《单链表》的实现(不含哨兵位的单向链表)

目录
编辑
前言:
链表的概念及结构:
链表的实现:
1.typedef数据类型:
2.打印链表 :
3.创建新节点:
4.尾插 :
5.头插:
6.尾删 :
7.头删:
8.查找节点:
9.指定下标前插入:
10.删除当前下标
11. 指定下标后插入:
12.删除当前下标的后一个节点 :
13.销毁链表:
总结:
前言:
我们在前面的学习中深度的讲解了顺序表的模拟实现,而在上一篇好题分享中,我们又对于链表中的几道基础题(含有含金量)作出了完善的解析,今天我们将要真正的开启链表的学习,就从最基础的模拟实现一个单链表开始
前两篇的blog在这里:
好题分析(2023.10.29——2023.11.04)-CSDN博客
《动态顺序表》的实现-CSDN博客
链表的概念及结构:
链表(Linked List)是一种常见的数据结构,它是由一系列节点(Node)组成的,每个节点包含两个部分:数据域和指针域。数据域存储数据,指针域指向下一个节点。
链表可以分为单向链表和双向链表两种:
单向链表:每个节点只有一个指针域,指向下一个节点。
双向链表:每个节点有两个指针域,一个指向前一个节点,一个指向后一个节点。
链表相较于数组,具有以下优势:
-
内存空间可以动态分配,不需要预先定义大小。
-
插入和删除操作比较容易,只需要改变指针指向即可,不需要移动元素。
-
可以节省内存空间,因为链表中的节点可以零散分布在内存中,不需要连续的空间。
但是链表的缺点是:
-
访问元素的时间复杂度为O(n),而数组可以通过下标随机访问元素,时间复杂度为O(1)。
-
链表的节点需要额外的指针域来存储指向下一个节点的指针,因此内存占用相对于数组较大。
这些特点使得链表在某些场景下比数组更加适用,比如实现队列、栈、哈希表等数据结构,或者需要频繁插入和删除元素的场景。
介绍完链表的基本信息,下面我们就来实现链表!
链表的实现:
1.typedef数据类型:
typedef int SLNDataType;
typedef struct SlistNode
{
SLNDataType val;
struct SlistNode* next;
}SLNode;这里与我们最早实现通讯录和顺序表的结构相似,在这里我就不过多赘述。
2.打印链表 :
void SLTPrint(SLNode* phead)
{
while (phead)
{
printf("%d->", phead->val);
phead = phead->next;
}
printf("NULL\n");
}打印函数的内容较好理解,在这里我不进行过多的赘述。
3.创建新节点:
SLNode* CreateNode(SLNDataType x)
{
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
if (newnode == NULL)
{
perror("CreateNode -> malloc");
exit(-1);
}
newnode->next = NULL;
newnode->val = x;
return newnode;
}这里与我们在顺序表中,在堆区申请空间而使用的malloc相似。
在这里我们是定义了一个指针newnode,这里要注意的是此时的newnode的返回值是SLNode*,意思就是指向一个SLNode类型的结构体指针!
所以对于该结构体我们就给它赋予初始值,即newnode->val = x;newnode->next = NULL;
4.尾插 :
void SLTPushBack(SLNode** pphead, SLNDataType x)
{
assert(pphead);
SLNode* newnode = CreateNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}对于此函数的实现,我们首先要讲解的就是此时的形参必须是一个二级指针!
我们都知道,
形参是实参的一份临时拷贝!
我们在实现这些关于结构体的函数,传递的都是结构体的地址。
对于顺序表和通讯录,我们这样传递不成问题。例:
Contact c;
CreateContact(&c);等等代码。因为我们一开始是创建了一个结构体C,这时我们想要在结构体里修改各个成员的值,就需要调用CreateContact函数,那么我们都知道要传入结构体指针,因为当我们传入指针,指针可以在原来的数据上进行修改,同时可以返回到修改完的数据。
但当我们仅仅传一个C,而非指针时,此时函数内部就会再创建一个结构体,对新创建的结构体里的各个成员进行修改,一旦函数结束,此结构体就会销毁,原来的结构体不会发生改变。
这就是为什么形参是实参的一份临时拷贝!
同理,
对于当前的链表,我们在主函数肯定会有:
SLNode* plist = NULL;
我们在此刻是使用的结构体指针,而非结构体对象,因为我们使用结构体指针可以更方便访问链表的头结点,进而进行许许多多的操作。
那如果我们在函数里用的是一级指针的话,就会出现:
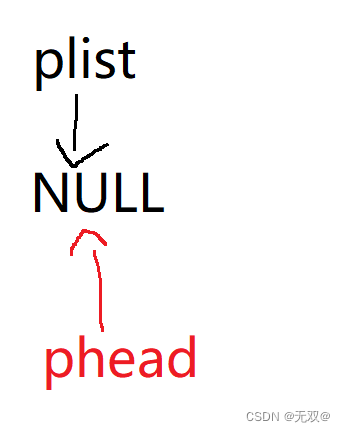
当我们实施添加节点时,
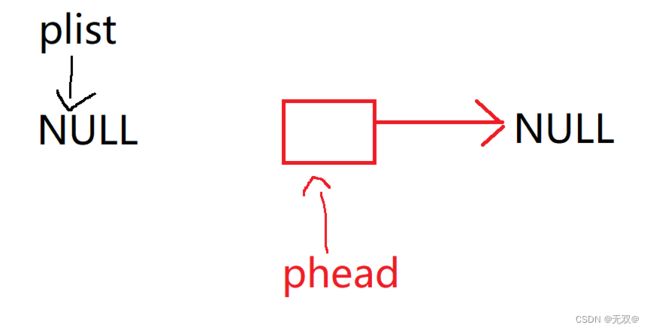
看似我们创建了新节点,但实际上是这样的。
一旦函数结束,phead就会销毁,新开辟出来的结点就会找不到。
就会导致内存泄漏。
所以正确的做法就是利用二级指针,来解引用得到原指针而修改里面的next,并且指向新节点。
即:
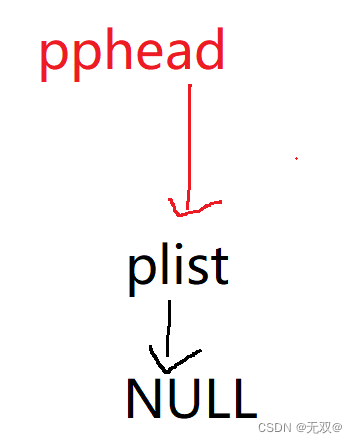
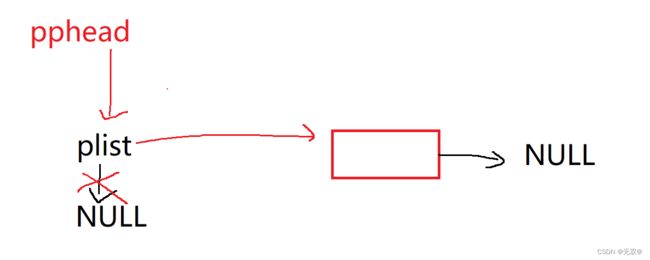
这就很好的解释了为什么要用双指针来接收。
然后就是要注意,当指针为NULL和指针已经指向节点要分开讨论。
5.头插:
void SLTPushFront(SLNode** pphead, SLNDataType x)
{
assert(pphead);
SLNode* newnode = CreateNode(x);
newnode->next = *pphead;
*pphead = newnode;
}头插的代码很好理解,在这里我不做过多赘述。
6.尾删 :
void SLTPopBack(SLNode** pphead)
{
assert(pphead);
assert(*pphead);
SLNode* tail = *pphead;
if (tail->next == NULL)
{
free(tail);
tail = NULL;
}
else
{
SLNode* prev = NULL;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
prev->next = NULL;
free(tail);
tail = NULL;
}
}对于该函数的实现,注意的就是要保存最后一个节点前的结点,这样我们就可以将前一个节点的next指向NULL。
同时注意要将空节点和有节点分开讨论。
7.头删:
void SLTPopFront(SLNode** pphead)
{
assert(*pphead);
assert(pphead);
SLNode* tmp = (*pphead)->next;
free(*pphead);
*pphead = tmp;
}头删的大致思路与尾删类似,在这里我不过多赘述。
8.查找节点:
SLNode* SLTFind(SLNode* phead, SLNDataType x)
{
assert(phead);
while (phead)
{
if (phead->val == x)
{
return phead;
}
phead = phead->next;
}
return NULL;
}9.指定下标前插入:
void SLTInsertBefore(SLNode** pphead, SLNode* pos, SLNDataType x)
{
assert(pphead);
assert(*pphead);
assert(pos);
SLNode* tail = *pphead;
if ((*pphead) == NULL)
{
SLTPushFront(pphead, x);
}
else
{
while (tail->next != pos)
{
tail = tail->next;
}
SLNode* newnode = CreateNode(x);
newnode->next = pos;
tail->next = newnode;
}
}10.删除当前下标
void SLTErase(SLNode** pphead, SLNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
SLNode* tmp = *pphead;
if (*pphead == pos)
{
SLTPopBack(pphead);
}
else
{
while (tmp->next != pos)
{
tmp = tmp->next;
}
tmp->next = pos->next;
free(pos);
pos = NULL;
}
}11. 指定下标后插入:
void SLTInsertAfter(SLNode* pos, SLNDataType x)
{
assert(pos);
SLNode* newnode = CreateNode(x);
newnode->next = pos->next;
pos->next = newnode;
}12.删除当前下标的后一个节点 :
void SLTEraseAfter(SLNode* pos)
{
assert(pos);
assert(pos->next);
SLNode* tmp = pos->next;
pos->next = tmp->next;
free(tmp);
tmp = NULL;
}13.销毁链表:
void SLTDestory(SLNode** pphead)
{
assert(pphead);
SLNode* prev = NULL;
while (*pphead)
{
prev = *pphead;
*pphead = (*pphead)->next;
free(prev);
}
prev = NULL;
}总结:
在这里我仅仅只是讲解了实现单链表的基本概念,而对于后续的一些函数实现,我并没有进行过多的讲解,因为这些函数的实现与之前的尾插和头插大差不差。
需要注意的就是释放和插入的next指向,以及先后顺序。
这些在之后做题中会多次提到,我们也会不断熟练。
总之,对于这部分链表问题,我们应当多多练习多多刷题,提升我们的熟练度才是首要目标!
记住
“坐而言不如起而行”
Action speake louder than words
以下是我本次文章的全部代码:
Data structures amd algorithms: 关于数据结构和算法的代码 - Gitee.com