go笔记——map
map的底层实现的原理
Go中的map是一个指针,占用8个字节,指向hmap结构体
源码包中src/runtime/map.go定义了hmap的数据结构:
hmap包含若干个结构为bmap的数组,每个bmap底层都采用链表结构,bmap通常叫其bucket

hmap结构体
// A header for a Go map.
type hmap struct{
count int
//代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8
//状态标志(是否处于正在写入的状态等跖)
B uint8
// buckets(桶)的对数
//如果B=5,则buckets数组的长度=2^B=32,意味着有32个桶
noverflow uint16
//溢出桶的数量
hash0 uint32
//生成hash的随机数种子
buckets unsafe.Pointer
//指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil
oldbuckets unsafe.Pointer
//如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
nevacuate uintptr
//表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra
//存储溢出桶,这个字段是为了优化GC扫描而设计的,下面详细介绍
}
bmap的结构体
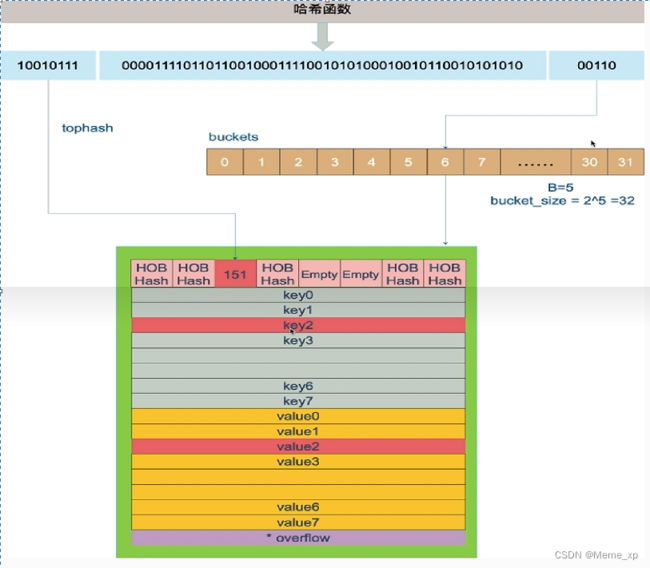
bmap就是我们常说的"桶" 一个桶里面会最多装8个key,这些key之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低B位是相同的,关于key的定位我们在map的查询中详细说明。在桶内,又会根据key 计算出来的 hash值的高8位来决定key到底落入桶内的哪个位置(一个桶内最多有8个位置)。
//A bucket for a Go map.
type bmap struct {
tophash [bucketcnt]uint8
//len为8的数组
//用来快速定位key是否在这个bmap中
//一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}
上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype由编译器编译时候确定
values [8]elemtype
// elemtype由编译器编译时候确定
overflow uintptr
// overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
小总结:
1.tophash就是用于实现快速定位key的位置,在实现过程中会使用key的hash值的高8位作为tophash值,存放在bmap的tophash字段中
2.tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于minTopHash的
为了避免key哈希值的高8位值和这些状态值相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值加上minTopHash作为该key的tophash.单元的状态值如下:
emptyRest = 0 //表明此桶单元为空,且更高索引的单元也是空
empty0ne=1 //表明此桶单元为空
evacuatedX=2 //用于表示扩容迁移到新桶前半段区间
evacuatedY=3 //用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 //用于表示此单元已迁移
minTopHash= 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >>lgoarch.PtrSize*8 -8))
if top < minTopHash {
top += minTopHash
}
return top
}
mapextra结构体
当map的key和value都不是指针类型时候,brmap将完全不包含指针,那么gc时候就不用扫描bmap, bmap指向溢出桶的字段overflow是uintpt类型,为了防止这些overfiow桶被gc掉,所以需要mapextra.overlow将它保存起来。如果bmap的overflow是"bmap类型,那么gc扫描的是一个个拉链表,效率明显不如直接扫描一段内存(hmap.mapextra.overflow)
type mapextra struct {
overflow *[] *bmap
//overflow包含的是hmap.buckets 的overflow的buckets
oldoverflow * [ ]*bma
// oldoverflow包含扩容时 hmap.oldbuckets的overflow的bucket
nextoverflow *bmap
//指向空闲的overflow bucket的指针
}
map的底层数据结构,一共有三层最外层是一个哈希表,第二层是桶的数组,第三层是溢出桶,通过链表形式连接起来,所有的溢出桶在extra这个这里面的
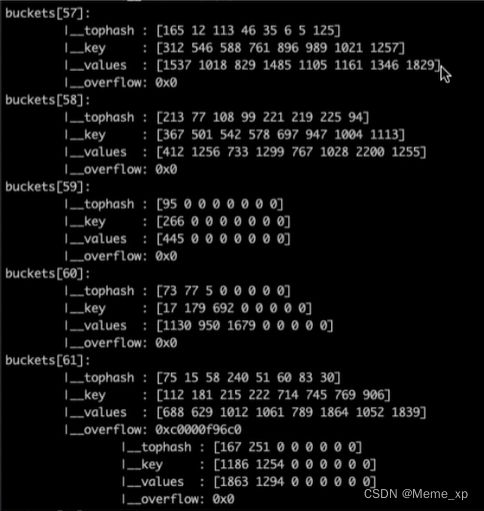
注意到key和value 是各自放在一起的,并不是(key/value/key/valuel/…这样的形式,当key和value类型不一样的时候,key和value占用字节大小不一样,使用keylvalue这种形式可能会因为内存对齐导致内存空间浪费,所以Go采用key和value分开存储的设计,更节省内存空间!!!!!!!!!!!!!
go map的遍历为什么是无序的?
使用range多次遍历map时输出的key和value的顺序可能不同。这是Go语言的设计者们有意为之,旨在提示开发者们,Go底层实现并不保证map遍历顺序稳定,请大家不要依赖range遍历结果顺序
先随机选桶,再随机桶里面
主要原因有2点:
1.map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
2.map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的Key,
搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了
map本身是无序的,且遍历时顺序还会被随机化,如果想顺序遍历map,需要对 map key 先排序,再按照 key 的顺序遍历map。
如何按顺序遍历
func TestMapRange(t *testing.T){
m:= map[int]string{1: "a",2:"b",3: "c"}
t.Log(""first range: "")
for i, v := range m {
t.Logf("m [%v]=%v ",i,v)
t.Log("second range: ")
for i, v := range m {
t.Logf("m[%sv]=%v". i,v)
//实现有序遍历
var sl []int
//把key单独取出放到切片
for k := range m {
sl = append(sl,k)
}
//排序切片
sort.Ints(sl)
//以切片中的key顺序遍历map就是有序的了
for _. k := range sl {
t.Log(k,m[k])
}
map为什么不是线程安全
map默认是并发不安全的,同时对map进行并发读写时,程序会panic
原因如下:
go官方在经过了长时间的讨论后,认为Go map,更应适配典型使用场景(不需要从多个gooutine中进行安全访问),而不是为了小部分情况(并发访问),导致大部分程序付出加锁代价(性能),决定了不支持。
场景:2个协程同时读和写,以下程序会出现致命错误: fatal error: concurrent map writes
如何实现并发访问
1.使用读写锁map+sync.RWMutex
2.使用sync.Map
map如何进行查找
Go语言中读取map有两种语法︰带comma和不带comma。当要查询的key不在map里,带comma的用法会返回一个bool型变量提示key是否在map中;而不带comma的语句则会返回一个value类型的零值。如果value是int型就会返回0,如果value是string类型,就会返回空字符串。

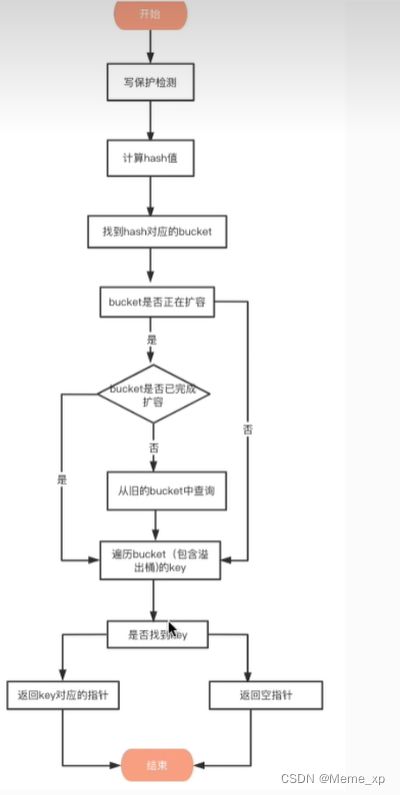
查找的流程:
map冲突解决的办法
比较常用的Hash冲突解决方案有链地址法和开放寻址法:
链地址法
当哈希冲突发生时,创建新单元,并将新单元添加到冲突单元所在链表的尾部。
开放寻址法
当哈希冲突发生时,从发生冲突的那个单元起,按照一定的次序,从哈希表中寻找一个空闲的单元,然后把发生冲突的元素存入到该单元。开放寻址法需要的表长度要大于等于所需要存放的元素数量
开放寻址法有多种方式∶线性探测法、平方探测法、随机探测法和双重哈希法。这里以线性探测法来帮助读者理解开放寻址法思想
线性探测法
设Hash( key)表示关键字key的哈希值,表示哈希表的槽位数(哈希表的大小)。
线性探测法则可以表示为:
如果Hash(x) % M已经有数据,则尝试(Hash(x) + 1)%N;
如果(Hash(x)+ 1)%M也有数据了,则尝试((Hashlx)+ 2)% M;如果(Hash(×) + 2)%也有数据了,则尝试(Hash(x) + 3)% M;
两种解决方案比较
对于链地址法,基于数组+链表进行存储,链表节点可以在需要时再创建,不必像开放寻址法那样事先申请好足够内存,因此
1.链地址法对于内存的利用率会比开方寻址法高。
2.链地址法对装载因子的容忍度会更高,并且适合存储大对象、大数据量的哈希表。
3.较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
对于开放寻址法,它只有数组一种数据结构就可完成存储,继承了数组的优点,对CPU缓存友好,易于序列化操作。但是它对内存的利用率不如链地址法,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
总结
在发生哈希冲突时,Python中dict采用的开放寻址法,Java的HashMap采用的是链地址法,而Go map也采用链地址法解决冲突,具体就是插入key到map中时,当key定位的桶填满8个元素后(这里的单元就是桶,不是元素),将会创建一个溢出桶,并且将溢出桶插入当前桶所在链表尾部。
map的负载因子为什么是6.5
什么是负载因子?
负载因子(load factor),用于衡量当前哈希表中空间占用率的核心指标,也就是每个 bucket桶存储的平均元素个数。
负戴因子=哈希表存储的元素个数/桶个数
另外负载因子与扩容、迁移等重新散列(rehash)行为有直接关系:
·在程序运行时,会不断地进行插入、删除等,会导致 bucket不均,内存利用率低,需要迁移。在程序运行时,出现负载因子过大,需要做扩容,解决 bucket过大的问题。
负载因子是哈希表中的一个重要指标,在各种版本的哈希表实现中都有类似的东西,主要目的是为了平衡buckets 的存储空间大小和查找元素时的性能高低。在接触各种哈希表时都可以关注一下,做不同的对比,看看各家的考量。
为什么是6.5?
为什么Go语言中哈希表的负载因子是6.5,为什么不是8,也不是1。这里面有可靠的数据支撑吗?
看一份测试报告
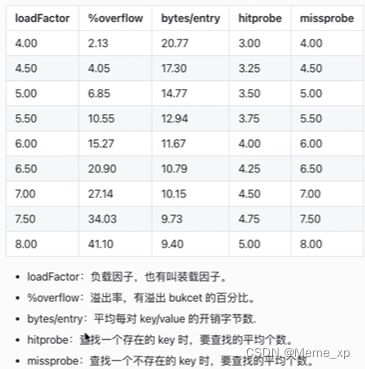
装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数
根据这份测试结果和讨论,Go官方取了一个相对适中的值,把Go中的 map的负载因子硬编码为6.5,这就是6.5的选择缘由。
这意味着在Go语言中,当map存储的元素个数大于或等于6.5*桶个数时,就会触发扩容行为
map什么时候扩容?
向map中插入如新的key时候会发生下面两个条件的检测
1.超过负载
map元素的个数>6.5*桶的个数
2.溢出桶太多了
2.1当桶总数<2^15时,如果溢出桶总数>=桶总数,则认为溢出桶过多。
2.2当桶总数>= 2^15 时,直接与 2^15 比较,当溢出桶总数>=2^15时,即认为溢出桶太多了。
对于条件2,其实算是对条件1的补充。因为在负载因子比较小的情况下,有可能map的查找和插入效率也很低,而第1点识别不出来这种情况。
表面现象就是负载因子比较小比较小,即map里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶),比如不断的增删,这样会造成oveflow的bucket数量增多,但负载因子又不高,达不到第1点的临界值,就不能触发扩容来缓解这种情况。这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了第2扩容条件。
map扩容机制
双倍扩容:针对条件1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为双倍扩容
等量扩容:针对条件2,并不扩大容量,buckets数量维持不变,重新做一遍类似双倍扩容的搬迁动作,把松散的键值对金新排列一次,使得同一个 bucket中的 key排列地更紧密,节省空间,提高bucket利用率,进而保证更快的存取。该方法我们称之为等量扩容。
扩容函数hashGrow()
上面说的 hashbrow()函数实际上并**没有真正地"搬迁",**它只是分配好了新的 buckets,并将老的 buckets挂到了 oldbuckets字段上。真正搬迁 buckets的动作在grollork()函数中,而调用 groMiork()函数的动作是在mapassign和mapdelete函数中。也就是插入或修改、删除key 的时候,都会尝试进行搬迁 buckets的工作.先检查oldbuckets是否搬迁完毕,具体来说就是检查oldbuckets 是否为nil
渐进式搬迁:每一次只搬迁两个bucket,防止造成较大的延迟
map和sync.Map谁的性能好?
对比原始map:
和原始map+RWLock的实现并发的方式相比,减少了加锁对性能的影响。它做了一些优化:可以无锁访问read map,而且会优先操作read map,倘若只操作ead maep就可以满足要求,那就不用去操作write map(dirty),所以在某些特定场景中它发生锁竞争的频率会远远小于map+RWLock的实现方式
优点:
适合读多写少的场景
缺点:
写多的场景,会导致read map缓存失效,需要加锁,冲突变多,性能急剧下降