Spark 资源调优
1 资源规划
1.1 资源设定考虑
1、总体原则
以单台服务器128G内存,32线程为例。
先设定单个Executor核数,根据Yarn配置得出每个节点最多的Executor数量,每个节点的yarn内存/每个节点数量=单个节点的数量
总的executor数=单节点数量*节点数。
2、具体提交参数
1)executor-cores
每个executor的最大核数。根据经验实践,设定在3~6之间比较合理。
2)num-executors
该参数值=每个节点的executor数 * work节点数
每个node的executor数 = 单节点yarn总核数 / 每个executor的最大cpu核数
考虑到系统基础服务和HDFS等组件的余量,yarn.nodemanager.resource.cpu-vcores配置为:28,参数executor-cores的值为:4,那么每个node的executor数 = 28/4 = 7,假设集群节点为10,那么num-executors = 7 * 10 = 70
3)executor-memory
该参数值=yarn-nodemanager.resource.memory-mb / 每个节点的executor数量
如果yarn的参数配置为100G,那么每个Executor大概就是100G/7≈14G,同时要注意yarn配置中每个容器允许的最大内存是否匹配。
1.2 内存估算
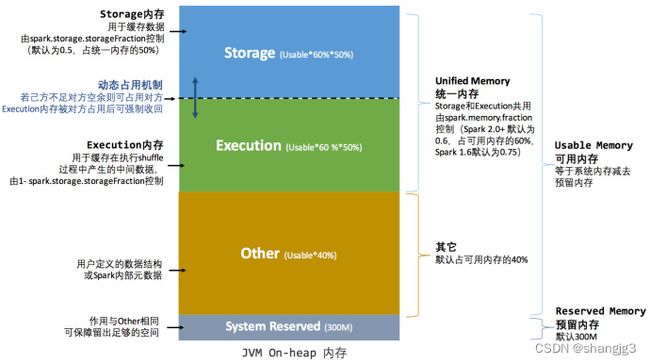
- 估算Other内存 = 自定义数据结构*每个Executor核数
- 估算Storage内存 = 广播变量 + cache/Executor数量
- 估算Executor内存 = 每个Executor核数 * (数据集大小/并行度)
1.3 调整内存配置项
一般情况下,各个区域的内存比例保持默认值即可。如果需要更加精确的控制内存分配,可以按照如下思路:
spark.memory.fraction=(估算storage内存+估算Execution内存)/(估算storage内存+估算Execution内存+估算Other内存)得到
spark.memory.storageFraction =(估算storage内存)/(估算storage内存+估算Execution内存)
代入公式计算:
Storage堆内内存=(spark.executor.memory–300MB)*spark.memory.fraction*spark.memory.storageFraction
Execution堆内内存=
(spark.executor.memory–300MB)*spark.memory.fraction*(1-spark.memory.storageFraction)
2 持久化和序列化
2.1 RDD
1、cache

打成jar,提交yarn任务,并在yarn界面查看spark ui
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.cache.RddCacheDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar

通过spark ui看到,rdd使用默认cache缓存级别,占用内存2.5GB,并且storage内存还不够,只缓存了29%。
2、kryo+序列化缓存
使用kryo序列化并且使用rdd序列化缓存级别。使用kryo序列化需要修改spark的序列化模式,并且需要进程注册类操作。
打成jar包在yarn上运行。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.cache.RddCacheKryoDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
查看storage所占内存,内存占用减少了1083.6mb并且缓存了100%。使用序列化缓存配合kryo序列化,可以优化存储内存占用。



根据官网的描述,那么可以推断出,如果yarn内存资源充足情况下,使用默认级别MEMORY_ONLY是对CPU的支持最好的。但是序列化缓存可以让体积更小,那么当yarn内存资源不充足情况下可以考虑使用MEMORY_ONLY_SER配合kryo使用序列化缓存。
3 DataFrame、DataSet
1、cache
提交任务,在yarn上查看spark ui,查看storage内存占用。内存使用612.3mb。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.cache.DatasetCacheDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar

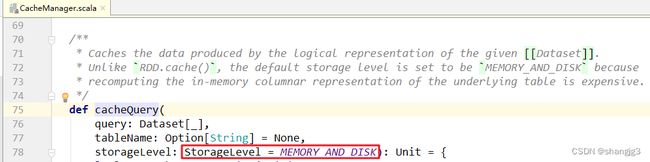
DataSet的cache默认缓存级别与RDD不一样,是MEMORY_AND_DISK。
源码:Dataset.cache() -> Dataset.persist() -> CacheManager.cacheQuery()
2、序列化缓存
DataSet类似RDD,但是并不使用JAVA序列化也不使用Kryo序列化,而是使用一种特有的编码器进行序列化对象。

打成jar包,提交yarn。查看spark ui,storage占用内存646.2mb。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.cache.DatasetCacheSerDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar

和默认cache缓存级别差别不大。所以DataSet可以直接使用cache。
从性能上来讲,DataSet,DataFrame大于RDD,建议开发中使用DataSet、DataFrame。
3 CPU优化
3.1 CPU低效原因
1、概念理解
1)并行度
- spark.default.parallelism

设置RDD 的默认并行度,没有设置时,由join、reduceByKey和parallelize等转换决定。
- spark.sql.shuffle.partitions
适用SparkSQL时,Shuffle Reduce 阶段默认的并行度,默认200。此参数只能控制Spark sql、DataFrame、DataSet分区个数。不能控制RDD分区个数

2)并发度:同时执行的task数
2、CPU低效原因
1)并行度较低、数据分片较大容易导致 CPU 线程挂起
2)并行度过高、数据过于分散会让调度开销更多
Executor 接收到 TaskDescription 之后,首先需要对 TaskDescription 反序列化才能读取任务信息,然后将任务代码再反序列化得到可执行代码,最后再结合其他任务信息创建 TaskRunner。当数据过于分散,分布式任务数量会大幅增加,但每个任务需要处理的数据量却少之又少,就 CPU 消耗来说,相比花在数据处理上的比例,任务调度上的开销几乎与之分庭抗礼。显然,在这种情况下,CPU 的有效利用率也是极低的。
3.2 合理利用CPU资源
每个并行度的数据量(总数据量/并行度) 在(Executor内存/core数/2, Executor内存/core数)区间
提交执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.atguigu.sparktuning.partition.PartitionDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
去向yarn申请的executor vcore资源个数为12个(num-executors*executor-cores),如果不修改spark sql分区个数,那么就会像上图所展示存在cpu空转的情况。这个时候需要合理控制shuffle分区个数。如果想要让任务运行的最快当然是一个task对应一个vcore,但是一般不会这样设置,为了合理利用资源,一般会将并行度(task数)设置成并发度(vcore数)的2倍到3倍。
修改参数spark.sql.shuffle.partitions(默认200), 根据我们当前任务的提交参数有12个vcore,将此参数设置为24或36为最优效果:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.atguigu.sparktuning.partition.PartitionTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar