梯度下降推导及案例
最美的等待是,我们——未来可期。
场景引入
梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
我们同时可以假设这座山最陡峭的地方是无法通过肉眼立马观察出来的,而是需要一个复杂的工具来测量,同时,这个人此时正好拥有测量出最陡峭方向的能力。所以,此人每走一段距离,都需要一段时间来测量所在位置最陡峭的方向,这是比较耗时的。那么为了在太阳下山之前到达山底,就要尽可能的减少测量方向的次数。这是一个两难的选择,如果测量的频繁,可以保证下山的方向是绝对正确的,但又非常耗时,如果测量的过少,又有偏离轨道的风险。所以需要找到一个合适的测量方向的频率,来确保下山的方向不错误,同时又不至于耗时太多!
Gradient Descent
相关概念
1.步长或学习效率(learning rare):步长决定在梯度下降过程中,每一步沿梯度负方向前进的距离。
2.假设函数(hppothesis function):也就是我们的模型学习到的函数 记为 h_θ(x) = θ0x0+θ1+x1+θ2x2+…=θTX
3.损失函数(loss function): 损失函数是用来评估模型h_θ(x)的好坏,通常用损失函数来度量拟合的程度,线性回归中损失函数通常为label和假设函数输出的差的平方。自己理解为(实际值-真实值)的平方。
损失函数
梯度下降的基本过程就和下山的场景很类似。
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向(在后面会详细解释) 所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。那么为什么梯度的方向就是最陡峭的方向呢?接下来,我们从微分开始讲起
微分
看待微分的意义,可以有不同的角度,最常用的两种是:
- 函数图像中,某点的切线的斜率
- 函数的变化率
- 几个微分的例子:

梯度
梯度实际上就是多变量微分的一般化。 下面这个例子:

算法过程
1.先决条件:确认优化模型的假设函数h_θ(x)和损失函数J_(θ)

2.参数的初始化: 初始化假设函数的参数θ(注:θ是一个向量),算法中止距离ϵ以及步长α
3.确定当前位置的损失函数的梯度,对于θ_j,梯度如下

4.确定是否所有的θ_j,梯度下降的距离都小于ϵ,如果小于则算法中止,当前为最后结果,否则,则重复步骤(3)
5.更新所有的θ,对于θ_j(其更新的表达式如下

梯度下降的形式BGD、SGD、以及MBGD
三种算法中文名分别为
- 批量梯度下降(Batch gradient descent)
批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新 优点:全局最优解;易于并行实现; 缺点:当样本数目很多时,训练过程会很慢。
- 随机梯度下降(Stochastic gradient descent)
随机梯度下降是通过每个样本来迭代更新一次, 如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。 优点:训练速度快; 缺点:准确度下降,并不是全局最优;不易于并行实现。
- 小批量梯度下降(Mini-batch gradient descent)
有上述的两种梯度下降法可以看出,其各自均有优缺点,那么能不能在两种方法的性能之间取得一个折衷呢?即,算法的训练过程比较快,而且也要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷。MBGD在每次更新参数时使用b个样本(b一般为10) 不过都叫梯度下降算法,可见他们的核心是没有变的,变化的只是取训练集的方式,而梯度下降最核心的就是对函数求偏导,这个是在高等数学里有的。
Practice
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
#构造训练数据 h(x)
x = np.arange(0.,10.,0.2)
m = len(x)
x0=np.full(m,1.0)
train_data = np.vstack([x0,x]).T #通过矩阵变化得到测试集【x0,x1】
y = 4*x+1+np.random.randn(m)#构造“标准”答案
def BGD(alpha,loops,epsilon):
'''
alpha:步长
loops:循环次数
epsilon:收敛精度
'''
count=0#loop次数
thata = np.random.randn(2)#随机thata向量初始的值也就是起点位置
err = np.zeros(2)#上次thata的值,初始化为0的向量
finish=0#完成标志位
result = []
while count<loops:
count+=1
#所有训练数据的期望更新一次thata
sum = np.zeros(2)#初始化thata更次年总和
for i in range(m):
cost = (np.dot(thata,train_data[i])-y[i])*train_data[i]
sum+=cost
thata = thata-alpha*sum
result.append(np.linalg.norm(thata-err))
if np.linalg.norm(thata-err)<epsilon:#判断是否收敛
finish = 1
break
else:
err=thata#没有则将当前thata向量赋值给err,作为下次判断参数
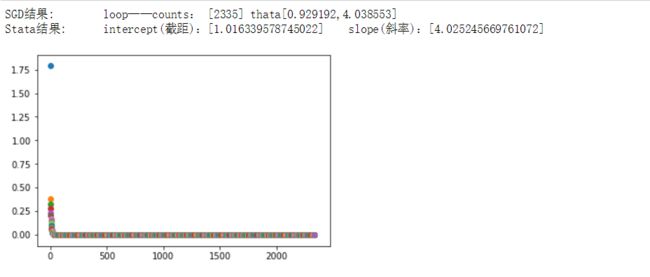
print (f'SGD结果:\tloop——counts: [%d]\tthata[%f,%f]'%(count,thata[0],thata[1]))
return thata,result
if __name__=='__main__':
result=[]
thata,result=BGD(0.00009,10000,1e-4)
slope,intercept,r_value,p_value,slope_std_error=stats.linregress(x,y)
print(f'Stata结果:\tintercept(截距):[%s]\tslope(斜率):[%s]'%(intercept,slope))
for i in range(len(result)):
plt.scatter(i,result[i])
#plt.plot(x,y,'k+')
#plt.plot(x,thata[1]*x+thata[0],'r')
plt.show()
结果如下