FusionDiff:第一个基于扩散模型实现的多聚焦图像融合的论文
文章目录
-
- 1. 论文介绍
- 2. 研究动机
- 3. 模型结构
-
- 3.1 网络架构
- 3.2 前向扩散过程
- 3.3 逆向扩散过程
- 3.4 训练和推理过程
- 4. 小样本学习
- 4. 实验结果
1. 论文介绍
题目:FusionDiff: Multi-focus image fusion using denoising diffusion probabilistic models
作者:Mining Li,中国科学技术大学
录用期刊:Expert Systems with Applications 2023
论文地址:paper
开源代码地址:code
论文主要创新点:提出了第一个基于扩散模型 (Diffusion) 实现的多聚焦图像融合模型,并实现了小样本学习,将训练集降低为以往算法的 2% 以内。
2. 研究动机
目前多聚焦图像融合领域中,深度学习方法的效果明显优于传统算法,深度学习方法可以分为基于决策图的方法和端到端的方法。在基于决策图的方法中,学者们致力于提高聚焦/散焦像素的分类精度。在端到端的方法中,学者们致力于尽可能多的从源图像中提取特征并重建出高质量的融合图像。
目前多聚焦图像融合(MFIF)领域缺乏复杂场景的测试集。单考虑 Lytro 和 MFFW 等公开的多聚焦图像融合数据集,这些数据集中图像的结构非常简单,聚焦和散焦区域的分布也不复杂;因此目前达到 SOTA 水平的方法已经能够取得非常好的融合效果了。
但要想在这些简单的数据集上做出更好的效果,就需要使用更复杂的网络结构。因此越来越多的论文致力于使用更复杂的网络模型和结构,使用更多的损失函数来提高融合性能;但这样的工作实现或复现起来是很困难的,其给读者的启发性也比较有限。
本文另辟蹊径,从图像生成的角度考虑图像融合,将其建模为一个条件图像生成任务,并取得了 SOTA 效果。
3. 模型结构
任何基于 Diffusion 实现的算法都高度依赖于对 Diffusion 的理解,这里就不讲解 Diffusion 了。关于 Diffusion 的介绍和数学原理的推导可以参考书籍 《生成式深度学习的数学原理》
3.1 网络架构
FusionDiff 是一个简单的 Conditional Diffusion Model(条件扩散模型)网络,其图像融合示意图如下:
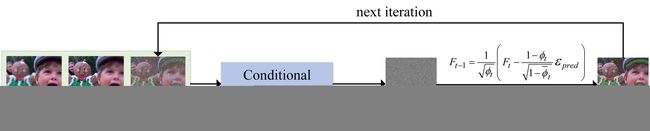
FusionDiff 以两张源图像 { S 1 , S 2 } \{ S_1,S_2 \} {S1,S2} 作为条件输入到噪声预测网络中,将预测的噪声通过 Eq(7) 转换为融合图像的隐变量 F t − 1 F_{t-1} Ft−1,随着迭代步骤 t t t 增加, F t − 1 F_{t-1} Ft−1 变得越来越清晰(与 ground-truth 越来越接近),将 F 0 F_{0} F0 输入作为最终的融合结果。
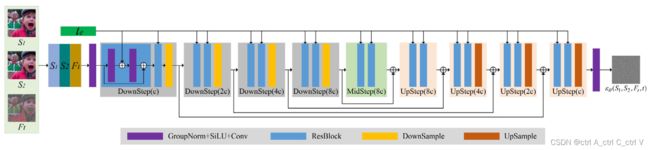
FusionDiff 的噪声预测网络是一个 U-Net 网络:
3.2 前向扩散过程
对于 { S 1 , S 2 , F } \{ S_1,S_2,F \} {S1,S2,F} 的训练集图像对,对真实的融合图像 (ground-truth) F F F 逐步加噪,直到变成纯噪声。示意图如下:

文中设置 T = 2000 T=2000 T=2000,采用 cos 形式的噪声方差变化函数。
3.3 逆向扩散过程
DDPM 的逆向扩散过程为 Eq(6):
F t − 1 = 1 ϕ t ( F t − 1 − ϕ t 1 − ϕ ‾ t ε θ ( F t , t ) ) + Σ θ ϵ , w h e r e ϵ ∼ N ( 0 , I ) \ {F_{t - 1}} = \frac{1}{{\sqrt {{\phi _t}} }}\left( {{F_t} - \frac{{1 - {\phi _t}}}{{\sqrt {1 - {{\overline \phi }_t}} }}{\varepsilon _\theta }\left( {{F_t},t} \right)} \right) + \sqrt {\Sigma _\theta }{{\epsilon}},where \ {\epsilon}\sim N\left( {0, I} \right) Ft−1=ϕt1 Ft−1−ϕt1−ϕtεθ(Ft,t) +Σθϵ,where ϵ∼N(0,I)
作者认为多聚焦图像融合是一个相对确定性的过程,“在MFIF中,观察者很容易区分每个源图像的哪些像素被聚焦,从而大致确定融合图像中应该包含哪些区域。也就是说,对于一系列源图像,FusionDiff 生成的结果应该与观察者预期的融合结果一致,而不是随机生成的。因此 FusionDiff 在图像生成过程中不添加任何随机噪声,以避免融合图像的随机性。”
与 DDIM 相似,FusionDiff 的逆向扩散过程不包含高斯随机噪声项,即 Eq(7):
F t − 1 = 1 ϕ t ( F t − 1 − ϕ t 1 − ϕ ‾ t ε θ ( S 1 , S 2 , F t , t ) ) \ {F_{t - 1}} = \frac{1}{{\sqrt {{\phi _t}} }}\left( {{F_t} - \frac{{1 - {\phi _t}}}{{\sqrt {1 - {{\overline \phi }_t}} }}{\varepsilon _\theta }(S_1, S_2, {F_t}, t)} \right) Ft−1=ϕt1 Ft−1−ϕt1−ϕtεθ(S1,S2,Ft,t)
为了验证基于 Eq(7) 的融合过程是否比基于 Eq(6) 更有效,作者进行了重复性实验:
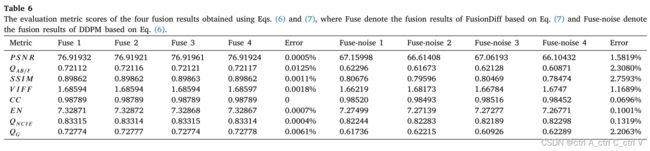
可以看到基于 Eq(7) 的融合结果取得了更高的评价指标得分和更低的误差(即更高的确定性/稳定性)。
3.4 训练和推理过程
训练过程:

推理过程:

4. 小样本学习
FusionDiff 实现了小样本学习,仅仅采用了 100 对多聚焦图像进行训练就取得了 SOTA 的融合结果。以往的 MFIF 算法需要 5000 对图像以上,Table 1 列举了一些代表性的方法的训练集规模:

小样本学习的性能使得 FusionDiff 可能适用于样本稀缺的多聚焦图像融合领域,如显微和生物成像场景。
4. 实验结果
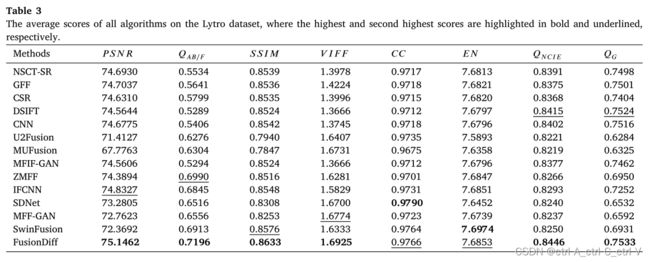
作者对比了当前所有类型的代表性的 MFIF 方法:
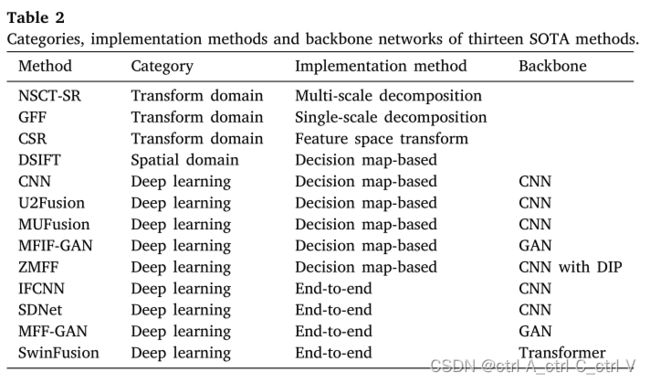
FusionDiff 在 Lytro 和 MFFW 两个公开数据集上取得了 SOTA: