HNU计概课实训题代码日记(20230506)
这次的实训只有三道,但是那堆网上搜不出来的选择题太过恶心。
实验6.2 Numpy及其应用
第1关:Numpy内置函数应用
这关的提示比较到位,就是后面的斐波那契数列需要注意一下。
# -*- coding: utf-8 -*-
import numpy as np
#1 使用numpy的linspace函数,创建初值为1,终止为5,元素个数为5的等差数组
########## begin ##########
# 请在此填写代码
A=np.linspace(1,5,5)
########## end ##########
print(A)
#2 将数组B变换成2行5列的二维数组
B=np.arange(0,20,2)
# 请在此填写代码
B=B.reshape(2,5)
########## end ##########
print(B)
#3 随机数种子为8,生成2行2列的随机数数组,值在[0,1)之间
np.random.seed(8)
# 请在此填写代码
C=np.random.rand(2,2)
########## end ##########
print(C)
#4 随机数种子为11,生成3行3列的正态分布随机数数组,期望值为5,标准差为2
np.random.seed(11)
# 请在此填写代码
D=np.random.normal(5,2,(3,3))
########## end ##########
print(D)
#5 使用斐波那契数列(1,1,2,3,5,...)生成一个5行4列的numpy数组,数组名为E
# 请在此填写代码
x=[]
i=0
a=1
b=1
while i<20:
x.append(a)
a,b=b,a+b
i+=1
E=np.array(x)
E=E.reshape(5,4)
########## end ##########
print(E)
#6使用numpy的logspace函数,创建初值为1,终止为1000,元素个数为4的等比数组
########## begin ##########
# 请在此填写代码
G=np.logspace(0,3,4)
########## end ##########
print(G)第2关:求二维数组中最大值及所在的位置
本关任务:用二维数组输出指定行数的等腰三角形格式的杨辉三角形(输出时,每个数据占3位并右对齐)
旁边说明了这关的方法,其实就是常规的循环稍做改动。
# -*- coding: utf-8 -*-
import numpy as np
n,m=map(int,input().split(' '))
np.random.seed(7)
a=[np.random.randint(1,100) for i in range(n*m)]
b=np.array(a).reshape(n,m)
row,col=1,1
maxx=b[0,0]
###################begin################
#在此填写代码
for i in range(n):
for j in range(m):
if b[i,j] > maxx:
maxx = b[i,j]
row,col = i+1 , j+1
#############end################
print("最大值为:%d" %maxx)
print("所在位置为:%d行%d列" %(row,col))
第3关:用二维数组输出指定行数的等腰三角形格式的杨辉三角形
本关任务:用二维数组输出指定行数的等腰三角形格式的杨辉三角形(输出时,每个数据占3位并右对齐)
这关答案是上课给的,因为实际输出格式很难和答案完全对应。
# -*- coding: utf-8 -*-
#输出n行的杨辉三角形
import numpy as np
n=int(input())
a=[0]*n**2
b=np.array(a ).reshape(n,n)
for i in range(n):
b[i,0]=1
b[i,i]=1
############begin###########################
#填写代码开始
for j in range(1,i):
b[i,j] = b[i-1 , j-1] + b[i-1, j]
for i in range(n):
print(' '*(n-i-1), end='')
for j in range(i):
print('%3d ' % b[i,j],end='')
print("%3d"%b[i,i])
##########end###############################
AI-智能应用-慕课学习与练习
-
1、
以下哪个不是大数据的特征( C)
A、价值密度低
B、数据类型繁多
C、访问时间短
D、处理速度快
-
2、
下面哪一个不是大数据的关键技术(D )
A、云计算
B、分布式文件系统
C、数据众包
D、关系型数据库
-
3、
数据清洗的方法不包括(C )
A、缺失值处理
B、噪声数据清除
C、一致性检查
D、重复数据记录处理
-
4、
下列关于大数据的说法中,错误的是(A )
A、大数据具有体量大、结构单一、时效性强的特征
B、处理大数据需采用新型计算架构和智能算法等新技术
C、大数据的应用注重相关分析而不是因果分析
D、大数据的目的在于发现新的知识与洞察并进行科学决策
-
5、
下列哪项通常是集群的最主要瓶颈 (C )
A、CPU
B、网络
C、磁盘IO
D、内存
-
6、
下列关于MapReduce说法不正确的是( C)
A、MapReduce是一种计算框架
B、MapReduce来源于google的学术论文
C、MapReduce程序只能用java语言编写
D、MapReduce隐藏了并行计算的细节,方便使用
-
7、
关于大数据的价值密度描述正确的是以下哪个? (A )
A、大数据由于其数据量大,所以其价值密度低。
B、大数据由于其数据量大,所以其价值也大。
C、大数据的价值密度是指其数据类型多且复杂。
D、大数据由于其数据量大,所以其价值密度高。
-
8、
下列( C)应用领域不属于人工智能应用。
A、人工神经网络
B、自动控制
C、信息管理系统
D、专家系统
-
9、
步行机器人的行走机构多为(C )
A、滚轮
B、履带
C、连杆机构
D、齿轮机构
-
10、
机器人系统的组成与结构主要有三大部分组成,不包括下面哪一个( C)
A、机械部分
B、传感部分
C、输出部分
D、控制部分
AI-智能决策-慕课学习与练习
-
1、
遗传算法是模拟自然界的(C )现象提出的算法。
A、自然选择
B、人工选择
C、适者生存
-
2、
遗传算法的基本操作包括(ABC )
A、选择
B、交叉
C、变异
D、遗传
-
3、
模拟退火算法是模拟(B )的过程
A、灭火
B、金属退火
C、物体退火
-
4、
模拟退火算法与爬山法的不同是( B)
A、优先选择最优解
B、以一定概率接收较差的解
C、始终选择最优解
-
5、
受自然界现象或原理启发而提出的智能优化算法包括(ABC )
A、遗传算法
B、蚁群算法
C、粒子群优化算法
D、始终选择最优解
-
6、
典型的智能决策系统包括(ABCD )
A、知识库
B、模型库
C、方法库
D、数据库
-
7、
构成状态空间的4个要素是( B)
A、开始状态、目标状态、规则和操作
B、初始状态、中间状态、目标状态和操作
C、空间、状态、规则和操作
D、开始状态、中间状态、结束状态和其他状态
-
8、
专家系统是以( C)为基础,以推理为核心的系统。
A、专家
B、软件
C、知识
D、解决问题
-
9、
下列说法错误的是(C )
A、解的适应度是演化过程中进行选择的唯一依据。
B、优胜劣汰的选择机制使得适应值大的解有较高的存活率,这是遗传算法与一般搜索算法的主要区别之一。
C、模拟退火算法允许向坏的方向移动以摆脱局部最大值,这种移动随着时间的推移概率逐步上升。
D、搜索算法本质上是一个程序,旨在找到到达目标的最佳或最短路径。
-
10、
粒子群优化算法在迭代过程中,粒子通过跟踪两个“极值”(B )和( C)来搜索最优解。
A、群体极值
B、个体极值
C、全局极值
D、粒子极值
AI-机器学习-慕课学习与练习
-
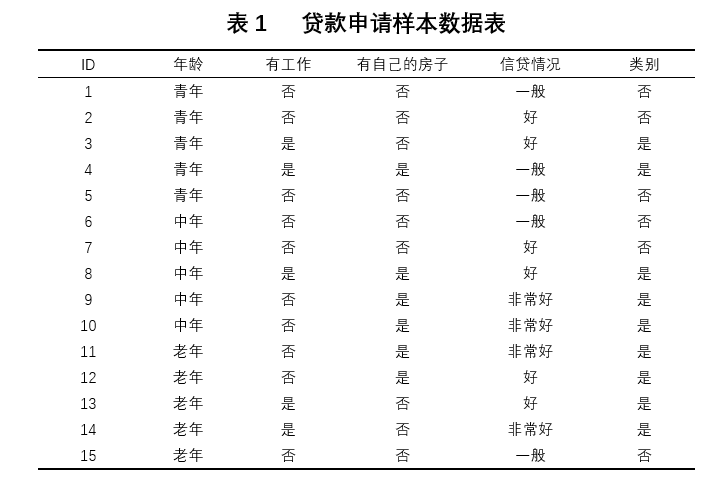
表1是一个由15个样本组成的贷款申请训练数据,这些数据包括贷款申请人的年龄、是否有工作、是否有房子以及信贷情况信息,表的最后一列表示是否同意该客户贷款。利用这些样本训练一棵决策树,再利用得到的决策树决定对于一个新的客户,是否同意其贷款。该问题属于(AC )。
A、监督学习
B、非监督学习
C、二分类问题
D、多分类问题
-
2、
对于表1所给的训练数据集D,根据信息增益准则选择最优特征。分别以A_1,A_2,A_3,A_4表示年龄、有工作、有自己的房子和信贷情况4个特征。现已经计算出经验熵H(D)=0.971,不同特征划分下D的经验条件熵也已经通过计算得到:H(D|A_1 )=0.888,H(D|A_2 )=0.647,H(D|A_3 )=0.551,H(D|A_4 )=0.608。则应选取特征(C )作为最优特征。
A、年龄
B、有工作
C、有自己的房子
D、信贷情况
-
3、
在构建决策树的过程中,下列情况中不会导致出现叶子结点的是(D )。
A、当前数据集以特征“年龄”划分,年龄取值为“老年”的样本全是正例
B、当前数据集已经分别以“年龄”、“有工作”、“有自己的房子、”“信贷情况”为标准进行划分,但数据集仍包含正例和反例
C、当前数据集以特征“信贷情况”划分,但当前数据集已经没有信贷情况为“好”的样本了
D、当前数据集已经经过“年龄”、“有工作”两个特征的划分,现以“信贷情况”为标准进行划分,信贷情况为“一般”的集合包含一个正例和两个反例
-
4、
以下关于k近邻算法的说法中,错误的是(AB )
A、k近邻法中,当训练集、距离度量、分类决策规则确定后,其结果唯一确定
B、k取值过小会导致过拟合,因此k值应尽可能大
C、k近邻算法中的分类决策规则往往是多数表决,它等价于经验风险最小化
D、k近邻算法虽然易于实现,但需要存储全部训练样本,计算量较大
-
5、
数据点(1,3)和(5,6)之间的欧氏距离和曼哈顿距离分别是(B )。
A、5,5
B、5,7
C、7,5
D、7,7
-
6、
以下两个图中,训练集、距离度量、分类决策规则都相同的情况下,k值的大小关系为(C)。
A、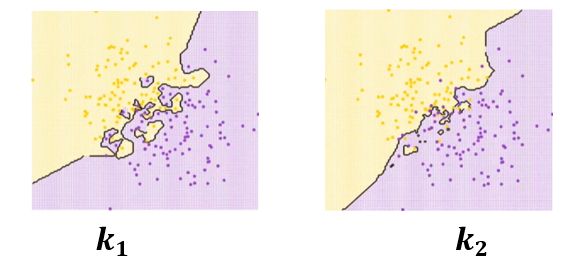
B、k1>k2
C、k1=k2
D、k1无法确定
-
7、
以下关于K-means算法的说法中,正确的是( D)。
A、K-means算法是一种聚类方法,属于监督学习
B、在训练初始阶段,K-means算法需要先学习样本的类别数和初始类别中心
C、不同的初始聚类中心对聚类结果影响不大
D、K-means算法容易陷入局部最优
-
8、
以下哪个网络属于多层前馈神经网络( A)
A、
B、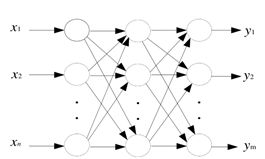
C、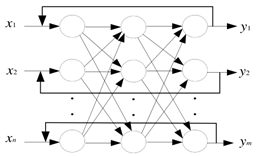
D、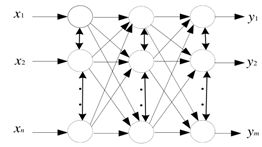
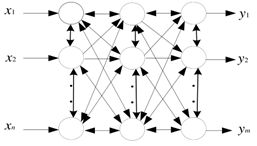
-
9、
以下关于神经元和感知机的说法中,错误的是(D )。
A、人工神经元主要由一组连接、一个加法器、一个激活函数组成
B、理想激活函数是阶跃函数, 其中0表示抑制神经元而1表示激活神经元
C、相较于阶跃函数,Sigmoid函数具有连续、光滑的优点
D、感知机由两层或两层以上神经元组成,可以解决复杂的问题
-
10、
以下关于误差逆传播算法的说法中,错误的是(B )。
A、BP算法基于梯度下降策略, 以目标的负梯度方向对参数进行调整
B、学习率η过大会导致震荡,因此越小越好
C、BP算法容易陷入局部最小
D、BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络
AI-机器感知-慕课学习与练习
-
1、
目标检测算法的主要目的是找到图像中用户感兴趣的语义对象的( C)
A、位置
B、类别
C、位置和类别
D、语义相关性
-
2、
以下哪项不是计算机中常用的颜色模型(D)
A、RGB
B、YCbCr
C、HSV
D、XYZ
-
3、
以下哪项图像变换操作会影响图像的清晰度(C)
A、图像旋转
B、图像缩小
C、图像放大
D、图像平移
-
4、
相比于二阶段目标检测算法,一阶段目标检测算法主要的优点是(B)
A、准确度高
B、速度快
C、运行内存小
D、模型简单
-
5、
相比于一阶段目标检测算法,二阶段目标检测算法主要的优点是(A):
A、准确度高
B、速度快
C、运行内存小
D、模型简单
-
6、
一阶段目标检测算法的主要原理是(B):
A、首先生成大量的枚举框,再采用深度学习算法提取特征并每个枚举框进行分类
B、采用回归的方式计算真实框与锚框之间的位置偏差和类别偏差
C、首先生成大量的枚举框,再采用传统的特征提取算法提取特征并每个枚举框进行分类
D、将目标检测问题转换为分类问题,通过枚举、特征提取和分类建立模型
-
7、
YOLO算法的损失函数不包括下列哪个部分( D)
A、对象分类误差
B、对象定位误差
C、对象置信度误差
D、非对象分类误差
-
8、
YOLO算法中锚框的大小和数量的设置是(A )
A、人工设置
B、机器自动学习
C、既可人工设置也可机器自动学习
D、以上都不是
-
9、
YOLO算法中一个锚框所带的参数不包括(D)
A、location
B、objectiveness
C、classification
D、non-objectiveness
-
10、
非极大抑制算法保留的候选框是(C )
A、置信度最高的前K个候选框
B、置信度最高且位置具有多样性的前K个候选框
C、置信度最高的前K个不相互重叠的候选框
D、不相互重叠的K个候选框