postgresql数据库优化
目录
概要
优化方法
硬件知识
CPU及服务器体系结构
内存
硬盘
文件系统及I/O调优
文件系统的崩溃恢复
Ext2文件系统
Ext3文件系统
Ext4文件系统
XFS文件系统
Barriers I/O
I/O调优的方法
SSD的Trim优化
数据库性能视图
Linux监控工具
数据库内存优化
大页内存配置
vacuum 中的优化
预写式日志写优化
概要
数据库优化的思路有很多种。比较常用的是下面两种优化思路。
·第一种思路:有人说过,“The fastest way to do something is don't do it”,意思是说,“ 做得最快的方法就是不做”。从这个思路上来说,把一些无用的步骤或作用不大的步骤去
掉就是一种优化。
·第二种思路:做同样一件事情,要想更快有多种方法,最简单的方法就是换硬件,
让数据库跑在更快的硬件上。但换硬件一般都是最后的选择,除此之外,最有效的方法是优化算法,如让SQL走到更优的执行计划上。
在数据库优化中,主要有以下优化指标。
·响应时间:衡量数据库系统与用户交互时多久能够发出响应。
·吞吐量:衡量在单位时间内可以完成的数据库任务。
进行数据库优化时,笔者都是围绕着上述指标进行优化的。
数据库优化工作中,第一项就是确定优化目标。
·性能目标:如CPU利用率或IOPS需要降到多少。
·响应时间:需要从多少毫秒降到多少毫秒。
·吞吐量:每秒处理的SQL数或QPS需要提高到多少。
一个已运行的数据库系统,如果前期设计不合理、性能不高,后期在优化时会非常困难,有可能永远无法达到高性能,因此,在新建一套数据库系统前,首要的事应该是设计优化。良好的设计能最大限度地发挥系统的性能。
优化方法
优化的第一件事是确定目标,那么要如何确定一个合理的目标呢?这就需要使用测试工具。熟练使用常用的测试工具是做数据库优化的基础。下面是一些常用的测试工具。
·memtest86+:内存测试工具。
·STREAM:内存测试工具。
·sysbench:综合测试工具,可以测试CPU、I/O、数据库等。
·pgbench:PostgreSQL自带的测试工具,可以仿真TPC-B的测试模型。
·fio:最强大的免费I/O测试工具。
·orion:Oracle的I/O测试工具,测试裸设备的I/O能力,功能比fio要少,但使用简单。
熟练掌握以上几种测试工具的使用方法,对数据库的优化很有帮助。在数据库优化中,首先需要了解一些常用硬件的相关知识,熟悉这些硬件的特性和性能,才能知道目前数据库系统使用的硬件是否到达了瓶颈、更换硬件是否能提高数据库的性能。
硬件知识
CPU、内存、网络、硬盘的响应时间和吞吐量都是不一样的,了解这些知识,有助于
理解如何优化硬件。
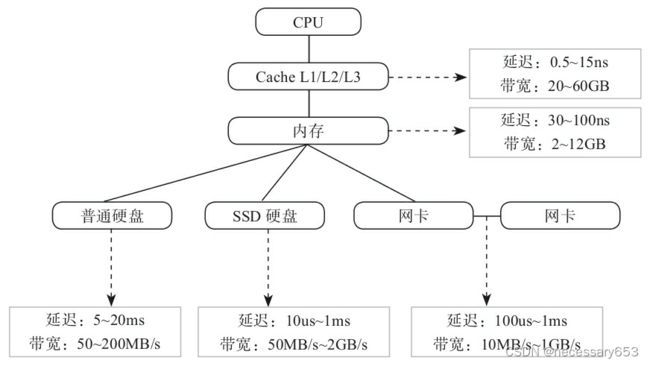
CPU、内存、网络、硬盘等各层次的响应时间
下面将介绍有关硬件的基础知识和部分硬件的性能。虽然不要求记住各种硬盘的详细性能情况,但需要了解某种硬件的性能在哪个数量级上。
CPU及服务器体系结构
服务器系统可以分为以下几种体系结构。
(1)SMP/UMA -Symmetric Multi Processing/Uniform Memory Architecture
·优点:服务器中多CPU对称工作,无主次关系。各CPU共享相同的物理内存,访问内存任何地址所需的时间相同,因此程序设计较为简单。
·缺点:因多CPU无主次关系,需要解决内存访问冲突,所以硬件实现成本高。
(2)NUMA-Non-Uniform Memory Access
·优点:多CPU模块,每个CPU模块具有独立的本地内存(快),但访问其他CPU内存(慢),硬件实现成本低。
·缺点:全局内存访问性能不一致;设计程序时需要特殊考虑。
(3)MPP-Massive Parallel Processing
·优点:由多个SMP服务器通过节点互联网络连接而成,每个节点都可访问本地资源(内存、存储等),完全无共享(Share-Nothing)。最易扩展,软件层面即可实现。
·缺点:数据重分布;程序设计复杂。
目前,Intel的X86架构属于NUMA架构。
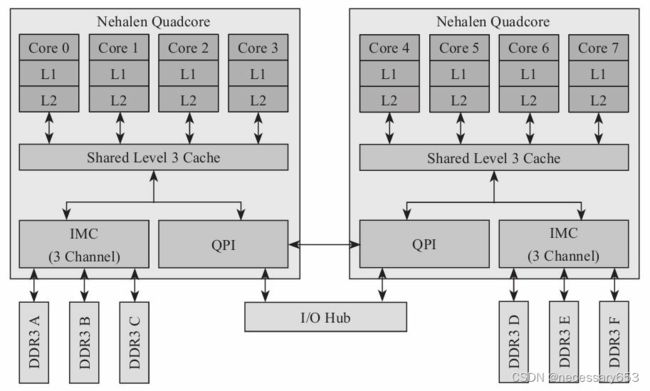
从图中可以看到,两颗4核的CPU通过总线连接,内存分别连接到各自的CPU上。所以从一个CPU的内存访问挂在另一个CPU上的内存,速度会慢一些。
下面介绍一些CPU的相关知识。先看看CPU的部分术语。
·主频:CPU的时钟频率,内核工作的时钟频率。
·外频:系统总线的工作频率。
·倍频:CPU外频与主频相差的倍数。
·前端总线:将CPU连接到北桥芯片的总线。
·总线频率:与外频相同,或者是外频的倍数。
·总线数据带宽:(总线频率×数据位宽)/8。
Intel CPU有以下3级cache。
·L1、L2级cache:核心core独占;带宽为20~80GB/S;延时为1~5ns。
·L3级cache:核心core之间共享;带宽为10~20GB/S;延时为10ns。
Intel CPU通过QPI(QuickPath Interconnect技术)与其他CPU通信,QPI大约在20GB/s
内存
内存是CPU与外部沟通的桥梁。CPU运算时所需的数据都临时保存在内存中,计算机的所有程序也都运行在内存中,内存通常也用于硬盘等外部存储器的数据缓存。
内存从硬件上分为以下几种。
·SRAM:静态随机存储器。随机是指数据不是线性依次存储的,而是自由指定地址进行数据读写的。CPU的cache一般使用这种存储方式,特点是速度快但造价高,不能大规模使用。
·DRAM:动态随机存储器。动态是指存储阵列需要不断刷新来保证数据不丢失。造价比SRAM低得多,但速度也慢一些。
·SDRAM:同步动态随机存储器,同步是指工作时需要同步时钟,内部命令的发送与数据的传输都以它为基准。
·DDR SDRAM:双倍数据传输率的SDRAM,DDR是“Double Data Rate”的缩写。普通的SDRAM在一个时钟周期内只传输一次数据,即它在时钟的上升期进行数据传输;而DDR内存则在一个时钟周期的上升期和下降期各传输一次数据,因此称为双倍速率同步动态随机存储器。DDR内存又分DDR1、DDR2、DDR3、DDR4几种,分别对应第一代、第二代、第三代、第四代DDR。目前主流的内存为DDR4内存。
硬盘
硬盘按接口可以分为以下3种。
·ATA系列:包括较早的硬盘接口,比如IDE(Integrated Drive Electronics)、PATA(Parallel ATA)及SATA(Serial ATA)。
·SCSI系列:包括早期的并行SCSI和现在使用较广泛的SAS(串行SCSI)。
·FC接口:支持FC协议接口的硬盘。
FC接口的硬盘一般只在专用存储上使用,通常见到的硬盘都是SATA或SAS接口的。
硬盘按存储介质来区分,可以分为以下两种。
·HDD:普通机械硬盘。
·SSD:固态硬盘。
机械硬盘和SSD硬盘都有SATA和SAS接口的这两种。
硬盘通常通过SAS或SATA接口的卡连接到主机上。SAS卡既能接SAS硬盘,也能接SATA硬盘,但SATA卡只能接SATA硬盘。
目前SAS的接口速度一般是3Gb/s或6Gb/s。
目前在服务器上使用的硬盘其大小有以下两种:
·2.5英寸。
·3.5英寸。
当前SSD硬盘的大小一般是2.5英寸。
机械硬盘的转速通常有以下几种:
·7200转,目前大多数的SATA硬盘都是7200转。
·10000转。
·15000转。
转速的单位是转/分钟,也就是10000转的硬盘的转速实际是1分钟10000转。
机械硬盘有以下性能指标。
·平均寻道时间(E):15000转的SAS硬盘为4ms左右。
·旋转延时(L):15000转的SAS硬盘为2ms左右。
·内部传输时间(X):通常为0.8ms。
·吞吐率(Throughput):15000转的SAS硬盘为170Mb/s左右,机械硬盘为50~200Mb/s。
·磁盘服务时间:RS=E+L+X=6.8ms。
·硬盘的IOPS:可以算出硬盘的IOPS=1/RS=1000ms/6.8=147。
SSD硬盘一般分为如下两种。
·SLC:是“Single Layer Cell”的缩写,特点是成本高、容量小、速度快,约10万次擦写寿命。
·MLC:是“Multi-Level Cell”的缩写,特点是容量大、成本低,但速度慢,约1万次擦写寿命。
·TLC:是“Trinary-Level Cell”的缩写,特点是容量最大、成本最低,但速度最慢,约1000次擦写寿命。
MLC并不像SLC一个单元只对应一个比特位。SLC一个单元,根据电压的高低只对应一个比特位,不是0就是1,而MLC一个单元根据电压的高低存储多个值,如0、1、2、3等4个值。所以在MLC中,同样的一个单元中可以存储更多的数据,但也因此要通过不同的电压值来识别出多个值,不像SLC只需要识别出两个值就可以了,所以MLC识别一个单元值的出错概率会增加,必须进行错误修正,这就导致其性能大幅落后于结构简单的SLC闪存。也正是因为这个原因,MLC闪存的复写次数通常只有SLC的十分之一。TLC利用不同电位的电荷来存储,一个浮动栅存储3个bit的信息,TLC的复写次数通常只有MLC的十分之一。目前因为价格的原因,SLC的SSD基本看不到了,大都是MLC和TLC的SSD。
服务器上使用的SSD硬盘的性能指标如下。
·IOPS:读通常可以达到几万以上,写通常在几千以上。
·吞吐率:读通常可以达到250Mb/s以上,写通常可以达到150Mb/s以上。
·响应时间(Latency):读在几十微秒到100微秒之间,写在200微秒到1毫秒之间。擦除时间在2毫秒左右。
SSD硬盘与机械硬盘最大的差别有以下几点:
·SSD的随机性能好。SSD的读IOPS通常在机械硬盘的两个数据级以上,写IOPS也至少是1个数量级以上。但读写吞吐率一般只有机械硬盘的数倍,最多10倍左右。
·SSD内部存在擦除。也就是在重写旧数据时,不能像机械硬盘一样直接改写,而是需要经过一个擦除的过程后,才能再写。每次擦除的数据块比读写的块要大很多,通常在128KB到512KB之间,而读写的块大小通常为4KB。
·SSD中闪存芯片的写次数是有限的,写到一定次数时就会损坏。这个次数通常为10000~100000次。所以SSD内部需要一定的算法,让写比较平均地分散到其他各处。也就是说,如果一直写SSD硬盘的相同逻辑地址的同一个位置,实际写的物理芯片并不是同一个位置。由于物理所需要的“擦除”特性及写寿命等原因,SSD硬盘存在着写放大的情况,也就是说,外部写4K的数据,内部实际写的数据量有可能大大超过这个数值。具体会产生多少的写放大,与应用的I/O特点以及不同SSD厂家内置在SSD内部的平衡写的算法有很大关系。不同厂家的产品会有很大的不同。所以对于考察一款SSD硬盘,除了看IOPS和吞吐率外,还需要测试其I/O性能的抖动情况。
SSD硬盘内部通常有以下几种优化。
·FTL(Flash Translation Layer):物理逻辑地址映射。防止某个逻辑地址写太多次数而损坏芯片。
·Reclamation:异步擦除策略,降低延时。
·Wear Leveling:均衡写磨损,延长寿命。
·Spare Area:预留空间,减少写放大。一般情况下,SSD出厂后,内部会有一部分预留空间,而Intel的SSD用户还可以再多预留一部分空间,这样可以提高写性能。
文件系统及I/O调优
目前PostgreSQL数据库还不支持直接在裸设备上存储数据,也就是说,PostgreSQL的数据必须存储在文件系统上,故而选择一个合适的文件系统对PostgreSQL数据库来说非常重要
文件系统的崩溃恢复
文件系统中除记录文件内容信息外,还记录了一些元数据(如目录树、文件名、文件的块分配列表),以及和文件相关的一些属性(如文件名、文件的创建时间等),还有磁盘的空间分配信息(如哪些块已被分配、哪些块是空闲的)。在写一个文件时,除了写文件的内容信息外,还会写一些元数据。为了保证数据的可靠性,在出现宕机等异常情况后,文件系统除了要保证元数据本身一致,还要求文件内容的数据与元数据之间也是一致的。元数据一致性当然是最重要的,不能将同一个数据块分配给两个文件,这会导致一个文件的内容被另一个文件覆盖。分配出去的数据块必须有文件在使用,否则会导致明明现有文件并未占用多少空间,但文件系统上却没有空间了。当向一个文件的末尾添加数据时,文件会扩大,如果元数据记录了该文件的扩大,但新数据没有实际写入,就会导致新扩大的数据块中存在垃圾数据,这有可能导致问题产生。
早期的文件系统并不能保证元数据与数据的一致性,如Windows下的FAT文件系统和Ext2文件系统。当一个操作需要多次写元数据或一次写元数据一次写数据时,操作中的多个步骤通常不是原子性的,要保证一致性就必须要有类似数据库中的事务的概念。要有事务就需要有日志,也就是说,要通过日志来保证整个操作的一致性。所以现在流行的文件系统都被设计成有日志的,如Ext3、Ext4及Windows下的NTFS文件系统。但写日志相当于原先的一次写变成了两次写,可能会降低写的性能。为了降低对性能的影响,多数文件系统通常只是把元数据写入日志,而实际数据块内容的变更并不会写入日志。如果一个文件已被写过,再写以前的数据块时,不会分配新的数据块;关于空间分配的元数据也不会被更新,通常只更新文件上的时间戳。对于数据库来说,这种情况下通常不会产生不一致,所以数据库使用重写会更安全一些,PostgreSQL中WAL日志的写就是这样的。
Ext2文件系统
早期的Linux系统使用Ext2文件系统。Ext2文件系统不是一种日志文件系统,它的性能比较好,但由于没有日志,在写数据时,如果机器突然宕机,文件系统中的数据可能会不一致。当不一致产生时,因为没有日志,做fsck可能会需要很长时间。基于上述原因,Ext2文件系统并不适合存放PostgreSQL的数据文件。
PostgreSQL中WAL日志文件一般都是事先建好的文件,在初始化到指定大小后再开始写,所以后期的写不会产生元数据的写,机器崩溃也不会导致数据不一致,所以可以把WAL日志放在一个单独的Ext2文件系统中。在PostgreSQL数据库中写WAL日志不是性能的短板,所以不建议选择虽然速度快但有些危险的Ext2文件系统。
Ext3文件系统
Ext3文件系统是Linux下使用最广泛的文件系统,它提供以下3种数据日志记录方式。
·data=writeback:对数据不提供任何日志记录,只记录元数据的变更。所以元数据的写与数据块之间的写的先后顺序及多个数据块写的先后顺序都不能被保证。
·data=ordered:记录元数据,同时在逻辑上将元数据和数据块分组到被称为“事务”的单个单元中。将新的元数据写到磁盘上时,首先写的是相关的数据块,这样就保证了元数据与数据之间的一致性。但如果写一个数据块时出现宕机,有可能出现这个数据块只有一部分被写入,而另一部分还是旧数据的情况。
·data=journal:这种方式提供了完整的数据和元数据日志记录。对于所有新数据,首先写入日志,然后写入它的最终位置。在系统崩溃的情况下可以重放日志,使数据和元数据处于一致的状态。实际操作时,指定日志记录方式的方法如下:
·向/etc/fstab中与此文件系统相关的行中添加适当的字符串,如“data=journal”。
·在调用mount时直接指定 -o data=journal命令行选项。
指定根文件系统的日志记录方式的方法稍有不同,需要在名为“rootflags”的特殊内核引导选项上进行设置,示例如下:
rootflags=data=journal 从理论上说,writeback模式的性能最好,但可靠性最差;journal模式的性能最差,但可靠性最好。如果硬件是带电池的Raid卡,而Raid卡上都有写缓存,在写缓存的帮助下,三者的性能差异并不是很大。因为文件系统日志的写通常是顺序写,这些顺序写的数据写入Raid卡的缓存中后会立即返回,而Raid卡会在后台再把数据刷新到磁盘中,所以这种情况下三种模式的性能差异并不大。在PostgreSQL中通常会使用默认的ordered模式。当然也不应该完全放弃journal模式,因为journal模式提供了更全面的完整性保证。
Ext4文件系统
Ext4是Ext3文件系统的重大改进版,不像Ext3相对于Ext2只是增加了一个日志功能,Ext4修改了Ext3部分重要的数据结构,因此可以提供更佳的性能和更大的可靠性。Linux内核自2.6.28开始正式支持Ext4,不过直到2.6.32才达到一个较稳定的程度,所以建议用户在2.6.32之后的内核中再使用Ext4。
Ext4最有用的功能如下。
·与Ext3兼容:只需执行一些命令就能将Ext3在线迁移到Ext4,而无须重新格式化磁盘或重新安装系统。原有的Ext3数据结构照样保留,Ext4将作用于新数据。
·完善的barrier和fsync功能:Ext3在处理barrie和fsync功能时有一些问题,Ext4真正解决了这些问题,可以让PostgreSQL达到更高的磁盘吞吐量。这在大批量顺序读写时特别有用。
·快速fsck:Ext3中执行fsck第一步就会很慢,因为它要检查所有的inode,现在Ext4给每个组的inode表中都添加了一份未使用inode的列表,在Ext4做fsck时就可以跳过这些未使用的inode节点。
·Extents:Ext3采用间接块映射,当操作大文件时,效率极其低下。比如一个100MB大小的文件,在Ext3中要建立25600项(每个数据块占用一项,数据块大小为4KB)的映射表;而Ext4引入了现代文件系统中流行的extent概念,每个extent为一组连续的数据块,对一个连续的空间,只需要一项就可以表示,这大大提高了效率。
·多块分配:当写数据到Ext3文件系统中时,Ext3的数据块分配器每次只能分配一个4KB的块,写一个1GB文件就要调用256000次数据块分配器,而Ext4的多块分配器(Multiblock Allocator' MBAlloc)支持一次调用分配多个数据块。
·延迟分配:Ext3的数据块分配策略是尽快分配,而Ext4和其他先进的文件系统一样,都是尽可能地延迟分配,直到文件在cache中写完才开始分配数据块并写入磁盘,这样就能让多块分配及extent的性能发挥到最佳。
·在线碎片整理:尽管延迟分配、多块分配和extents能有效减少文件系统碎片,但碎片还是会不可避免地产生。Ext4支持在线碎片整理,并提供了e4defrag工具进行个别文件或整个文件系统的碎片整理。
·日志校验:日志是最重要的部分,硬件原因也会导致日志损坏,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4的日志校验功能可以避免此问题。另外,Ext4将Ext3的两阶段日志机制合并成一个阶段,提高了性能。
·“无日志”(No Journaling)模式:Ext4允许完全关闭日志,以便某些有特殊需求的用户借此提升性能。
·持久预分配(Persistent Preallocation):一些下载软件为了保证下载的文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。Ext4在文件系统层面实现了持久预分配的API函数,即libc中的posix_fallocate(),这种方式比用应用软件实现更高效。
·inode的新特性:Ext4支持更大的inode,Ext3默认的inode大小为128字节,Ext4默认的inode大小为256字节,这样就可以在inode中容纳更多的扩展属性,如纳秒时间戳或inode版本。Ext4还支持快速扩展属性(fast extended attributes)和inode保留(inodes reservation)。
·更大的文件系统和更大的文件:Ext3目前最大支持16TB的文件系统和2TB的文件,Ext4则最大支持1EB(1048576TB,1EB=1024PB,1PB=1024TB)的文件系统以及16TB的文件。
·无限数量的子目录:Ext3目前只支持32000个子目录,而Ext4支持无限数量的子目录。基于以上原因,如果Linux的内核较新,而且版本在2.6.32以上,使用Ext4是不错的选择。
XFS文件系统
XFS与前面讲的Ext3文件系统不同,它从一开始就设计为日志文件系统了,而不像Ext3文件系统的日志功能是后来加上去的。数据库使用XFS会有更高的性能。XFS的日志中只记录元数据,所以XFS从性能上更像Ext3的writeback模式,但XFS在重放日志时会让垃圾块返回全零的数据,而不像Ext3会返回旧数据。PostgreSQL有可能认为旧数据是正确的数据,从而导致产生问题。当返回全零数据时,只要打开PostgreSQL的full_page_writes配置项,PostgreSQL就能用WAL日志自动修复这些全零数据块。从一些第三方的测试数据来看,在性能上,XFS相比Ext3有5%~30%的提高,所以建议在Linux环境下把PostgreSQL数据库建在XFS文件系统上
Barriers I/O
为了保证数据的可靠性,I/O的写顺序很重要。例如,在PostgreSQL数据库中要求必须在写入WAL日志后,数据块的数据才能被写入。但是,存放在cache里的用户发起的写顺序不一定等于实际写入非易失性硬件介质的顺序,因为各级的cache都有可能改变I/O的顺序。例如,在Linux操作系统中,为了提高性能,I/O调度器通过电梯算法改变了I/O的顺序。在Raid卡上也有相应的算法改变I/O的顺序,在硬盘内部也会向几兆到几十兆的内存做cache,硬盘内部有一些算法可通过改变I/O顺序来提高性能。那么是不是就没有办法来保证I/O的顺序性了?当然不是,在操作系统中,为了保证I/O的顺序,专门提供了一种I/O机制,被称为Barriers I/O。Barriers I/O定义如下:
·Barriers请求之前的所有在队列中的请求必须在Barries请求开始前被结束,并持久化到非易失性介质中。
·Barriers请求之后的I/O需要等到其写入完成后才能执行。Barries I/O是操作系统层面的概念,为了实现Barriers I/O,底层的硬件及驱动必须有相应的支持。SCSI/SAS硬盘通过FUA(Force Unit Access)技术和SYNCHRONIZE CACHE(同步缓存)技术来实现Barries I/O功能。FUA技术让用户可以不使用硬盘上的缓存直接访问磁盘介质。SYNCHRONIZE CACHE技术让用户可以把整个硬盘上的缓存都刷新到介质上。SATA硬盘可以通过FLUSH CACHE EXT调用来支持Barries I/O功能,另外,如果SATA硬盘开启了NCQ(Native Command Queuing),也可以处理FUA。Linux开启NCQ需要使用libata驱动。查看Linux是否装载了libata的方法如下:
[root@vm08 ~]# dmesg |grep libata
[ 1.580903] libata version 3.00 loaded.
多数文件系统都提供了是否开启Barriers I/O选项,Ext3和Ext4默认开启了Barriers,如果想关闭Barriers,则需要在挂载文件系统时指定参数barriers=0,命令如下:
mount -o barriers=0 /dev/sdb1 /data/pgdata XFS也默认打开了Barriers,如果想关闭,则需要在挂载文件系统时指定参数nobarrier ,命令如下:
mount -o nobarrier /dev/sdb1 /data/pgdataI/O调优的方法
方法1:打开noatime
每个文件上都有以下3个时间。
·ctime:改变时间。
·mtime:修改时间。
·atime:访问时间。
通常,PostgreSQL并不使用这3个时间,首先可以禁止atime,这样读文件时就不会再更新文件的atime。mtime和ctime有时还有些作用,如判断相应的数据文件最后是什么时候修改的。因此,PostgreSQL数据目录所在的文件系统在/etc/fstab中的配置项上一般都设置为“noatime”,示例如下:
/dev/sdd1 / xfs noatime,errors=remount-ro 0 1方法2:调整预读
Linux环境下块设备通常都默认打开了预读,可以使用命令查看预读
查看预读的具体示例如下:
[root@vm08 ~]# blockdev --getra /dev/sda
8192上面的示例中返回值为“8192”,表示是8192个扇区,即4MB。
设置预读的命令如下:
blockdev --setra 4096 /dev/sdf
同样,上面的“4096”代表4096个扇区,即2MB。
上面的设置并不会永久生效,机器重启后该设置就会失效,如果想让其永久生效,应该把上面的命令放到开始自启动脚本中,如放在/etc/rc.local中。
方法3:调整虚拟内存参数
需要调整的第一个虚拟内存参数是swappiness,该参数值的范围为0~100,为0时表示尽量使用物理内存,取值越大,越倾向于使用SWAP空间,默认值为“60”。查看此参数当前值的方法如下:
cat /proc/sys/vm/swappiness
设置此参数值,并使其永久生效的方法是在/etc/sysctl.conf中添加如下命令行:
vm.swappiness = 0
然后执行如下命令,让/etc/sysctl.conf中的配置项生效:
sysctl -p
如果想让PostgreSQL数据库的性能尽量平稳,就应该把此值设置为“0”。第二个需要调整的虚拟内存参数是“overcommit”。在Linux中,程序调用malloc()函数
分配内存时,只分配虚拟内存,真正的物理内存并没有被分配,只有进程真正需要使用时才会分配物理内存。这种申请内存后并不会马上使用的技术就叫“Overcommit”技术。Overcommit技术的优势在于,系统中运行的进程可以分配的内存数可以超过机器上拥有的物理内存,其劣势在于,当进程真正需要内存时,可能没有可用的物理内存可以使用,此时需把其他进程使用的内存放到SWAP区中,但是如果SWAP中也放不下,就会发生OOMkiller,它会选择杀死一些用户态的进程以释放内存。OOM的意思是“Out of Memroy”。vm.overcommit参数可控制调用malloc()函数时分配内存的行为,此参数可以取以下3
个值。
·0:启发式策略,表示Linux将启发式地检查是否有足够的内存可以Overcommit,如果有则成功调用malloc(),内存申请成功;否则,内存申请失败,并把错误返回给应用程序。这种方式并不能完全避免OOM killer。
·1:总是成功调用malloc(),并不管当前内存的实际情况。
·2:不允许Overcommit,即当分配给所有进程的内存超过swapd大小+N%×物理时,会分配失败,N%是一个百分比,该值是由另一个参数vm.overcommit_ratio控制的。上面参数值中的“0”和“1”都不能避免OOM killer,所以在PostgreSQL数据库中要把此
参数设置为“2”,命令如下:
vm.overcommit_memory=2
要根据当前机器上的实际物理内存和SWAP空间的大小对参数vm.overcommit_ratio进行合理配置。如果想保守一些,让能分配的所有内存不超过物理内存的大小,如以下一台机器,其物理内存为4GB,SWAP也为4GB:
osdba@osdba-work:~/bin$ free -m total used free shared buffers cached
Mem: 3844 3721 123 249 98 1392
-/+ buffers/cache: 2230 1614
Swap: 3984 0 3984
则可以设置vm.overcommit_ratio为“0”,swap+0%*mem为“4G”,能分配的所有内存大
小恰好是4GB:
vm.overcommit_ratio=0
另一台机器的内存为128GB,SWAP为4GB,则可以配置vm.overcommit_ratio为“95” ,这样能分配的所有内存为4G+128G×0.95=125.6GB,示例如下:
vm.overcommit_ratio=95
从上面的示例中可以看出,vm.overcommit_ratio要根据机器的总物理内存和SWAP空间大小进行合理的配置。
方法4:写缓存优化
在Linux系统中,对文件的普通写,并不会马上写入磁盘中,而是会先写到内存页cache中,实际刷新到磁盘中的操作是由内核线程来完成的。在Linux2.6中,内核线程为pdflush,在Linux3.0以上则为flush进程。既然是由Linux中的一个内核线程后台刷新到磁盘中的,那么当内存中累积多少脏数据或积累多长时间后刷新是有讲究的,如果刷新得太频繁会产生过多的I/O,因为同一个数据块,在刷新到磁盘之前可能被写了好几次,但不管写了几次,实际上只会写到磁盘一次。而如果刷新太慢,会占用太多的内存,当真正需要内存时,需要先把脏数据刷新到磁盘中以腾出内存空间,从而导致PostgreSQL数据库的性能出现较大的抖动。
在Linux系统中有以下3个参数用于控制写缓存的过程。
·vm.dirty_background_ratio:指定文件系统缓存脏页数量达到系统内存百分之多少时(如5%)触发内核刷脏页线程,并将缓存的脏页异步地刷入磁盘中。
·vm.dirty_ratio:指定当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不把缓存脏页写入磁盘中,此过程可能导致很多应用进程的文件I/O被阻塞。
·vm.dirty_writeback_centisecs:单位为百分之一秒,指定内核线程执行刷新脏页的回写操作之间的时间间隔。在早期的Linux2.6的内核中,vm.dirty_background_ratio的值为“10”,而vm.dirty_ratio的值为“40”,这两个参数的值明显太大了,在较新的内核中,对这两个参数的默认值做了
如下修改:
vm.dirty_background_ratio = 10
vm.dirty_ratio = 20
在较大内存的机器上还可以把这两个值调得更低一些,如在8GB以上的机器上可以做如下调整:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
或设置得更小一些,命令如下:
vm.dirty_background_ratio = 1
vm.dirty_ratio = 2
在实际应用中可以根据需求,通过测试来确定一个更精确的值。
方法5:调整I/O调度器
Linux系统下通常有以下3种I/O调度器。
·cfq:完全公平队列(Completely Fair Queuing),尝试为所有的请求分配公平的I/O带宽,注意是带宽,而不是响应时间。
·deadline:平衡所有请求,避免某个请求被饿死,使响应时间最优化。
·noop:除了基本的块合并及排序工作以外,其他基本上什么也不做。可以看出,数据库比较适合使用deadline调度器,而Linux下默认的I/O调度器是cfq。
手动设置调度器的方法如下:
echo deadline > /sys/block/sdd/queue/scheduler
真实配置时,上面中的“sdd”需要换成实际的硬盘名称。上面手动设置的方法并不持久,在机器重启后,设置就会失效。如果想将设置持久化,可以把上述命令行放到开机自启动脚本“rc.local”中。另一种方法是在Linux内核启动命令行上改变默认的I/O调度器,常用的修改的方法是修改grub.conf中的启动命令行,在命令行后加上“elevator=deadline”,命令如下:
kernel /vmlinuz-2.6.18-128.e15 ro root=/dev/sda1 elevator=deadline
实际上,改变I/O调度器对PostgreSQL性能的提升很小,所以保留默认的调度器也是可以的。
SSD的Trim优化
相比机械硬盘,SSD硬盘的随机读写能力提升了两个数量级以上,顺序读写的性能也提升了几倍,所以使用SSD可以大幅提升PostgreSQL的性能。因为SSD的底层操作与机械硬盘非常不同,对一块SSD进行一些随机写之后,SSD的写性能可能会出现不可预期的逐步性能退化,这是因为SSD内部有擦除和均衡写磨损(W
ear Leveling)策略,而使用Trim命令(ATA命令集中称为“TRIM”,SCSI命令集中称为“UNMAP”)能通知固态硬盘(SSD)哪些数据块已不再考虑使用,可以被内部擦除。当删除一个文件时,该文件在SSD内部占用的空间实际上是可以擦除的,但因为SSD内部并不了解文件系统的情况,这些可被擦除的空间仍然会被保留,这会使SSD变慢。而目前常用的文件系统(如Ext4、XFS)都提供了通知SSD哪些数据块可以被擦除的功能,即文件系统向SSD发送了Trim指令。当然要使用该功能,需要在mount文件系统时加上discard选项,命令如下:
mount -o discard, noatime/dev/sdd1 /data
数据库性能视图
PostgreSQL数据库提供了很多性能和当前状态的统计视图,这些视图都是以“pg_stat” 开头的。是否产生这些统计数据由以下几个参数决定。·track_counts:是否收集表和索引上的统计信息,默认为“on”。
·track_functions:可以取值“none”“pl”和“all”,如果是“pl”则只收集PL/PgSQL写的函数的统计信息;如果是“all”收集所有类型的函数,包括C语言和SQL语言写的函数的统计信息。默认值为“none”。
·track_activities:是否收集当前正在执行的SQL。默认值为“on”。
·track_io_timing:是否收集I/O的时间信息。默认值为“off”,即不收集,因为收集该信息可能会导致某些平台上的性能瓶颈。最常用的视图为pg_stat_activity,该视图可以查询出当前正在运行的SQL。
此外
PostgreSQL提供了以下各个对象级别的统计信息的视图:
·pg_stat_database。
·pg_stat_all_tables。
·pg_stat_sys_tables。
·pg_stat_user_tables。
·pg_stat_all_indexes。
·pg_stat_sys_indexes。
·pg_stat_user_indexes。
pg_stat_database用于显示以下信息:
·各个数据库相关的活跃服务器进程数。
·已提交的事务总数。
·已回滚的事务总数。
·已读取的磁盘块总数。
·缓冲区命中总数。
·行插入、行读取、行删除的总数。
·死锁发生的次数。
·读数据块的总时间。
·写数据块的总时间。
默认情况下track_io_timing参数是关闭的,所以“读数据块的总时间”和“写数据块的总时间”这两项没有数据。打开该配置项在一些平台上可能会导致性能问题,可以通过PostgreSQL提供的pg_test_timing工具来测试是否存在此问题,
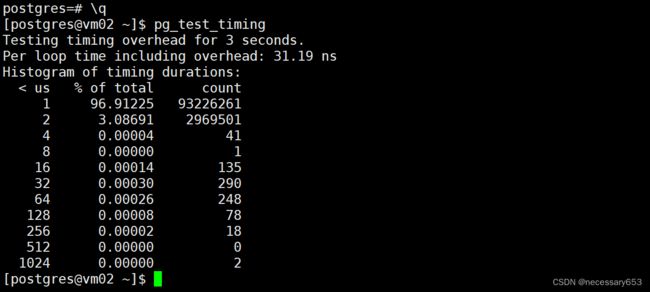
从上面的示例中可以看出,调用一次timing花费的时间为31.19ns,说明调用tining的代价很小,所以打开此参数没有问题。
pg_stat_all_tables、pg_stat_sys_tables、pg_stat_user_tables这3张视图内容相似,只是pg_stat_all_tables显示的是所有表的统计信息,而pg_stat_sys_tables只显示系统表的统计信息,pg_stat_user_tables只显示用户表的统计信息。这3张视图中有如下信息:
·顺序扫描总数。
·顺序扫描抓取的活数据行(liverow)的数目。
·索引扫描的总数(属于该表的所有索引)。
·索引扫描抓取的活数据行的数目。
·插入的总行数、更新的总行数、删除的总行数、HOT更新的总行数。
·上次手动VACUUM该表的时间,上次由AutoVacuum自动清理该表的时间。
·上次手动ANALYZE该表的时间,上次由AutoVacuum自动ANALYZE该表的时间。
·VACUUM的次数(不包括VACUUM FULL)。
·AutoVacuum的次数。
·ANALYZE的次数。
·由AutoVacuum自动ANALYZE此表的次数。
PostgreSQL提供了对数据库内函数的调用次数及其他信息的统计视图“pg_stat_user_functions”。
该视图提供了以下信息:
·每个函数的调用次数。
·执行每个函数花费的总时间。
·执行函数时它自身花费的总时间,不包括它调用其他函数花费的时间。
PostgreSQL还提供了以下各个对象上发生的I/O情况的统计视图:
·pg_statio_all_tables。
·pg_statio_sys_tables。
·pg_statio_user_tables。
·pg_statio_all_indexes。
·pg_statio_sys_indexes。
·pg_statio_user_indexes。
·pg_statio_all_sequences。
·pg_statio_sys_sequences。
·pg_statio_user_sequences。
这些视图统计了该对象上发生的数据块的读总数、缓存区命中总数,如果是表,还提供了该表上所有索引的磁盘块读取总数、所有索引的缓冲区命中总数、辅助TOAST表(如果存在)上的磁盘块读取总数、辅助TOAST表(如果存在)上的缓冲区命中总数、TOAST表上的索引的磁盘块读取总数、TOAST表上索引的缓冲区命中总数。“pg_statio_”系列视图在判断缓冲区效果时特别有用,可以统计出各个数据库缓冲区的命中率。这些视图中记录的信息都是数据库启动后的统计信息,也就是说是一个累积值,这与Oracle数据库中的统计视图是一样的。如果想看某一段时间内的统计数据,还需要写一个程序或使用一些工具,在开始时间统计一次数据,结束时间再统计一次数据,两次数据相减才能算出这段时间内的统计数据。Oracle数据库中提供了statspack的工具,PostgreSQL数据库中也有人写了类似工具,叫pgstatspack,具体可见http://github.com/dtseiler/pgStatsPack2。
这些统计数据视图对进行性能问题的定位非常有用,建议初学者多学习这些视图的使用方法,掌握每一列数据的含义。
Linux监控工具
在PostgreSQL调优过程中,掌握Linux下常见的命令工具也是有很大帮助的。下面列出了一些常用的命令:
·top。
·iostat。
·vmstat。
·sar。
top命令用于查看全局信息,如CPU的占用率、load情况、内存的使用情况、topN的进程。iostat命令用于查看磁盘的读写IOPS、读写吞吐量、读写响应时间及I/O利用率,示例如下:
iostat -dmx 1 /dev/sdm
其中比较重要的是关系到响应时间的几项,如await和svctm。await包括了在队列中等待的时间,svctm指把I/O发送到磁盘上花费了多少时间,不包括在I/O队列中的时间。对于普通硬盘来说,该时间通常不应该超过20ms。另外,最后一项“%util”表示I/O利用率,需要注意的是,当I/O利用率为10%时,并不是表示IOPS翻一倍,I/O利用率就会涨到20% ,也就是说,I/O利用率与IOPS之间没有线性关系。多数情况下,当IOPS增大时,如果没有到达磁盘的瓶颈,I/O利用率会一直处于一个较低的值,当IOPS增大成为磁盘的瓶颈时,I/O利用率会从一个较小的值很快上升到100%。使用vmstat命令可以查看内存的使用情况,命令如下
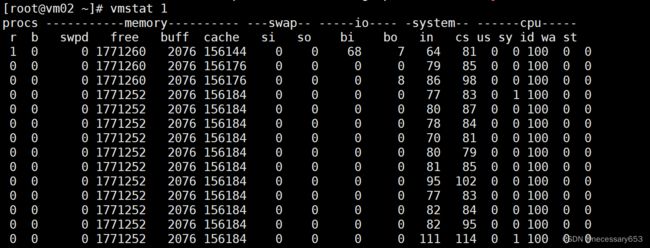
这里需要重点关注swap大类中的si和so,如果这两项中有大于0的数值,说明发生了SWAP交换,系统的内存不足了。通过bi和bo也可以看到当前I/O的情况。
使用sar工具可以查看各种信息,最常用的是查看网络流量,示例如下:
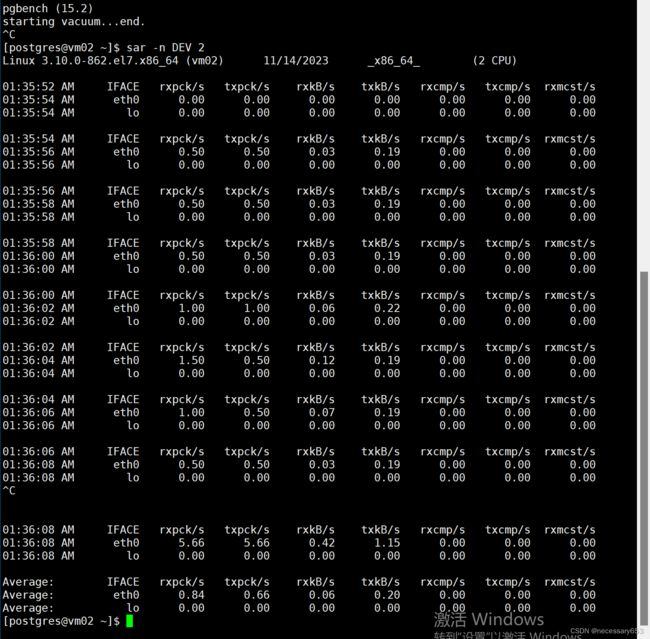
数据库内存优化
PostgreSQL中与内存有关的配置参数如下。
·shared_buffers:共享缓存区的大小,相当于Oracle数据库中的SGA,主要做数据块的缓存。
·work_mem:为每个进程单独分配的内存,主要用于排序、HASH等操作。
·maintence_work_mem:为每个进程单独分配的内存,主要是进行维护操作时需要的内存,如VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等操作需要的内存。
·autovacuum_work_mem:从PostgreSQL 9.4版本开始新增的参数。在PostgreSQL 9.4之前的版本中,AutoVacuum的每一个worker进程与手动做VACUUM一样,分配的内存大小都是由maintence_work_mem参数控制的,现在分开了,AutoVacuum的worker进程由该参数控制,手动VACUUM时分配的内存大小仍由maintence_work_mem参数控制。此参数默认设置为“-1”,即与原先的行为是一样的,当把此参数设置为其他值时,可以为AutoVacuum的每个worker进程做VACUUM操作时指定不同的内存值。
·temp_buffers:指定临时表的缓存的大小,这是为每个不同的进程单独分配的内存,不在共享内存中。默认为8MB,通常保持默认值就可以了。
·wal_buffers:指定WAL日志缓存的大小,默认值是“-1”,即会根据shared_buffer的大小自动设置。选择等于shared_buffers的1/32的尺寸(大约3%),但是不小于64KB也不大于WAL文件的尺寸(通常为16MB)。不应该超过WAL文件的大小,通常保持默认值就可以了,如果手动设置,一般为4MB~16MB。
·huge_pages:是否使用大页,默认设置是“try”,表示尽量使用大页,如果操作系统未开启大页或分配的大页内存太小,数据库虽仍然能启动,但不再使用大页内存。
·effective_cache_size:该参数实际上与具体的内存分配没有关系,它是告诉优化器在估计SQL的执行代价时假设有多少磁盘缓存,注意主要指文件系统缓存,通常设置为机器总内存的80%,设置得多一些(如90%)或少一些(如50%)并不会有严重的影响。shared_buffers,即共享缓存区的大小,因为要在多个进程中共享,所以必须使用共享内存技术来存放。PostgreSQL的数据文件都在文件系统中,操作系统的文件系统也有缓存,这有可能会导致数据库的数据块除了在PostgreSQL的共享内存中有一个副本以外,在文件系统的缓存中也有一个副本,因此造成内存利用率不高,这就是PostgreSQL中的Double Buffering问题。在Oracle数据库中,通过设置Direct I/O来避免双缓存问题,但PostgreSQL中未实现对Direct I/O的支持。为了减少双缓存问题带来的影响,
通常使用以下方法解决:
设置较小的shared buffer,将大多数内存给文件系统缓存使用,如在一台有24GB内存的机器上,可以把PostgreSQL中的shared buffer设置为较小值,如500MB~1GB,其他内存都留给文件系统缓存使用。所以一般来说,shared buffer的设置值不应超过总内存的1/4,如一台256GB的机器,通常把shared buffer设置为32GB就够了。work_mem参数指定的内存不是总共消耗的内存,也不是一个进程分配内存的最大值,而是SQL中的每个HASH或排序操作都会分配这么多内存,也就是说,包含HASH和排序操作越多的复杂SQL,分配的内存越多。如果有并发的M个进程,每个进程中有N个HASH操作,则需要分配的内存是M×N×work_mem,所以work_mem不要设置得太大,通常保持默认的4MB就足够了。如果把work_mem设置得太大,如超过256MB,很容易因为瞬间的大并发操作导致Out of Memory问题。从PostgreSQL 9.3版本开始,共享内存已从System V方式变成了使用POSIX方式和mmap方式,因此在PostgreSQL 9.3版本之后不再需要配置Linux的“shmmax”和“shmall”参数,而在此之前的版本中则需要配置这两个参数,它们的含义分别如下。
·shmall:表示整个系统内可以为共享内存配置的共享内存页面数。如果一台机器上运行有多个数据库实例,需要把此值设置成大于各个数据库实例所需要的共享内存之和。简单的做法是设置成机器总内存的页面数。
·shmmax:表示单个共享内存段(Shared Memory Segment)可以创建的共享内存的最大值。通常设置成机器的总内存数就可以了。
shmall的单位是页面,而shmmax的单位是字节
一台256GB的机器的配置如下:
kernel.shmmax = 274877906944
kernel.shmall = 67108864
把上述配置放到/etc/sysctl.conf文件中,然后运行sysctl -p让其生效即可。
除设置SysV共享内存的参数外,还需要设置SysV信号量的相关参数,SysV信号量用于对共享内存访问时进行锁管理。Linux下需要配置的信号量参数主要有以下几个。
·SEMMSL:内核参数,控制每个信号集合的最大信号数。
·SEMMNS:内核参数,控制系统范围内能使用的最大信号量数。
·SEMOPM:semop()函数每次调用所能操作的信号量集中信号量的最大值。
·SEMMNI:内核参数,控制整个系统中信号集的最大数量。
上面提到了一个概念——“信号量集”,每个信号量集由很多个信号量组成,操作系统可以对一个信号量集做一个原子操作,所以系统中信号量的最大数目=每个信号量集的大小*信号量集的个数,即:
SEMMNS=SEMMSL* SEMMNI
而SEMOPM是指对某个信号量集进行一个原子操作时可以操作的信号量数,所以其最大值不应超过信号量集中信号量的数目,通常设置为相等,即:
SEMOPM=SEMMSL
在PostgreSQL数据库中,这几个参数有如下要求:
·SEMMNI>=ceil((max_connections+autovacuum_max_workers+4)/16)。
·SEMMSL>=17。
从前面的讲解中可以知道:
·SEMOPM <=SEMMSL。
·SEMMNS=SEMMSL×SEMMNI=ceil((max_connections+autovacuum_max_workers+4)/16)×17。
假设一个数据库有如下配置:
·max_connections=2000,但以后有可能超过2000个连接,认为设置到10000是极限,下面按10000来计算信号量的配置。
·autovacuum_max_workers=3。
则这几个参数的配置值如下:
·SEMMNI=ceil((max_connections+autovacuum_max_workers+4)/16)=626,取一个整数650。
·SEMMSL要求大于17,如设置20就可以了。
·SEMOPM与SEMMSL相同,即20。
·SEMMNS=SEMMNI×SEMMSL=650×20=13000。
那么,此数据库在/etc/sysctl.conf中的配置如下:
# SEMMSL SEMMNS SEMOPM SEMMNI
kernel.sem=20 13000 20 650
Oracle数据库也需要设置信号量参数,但设置的值一般比PostgreSQL数据库要大一些,这些参数的值设置得大一些并不会出现明显的资源消耗,所以有些公司为了统一比配项,会按Oracle数据库的要求进行配置,这样配置完成后也可以满足PostgreSQL数据库的运行,如5000个连接的Oracle数据库的要求配置如下:
# SEMMSL SEMMNS SEMOPM SEMMNI
kernel.sem=5010 3256500 5010 650
大页内存配置
对一些连接数很大且内存较大的PostgreSQL数据库,强烈建议配置大页。这不仅是因为大页的性能会高一些,也是为了避免页表过大。操作系统把逻辑地址映射成物理地址时,需要把映射关系也存储到一个内存中,这部分内存就是页表。在Linux操作系统中,即使是同一块共享内存,每个进程中的逻辑地址也是不相同的,因此不同进程中的映射表项也不相同。在64位的机器上,每个4k页需要占用大约8字节的内存,一台48GB内存的机器,如果分配了24GB共享内存,则每个进程的页表大小为(24G/4k)×8=48MB,如果服务器连接上500个进程,页表的大小将是500×48=24GB。这会立刻把机器上所有内存吃光,因而会产生很大的问题。当然并不是每个新连接一连接上来,后面进程的页表就会马上分配48MB,当进程需要建立逻辑地址与物理地址之间的关系时才会分配,所以进程占用的页表空间是缓慢增加的,但最终还是可能会占用很大的页表内存。要查看是否存在这个问题,可以使用如下命令来检查页表的大小:
cat /proc/meminfo |grep PageTables
PageTables: 55612 kB
如果发现页表的大小不是几十兆,而是达到了1GB以上,就说明数据库存在此问题。基于共享内存的多进程架构的程序都会存在这个问题。Oracle数据库在Linux下也存在这个问题,需要使用大页来解决。PostgreSQL 9.4版本开始支持大页,打开大页的方法是设置参数“huge_pages”,命令如下:
huge_pages = try
把huge_pages设置为“try”,表示让PostgreSQL尝试使用大页,如果操作系统没有配置大页或配置的大页小于PostgreSQL需要的大页内存,那么PostgreSQL在分配大页失败后,会使用普通内存。如果把huge_pages设置为“on”,分配大页失败后,PostgreSQL也会启动失败。操作系统中大页的设置项在/etc/sysctl.conf中,命令如下:
vm.nr_hugepages=10240
上例表示设置了大小为10240*2MB的内存,即大约为20GB内存。使用如下命令让该设置生效:
sysctl -p
设置完成后,检测设置是否生效,命令如下:
cat /proc/sys/vm/nr_hugepages
如果发现显示值小于设置值,可以多次运行下面的命令直到显示值与设置值相同:
echo 10240 > /proc/sys/vm/nr_hugepages
前面配置了大页内存,大页的大小是2MB,实际现在的硬件基本都可以使用1GB大小的大页,其性能会更高,在Redhat7.X或CentOS7.X下,可以用如下命令设置1GB大小的大页:
grubby --update-kernel=ALL --args="default_hugepagesz=1G hugepagesz=1G hugepages=32"
上面的命令设置了32GB的大页内存。该命令实际上是把大页参数设置到了内核的参数上,即操作系统一启动就把32GB的大页内存分配好了。执行完上面的命令后,需要重新启动机器才能生效。需要注意的是,大页内存一旦设置,内存就实际地分配出去了,也会一直驻留在内存中的,不会被交换出去。对于Oracle的DBA来说,就相当于天然是LOCK_SGA,所以大页内存的设置需要与shared_buffer一样或稍大一些,因为比shared_buffe多出来的大页内存既不能给文件系统缓存使用,也不能给其他不使用大页内存的程序使用,相当于白白浪费了。
最后还有一个需要注意的问题,即Linux中还有一个透明大页(Transparent Hugepage),即Linux自动进行大小页的转换和自动管理,但目前在Redhat 7.X/CentOS 7.X下该功能会带来性能的抖动或下降,通常建议关闭透明大页,关闭方法如下:
grubby --update-kernel=ALL --args="transparent_hugepage=never"
vacuum 中的优化
PostgreSQL数据库需要定期做VACUUMING,是基于以下几个原因:
·标记多版本中不再需要的旧的版本行所占用的空间为可用,以重复使用这部分磁盘空间。
·更新统计数据,保证执行计划的正确性。
·事务ID为32位递增的整数,当增到最大值时会重新从起始值开始,这就要保证旧的已提交事务的数据仍然可见,需要把这些行上的事务ID更新为一个永远可见的事务ID(Frozen ID)。
有以下两种VACUUM:
·标准的VACUUM。
·VACUUM FULL。
VACUUM的标准方式通常可以与SELECT语句和DML语句如INSERT、UPDATE、DELETE命令并行执行,但是当正在清理该表时,不能使用如ALTER TABLE这样的DDL语
句来修改表定义。VACUUM FULL需要得到表上的一个排斥锁才能工作,它不能与其他使用该表的语句并行执行,因此一般情况下,管理员应尽量使用标准的VACUUM。不过VACUUM FULL可以回收更多的磁盘空间,当然它的运行速度也要慢得多。对于一般的数据库,默认配置中AutoVacuum后台进程会自动运行(这是因为默认配置参数autovacuum为“on”),会自动地周期做VACUUM,所以不再需要手动VACUUM。执行VACUUM时会产生一些负载,这会影响到一些正常的数据库访问,因此PostgreSQL数据库提供了一种机制和多个配置参数来减少该操作对正常访问的影响。这种机制的方式为,在执行VACUUM和ANALYZE命令时,PostgreSQL会统计这些操作产生的代价值,并把该代价值累计到一个计数器中,当此计数器的值超过设定的阈值时,会休眠,然后把计数器置0再继续执行,当计数器的值再次超过指定的阈值时,则再次休眠,如此不断重复这一过程。通过工作一段时间再休眠一段时间来减少VACUUM对数据库性能的影响,这一特性默认是关闭的。vacuum_cost_delay参数默认为“0”,当设置为非零值时,就是打开了该功能。当每次累计的工作量到达了参数vacuum_cost_limit指定的值时,会休眠参数vacuum_cost_delay指定的毫秒数。该值的计算方法如下:
访问在共享内存中的数据块数×vacuum_cost_page_hit+访问在磁盘上的数据块数×vacuum_cost_page_miss+修改干净的在磁盘中的数据块数×vacuum_cost_page_dirty
这些参数的意义如下:
·vacuum_cost_page_hit:VACUUM访问的数据块在共享内存中的代价值,默认为“1”。
·vacuum_cost_page_miss:VACUUM访问的数据块不在共享内存中的代价值,默认为“10”。
·vacuum_cost_page_dirty:VACUUM改变一个非脏数据块为脏数据块的代价值,默认为“20”。
要想减少执行VACUUM命令对现有系统的影响,可以把vacuum_cost_delay设置为一个合适的值,命令如下:
osdba=# set vacuum_cost_delay to 1;
SET
osdba=# vacuum;
VACUUM
但有时把vacuum_cost_delay设置为最小值1时,VACCUM操作的执行效率还是太低,这是因为默认的vacuum_cost_limit值太小,vacuum_cost_limit默认是“200”,如果是SSD硬盘可以把该值设置为“10000”,如果是一般带缓存的硬件Raid卡输出的机械硬盘,设置为1000~2000比较合适。对于自动VACUUM即AutoVacuum,也有一组与上面类似的参数来实现相同的功能。
·autovacuum_vacuum_cost_delay:PostgreSQL 12及以上版本默认是“2ms”,而PostgreSQL 11及之前版本默认值是“20ms”,20ms这个值通常太大了,改成2ms比较合适。
·autovacuum_vacuum_cost_limit:默认值是“-1”,即使用vacuum_cost_limit的值,前面讲过,通常此默认值会较低,如果是SSD硬盘可以把该值设置为“10000”,如果是一般带缓存的硬件Raid卡输出的机械硬盘,则设置为1000~2000比较合适。我们可以看到这些参数前都加了“autovacuum_”。还有一个参数可用于指定启动AutoVacuum的work进程的多少,即autovacuum_max_workers,默认值为“3”。当发现来不及AutoVacuum时,可以把此参数值调得大一些。
另外,可以合并更新,以减少更新的量,如下面的两条SQL:
update testtab01 set col1='vol1' where id=8;
update testtab01 set col2='vol2' where id=8;
应该优化为一条SQL语句,命令如下:
update testtab01 set col1='vol1',col2='vol2' where id=8;
对于更新频繁的表,应该设置更小的fillfactor,这样可以更多地利用HOT,同时索引上的更新也会少很多,也就减少了VACUUM的代价,命令如下:
osdba=# alter table test01 set (fillfactor = 50);
ALTER TABLE
通常一张表变更的行数超过一定的阈值时,AutoVacuum才会对这张表做VACUUM,该阈值的计算公式如下:
autovacuum_vacuum_scale_factor×表上记录数+autovacuum_vacuum_threshold
公式中的各参数说明如下。
·autovacuum_vacuum_threshold:当表上发生变化的行数至少达到此参数值时,才可能让AutoVacuum对其进行VACUUM,(这里说“可能”是因为还有另一个参数“autovacuum_vacuum_scale_factor”同时控制VACUUM的执行条件),默认值为“50”。也可以在表上单独设置此参数,让不同的表有不同的配置。
·autovacuum_vacuum_scale_factor:触发VACUUM的第二个阈值条件。调整这两个参数的值可以改变AutoVacuum的工作量,从而提升性能。对于一些大表,autovacuum_vacuum_scale_factor设置为“50”有一些小了,可以在大表上单独设置一个较大的值,如“90”,命令如下:
alter table big_table set (autovacuum_vacuum_threshold=90,toast.autovacuum_vacuum_threshold=90);
同样也有两个参数用于控制调整AutoVacuum进程进行统计信息收集(ANALYZE)的阈值条件。
·autovacuum_analyze_threshold:当表上发生变化的行数达到此参数值时,才可能让AutoVacuum对其进行ANALYZE,(这里说“可能”是因为还有另一个参数“autovacuum_analyze_scale_factor”同时控制VACUUM的执行条件),默认值为“50”。也可以在表上单独设置此参数,让不同的表有不同的配置。
·autovacuum_analyze_scale_factor:触发ANALYZE的第二个阈值条件。当表中行上的事务ID太早,超过autovacuum_freeze_max_age参数指定的年龄时,会强制地对这张表做VACUUM操作,autovacuum_freeze_max_age的默认值为2亿。这主要是为了防止事务ID回卷后无法正确判断事务的新旧,从而导致数据丢失。需
要注意的是,即使AutoVacuum被禁止,系统也会强制调用AutoVacuum进程在表上执行VACUUM。当表中行上最早事务ID的年龄没有超过vacuum_freeze_table_age参数指定的年龄时,会做LAZY UACUUM,LAZY UACUUM不会全表扫描,即之前做过垃圾回收的数据块会被记录,再次VACUUM时会跳过这些块。但当表中行上的最早事务ID的年龄超过vacuum_freeze_table_age参数指定的值时,会做一个全表扫描的VACUUM,称为“Aggressive Vacuum”,vacuum_freeze_table_age的默认值为“150000000”,即为1.5亿。需要把autovacuum_freeze_max_age设置为大于vacuum_freeze_table_age的值。有时为了减少因防止事务ID回卷而让AutoVacuum过于频繁地运行,可以增大这两个参数的值:
·vacuum_freeze_table_age=250000000:即为2.5亿。
·autovacuum_freeze_max_age=350000000:即为3.5亿。
预写式日志写优化
预写式日志(WAL)是对数据文件进行修改(通过是表或索引的数据文件)时,先把这些操作记录到日志中,数据文件修改后的脏页不必马上刷新到磁盘中,如果出现系统崩溃,可以重做记录在日志中的操作来恢复数据库。一些与WAL相关的参数会影响数据库的性能,可以调整这些参数来优化数据库的性能。
检查点是事务序列中的点,在发生检查点时,所有脏数据页都会被刷新到磁盘中并且向日志文件写入一条特殊的检查点记录,以确保在该点之前的所有信息都已经写到数据文件中(改变以前刷新的WAL的缩写文件)。在发生系统崩溃时,恢复过程查找最后的检查点记录,然后重做该检查点之后的日志,把数据库恢复到正常情况。检查点完成之后,检查点之前的日志不再需要,可以循环使用或删除,当然这些日志还可以用在Standby数据库上。
以下两个参数用于控制检查点发生的频率:
·max_wal_size。
·checkpoint_timeout。
每当写WAL日志量超过max_wal_size参数的指定值时(在PostgreSQL 9.4及之前的版本,是写的WAL文件数超过checkpoint_segments的参数值时),每过checkpoint_timeout秒就创建一个检查点,不管满足哪个条件,都会生成一个检查点。默认情况下max_wal_size为1GB(在PostgreSQL 9.4及之前的版本中checkpoint_segment的默认值为“3”),checkpoint_timeout为300秒(5分钟)。当然也可以用SQL命令“CHECKPOINT”强制创建一个检查点
。发生检查点时,需要把当前所有数据块的脏页刷新到磁盘中,因此它的开销比较高。让检查点发生得慢一些,可能会提高性能。可以通过设置checkpoint_warning对检查点参数进行简单的检查。如果检查点发生的时间间隔接近checkpoint_warning秒,就会在服务器日志中输出一条消息,这样,通过监控日志信息,就可以在检查点发生得过于频繁时通知用户减小该频率。为了避免检查点产生太多的I/O,导致系统性能出现大的抖动,可以让PostgreSQL在平时也尽快平均地把脏页刷新到磁盘中,而不必等到发生检查点时才发现需要写太多的脏页。这个机制是由参数checkpoint_completion_target来控制的,此参数的默认值为“0.5”,即让PostgreSQL在两个检查点间隔时间的0.5倍时间内完成所有脏页的刷新。看起来把该值设置得越接近1.0,性能的抖动越平稳,但实际上不要设置为“1.0”,设置为“0.9”就足够了,因为设置为“1.0”极有可能导致不能按时完成检查点。还有一个名为wal_buffers的参数,用于指定WAL缓存的大小,在较早的PostgreSQL版本中,此值默认为64KB,但在实际使用中,这个值通常有些小,因此在较新的PostgreSQL版本中,此默认值已被改为4MB。如果是较早的PostgreSQL版本,可以把此参数值设置得大一些。
PostgreSQL也提供了组提交(Group Commit)的功能,该功能默认是关闭的。它由以下两个参数控制。
·commit_delay:默认此值为“0”,而非零的延迟允许多个事务共用一个fsync()系统调用提交,如果系统负载足够高,那么在给定的时间间隔内,其他事务可能已经准备好提交了,这样多个事务就可以共用一个fsync()调用,从而提高性能。但是如果没有其他事务准备提交,那么该时间间隔就增加了事务的延迟时间。因此,只有在其他处于活跃状态的事务数超过参数commit_siblings设置的值时,该延迟才会真的发生,才会让多个事务共用一个fsync()系统调用。
·commit_siblings:默认值为“5”,表示只有存在5个活跃事务时,才会有组提交。还有以下一些参数可以根据实际情况进行调整。
·wal_level:决定多少信息写入WAL日志中。PostgreSQL 10及以上版本默认值是replica,PostreSQL9.6及之前版本默认值是minimal。设置成minimal时,记录的WAL日志最少,里面只写入数据库崩溃或突然关机后,进行恢复所需要的信息。设置成“replica”或更高的级别时才能为该数据库建Standby数据库。对该参数的修改需要重启数据库服务器才能生效。
·synchronous_commit:声明一个事务是否需要等到操作已被写到WAL日志中才返回。当设置成off时,会提高性能,但已成功提交并返回给应用程序的事务在主机或数据库崩溃时可能会丢失,因为这些事务可能还没有刷新到WAL日志中。将该参数设置为off不会有数据库不一致性的风险,它仅会导致数据库发生故障时可能会丢失一些最近已提交的事务。另外,此参数是可以以session级别来设置的,当明确知道某个事务不是很重要时,可以在session级别把此参数设置为off,这样不影响其他事务。
·full_page_writes:默认为on,PostgreSQL服务器在检查点之后对页面的第一次写入时会将整个页面写到WAL日志中。这主要是为防止在操作系统崩溃过程中,只有部分页面写入磁盘,进而导致同一个页面中同时包含新旧数据,在系统崩溃后的恢复期间,由于WAL中存储的行变化信息不完整,无法完全恢复该页。把完整的页面影像保存下来,就可以保证能够正确恢复页面。虽然设置为off可以提高一些性能,但异常宕机后有无法修复坏块的风险,所以一般不建议设置为off,除非配置了原子写,避免了坏块的问题。
·wal_writer_delay:声明WAL写进程的周期。在每个周期中,将WAL刷到磁盘后,休眠wal_writer_delay毫秒后再重复执行。默认是200毫秒。