【网安专题11.8】14Cosco跨语言代码搜索代码: (a) 训练阶段 相关程度的对比学习 对源代码(查询+目标代码)和动态运行信息进行编码 (b) 在线查询嵌入与搜索:不必计算相似性
Improving Code Generation by Training with Natural Language Feedback
- 写在最前面
- 论文名片
- 对未来论文的启发
- 课堂讨论
-
- 模型框架
- 语义相似性计算(实验部分讨论了作用)
- 动态和静态信息
- 编码
- 实际应用场景
- 研究背景
-
- 1.1 代码搜索任务
- 1.2 用于理解源代码的编码器模型
- 1.3 现有的相关工作
-
- 代码搜索任务的分类
- 编码动态信息
- 研究挑战与动机
-
- 现有挑战
- 主要动机
- 本文贡献
- 模型框架及方案
-
- 系统模型
- A.COSCO模型训练
-
- `优化目标`:
- Contrastive Training (对比训练)
- Semantic Similarity Score (语义相似度分数)
- Semantic Similarity Score Calculation For Training
- B. 基于COSCO模型的代码搜索
- 实验设置及结果
-
- A. 研究问题
- B. 数据集
- C. 评价指标
- 实验结果
-
- A. RQ1 - 整体性能表现
- B. RQ2 – 模型通用性
- C. RQ3 – SSS 语义相似度分数的影响(消融实验)
- D. RQ4 – 不同训练样本数量对性能的影响(参数分析)
- 总结与讨论
-
- 文章总结
- 讨论改进
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
崔凯同学分享了On Contrastive Learning of Semantic Similarity for Code to Code Search《基于语义相似度对比学习的代码搜索》
PPT好清爽,尤其是介绍系统模型的那部分,把ppt放上来了很多
中文:华文楷体
英文:Times New Roman
字体大小:18号
图注表注:楷体加粗
论文:https://arxiv.org/pdf/2303.16749.pdf
代码:https://github.com/reinforest-team/reinforest
论文名片
(自提亮点,但可能不明显)第一个由(跨语言)代码到代码的搜索模型:作为一种技术,增强大模型
-
提出了一种新颖的代码到代码搜索技术Cosco。该技术通过包括静态和动态特征,以及在训练过程中利用相似和不同的示例(对比学习),来增强大型语言模型(LLM)的性能
提出了有史以来第一种代码搜索方法,该方法在训练期间对动态运行时信息进行编码,而无需在推理时执行搜索中的语料库或搜索查询,以及第一种在正负参考样本上进行训练的代码搜索技术 -
进行了一系列研究证明了增强的LLM执行
跨语言代码到代码搜索的能力。评估表明,该方法的有效性在各种模型架构和编程语言中是一致的,比最先进的跨语言搜索工具高出44.7%;
消融研究表明,在训练过程中,单个阳性和阴性参考样本都会带来实质性的性能提升,证明相似和不同的参考都是代码搜索的重要组成部分
表明经过精心设计、微调的增强模型始终优于未经微调的增强型大型现代LLM,即使在增强最大的可用LLM时也是如此,这凸显了开源大模型的重要性
对未来论文的启发
- 可以探索(对比学习)如何利用相似和不同的参考来增强模型的性能。通过在训练过程中引入相似和不同的示例,可以让模型更好地理解关系的多样性和复杂性,从而提高其性能。
- (a) 训练阶段 相关程度的对比学习 对源代码(查询+目标代码)和动态运行信息进行编码 (b) 在线查询嵌入与搜索:不必计算相似性
课堂讨论
模型框架
进行编码,对编码得到的嵌入向量进行学习
对比学习:相似代码之间距离最小化
相似度计算:预先计算的嵌入&查询嵌入
文档代码的编码
语义相似性计算(实验部分讨论了作用)
余弦相似度:查询代码和查询库的相似性
创新点:训练过程中同时考虑正负样本
动态和静态信息
查询代码
静态:嵌入转换
动态:在线查询
编码
比如用java语言
训练语料库分为两部分:查询代码(java)、文档代码(python)
提到了什么代码特征,以能实现
跨语言搜索(目前只一对一、针对java到python)?
没有直接提及,可能是编码提取,通过余弦相似度学到了相关信息。
一对多时,余弦相似度可能不足以完成任务
实际应用场景
代码克隆的场景下,传统方法更有效
第三类:部分语句的插入、删除、修改
传统相似漏洞搜索,一大块代码copy才会导致漏洞
研究背景
- 随着强大的
大型语言模型(LLM)的兴起(代表如Bert模型 [1],如图1所示),应用于源代码分析任务的机器学习逐渐引起了广泛研究。 - 由于大型公共代码存储库的出现 [2],
代码到代码搜索( Code-to-Code Search)的潜力已经获得了新的意义,可协助完成常见的软件维护与开发任务,实现在大型代码库中定位和重用代码片段,例如,代码迁移、转译、代码修复、错误检测、和重构等。
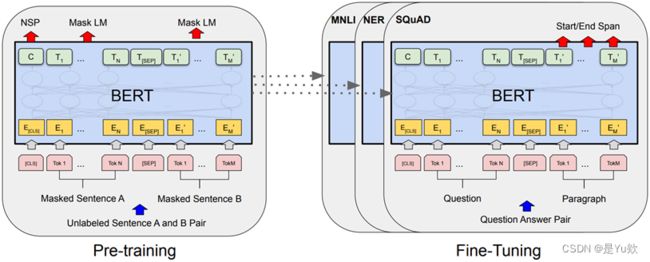 图1:Bert模型框架图。预训练的语言表征模型,基于Transformer的框架,能融合左右上下文信息的深层双向语言表征
图1:Bert模型框架图。预训练的语言表征模型,基于Transformer的框架,能融合左右上下文信息的深层双向语言表征
[1] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019, pp. 4171–4186. [Online]. Available: https://doi.org/10.18653/v1/n19 1423.
[2] B.Vasilescu, A. Serebrenik, and V. Filkov, “The state of the art in distributed software development: A systematic review,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 2019, pp. 69–79.
1.1 代码搜索任务
- 代码到代码搜索可以被广泛地定义为
获取代码样本(即查询项)后,搜索其他可用代码样本的语料库(即搜索语料库),并在搜索语料库中查找与查询匹配的代码克隆品。
代码搜索的系统架构,如图2所示。

• 跨语言代码到代码搜索,则专门地处理查询和语料库用不同语言编写的情况。(例如,开发人员 a 使用相对较新的语言或缺乏支持文档的语言编写代码)。
• 代码克隆(Code Clones)[3]源于多种因素,复制粘贴、代码重用和遵守编码模式:
类型1:相同的代码片段,但空白、注释或格式有所不同。
类型2:语法相同的代码片段,但变量、常量或函数名称有所不同。
类型3:带有修改的语句、函数调用或控制结构的类似代码片段。
类型4:语义相同且具有相同功能的代码片段,但其句法结构有所不同。由于源代码可能提供很少有用的上下文,这类克隆方式最难检测。
[3] F.-H. Su, J. Bell, G. Kaiser, and S. Sethumadhavan, “Identifying Functionally Similar Code in Complex Codebases,” in 2016 IEEE 24th International Conference on Program Comprehension (ICPC), 2016, pp. 1–10.
• 现有的静态代码搜索技术,可分为以下三类:
① 基于文本的方法。依靠传统的信息检索技术(例如,关键字搜索或字符串匹配)来查找相关的代码片段;
② 基于结构的方法。利用源代码的语法和语义结构(例如,抽象语法树)来查找匹配或相似的代码片段;
③ 基于机器学习的方法。利用文本和语义结构编码以及机器学习算法来查找克隆代码。
• 如今,代码搜索算法能够更好地从源代码文本中提取语义信息,已从传统的仅限于同一语言的代码查询和语料库,逐渐扩展到不同语言的查询和语料库的代码搜索。
• 由于静态代码搜索的高度可扩展性(无需代码执行、快速处理源代码)和易实现性(无需执行环境或运行时设置、可用的上下文缺少),针对类型4的代码克隆中行为相似性,动态分析信息(执行跟踪 或输入输出对)技术,利用额外的上下文来查找静态分析未检测到的代码克隆。
1.2 用于理解源代码的编码器模型
-
深度学习技术训练模型来“理解”源代码。即利用编码器Enc对给定代码片段c进行表示学习,得到向量嵌入
embeddeding Enc(c),其包括代码中的词典、句法和语义信息,随后应用于分类、搜索、排序等任务。 -
开源模型,例如 CodeBERT [4] 。或闭源嵌入的 API,例如 OpenAI 的 codex 嵌入 [5]。
-
针对高效的预训练模型,嵌入需要根据下游任务进行调整。
对于用于嵌入的开源模型,可以访问模型的权重对模型进行微调。
对于来自闭源模型的嵌入,可以在初始嵌入的基础上构建进一步的模型,但嵌入不能更改。
[4] Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “CodeBERT: A pre-trained model for programming and natural languages,” in Findings of the Association for Computational Linguistics: EMNLP 2020, Nov. 2020, pp. 1536–1547.
[5] OpenAI, “Openai’s text embeddings,” 2023. [Online]. Available: https://platform.openai.com/docs/guides/embeddings
1.3 现有的相关工作
代码搜索任务的分类
① 在训练或推理时都不运行代码的静态技术,依赖于其基于 token 的中间表示,或者基于图和基于 AST 的中间表示。但缺乏编码行为信息,并且需要之前的查询来获取上下文。
② 包括更多上下文的动态信息,但需要在训练和推理时运行代码带来额外的开销。
最近关于动态代码克隆检测,已经转向获取代码并将其分割成更小的段并比较。
编码动态信息
先前工作是 Trex通过在训练阶段编码微执行轨迹,来识别语义相似的函数,从而将学习到的表示转移到预训练的模型上。
学习动态行为信息在安全领域中尤其普遍,因为恶意软件经常混淆源代码以避免检测。
由于收集所有查询代码的运行时信息,需要相当长的时间来执行推理任务。
研究挑战与动机
现有挑战
※ 当前研究存在的主要挑战:
►当前,传统的动态分析技术需要在训练阶段执行代码、在搜索过程执行搜索语料库和搜索查询项目,这会导致扩展问题以及实践中运行代码所带来的所有与环境相关的问题。
►针对跨语言代码搜索问题,即查询和语料库来自不同的语言形式,需要重点考虑其行为相似性,而模型不能仅仅依赖于源代码的相似性。
主要动机
►在训练过程,COSCO模型从训练语料库中学习静态和动态相似性,借鉴对比学习的思想,最大化不相似代码之间的距离,并最小化相似代码之间的距离。
►训练前生成语义相似度得分 (SSS) 的动态相似性特征,该特征涉及使用相同输入执行的训练语料库,并比较具有相同输入类型函数的输出。
►创建搜索语料库中预先计算的嵌入,在推理时搜索查询嵌入,以便与预先计算的嵌入进行简单比较来生成搜索结果。具体过程,如图3所示。
本文贡献
※ 主要工作贡献:
① 为增强LLMs的代码搜索能力,本文提出了一种新的代码到代码搜索技术COSCO,在训练阶段对源代码(查询+目标代码)和动态运行信息进行编码,而无需执行任何内容,从而搜索语料库或搜索查询进行推理。
② 训练阶段同时考虑相似和不相似代码样本,同时利用静态和动态信息但不会在推理时产生运行代码开销。
③ 通过消融研究证明了COSCO在跨语言代码搜索推断动态行为的能力,即使推断仅基于静态信息。
④ 实验验证了COSCO模型在多个LLMs模型上的有效性。
⑤ 作为跨语言代码搜索的最新方法,开源代码如下:https://github.com/reinforest-team/REINFOREST
模型框架及方案
系统模型
• COSCO 模型主要包含两个独立的步骤: (a) 训练阶段; (b) 在线查询嵌入与搜索。
• COSCO 由两种不同的编码器组成: (a)查询代码编码器(Eq); (b)文档代码编码器(Ed)。
A.COSCO模型训练
优化目标:
① COSCO 模型对查询代码编码器(Eq)和文档代码编码器(Ed)生成的嵌入进行转换,即使相关代码之间的距离最小化,不相关代码之间的距离最大化。
②在训练过程中为 COSCO 模型提供动态代码相似性信息,即在代码搜索(推理)任务中不必计算查询代码与数据库中所有其他代码之间的语义(I/O)相似性。
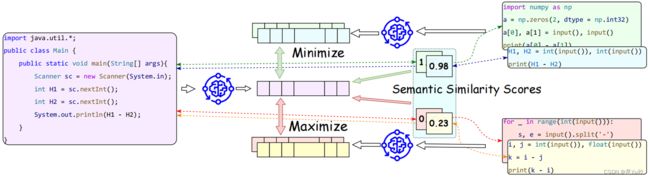
Contrastive Training (对比训练)
Contrastive Learning : 一种特殊的无监督学习方法,旨在通过最大化相关样本之间的相似性并最小化不相关样本之间的相似性来学习数据表示。通常使用一种高自由度、自定义的规则生成正负样本。在模型预训练中有着广泛的应用、良好的迁移性能。
► Positive和Anchor组成一组正样本对,这里Positive和Anchor可以是图片、音频、特征,且可以为多种数据类型,而且不一定要和Anchor是同种数据类型(CLIP);
► Negative和Anchor组成一组负样本对;
► 核心的三个模块即:
正负样本定义+Encoder(编码器)定义+损失函数定义


► 定义三元组的集合
一段以源语言 s 编写的代码 (例如,Java);
以目标语言 t 编写的代码集合(例如,Python)
代码样本 Cp :相同问题的解决方案(正样本);
代码样本 Cn :不同问题的解决方案(负样本)
Goal:希望使得 Cp 中每个元素的嵌入更接近 cs 的嵌入,并且使 Cn 中每个元素的嵌入远离 cs 的嵌入。
► Code Encoder 代码编码器
查询代码的嵌入;文档代码的嵌入 (正、负样本)
► 余弦相似度:
计算查询代码与每个正样本和负样本之间的余弦相似度
对比损失函数:最大化 cs 和 Cp 中所有元素之间的相似性,最小化 cs 和 Cn 中所有元素之间的相似性。
Semantic Similarity Score (语义相似度分数)
Goal:赋予COSCO模型有关语义(I/O)相似性的知识。
语义相似性函数:计算源代码和目标代码之间的语义相似度。
对比损失函数:对公式2进行了修正,超参数 α 表示语义训练的相对重要性,凭经验发现将 α 设为 0.2 可获得最佳性能。
Semantic Similarity Score Calculation For Training
(训练阶段语义相似度分数计算)
基于运行时信息的语义相似度评分计算,采用 SLACC 的 相似性评分方法,即匹配输出的数量除以总输入的数量。

图5:相似度评分流程,其中包括 (a) 语料库生成; (b) 相似度计算。

► 相似性分数的生成过程
① 由代码语料库生成输入语料库,对系统调用进行静态分析,并推导出该特定代码的输入结构。
首先提取语料库中的所有输入结构,然后根据原始类型为每个结构生成大量随机值的输入,并创建输入语料库。
② 针对任意两个代码样本,进行相似度计算。
首先提取其输入结构,使用与其输入结构匹配的输入运行,再执行上述描述的相似度计算。 注意,与 SLACC 一样,如果两段代码具有不同的输入结构,相似度分数为零。
B. 基于COSCO模型的代码搜索
主要步骤:
① 编码。利用经训练得到的两个代码编码器 Eq 和 Ed ,分别对查询代码和文档代码进行编码。
② 搜索。由于编码表示是实值向量,FAISS 等索引工具可将它们存储在索引数据库中以进行高效搜索。根据公式(1)中的相似度得分在嵌入数据库中进行搜索,并返回相似度得分最高的前 n 项候选项目。
实验设置及结果
A. 研究问题
为了评估本文所提出的COSCO模型性能,主要考虑了四个主要研究问题,如下:
RQ1: 与其他跨语言代码搜索技术的性能相比,COSCO 的性能表现如何?
RQ2: COSCO的方法和性能是否适用于不同的模型?
RQ3:在训练阶段采用的语义相似度分数是否可以改善代码搜索性能?
RQ4:如果改变可用于训练的正、负比较样本的数量会对COSCO的性能有何影响?
B. 数据集
► 为了评估COSCO,本文采用了Atcoder数据集[11],其主要针对361个编程竞赛问题,由18644个Java解决方案和22317个Python解决方案组成。
► 通过将数据集重新划分为不同的问题来创建训练、验证和测试集,即训练、验证和测试分集不共享同一问题的解决方案。
[11] K. Nakamura, R. Iwasaki, S. Hoshino, and I. Sato, “Atcoder: A dataset for machine learning on programming,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2021, pp. 3601–3611.
表1:数据集的统计数据,其中“Average”表示每个问题的平均文件数。

C. 评价指标
本文主要利用了三个性能评价指标,如下:
① PR@N精度,反映代码搜索任务的重要性能。
将测试集中的每个样本作为查询对象,在前 N 个搜索结果中找出真实正的样本的平均数量,并与测试集中的其他样本进行比较,且N 介于 1 和 5 之间。
② ARG(Average Rank Gap),反应语料库中的全部搜索结果。
被定义为负样本的平均排名减去正样本的平均排名。
③ AFP(Average First Position),反应语料库中的正样本排序最高的搜索结果。
其他实验细节
► 本文使用 BM25 python 库实现了 TF-IDF 搜索,将源代码视为自然语言,并执行基于标记的搜索。另外,还实施基于 AST 的搜索,改进了SLACC 方法,使用语料库中查询和文档的 AST 表示法,并将其从特定语言的 AST 转换为具有通用节点类型的通用 AST。
► 利用标准树距离算法来确定两个代码样本的相似性;重新实施了 COSAL的标记子集技术,将函数划分为较小的片段,并对较小的代码片段进行聚类,以确定函数之间的相似性。
实验结果
A. RQ1 - 整体性能表现
► 验证COSCO模型在寻找跨语言克隆方面的表现如何。
► 选取了三种state-of-the-art LLM模型进行对比验证实验。
① CodeBERT 是微软亚洲研究院开发的用于代码表示和生成的预训练模型,具有跨编程语言传输知识的能力,可针对各种下游任务微调,并表现出良好性能。
② GraphCodeBERT 是扩展模型,将控制流图合并到其预训练过程中,更好地捕获代码标记间关系,并为代码分析和生成任务生成准确的表示。
③ UnixCoder是由 Facebook AI 开发的自然语言到 shell 命令翻译的预训练模型,根据自然语言输入生成 shell 命令,具有理解复杂命令与转换可执行命令能力。
► 上述模型先在训练集上被训练为分类器,然后对于测试集中的每个文档,分类器确定文档与给定查询匹配的概率,并根据最高概率对结果进行排序,最终得到代码搜索结果。

► 时间复杂度。在搜索过程中,需对整个测试语料库进行分类。COSCO 可以使用预先计算的语料库嵌入,并且只需要根据查询创建与之最接近嵌入向量,而不需要考虑语料库的其余部分。时间消耗约14h。
► 指标性能。COSCO 模型在所有评估指标上都远远优于现有的跨语言代码搜索技术,与 Java 到 Python 搜索的最近基线相比提高了 40.6%,与 Python 到 Java 搜索的最近基线相比提高了 11.5%。 本文的性能比 COSAL 的最先进性能高出 44.7%。

图7:COSCO模型的整体性能表现,(a) 在 Java 到 Python 搜索任务; (b) 在 Python 到Java 搜索任务。


B. RQ2 – 模型通用性
► 验证COSCO模型是否能够有效提高许多不同的 LLM 模型(开源和专有)的性能。
► 选取了CodeBERT、OpenAI 的 Codex Ada、Babbage、Curie 和 Davinci 等 LLM模型进行对比验证实验。
COSCO 的训练始终能够提高 Java 到 Python 和 Python 到 Java 查询的代码到代码搜索性能,改进范围从 5.2% -10.44%

图8:经过训练和未经训练COSCO模型的训练影响 (PR@1),(a) 在 Java 上的训练提升; (b) 在 Python 上的训练提升。
使用 COSCO 方法的各种模型相对于 COSAL (SOTA) 的整体性能。
► COSCO 的训练方法始终改进基础 LLM 模型,Java 到 Python提升26.2%,Python 到 Java 提升5.17%;
► 发现经过微调的 CodeBERT 在跨语言代码查询上的每个指标都优于所有其他模型,7.69x、9.96x。

图9:COSCO模型的在不同模型上的表现,(a) 在 Java 上的模型表现; (b) 在 Python 上的模型表现。
C. RQ3 – SSS 语义相似度分数的影响(消融实验)
► 探究SSS 对 COSCO 各种底层模型在跨语言查询性能的影响。
无论使用哪种查询语言或用于嵌入的模型,使用 SSS 计算总是可以提高模型性能。尤其,对 OpenAI 专有模型之一(davinci)有显著提升。SSS 与性能最佳版本的 COSCO (CodeBERT) 结合在一起,7%、4.8%。

图10:COSCO模型的语义相似度分数影响(PR@1),(a) 在 Java 上的SSS影响; (b) 在 Python 上的SSS影响。
D. RQ4 – 不同训练样本数量对性能的影响(参数分析)
► 通过改变训练阶段可用的正负样本的数量,探究每个参考样本数量对模型性能的影响。
使用相同数量的正、负参考样本对 分别为1 、3 和 5 个参考进行了性能实验。
x 轴和 y 轴显示训练期间可用的正样本和负样本的数量,圆圈的大小代表模型在该情况下的 PR@1 性能,越大越好。

图10:在训练期间不同数量参考样本的 COSCO 模型性能,(a) 在 Java 到 Python 搜索上的不同的参考样本 (PR@1); (b) 在 Python 到 Java上的不同的参考样本 (PR@1)。
表 4:关于正样本和负样本的影响详细结果,其中 Max-p 和 Max-n 分别代表最大正样本和最大负样本。

► COSCO 的性能取决于正负样本量。与仅使用正样本和负样本相比,使用正样本和负样本的组合可分别将 Python 到 Java 搜索的性能提高 10.2 倍和 17.8 倍,将 Java 到 Python 搜索的性能提高 15.5 倍和 12.2 倍。
总结与讨论
文章总结
► 本文提出了一种新颖的由代码到代码搜索模型,称为 COSCO。 该方法利用通过以语义相似度得分 (SSS) 的形式对运行时行为进行编码,从而来增强LLM性能表现。 与在训练过程中仅考虑正样本的代码搜索不同,COSCO 模型既最小化相似样本之间的距离,又最大化不相似样本之间的距离,有效降低了模型时间复杂度。
► 在跨语言代码搜索任务中对COSCO模型进行了充分验证,即使用 Java 查询搜索 Python 样本语料库、使用 Java 查询搜索 Python 样本语料库,并表明该方法在所有评估指标上的先进性。
► 另外,验证了语义相似性分数计算、训练阶段的正负样本数量对模型性能的重要性影响。表明COSCO模型在推理阶段没有可用的动态上下文的情况下,学习了动态行为信息,并依赖于正负样本的存在。
讨论改进
※ 存在的问题与局限性 ※
① Q:模型内部问题
A: 由于本文进行了独立的训练、验证和测试集划分,与包括 COSAL 在内的基准方法对比,实验设置较为单一化。在Atcoder 数据集上的验证中,由于输入规范的问题,未在大部分数据集上执行,当无法收集到SSS时,即使用默认值。如果能够为整个数据集生成输入,SSS 可能会产生其他的的影响。并且在例如α等超参数设置上,存在调整粗略的问题。
② Q:模型外部问题
A: Atcoder 数据集是根据各个级别的从业者向编码竞赛提交的内容编译而成的。目前不清楚这些竞赛中的代码是否真正反映了现实场景下的生产代码,未能验证COSCO模型在真实场景下的具体性能表现。另外,在训练阶段不考虑行为克隆,则会限制模型对于正负样本中学习上下文的数量。
③ Q:模型验证问题
A: 本文仅选用其认为标准且有意义的评估指标,而忽略了如Recall, Overall Accuracy, and F1 score等其他评价指标。另外,本文只针对解决跨语言的代码搜索,而未考虑在同语言的代码搜索实验进行模型有效性验证。
④ Q:主要局限性
A: 对于任意两代码之间的语义相似度计算,类似于输入(测试用例)的生成,仍是一个值得进一步探究的研究。本文仅依赖于单一函数到函数的映射,可能过于理想化,由于相同的行为可在不同代码库中的多个函数之间进行划分。