING


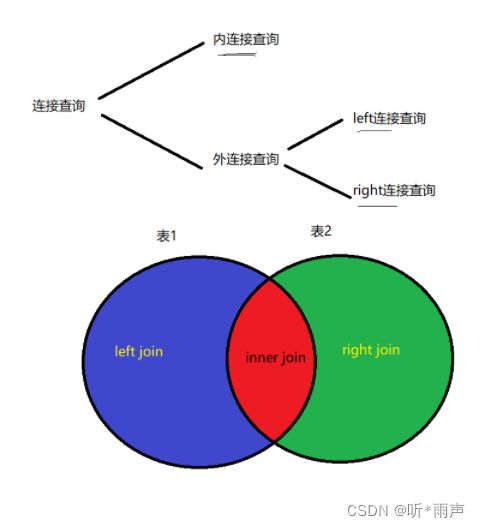
5.连接查询
06_多表查询
6.MySQL存储引擎
05_存储引擎
创建一张表里面有三个东西需要存储:表的结构;数据;索引
怎么存储,存储方式是什么这就是存储引擎直接影响的
MyISAM不支持事务、也不支持外键,索引采用非聚集索引,其优势是访问的速度快,对事务完整性没有要求,以 SELECT、INSERT 为主的应用基本上都可以使用这个存储引擎来创建表。MyISAM的表在磁盘上存储成 3 个文件,其文件名都和表名相同,扩展名分别是:-
- .frm(存储表定义)
-
- .MYD(MYData,存储数据)
-
- .MYI (MYIndex,存储索引)
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,支持自动增长列,外键等功能, 索引采用聚集索引,索引和数据存储在同一个文件,所以InnoDB的表在磁盘上有两个文件,其文件名 都和表名相同,扩展名分别是:-
- .frm(存储表的定义)
-
- .ibd(存储数据和索引)
MEMORY存储引擎使用存在内存中的内容来创建表。每个MEMORY 表实际只对应一个磁盘文件,格式是.frm(表结构定义)。MEMORY 类型的表访问非常快,因为它的数据是放在内存中的,并且默认使用 HASH 索引(不适合做范围查询),但是一旦服务关闭,表中的数据就会丢失掉。

15_ 锁
- 锁机制:表示数据库在并发请求访问的时候,多个事务在操作时,并发操作的粒度。
- B-树索引和哈希索引:主要是加速SQL的查询速度。
- 外键:子表的字段依赖父表的主键,设置两张表的依赖关系。
- 事务:多个SQL语句,保证它们共同执行的原子操作,要么成功,要么失败,不能只成功一部分,失败需要回滚事务。
- 索引缓存和数据缓存:和MySQL Server的查询缓存相关,在没有对数据和索引做修改之前,重复查询可以不用进行磁盘I/O(数据库的性能提升,目的是为了减少磁盘I/O操作来提升数据库访问效率),读取上一次内存中查询的缓存就可以了。
7.索引
10_索引优化与查询优化
当表中的数据量到达几十万甚至上百万的时候,SQL查询所花费的时间会很长,导致业务超时出错,此时就需要用索引来加速SQL查询。
由于索引也是需要存储成索引文件的,因此对索引的使用也会涉及磁盘I/O操作。如果索引创建过多,使用不当,会造成SQL查询时,进行大量无用的磁盘I/O操作,降低了SQL的查询效率,适得其反,因此掌握良好的索引创建原则非常重要!
7.1 索引分类
06_索引的数据结构
索引是创建在表上的,是对数据库表中一列或者多列的值进行排序的一种结果。索引的核心是提高查询的速度!
物理上(聚集索引&非聚集索引)/逻辑上(…)
索引的优点: 提高查询效率
索引的缺点: 索引并非越多越好,过多的索引会导致CPU使用率居高不下,由于数据的改变,会造成索引文件的改动,过多的磁盘I/O造成CPU负荷太重
1、普通索引:(二级索引)没有任何限制条件,可以给任何类型的字段创建普通索引(创建新表&已创建表,数量是不限的,一张表的一次sql查询只能用一个索引 where a=1 and b=‘M’)
2、唯一性索引:使用UNIQUE修饰的字段,值不能够重复,主键索引就隶属于唯一性索引,主键索引和唯一性索引都是一级索引(聚簇索引)
3、主键索引:使用Primary Key修饰的字段会自动创建索引(MyISAM不会自动创建,因为索引和数据是分开存放的; InnoDB会自动创建索引树,在索引树上面存放数据)
4、单列索引:在一个字段上创建索引
5、多列索引:在表的多个字段上创建索引 (uid+cid,多列索引必须使用到第一个列,才能用到多列索引,否则索引用不上)
6、全文索引:使用FULLTEXT参数可以设置全文索引,只支持CHAR,VARCHAR和TEXT类型的字段上,常用于数据量较大的字符串类型上,可以提高查询速度(线上项目支持专门的搜索功能,给后台服务器增加专门的搜索引擎支持快速高效的搜索 elasticsearch 简称es C++开源的搜索引擎 搜狗的workflow)
7.2 索引创建和删除
08_索引的创建与设计原则
创建表的时候指定索引字段:
CREATE TABLE index1(id INT,
name VARCHAR(20),
sex ENUM('male', 'female'),
INDEX(id,name));
在已经创建的表上添加索引:
CREATE [UNIQUE] INDEX 索引名 ON 表名(属性名(length) [ASC | DESC]);
删除索引:
DROP INDEX 索引名 ON 表名;
索引可能会出问题的点
1.经常作为where条件过滤的字段考虑添加索引
2.字符串列创建索引时,尽量规定索引的长度,而不能让索引值的长度key_len过长
3.索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了
给字段加索引,索引一定可以使用到吗?
如果通过索引找出来的数据量和全局扫描表找出来的数据量差不多,还不如做整表的搜索。因为使用索引的话首先得读索引文件花费磁盘IO,还得扫描索引树,如果数据一次取不完,最终还得去表里取数据。因此给字段加索引,但是以这个字段作为过滤条件,索引不一定会使用到。因为mysql server 会做优化。其次索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了



explain结果字段分析
- select_type
simple:表示不需要union操作或者不包含子查询的简单select语句。有连接查询时,外层的查询为simple且只有一个。
primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary且只有一个。
union:union连接的两个select查询,除了第一个表外,第二个以后的表的select_type都是union。
union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null。 - table
显示查询的表名;
如果不涉及对数据库操作,这里显示null;
如果显示为尖括号就表示这是个临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生的;
如果是尖括号括起来也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集; - type
const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type就是const。
ref:常见于辅助索引的等值查找,或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找会出现;返回数据不唯一的等值查找也会出现。
range:索引范围扫描,常见于使用<、>、is null、between、in、like等运算符的查询中。
index:索引全表扫描,把索引从头到尾扫一遍;常见于使用索引列就可以处理不需要读取数据文
件的查询,可以使用索引排序或者分组的查询。
all:全表扫描数据文件,然后在server层进行过滤返回符合要求的记录。 - ref
如果使用常数等值查询,这里显示const;
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段; - Extra
-
- using filesort:排序时无法用到索引,常见于order by和group by语句中。
-
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
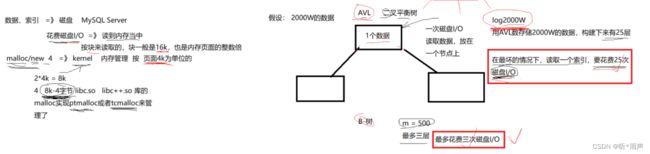
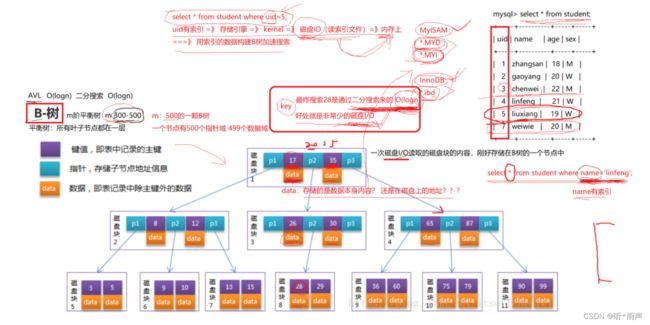
7.3 索引的底层原理
06_索引的数据结构
B树


B+树
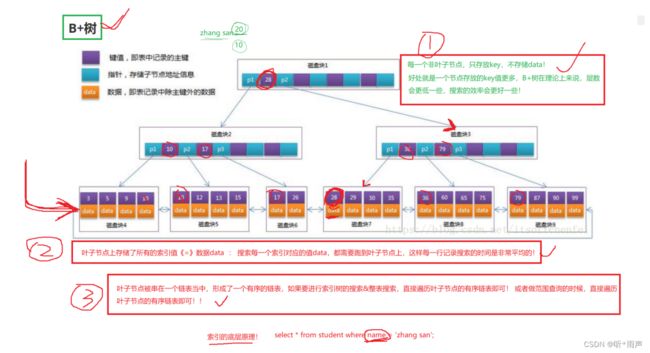
索引的底层原理话术?
通过select对一张表进行搜索时,如果加了过滤条件。mysql server是会先检测该字段有没有索引,没有索引就使用整表搜索,效率是最差的;如果有索引,底层操作系统会从磁盘索引文件中将索引数据加载到内存上,使用B+树进行构建索引,为什么使用B+树呢?因为B+树是一棵M叉的平衡树,搜索的效率是非常好的;而且B+树是一个节点一个节点构建的,一个节点的大小刚好对应一次磁盘IO加载数据块的大小,非叶子节点存放的都是Key,而所有的数据都在存放在叶子节点的,所以使用B+树构建索引内容会以花费最少的磁盘IO的次数,以二分搜索的时间复杂度log2(n)来找到所要查询的数据。
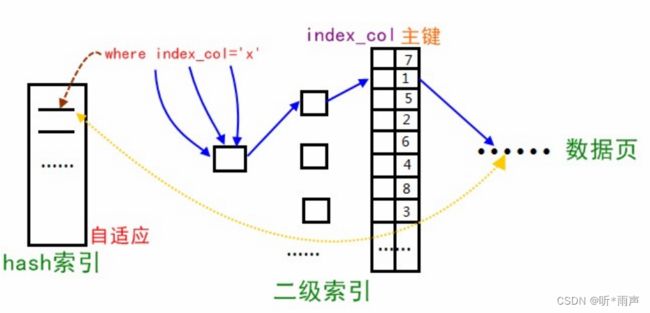
7.4主键索引和二级索引
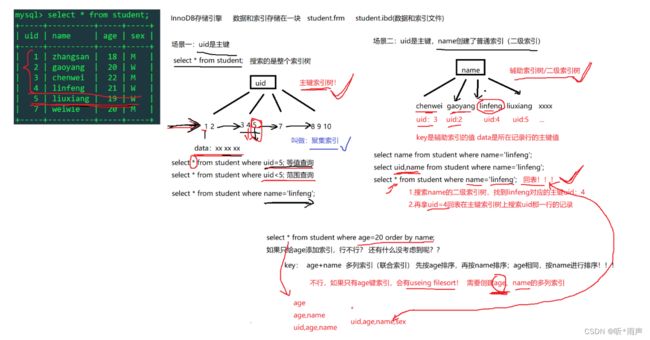
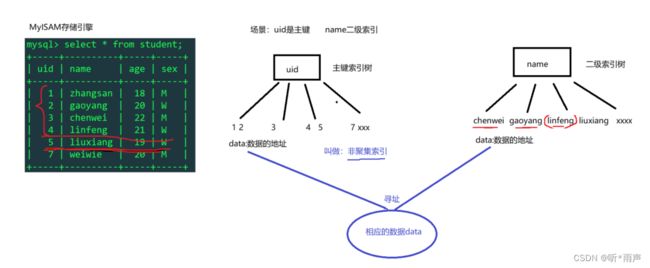
7.5 聚簇索引与非聚簇索引
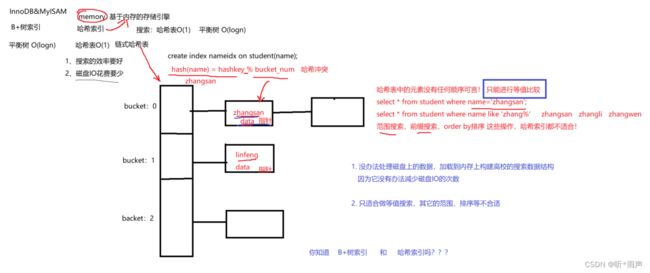
7.6 哈希索引
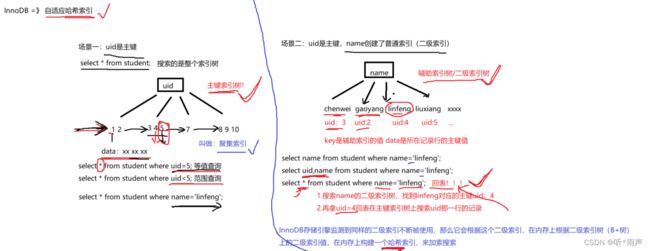
7.7 InnoDB自适应哈希索引
自适应:不是自己创建的而是自动优化的功能,为了加速搜索。相当于是对B+树上频繁使用二级索引搜索,并且进行回表操作的优化

7.8 当你被问道:SQL和索引的优化问题时,怎么切入???
回答:使用explain分析相应的SQL,就知道索引有没有被使用,或者没有建索引需要加索引,看是加主键索引,联合索引还是二级索引结合有没有分组排序 ,是否有where又有分组排序就要考虑是不是要加联合索引;对于涉及到Using filesort的SQL肯定是需要优化的。真真正正的项目涉及到很多的业务,有各种各样的SQL千万条,实际工作中不可能对每一条SQL进行explain啊?

10_索引优化与查询优化
索引和慢查询日志
09_性能分析工具的使用
MySQL可以设置慢查询日志,当SQL执行的时间超过我们设定的时间,那么这些SQL就会被记录在慢查询日志当中,然后我们通过查看日志,用explain分析这些SQL的执行计划,来判定为什么效率低下,是没有使用到索引?还是索引本身创建的有问题?或者是索引使用到了,但是由于表的数据量太大,花费的时间就是很长,那么此时我们可以把表分成n个小表,比如订单表按年份分成多个小表等。
慢查询日志相关的参数如下所示:
mysql> show variables like '%slow_query%';
+---------------------+-------------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /usr/local/mysql/data/LeideMacBook-Pro-slow.log |
+---------------------+-------------------------------------------------+
2 rows in set (0.00 sec)
8.事务
13_事务
14_MySQL事务日志
8.1事务概念
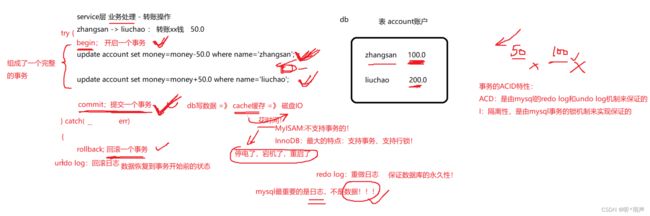
一个事务是由一条或者多条对数据库操作的SQL语句所组成的一个不可分割的单元,只有当事务中的所有操作都正常执行完了,整个事务才会被提交给数据库;如果有部分事务处理失败,那么事务就要回退到最初的状态,因此,事务要么全部执行成功,要么全部失败。所以记住事务的几个基本概念,如下:
- 1、事务是一组SQL语句的执行,要么全部成功,要么全部失败,不能出现部分成功,部分失败的结果。保证事务执行的原子操作。
- 2、事务的所有SQL语句全部执行成功,才能提交(commit)事务,把结果写回磁盘上。
- 3、事务执行过程中,有的SQL出现错误,那么事务必须要回滚(rollback)到最初的状态
8.2 ACID特性
13_事务-1.3
每一个事务必须满足下面的4个特性:
- 事务的原子性(Atomic):
事务是一个不可分割的整体,事务必须具有原子特性,及当数据修改时,要么全执行,要么全不执行,即不允许事务部分的完成。 - 事务的一致性(Consistency):
一致性表现为事务的执行对数据的影响
一个事务执行之前和执行之后,数据库数据必须保持一致性状态。数据库的一致性状态必须由用户来负责,由并发控制机制实现。就拿网上购物来说,你只有让商品出库,又让商品进入顾客的购物车才能构成一个完整的事务。 - 事务的隔离性(Isolation):
当两个或者多个事务并发执行时,为了保证数据的安全性,将一个事物内部的操作与其它事务的操作隔离起来,不被其它正在执行的事务所看到,使得并发执行的各个事务之间不能互相影响。 - 事务的持久性(Durability):
事务完成(commit)以后,DBMS保证它对数据库中的数据的修改是永久性的,即使数据库因为故障出错,也应该能够恢复数据!
事务的隔离性由锁机制实现。而事务的原子性、一致性和持久性由事务的 redo 日志和undo 日志来保证。
8.3 事务并发存在的问题
13_事务-3.1
事务处理不经隔离,并发执行事务时通常会发生以下的问题:
脏读(Dirty Read):一个事务读取了另一个事务未提交的数据。例如当事务A和事务B并发执行时,当事务A更新后,事务B查询读取到A尚未提交的数据,此时事务A回滚,则事务B读到的数据就是无效的脏数据。(事务B读取了事务A尚未提交的数据)不可重复读(NonRepeatable Read):一个事务的操作导致另一个事务前后两次读取到不同的数据。例如当事务A和事务B并发执行时,当事务B查询读取数据后,事务A更新操作更改事务B查询到的数据,此时事务B再次去读该数据,发现前后两次读的数据不一样。(事务B读取了事务A已提交的数据)虚读(Phantom Read)幻读:一个事务的操作导致另一个事务前后两次查询的结果数据量不同。例如当事务A和事务B并发执行时,当事务B查询读取数据后,事务A新增或者删除了一条满足事务B查询条件的记录,此时事务B再去查询,发现查询到前一次不存在的记录,或者前一次查询的一些记录不见了。(事务B读取了事务A新增加的数据或者读不到事务A删除的数据)
SELECT @@AUTOCOMMIT; 查看MySQL是否自动提交事务
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
8.4 隔离级别
13_事务-3.2
为什么要考虑事务的隔离级别,因为事务要并发执行。如果并发执行啥也不考虑安全性就堪忧,如果不考虑安全性就存在脏读,不可重复读,幻读等等,是全部都允许出现,还是全部都不允许出现,实际上是有的允许出现,有的不允许出现。对于不同程度上的出现或者不能出现的并发控制,才有了不同的隔离级别。
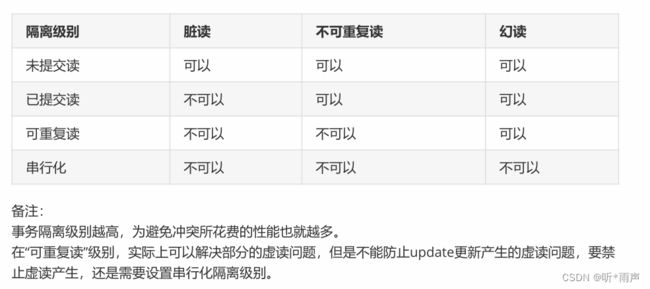
MySQL支持的四种隔离级别是:
1、TRANSACTION_READ_UNCOMMITTED。未提交读。说明在提交前一个事务可以看到另一个事务的变化。这样读脏数据,不可重复读和虚读都是被允许的。2、TRANSACTION_READ_COMMITTED。已提交读。说明读取未提交的数据是不允许的。这个级别仍然允许不可重复读和虚读产生。3、TRANSACTION_REPEATABLE_READ。可重复读。说明事务保证能够再次读取相同的数据而不会失败,但虚读仍然会出现。4、TRANSACTION_SERIALIZABLE。串行化。是最高的事务级别,它防止读脏数据,不可重复读和虚读。
16_多版本并发控制(MVCC)
9. 锁
15_ 锁

9.1 排它锁和共享锁
- 排它锁(Exclusive),又称为X 锁,写锁。
- 共享锁(Shared),又称为S 锁,读锁。
X和S锁之间有以下的关系: SS可以兼容的,XS、SX、XX之间是互斥的一个事务对数据对象 O 加了 S 锁,可以对 O 进行读取操作但不能进行更新操作。加锁期间其它事务能对O 加 S 锁但不能加 X 锁。
一个事务对数据对象 O 加了 X 锁,就可以对 O 进行读取和更新。加锁期间其它事务不能对 O 加任何锁。
显示加锁:select … lock in share mode强制获取共享锁,select … for update获取排它锁
9.2 InnoDB行级锁
InnoDB存储引擎支持事务处理,表支持行级锁定,并发能力更好。
- 1、
InnoDB行锁是通过给索引上的索引项加锁来实现的,而不是给表的行记录加锁实现的,这就意味着只有通过索引条件检索数据,InnoDB才使用行级锁,否则InnoDB将使用表锁。 - 2、由于InnoDB的行锁实现是针对索引字段添加的锁,不是针对行记录加的锁,因此虽然访问的是InnoDB引擎下表的不同行,但是如果使用相同的索引字段作为过滤条件,依然会发生锁冲突,只能串行进行,不能并发进行。
- 3、即使SQL中使用了索引,但是经过MySQL的优化器后,如果认为全表扫描比使用索引效率更高,此时会放弃使用索引,因此也不会使用行锁,而是使用表锁,比如对一些很小的表,MySQL就不会去使用索引。
9.3 串行化-》间隙锁解决幻读问题
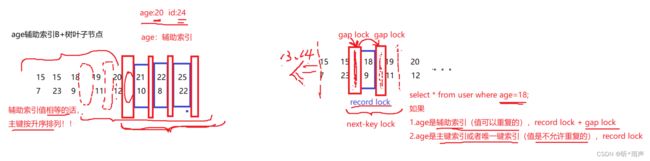
间隙锁是给不存在的记录加锁,不存在的记录存在一个范围,这个范围怎么找
范围查询时,对于范围内的行加行锁,对于行与行,以及范围内的间隙都会加间隙锁
等值查询时,等值的行加行锁,和该行相邻的间隙也会加间隙锁
间隙锁一般适应于辅助索引,因为辅助索引的值可以重复,存在幻读可能。对于主键索引是不允许重复的,即便插入相同的主键索引值,不需要锁,SQL语法识别时就会判断出错误。因此主键索引加行锁就可以。

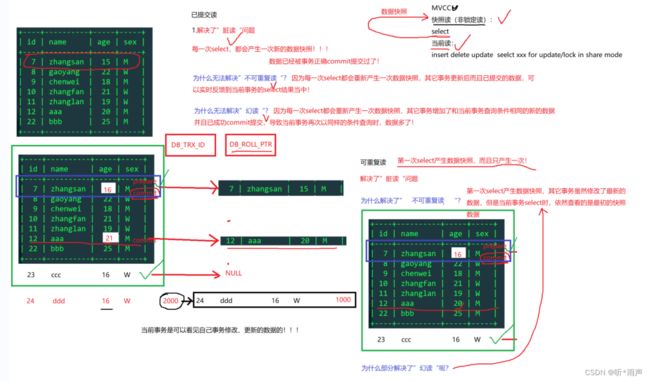
9.4 可重复读-》MVCC解决幻读问题
16_多版本并发控制(MVCC)

MVCC是多版本并发控制(Multi-Version Concurrency Control,简称MVCC),是MySQL中基于乐观锁理论实现隔离级别的方式,用于实现已提交读和可重复读隔离级别的实现,也经常称为多版本数据库。MVCC机制会生成一个数据请求时间点的一致性数据快照 (Snapshot), 并用这个快照来提供一定级别 (语句级或事务级) 的一致性读取。从用户的角度来看,好象是数据库可以提供同一数据的多个版本(系统版本号和事务版本号)。
MVCC多版本并发控制中,读操作可以分为两类:
1、快照读(snapshot read)读的是记录的可见版本,不用加锁。如select
2、当前读(current read)读取的是记录的最新版本,并且当前读返回的记录。如insert,delete,update,select…lock in sharemode/for update
已提交读: 每次执行语句的时候都重新生成一次快照(ReadView),每次select查询时。
可重复读: 同一个事务开始的时候生成一个当前事务全局性的快照(Read View),第一次select查询时。
快照内容读取原则:
1、版本未提交无法读取生成快照
2、版本已提交,但是在快照创建后提交的,无法读取
3、版本已提交,但是在快照创建前提交的,可以读取
4、当前事务内自己的更新,可以读到
怎么通过undo log来提供MVCC的非锁定读?
14_MySQL事务日志-2 undo log
MVCC会给插入的数据增加与MVCC快照读相关的列,一个是事务ID,表明是那一个事务对当前数据做的修改;一个是指针,指针指向该数据修改前的数据版本。当前位置放的肯定是最新的修改后的数据,之前的数据会形成一个版本链,放在undo log中。所以从当前行就可以访问到之前的数据,进行回滚就是理所当然的。


9.5 InnoDB表级锁
在绝大部分情况下都应该使用行锁,因为事务和行锁往往是选择InnoDB的理由,但个别情况下也使用表级锁;
1)事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间等待和锁冲突;
2)事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。
如:
LOCK TABLE user READ;读锁锁表
LOCK TABLE user WRITE; 写锁锁表
事务执行…
COMMIT/ROLLBACK; 事务提交或者回滚
UNLOCK TABLES; 本身自带提交事务,释放线程占用的所有表锁

意向锁要解决什么问题?
意向共享锁(IS锁):事务计划给记录加行共享锁,事务在给一行记录加共享锁前,必须先取得该表的IS 锁。
意向排他锁(IX锁):事务计划给记录加行排他锁,事务在给一行记录加排他锁前,必须先取得该表的IX 锁。
意向共享锁和意向排它锁都是针对使用表锁时这张表(1千万)里面得数据没有被其它事务获取过行锁X锁!,因为表中的数据很多,对于其中一行是否加行锁进行判断,效率太低了。因此事务计划给记录加行共享锁,事务在给一行记录加共享锁前,必须先取得该表的IS 锁;事务计划给记录加行排他锁,事务在给一行记录加排他锁前,必须先取得该表的IX 锁。

9.6 死锁
两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。
MyISAM 表锁是 deadlock free 的, 这是因为 MyISAM 总是一次获得所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。但在 InnoDB 中,除单个 SQL 组成的事务外,锁是逐步获得的,即锁的粒度比较小,这就决定了在 InnoDB 中发生死锁是可能的。
死锁问题一般都是我们自己的应用造成的,和多线程编程的死锁情况相似,大部分都是由于我们多个线程在获取多个锁资源的时候,获取的顺序不同而导致的死锁问题。因此我们应用在对数据库的多个表做更新的时候,不同的代码段,应对这些表按相同的顺序进行更新操作,以防止锁冲突导致死锁问题。

锁的优化建议
- 1.尽量使用较低的隔离级别
- 2.设计合理的索引并尽量使用索引访问数据,使加锁更加准确,减少锁冲突的机会提高并发能力
- 3.选择合理的事务大小,小事务发生锁冲突的概率小
- 4.不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会
- 5.尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响
- 6.不要申请超过实际需要的锁级别
- 7.除非必须,查询时不要显示加锁
10. MySQL日志
10.1 redo log
14_MySQL事务日志-1 redo log

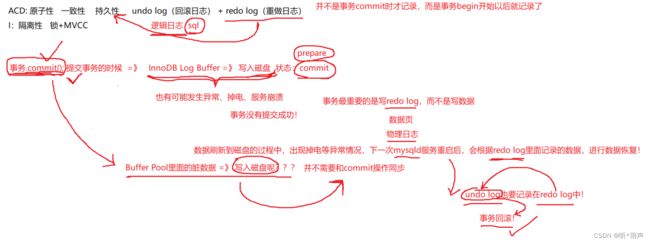
redo log:重做日志,用于记录事务操作的变化,确保事务的持久性。redo log是在事务开始后就开始记录,不管事务是否提交都会记录下来,在异常发生时(如数据持久化过程中掉电),InnoDB会使用redo log恢复到掉电前的时刻,保证数据的完整性。
innodb_log_buffer_size默认是16M,就是redo log缓冲区的大小,它随着事务开始,就开始写redolog,如果事务比较大,为了
避免事务执行过程中花费过多磁盘IO,可以设置比较大的redo log缓存,节省磁盘IO。
InnoDB修改操作数据,不是直接修改磁盘上的数据,实际只是修改Buffer Pool中的数据。InnoDB总是先把Buffer Pool中的数据改变记录到redo log中,用来进行崩溃后的数据恢复。 优先记录redo log,然后再慢慢的将Buffer Pool中的脏数据刷新到磁盘上。
innodb_log_group_home_dir指定的目录下的两个文件:ib_logfile0,ib_logfile1,该文件被称作重做日志。
buffer pool缓存池:
作用:加速读和加速写,直接操作data page,写redo log修改就算完成,有专门的线程去做把bufferpool中的dirty page写入磁盘。
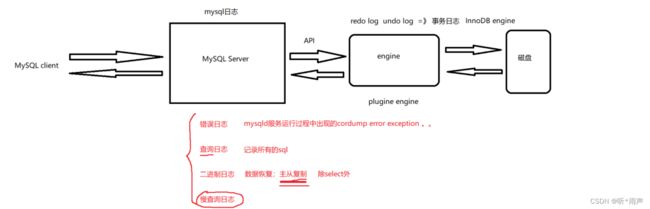
10.2 其它数据库日志
11.MySQL优化
如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何优化SQL和索引,这种方式简单有效;其次才是采用缓存的策略,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用主从架构,进行读写分离。
SQL和索引的优化
08_索引的创建与设计原则
10_索引优化与查询优化
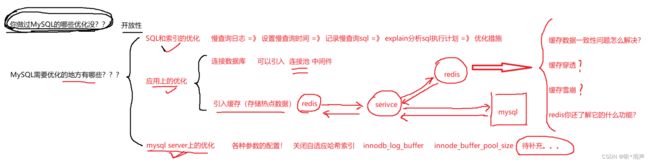
加缓冲层:Redis
16_Redis_Redis持久化
缓存一致性问题解决
21_Redis_浅析Redis缓存穿透和雪崩
17_Redis_Redis发布订阅
MySQL服务器优化
12_数据库其它调优策略
主从复制
读写分离-4.2
分库分表
12.数据库备份与恢复
