rust 字符串(String)详解
文章目录
- 前言
- 一、基本概念
- 二、构造
- 三、遍历
- 三、长度与容量
- 四、增删改查
-
- 1.增
- 2.删
- 3.改
- 4.查
- 五、分隔
- 六、转换
- 七、判断
前言
rust中的String,是一个非常常用的crate,它的底层涉及到了rust中的所有权概念,不过这不是本章的内容,如果对rust所有权概念感兴趣的,可以查看另一篇文章:rust所有权
本文的目的还是介绍String的基本用法,以及有哪些常用的函数可以使用
一、基本概念
字符串,也就是由一系列字符组成的,而在计算机中存储一个字符,用到的字节数量并不完全相同。
比如下面的代码:
fn main() {
let s1=String::from("h");
let s2=String::from("你");
println!("{} {}",s1.len(),s2.len());
}
同样是一个字符,只不过s1是英文字符,s2是中文字符,所使用的空间就不是一样大的:
1 3
一个英文字符用1个字节大小,而一个中文字符却要用3个字节大小
之所以出现这个现象,是因为rust中的字符串String为了更加的通用化,采用的是UTF-8编码,它可以容纳世界上绝大多数的字符,比如英文、中文、日文、阿拉伯文等等
一般我们windows电脑采用的是本地化编码,比如我是中国地区,用的就是属于中国的
GBK或者GB2312编码,这个编码只能存放中文字符,一旦遇到其它国家的字符,比如日文,就会出现乱码
当然了,有这个功能的并不只有utf-8,还有utf-16,utf-32等等
但它的好处就是,这个字符需要多大,就给他多大的空间,可以节约内存,如果换用utf-16,那么无论中英文都采用2个字节,如果为utf-32,无论中英文都采用4个字节
这样做的好处是大家都一样大,不用计算,就能取出对应的字符,而缺点就是占用空间大,尤其是对于使用英文的地区,就太亏了,明明一个字节就能存放他们一个字母,现在却需要两个字节、甚至四个字节!
而utf-8编码的优缺点则刚好与他们相反:节约空间,但效率较低
节约空间:英文就用一个字节表示,中文就用三个字节表示,阿拉伯文就用两个字节表示等等,可以最大限度地节约空间
效率较低:因为不同字符所占用地内存大小不一,所以想要取出一个字符,就必须进行遍历、判断,所以效率较低(如果为
utf-16,每次读取两个字节就行了,无需判断每个字节长什么样,这也是为什么window底层采用utf-16而不是utf-8编码,就是为了提高运行速度)
正因为utf-8编码的这一特性,导致了我们无法像c语言那样,可以直接遍历字符串中的所有字符:
fn main() {
let s=String::from("hello 世界");
for i in s{ //错误,无法直接遍历
}
}
同样的,你也无法直接用下标取出对应的字符
fn main() {
let s=String::from("hello 世界");
let c=s[0]; //错误,不能直接用下标取出字符
}
因为每个字符占用的内存大小不一,所以它不知道你是想要取出字符,才是想要取这个位置上的字节
二、构造
既然是学习String,那么第一件事就是了解我们应该怎么创建一个String
创建String,一般有三个方法,如下:
fn main() {
let s=String::from("hello 世界");
let mut s1=String::new();
s1.push_str("hello 世界");
//s1+="hello 世界"; //与上面的语句等价,即:追加字符串在后面
let s2="hello 世界".to_string();
println!("{}", s);
println!("{}", s1);
println!("{}", s2);
}
三个方法分别是调用from函数、new函数以及to_string函数
其中,from函数与to_string函数函数功能是等价的,只是调用的对象不同而已,作用都是从一个字符串字面量直接构造出一个String来
而new函数则是凭空产生一个String,并且为空,如果想要让它存值,就得将他声明为可变的(mut),之后可以用push_str函数或者+=操作符来追加字符串
最后输出的结果都是一样的:
hello 世界
hello 世界
hello 世界
除此之外,还有一个函数为with_capacity:
let s=String::with_capacity(100);
它的作用与new基本相同,唯一不同之处在于,这个函数需要一个参数来初始化其内部的内存大小,如果你事先知道自己需要多大的内存,那么建议你使用这个函数来构造一个String而不是用new
至于原因,可以参考后文的:长度与容量
三、遍历
接下来,我们首先要看的就是如何对字符串进行遍历,用到两个函数:as_bytes与chars
首先是as_bytes函数,看名字也知道,它的意思就是:作为字节
所以它的功能就是遍历字符串的所有字节,就可以这样写:
fn main() {
let s=String::from("hello 世界");
for i in s.as_bytes(){
print!("{} ",i);
}
}
它的作用就是遍历所以的字节值,打印结果如下:
104 101 108 108 111 32 228 184 150 231 149 140
其中,hello ,就分别对应着前面的104 101 108 108 111 32
最后一个
32,是中间的空格
而世界两个字,则分别对应228 184 150和231 149 140
由于都是一个字节,所以这个as_bytes返回的是一个字节数组,我们就可以字节通过下标获取第几个字节:
let cs=s.as_bytes();
let c=cs[1]; //取出第二个字节(从0算起,第二个字节的下标为1)
或者也可以简写为:
let c=s.as_bytes()[1]; //取出第二个字节(从0算起,第二个字节的下标为1)
除了as_bytes可以返回字节数组外,还可以使用bytes函数返回字符迭代器:
fn main() {
let s=String::from("hello 世界");
let mut b=s.bytes(); //返回字节迭代器
println!("{}",b.next().expect("err")); //打印第一个
println!("{}",b.next().expect("err")); //打印第二个
println!("{}",b.next().expect("err")); //打印第三个
println!("{}",b.next().expect("err")); //打印第四个
//...
//上面的代码等价于下面的写法:
for i in s.bytes(){
println!("{}",i);
}
}
显然这个函数并不如上面的as_bytes好用,这个就见仁见智了。
不过大多数时候,上面这种遍历的方式并不是我们想要的,我们只想要取出其中的第几个字符而已
这时,我们就可以用到chars函数,作用就是将其作为字符看待:
fn main() {
let s=String::from("hello 世界");
for i in s.chars(){
print!("{} ",i);
}
}
这时输出的结果就是:
h e l l o 世 界
成功将对应的字符给取了出来
如果你想要取出第几个字符,就可以用函数nth:
fn main() {
let s=String::from("hello 世界");
let mut m=s.chars(); //得到迭代器
let c=m.nth(7); //得到下标为7的Option返回值
if let Some(t) = c { //取出返回值中携带的字符
print!("{}",t);
}
}
这里得到的结果就是界字
更加简洁的写法就是:
fn main() {
let s=String::from("hello 世界");
let c=s.chars().nth(7); //得到下标为7的Option返回值
if let Some(t) =c { //取出返回值中携带的字符
print!("{}",t);
}
}
上面的写法应该还是很好理解的,就是将chars的返回值字节调用nth函数
当下面这个取值的操作才是有点麻烦了,所以我们还能更简洁:
fn main() {
let s=String::from("hello 世界");
let c=s.chars().nth(7).unwrap(); //取出下标7的字符
print!("{}", c);
}
这里的unwrap函数是Option这个trait的一个函数,等价于:
fn main() {
let s=String::from("hello 世界");
let c=s.chars().nth(7);
let r = match c {
Some(t) => t,
None => panic!("")
};
print!("{}", r);
}
如果不会这个用法的,可以参考我的其它文章,这里不再过多赘述
三、长度与容量
说到长度与容量,就不得不提及它的底层原理了。
因为String本质上是在堆上面分配的内存,也只有在堆上分配内存,才能满足我们想要动态修改字符串的目的。
与之相对应的是栈,堆与栈的概念在C/C++中听到的应该比较多,同时本套教程也是面对至少了解C/C++的程序员准备的,所以这里不再过多解释,如果不理解的可以自行浏览器搜索相关内存进行了解
而在你声明一个String后,编译器并不知道你后面会不会再对它进行修改,所以一般来说,它会申请一个比你预料中的要大上一些的内存,如果你后面想要追加、插入数据。就不用重新去开辟内存,而是直接在后面追加
长度与容量分别对应的函数为:len(), capacity()
比如下面这段代码:
fn main() {
let s=String::from("hello 世界");
print!("{} {}", s.len(),s.capacity());
}
因为是直接从一个字面量生成的String,而一般这样的行为大多数都不会再追加数据了,所以其默认行为就是容量与长度同样大:
12 12
但如果你用new的方式:
fn main() {
let mut s=String::new();
s.push('c');
print!("{} {}", s.len(),s.capacity());
}
这里生成了一个String,并用push函数向里面推入一个字符,此时结果为:
1 8
此时,虽然你只用了1个字节,但实际上它有8个字节的容量,这样就保证了你之后如果还想要继续往里面推入数据,就不用重新开辟内存了
重新开辟内容就意味着,要将这块内存上的数据拷贝到新内存,并释放掉原本的内存,这是一个非常影响程序效率的事情
也正因如此,如果你提前知道需要多大的内存,那就可以用函数with_capacity来创建一个String:
let mut s=String::with_capacity(1024); //提前分配好足够大的内存,避免后续出现拷贝
它的唯一一个参数就是你需要多大的内存
四、增删改查
对于数据的操作,无非就是增、删、改、查这四种
所以这里我们再尽量详尽的介绍一下这四种操作
1.增
首先是增,前面我们已经见过两个函数了:push_str与push两个函数
fn main() {
let mut s=String::new();
s.push_str("string"); //推入一个字符串
s.push('c'); //推入一个字符
}
这两个函数的区别就在于,前一个是用来向原字符串后面追加字符串的,而后一个则是用来追加字符的
除了调用函数,我们还可以方便的使用符号来代替
fn main() {
let mut s=String::new();
s+="string"; //推入一个字符串
//上面这句,等价于:s=s+"string";
//s=s+'c'; //错误,对于字符类型的,只能使用push函数
//或者通过下面这种方式:先将字符转换为String,然后前面添加&符号,代表对字符串的引用
s+=&'c'.to_string();
}
但这种操作太单一了,只能在后面推入数据,很多时候我们还想要在前面、中间位置插入数据该怎么做呢?
这时候就可以使用insert与insert_str函数了:
fn main() {
let mut s=String::new();
s+="string"; //推入一个字符串
s.insert_str(0, "prestr "); //在0字节位置插入字符串
s.insert(0,'中'); //在0字节位置插入字符
println!("{}", s);
}
其作用同样是一个插入字符串、一个插入字符
特别要注意的是,它的第一个参数代表要插入的位置,而这个位置是按字节算的,从0开始
比如从前面我们就已经知道了,一个中文汉字在utf-8编码中需要用到3个字节,那如果这时候,我在插入了一个’中‘字后,在第1个字节位置插入一个’国‘字,就会直接引起程序崩溃:
fn main() {
let mut s=String::new();
s+="string"; //推入一个字符串
s.insert(0,'中'); //在0字节位置插入字符
s.insert(1, '国'); //'中'字占3个字节,如果这时候在1位置插入,就会引起程序崩溃
println!("{}", s);
}
这个时候,最好是对要插入的位置进行检测:
if s.is_char_boundary(1){
s.insert(1, '国');
}
通过函数is_char_boundary来检测指定想要插入的位置是不是字符的边界,如果是字符的边界,那就代表我们可以插入字符,否则就不能插入字符
2.删
说完了增,下面我们再来说一说删,主要用到的函数就是remove与remove_matches
首先是remove函数,它的作用是删除一个字符:
fn main() {
let mut s="哈喽 world".to_string();
s.remove(0); //删除第0字节开始位置的字符
println!("{}", s);
}
这里我特意在字符串中放置了中文,就是为了让你能够更加明悟这一点,因为一个中文字符是占用的3个字节
运行后输出的代码为:
喽 world
也就是说,它的作用是移除从0字节开始的第一个字符,因为这是一个中文,占用三个字节,所以实际上它移除了三个字节
如果你像这样写,程序就会直接崩溃:
fn main() {
let mut s="哈喽 world".to_string();
s.remove(1); //删除第1字节开始位置的字符
println!("{}", s);
}
因为第一个字节所在的位置不是字符边界,它在第一个中文字符占用的三个字节中间
除了删除单个直接外,我们还可以使用remove_matches函数来删除子字符串,不过由于这个函数似乎还不稳定,所以暂时还用不了:
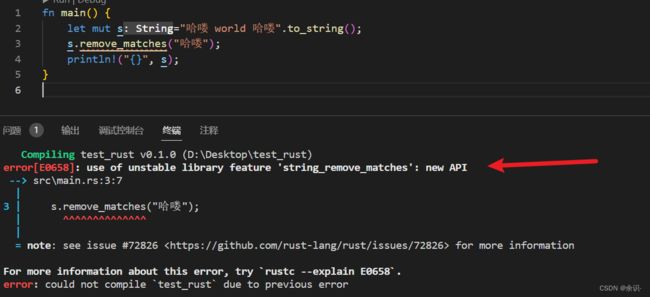
可能再过不久就会添加进来了,这里可以先了解一下
它的作用就是删除所有匹配到的子字符串
如果正常运行,那么上面的代码结果应该就是:
world
除了上面两个函数外,我们还可以使用函数drain来删除指定范围类的字符串:
fn main() {
let mut s="hello 哈喽 world".to_string();
s.drain(0..5);
println!("{}", s);
}
打印结果为: 哈喽 world
注意这个函数的返回值,就是被删除的子字符串,如果你想要保留,可以用下面这个办法:
fn main() {
let mut s="hello 哈喽 world".to_string();
let m:String=s.drain(0..5).collect(); //将删除的字符串转换为String并返回
println!("{}", m); //得到被删除的子字符串
}
除了上面用来删除字符的函数,我们还可以用另外一个函数replace_range来代替:
fn main() {
let mut s="哈喽 world 哈喽".to_string();
s.replace_range(0..6, "");
println!("{}", s);
}
它的第一个参数是一个范围,可以用上面代码中的语法书写(同样要注意边界问题)
然后第二个参数就要要取代的内容,我们可以直接将其设置为空字符串即可,这样就完成了删除操作
除了这些,我们还可以直接清空里面的内容,调用clear函数即可:
fn main() {
let mut s="哈喽 world 哈喽".to_string();
s.clear(); //清空
println!("{}", s);
}
3.改
接下来要介绍的就是String中的改操作,使用到的函数就是replace系列方法
比如下面的代码:
fn main() {
let s="哈喽 world 哈喽".to_string();
let ret=s.replace("world","世界");
println!("{}",ret);
}
它的作用就是搜寻字符串中所有能匹配到第一个参数的子字符串,并将其替换为第二个参数,最后将替换完成的结果返回
注意,它不会修改原字符串的内容,而是重新开辟的一块内存来存放结果
这时候,输出的结果为:
哈喽 世界 哈喽
如果想要直接修改原字符串,那就可以使用replace_range函数:
fn main() {
let mut s="哈喽 world 哈喽".to_string();
s.replace_range(7..12, "世界");
println!("{}",s);
}
使用这个函数唯一要注意的地方就在于,它的第一个参数为一个范围,如果字符串中存在中文,就一定要注意这个范围是指代的字节数组的范围,一定要在字符的边界上面,否则程序会字节崩溃
比如这里之所以是从7开始,是因为一个汉字占用三个字节,这里有两个函数外加一个空格,所以就是从7开始的,而world这个单词占用5个字节,7+5=12,所以范围为:
7..12
4.查
对于字符串,查找的操作也是非常常用的,用到的函数名称也非常的直白,就是find:
fn main() {
let s="哈喽 world 哈喽".to_string();
let i1=s.find('哈'); //查找字符
if let Some(t) = i1{
println!("查询到的位置为:{}",t);
}else{
println!("没有找到");
}
let i1=s.find("world"); //查找指定的字符串
if let Some(t) = i1{
println!("查询到的位置为:{}",t);
}else{
println!("没有找到");
}
}
这个函数既可以查早字符、也可以查早字符串,用起来还是非常方便的
它在查询后就会得到一个结果,为Option类型,可以用match或者if let语法取出里面的值
我这里为了方便,就直接用if let语句了
其结果为:
查询到的位置为:0
查询到的位置为:7
但你会发现,这个字符串中有两个哈喽,第一个查询语句查询的哈这个字符,就只返回了前面那个哈字的位置
这时,你就可以调用另一个rfind函数,它的作用是查找最后一次出现的位置,也就是从后面向前找:
fn main() {
let s="哈喽 world 哈喽".to_string();
let i1=s.rfind('哈'); //查找字符
if let Some(t) = i1{
println!("查询到的位置为:{}",t);
}else{
println!("没有找到");
}
let i1: Option<usize>=s.rfind("world"); //查找指定的字符串
if let Some(t) = i1{
println!("查询到的位置为:{}",t);
}else{
println!("没有找到");
}
}
这时的结果就为:
查询到的位置为:13
查询到的位置为:7
如果你想要获取指定位置的子字符串,就可以用get函数:
fn main() {
let s="hello,world".to_string();
let ret=s.get(0..5).expect("error");
println!("{}", ret);
}
五、分隔
除了一般的增删改查外,我们有时候还会有其它很多必要的操作,比如切割字符串
这时候就可以用splite系列函数了,比如下面这段代码:
fn main() {
let s="哈喽world世界world你好呀".to_string();
let ret=s.split("world");
for i in ret{
println!("{}", i);
}
}
我想要取出上面代码中的所有中文的子字符串,而各个中文子字符串都是用的world这个单词分隔的,那就可以用到splite这个函数了
它的作用就是用传入的参数将原本的字符串用这个字符串分隔开,然后返回第一个可遍历结果的迭代器,随后直接用for循环就可以遍历它得到结果
哈喽
世界
你好呀
比较常见的一个用途就是分隔路径,比如下面这个代码:
fn main() {
let s="D:/a/b/c/d/file.txt".to_string();
let ret=s.split('/');
for i in ret{
println!("{}", i);
}
}
就可以很方便的得到各个部分结果(这里用的是字符参数,也是可以的,上面用的是字符串作为参数):
D:
a
b
c
d
file.txt
而有时候,我们并不想要遍历,只想取出其中某一部分,那就可以调用collect函数,可以返回一个向量:
fn main() {
let s="D:/a/b/c/d/file.txt".to_string();
let ret:Vec<_>=s.split('/').collect();
println!("{}", ret[5]);
}
这样就可以直接通过下标来获取对应位置的数据了,非常的方便
不知道向量用法,请查看我的其它文章
上面这个函数默认是全部分隔的,但有时候我们可能只想分隔部分,那就还可以使用其它的类似函数
比如split_once函数,意思是只分隔一次:
fn main() {
let s="hello=world=yes".to_string();
let (f,b)=s.split_once('=').expect("not find");
print!("{} {}",f,b);
}
注意它的返回值为Option,这里为了方便就直接调用expect函数取得里面的值,如果没找到这个分隔符号就直接报错
它的返回值为:
hello world=yes
这个splite还有一些非常方便的相似函数可以供我们使用,但使用方法都基本类似,下面直接用代码演示:
按空格分割的函数:split_ascii_whitespace
fn main() {
let s="a b \n c \t d".to_string();
let ret=s.split_ascii_whitespace();
for i in ret{
println!("{}", i);
}
}
结果:
a
b
c
d
这里的空格不单单指的是空格,还有 制表符 \t以及换行符\n等
但正如它名字所说的,只支持ASCII码的空格符,如果你的字符串中还包含utf-8编码的空格符,就可以使用函数split_whitespace:
fn main() {
let s="a b \n \u{2009} c \td".to_string();
let ret=s.split_whitespace();
for i in ret{
println!("{}", i);
}
}
简单来说,就是split_whitespace更加强大
上面介绍的分隔函数,都会将分隔符号给去除掉,如果你想要保留分隔字符串,就可以使用函数:split_inclusive
方法如下:
fn main() {
let mut s="hello哈world哈".to_string();
let ret=s.split_inclusive('哈');
for i in ret{
println!("{}", i);
}
}
这次用哈字作为分隔符号,得到的结果将会保留这个分隔符:
hello哈
world哈
除此之外,我们还可以根据下标将字符串分割为两部分:
fn main() {
let s="hello=world".to_string();
let (f,b)=s.split_at(5);
println!("{}\n{}",f,b);
}
用到的函数就是split_at,不过需要注意的是,只要你的字符串中涉及到中文(不是字母的文字),那就要注意这个下标一定得是字符边界,否则程序直接崩溃
如果有时候那你需要可变的返回值,那就可以使用split_at_mut,方法类似,不再赘述
而spite_off函数的作用与split_at基本类似,不同之处在于,它会截断原字符串,并返回后半段的字符:
fn main() {
let mut s="hello=world".to_string();
let b=s.split_off(5);
print!("{}\n{}",s,b);
}
上面两段代码的结果相同:
hello
=world
最后还有一个函数可以用来得到指定字符结尾的子字符串:
fn main() {
let mut s="hello,world,test,哈哈哈,".to_string();
let ret=s.split_terminator(',');
for i in ret{
println!("{}", i);
}
}
上面的代码就可以得到所有以,结尾的子字符串,但如果只是这样用话,也许还不如直接用splite函数了
所以它还有更高级的用法,如下:
fn main() {
let s="hello,world;test-哈哈哈=".to_string();
let ret=s.split_terminator([',',';','-','=']);
for i in ret{
println!("{}", i);
}
}
它可以指定一系列作为结尾的字符或字符串!
甚至如果你了解闭包的话,还可以用闭包!
fn main() {
let s="hello,world;test-哈哈哈=".to_string();
let ret=s.split_terminator(|c| if c==',' || c==';' || c=='-' || c== '=' {true} else {false});
for i in ret{
println!("{}", i);
}
}
都可以得到结果:
hello
world
test
哈哈哈
六、转换
作为字符串,一个非常常见的场景就是将字符串转换为数字,这时候就可以调用parse函数
fn main() {
let s=" 100\t\n".to_string();
let num:i32=s.trim().parse().expect("解析错误");
print!("{}",num);
}
这里用这个字符串作为解析的目的,就是提醒你在解析时,一定要先调用trim函数,去除掉多余空白字符,否则解析必然会出错
因为它的返回值为Result类型,所以需要调用expect取出转化后得到的值,如果转换失败,则直接报错
另一个注意的点是,如果你想要解析字符串到指定类型,你就必须表明想要解析的数据类型
比如这里的 let num:i32,就是告诉这个函数我想要解析为i32类型
七、判断
作为字符串,判断也是一个非常常用的功能
比如判断是否与某个字符串相等,就可以直接用==进行判断即可:
fn main() {
let s="hello".to_string();
if s=="hello" {
println!("s 为hello ")
}else{
println!("s 不为hello ")
}
}
除此之外,我们还可以判断字符串是否以某个子字符串开始或者结尾:
fn main() {
let s="hello".to_string();
if s.starts_with("hel"){
println!("s 是以hel作为开头的");
}
if s.ends_with("llo"){
println!("s 是以llo作为结尾的");
}
}
尤其是ends_with函数,常用来判断一个文件的后缀是不是指定的格式,比如.txt文本文件等
然后还有判断是否包含某个子字符串,也很常用:
fn main() {
let s="hello 哈喽 world".to_string();
if s.contains("哈喽"){
println!("s 包含哈喽两个字");
}
}