数据库设计——数据库三范式
概述
数据库三范式属于数据库设计过程中。设计一个新的数据库系统需要关注广泛的问题,对于一般的数据库设计来说,大体上是下面的步骤:
-
数据库设计最初阶段需要完整刻画未来数据库用户的数据需求,为了完成这个任务需要设计人员与专家和用户进行交流,产生需求规格说明。
-
经过上面的需求分析,获得了基本的需求规格说明,基于需求利用实体-联系图也就是E-R图,建立概念模型。建立的模型需要不断 进行审查,力求设计出的概念模型对说有数据需求都满足。这个阶段,只关注描述数据及其联系,而不关注物理存储具体实现。
-
完善的概念模式还应该指明企业的功能需求,在功能需求规格说明中,用户描述将在数据上进行的各类操作(或事务)。
-
最后将抽象数据模型进行数据库实现,具体还分为两个阶段:
-
逻辑设计阶段。将高层概念模式映射到将使用的数据库系统的实现数据模型上。实现数据模型通常是关系数据模型,该阶段通常包括将以 实体-联系模型定义的概念模式映射到关系模式。
-
设计者将所得到的系统特定的数据库模式使用到后续的物理设计阶段中。在该阶段指明数据库的物理特征。
通过上述四个步骤,实际上就可以得到一个基本的数据库模式,但是往往这样的数据库模式不一定是良好的数据库模式,设计数据库模式的目标是 生成一组关系模式,使我们存储信息时避免不必要的冗余,也没有增删改查产生的异常,数据也可以保持良好的一致性。基于这个要求,就需要设计 满足适当范式(normal form)的模式来实现。
初学这个概念的时候,可能很难理解为什么要引入这些概念,为什么数据库不能随意设计呢,即使不基于这样的概念,难道不能设计出好的数据库模式吗? 实际上,良好的数据库模式基本上都满足于三范式的要求。殊途同归,因为三范式的设计要求能极大的避免数据冗余,保证数据的一致性和良好的操作性。 因此,理解并在实际设计数据库过程中遵循三范式的要求是一种必然的要求。
随着近些年数据库技术的蓬勃发展,实际上部分数据库已经不遵循这种设计理念了,比如Redshift数据库甚至都不对主键的唯一性做出约束,这样的数据库 设计并不普适与所有的业务场景,传统的PostgreSQL与MySQL还都是遵循这些准则。因此,实际使用数据库管理系统时,需要区分不同数据库的特性,才能 更好的使用他们。
函数依赖
函数依赖是三范式的基础,三范式都是在函数依赖的概念上进一步讨论的。
首先先明确函数依赖的定义,给定一个关系r,如果对实例中所有元组对,t1和t2,都满足t1[a]=t2[a],则t1[b]=t2[b],那么我们说该函数依赖在模式r上成立。我们可以通过下面一组关系来进一步理解函数依赖的概念。
r(A,B,C,D)
| A | B | C | D |
|---|---|---|---|
| a1 | b1 | c1 | d1 |
| a1 | b1 | c1 | d2 |
| a2 | b2 | c2 | d2 |
| a2 | b3 | c2 | d3 |
| a3 | b3 | c2 | d4 |
我们可以注意到每个A的值会对应一个C的值,a1对应c1,a2对应c2,只要是A属性相同取值,C属性取值必然相同,是多对一的关系,这种情况符合函数依赖的定义,记为A-->C,但是反过来,C-->A并不成立。
第一范式
有了函数依赖的定义之后就可以讨论范式的概念了。
第一范式是关系型数据库的基本要求,甚至有的说法称,如果连第一范式都不满足的数据库就肯定不是关系型数据库,虽然一定意义上是这样的,但是现在的数据库系统已经允许一定程度上不满足第一范式的要求。
所谓的第一范式,就是要求所有属性都是原子的属性,不可再分。比如现在有一个个人信息的关系。
r(name,age,gender,address)
| name | age | gender | address |
|---|---|---|---|
| wang | 18 | male | 中国北京市海淀区 |
此时的地址属性就是组合属性,将国家省市和区组合在一起,显然是不符合第一范式的定义,假设某个人搬家,从海淀区搬到朝阳区,则对数据库的修改将变得麻烦,数据库不同表中的相应数据也难以保持一致。
第一范式是关系型数据库的基本要求。
第二范式
第二范式是在第一范式的基础上进行定义的,首先要求每个属性都是不可再分的原子属性,其次要求每个非主属性都要完全函数依赖于码。换句话说将一范式的数据库模式消除部份依赖就可以产生第二范式。
假设有这样一组关系,r(学号,系,宿舍,课程号,分数),根据生活中经验积累,我们可以明确这个关系的主键是(学号,课程号),其中依赖关系是(学号,课程号)-->(系,宿舍,分数)。
但是我们还可以发现其他的依赖关系,学号-->系,学号-->宿舍,这种模式可以通过如下的图形象的表示出来。  这样系和宿舍这两个属性对主键就存在部分依赖,他们都部分依赖于学号这个属性,而不是完全依赖于(学号,课程号)这两个属性,这种部分依赖是第二范式中着重要消除的依赖关系。
这样系和宿舍这两个属性对主键就存在部分依赖,他们都部分依赖于学号这个属性,而不是完全依赖于(学号,课程号)这两个属性,这种部分依赖是第二范式中着重要消除的依赖关系。
这种依赖关系的存在会导致四种问题:
-
数据冗余
-
插入异常
-
删除异常
-
修改复杂,数据不一致
| 学号 | 系 | 宿舍 | 课程号 | 分数 |
|---|---|---|---|---|
| 20200301 | 计算机 | 01 | 200001 | 90 |
| 20200302 | 计算机 | 01 | 200002 | 100 |
| 20200401 | 电气自动化 | 01 | 20001 | 85 |
从上面的示例表可以看到如下问题:
-
系和宿舍显然出现了多次重复,数据冗余,占用数据库的存储空间。
-
假如学校新开设一个人工智能系,还未对外招生,没有学生信息和课程信息,此时这条数据则因为缺少主键不能插入,产生插入异常。
-
假如因为教育部的知识和学校的动态调整,将电气自动化系取消,学生分流向其他系,此时需要删除电气自动化系的记录,却将学号为20200401的学生从数据库中误删,导致学号信息丢失。
面对这些第一范式存在的问题,根据第二范式的原则,我们将这个关系,分解成两个关系。
可以在一定程度上解决第一范式的四个问题,但是那四个问题并没有完全解决,由此就产生了第三范式。
第三范式
为了进一步解决第二范式面对的数据冗余,插入删除异常等问题,提出了第三范式。 第三范式是在第二范式的基础上,消除第二范式中存在的传递依赖所得到的。也就是说,第三范式要求,该数据库的模式每个属性都是原子属性,非主属性对码都是完全函数依赖,非主属性不传递依赖于码。
我们接着讨论上面分析的(学号,系,宿舍,课程号,分数)这个关系。经过第二范式已经分解成两个关系后,实际上,(学号,系,宿舍)中仍然存在一种函数依赖系-->宿舍,学号是这个关系的主属性,系和宿舍是非主属性,但是存在传递依赖关系,通过下图进行理解。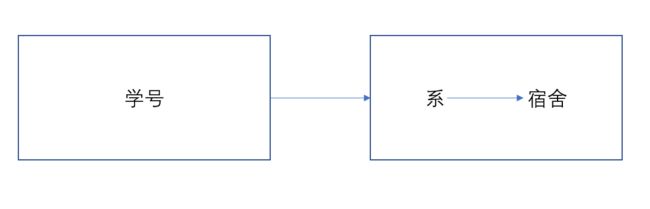
针对这个问题,按照第三范式的原则,我们进一步对这个关系进行分解,进而消除传递依赖。
通过这样分解,我们就能得到一个相对良好的数据库设计模式,可以解决大部分的数据冗余,插入删除异常,数据不一致的情况。但是实际上,第三范式仍然存在一些问题,还不是最严格的设计方案,更加严格的要求进而有BC范式,第四范式等等,感兴趣的同学可以深入研究,日后可以考虑出一起BC范式和第四范式的介绍。
笔者水平有限,在理解前人的成熟知识的基础上写出这篇文章,谬误之处必定多多,还希望批评指针。进步的路上你我相伴才不会孤单。