Playwright架构及运行原理
本篇来聊聊Playwright的架构技术以及运行原理。
为什么要了解架构技术及运行原理呢?
此前在测试打工人如何学习一文中说过,学习一门新技术最好的方法就是先了解其原理,搞清楚工具或知识点背后的原理,理解它是通过什么方式解决问题的,学会从工具的使用中提取思考点,而不仅仅是当个工具人。
架构图
那么Playwright的架构和运行原理又是怎样的呢?
虽说Playwright出身名门,但是它也是站在巨人肩膀上的产品。
Playwright其实是赫赫有名的Puppeteer改造而来的,所以Puppeteer的逻辑和实现原理对于Playwright是通用的。
加上Playwright官方并没有直接给出Playwright的架构图,所以我们可以直接参考Puppeteer的架构图。
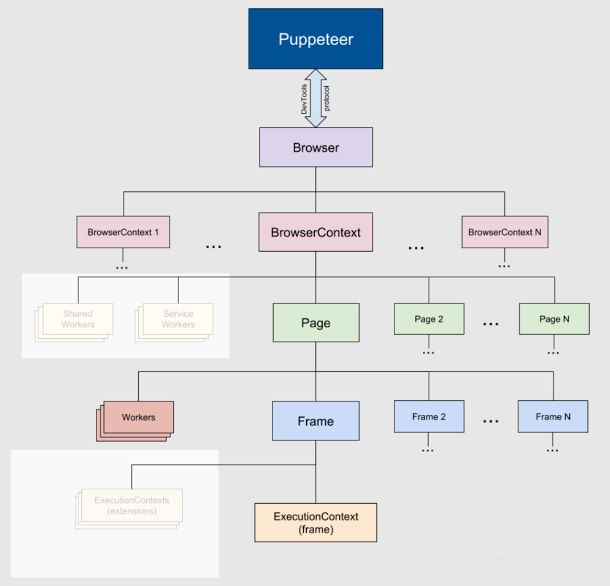
从上图中我们可以看出Puppeteer API 是分层的,并反映了浏览器的结构。
首先,我们通过Puppeteer来控制浏览器,实现自动化。
Puppeteer和Browser浏览器之间是通过CDP协议(Chrome DevTools Protocol,谷歌开发者协议,该协议是建立在WebSocket协议之上,CDP协议允许我们检测、调试Chromium、Chrome和其他基于Blink的浏览器)进行通信的。
这里的Browser对应着一个浏览器实例,一个浏览器实例可以包含多个Browser Context,也就是浏览器上下文。
一个Browser Context就是一个浏览器的上下文会话,就像我们打开一个Chrome之后,又打开一个隐身模式的Chrome。Browser Context具有独立的Session、Cookie和Cache,独立不共享。
一个Browser Context可以包含多个Page,一个Page其实就是一个tab页面,我们可以通过browserContext.newPage()来进行实例化创建,且browser.nwePage()在创建页面的时候会使用默认的Browser Context。
一个Page可以包含多个Frame,Frame就是一个框架,每个Page页面至少有一个主框架main frame,可能还包含多个子框架,子框架主要由iframe标签创建而产生的。
Frame至少有一个可执行上下文ExecutionContext,ExecutionContext就是JavaScript的一个执行环境,每一个Frame都有一个默认的JavaScript执行环境。
Worker具有单一执行上下文,便于与 WebWorkers 交互。
总结
在Playwright中,这些概念和Puppeteer是一样的。
当然,Playwright为了照顾众多使用Selenium的用户,也加入了Selenium的很多概念以及用法,这些内容将会在后面的实际操作中进行介绍(请持续关注「伤心的辣条」公众号),也就是说,如果之前使用过Selenium的同学,学习Playwright也将会是一件非常简单的事情。

以上,完。
脚踏实地,仰望星空,和小编一起学习软件测试,升职加薪!
最后: 为了回馈铁杆粉丝们,我给大家整理了完整的软件测试视频学习教程,朋友们如果需要可以自行免费领取【保证100%免费】

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

面试文档获取方式:

![]()