机器学习2022吴恩达老师课程——学习笔记(五)
还是关注房价,假设有两个特征,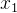 和
和 分别是size和number of bedrooms
分别是size和number of bedrooms
已知,size是300-2000 #bedrooms是0-5(可见一个特征的范围比较大,而另一个比较小)
现有一组样本数据,size是2000,#bedrooms=5,而price是500k美元 (即=2000,=5,![]() =500)
=500)
linear regression model: ![]() (
( )=
)= *+
*+ *+b
*+b
- 若=50 =0.1 b=50 则
 ()=50*2000+0.1*5+50=100050.5 (so,this is not a very good set of parameter choices for and )
()=50*2000+0.1*5+50=100050.5 (so,this is not a very good set of parameter choices for and ) - 若=0.1 =50 b=50 则()=0.1*2000+50*5+50=500
得出结论:When a possible range of values of a feature is large,it is more likely that a good model will learn to choose a relatively small parameter value. When the possible values of feature are small,a reasonable value for its parameters will be relatively large.

 当成本的函数呈现右图中椭圆状的“等高线图”时,梯度下降会复杂(skinny gradient descent may end up bouncing back and forth for a long time)
当成本的函数呈现右图中椭圆状的“等高线图”时,梯度下降会复杂(skinny gradient descent may end up bouncing back and forth for a long time)
所以,这是Feature Scaling就登场了
Feature Scaling
实现Feature Scaling的三种方法:
第一种方法:

第二种方法:

第三种方法:

需要Feature Scaling的情况

如何检查梯度下降收敛?

第一种方法是绘制成本和迭代次数的函数图像,当成本没有很大的下降趋势时,说明已经收敛
第二种方法叫Automatic convergence test,设置一个很小的数(如 ),当成本小于这个数时,认为已经收敛
),当成本小于这个数时,认为已经收敛
如何设置学习率呢(learning rate?)

还是看成本和迭代次数的函数图像,如果函数图像上下反复或者一直上升,说明当前的学习率大了。如果经历了很多很多次迭代,成本还在下降未收敛,说明当前的学习率小了。
过大过小都不好,就需要调整

代码部分(学习率的选择):
1.工具
import math
import copy
import numpy as np
np.set_printoptions(precision=2) #用于控制Python中小数的显示精度
import matplotlib.pyplot as plt
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')
#lab_utils_multi.py中用到的函数
from lab_utils_multi import load_house_data, compute_cost, run_gradient_descent
from lab_utils_multi import norm_plot, plt_contour_multi, plt_equal_scale, plot_cost_i_w2.训练数据读入
# load the dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']这里调用函数load_house_data()
def load_house_data():
data = np.loadtxt("./data/houses.txt", delimiter=',', skiprows=1) #分隔符是','且跳过第一行
X = data[:,:4]
y = data[:,4]
return X, yhouses.txt的部分截图如下:

- data[:,:4] 所有行,每行的前四个元素(:4
 0 1 2 3)
0 1 2 3) - data[:,4] 所有行,每行的第五个元素
data:

3.绘制图标,观察每个特征对应的y(看分布)
fig,ax=plt.subplots(1, 4, figsize=(12, 3), sharey=True) #共享y轴
for i in range(len(ax)): #4个子图
ax[i].scatter(X_train[:,i],y_train) #画点,横坐标X_train[:,i],纵坐标y_train(它们都是同元素个数的列表)
ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("Price (1000's)")
plt.show()
Above, increasing size also increases price. Bedrooms and floors don't seem to have a strong impact on price. Newer houses have higher prices than older houses.
4.将学习率设为9.9e-7,实现梯度下降
(1)计算偏导的函数
def compute_gradient_matrix(X, y, w, b):
"""
Computes the gradient for linear regression
Args:
X : (array_like Shape (m,n)) variable such as house size
y : (array_like Shape (m,1)) actual value
w : (array_like Shape (n,1)) Values of parameters of the model
b : (scalar ) Values of parameter of the model
Returns
dj_dw: (array_like Shape (n,1)) The gradient of the cost w.r.t. the parameters w.
dj_db: (scalar) The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape
f_wb = X @ w + b
e = f_wb - y
dj_dw = (1/m) * (X.T @ e)
dj_db = (1/m) * np.sum(e)
return dj_db,dj_dw
这里,利用向量的运算,显然是比较优秀的
前面在计算偏导是,用的是循环(回顾一下)

(2)计算成本的函数
# Loop version of multi-variable compute_cost
def compute_cost(X, y, w, b):
"""
compute cost
Args:
X : (ndarray): Shape (m,n) matrix of examples with multiple features
w : (ndarray): Shape (n) parameters for prediction
b : (scalar): parameter for prediction
Returns
cost: (scalar) cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
f_wb_i = np.dot(X[i],w) + b
cost = cost + (f_wb_i - y[i])**2
cost = cost/(2*m)
return(np.squeeze(cost)) (3)实现梯度下降(这里比较特殊的是,调用时,传参有传的是函数,形式参数里的cost_function对应的实际参数为compute_cost,gradient_function对应的实际参数为compute_gradient_matrix)
#This version saves more values and is more verbose than the assigment versons
def gradient_descent_houses(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters):
"""
Performs batch gradient descent to learn theta. Updates theta by taking
num_iters gradient steps with learning rate alpha
Args:
X : (array_like Shape (m,n) matrix of examples
y : (array_like Shape (m,)) target value of each example
w_in : (array_like Shape (n,)) Initial values of parameters of the model
b_in : (scalar) Initial value of parameter of the model
cost_function: function to compute cost
gradient_function: function to compute the gradient
alpha : (float) Learning rate
num_iters : (int) number of iterations to run gradient descent
Returns
w : (array_like Shape (n,)) Updated values of parameters of the model after
running gradient descent
b : (scalar) Updated value of parameter of the model after
running gradient descent
"""
# number of training examples
m = len(X)
# An array to store values at each iteration primarily for graphing later
hist={}
hist["cost"] = []; hist["params"] = []; hist["grads"]=[]; hist["iter"]=[];
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
save_interval = np.ceil(num_iters/10000) # prevent resource exhaustion for long runs
print(f"Iteration Cost w0 w1 w2 w3 b djdw0 djdw1 djdw2 djdw3 djdb ")
print(f"---------------------|--------|--------|--------|--------|--------|--------|--------|--------|--------|--------|")
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_db,dj_dw = gradient_function(X, y, w, b)
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save cost J,w,b at each save interval for graphing
if i == 0 or i % save_interval == 0:
hist["cost"].append(cost_function(X, y, w, b))
hist["params"].append([w,b])
hist["grads"].append([dj_dw,dj_db])
hist["iter"].append(i)
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters/10) == 0:
#print(f"Iteration {i:4d}: Cost {cost_function(X, y, w, b):8.2f} ")
cst = cost_function(X, y, w, b)
print(f"{i:9d} {cst:0.5e} {w[0]: 0.1e} {w[1]: 0.1e} {w[2]: 0.1e} {w[3]: 0.1e} {b: 0.1e} {dj_dw[0]: 0.1e} {dj_dw[1]: 0.1e} {dj_dw[2]: 0.1e} {dj_dw[3]: 0.1e} {dj_db: 0.1e}")
return w, b, hist #return w,b and history for graphing(4)运行梯度下降
def run_gradient_descent(X,y,iterations=1000, alpha = 1e-6):
m,n = X.shape
# initialize parameters
initial_w = np.zeros(n)
initial_b = 0
# run gradient descent
w_out, b_out, hist_out = gradient_descent_houses(X ,y, initial_w, initial_b,
compute_cost, compute_gradient_matrix, alpha, iterations)
print(f"w,b found by gradient descent: w: {w_out}, b: {b_out:0.2f}")
return(w_out, b_out, hist_out)(5)将学习率设为9.9e-7
#set alpha to 9.9e-7
_, _, hist = run_gradient_descent(X_train, y_train,10, alpha = 9.9e-7)经过层层调用之后,输出结果为:

(6)绘制迭代次数以及w[0]和成本之间的关系的图像
def plot_cost_i_w(X,y,hist):
ws = np.array([ p[0] for p in hist["params"]])
print(ws)
rng = max(abs(ws[:,0].min()),abs(ws[:,0].max())) #w[0]所有迭代取值的最大值
print(rng)
wr = np.linspace(-rng+0.27,rng+0.27,20) # 均匀间隔 创建数值序列
print(wr)
#固定w[1]、w[2]、w[3]以及b
cst = [compute_cost(X,y,np.array([wr[i],-32, -67, -1.46]), 221) for i in range(len(wr))] #len(wr)为20
fig,ax = plt.subplots(1,2,figsize=(12,3))
#自变量为迭代次数,因变量为成本
ax[0].plot(hist["iter"], (hist["cost"])); ax[0].set_title("Cost vs Iteration")
ax[0].set_xlabel("iteration"); ax[0].set_ylabel("Cost")
ax[1].plot(wr, cst); #自变量为wr,因变量为cst,绘制抛物线
ax[1].set_title("Cost vs w[0]")
ax[1].set_xlabel("w[0]"); ax[1].set_ylabel("Cost")
ax[1].plot(ws[:,0],hist["cost"])
plt.show()
plot_cost_i_w(X_train, y_train, hist)
上面的右图,蓝色线是固定了其他的参数(w[1] w[2] w[3] 和b),计算20个w[0]的取值对应的成本的函数。 黄色线是体现w[0]和迭代过程中产生的成本的关系的函数。
Note that this is not a completely accurate picture as there are 4 parameters being modified each pass rather than just one. This plot is only showing w0 with the other parameters fixed at benign values.Note that this is not a completely accurate picture as there are 4 parameters being modified each pass rather than just one. This plot is only showing w0 with the other parameters fixed at benign values.
可以看出,当前的学习率太大了,导致成本上升
5.将学习率(应小于9.9e-7)调整为9e-7,实现梯度下降
#set alpha to 9e-7
_,_,hist = run_gradient_descent(X_train, y_train, 10, alpha = 9e-7)
plot_cost_i_w(X_train, y_train, hist)
On the left, you see that cost is decreasing as it should. On the right, you can see that w0 is still oscillating around the minimum, but it is decreasing each iteration rather than increasing. Note above that dj_dw[0] changes sign with each iteration as w[0] jumps over the optimal value. This alpha value will converge. You can vary the number of iterations to see how it behaves.
好吧,那我把迭代次数改大一点:
#set alpha to 9e-7
_,_,hist = run_gradient_descent(X_train, y_train, 100, alpha = 9e-7)
plot_cost_i_w(X_train, y_train, hist)看图:

就是横跳吧,说明学习率还是大了,但成本时下降的(感觉也可以)
5.再将学习率调整为1e-7,实现梯度下降
#set alpha to 1e-7
_,_,hist = run_gradient_descent(X_train, y_train, 10, alpha = 1e-7)
plot_cost_i_w(X_train,y_train,hist)
可见,这个学习率是不错的.
代码部分(Scaling Feature)
三种方法:

看Z-score normalization 这种方法 :

1. 将各特征的样本值进行特征缩放(X_train  X_norm)的函数
X_norm)的函数
def zscore_normalize_features(X):
"""
computes X, zcore normalized by column
Args:
X (ndarray): Shape (m,n) input data, m examples, n features
Returns:
X_norm (ndarray): Shape (m,n) input normalized by column
mu (ndarray): Shape (n,) mean of each feature
sigma (ndarray): Shape (n,) standard deviation of each feature
"""
# find the mean of each column/feature
#np.mean求均值,axis=0是计算每一列的均值(这里就是对每一特征求均值)
mu = np.mean(X, axis=0) # mu will have shape (n,)
# find the standard deviation of each column/feature
#np.std求标准差,axis=0是计算每一列的标准差(这里就是对每一特征求标准差)
sigma = np.std(X, axis=0) # sigma will have shape (n,)
# element-wise, subtract mu for that column from each example, divide by std for that column
X_norm = (X - mu) / sigma
return (X_norm, mu, sigma)2.观察Z-score normalization 怎么一步步变化的
mu = np.mean(X_train,axis=0)
sigma = np.std(X_train,axis=0)
X_mean = (X_train - mu)
X_norm = (X_train - mu)/sigma
fig,ax=plt.subplots(1, 3, figsize=(12, 3))
ax[0].scatter(X_train[:,0], X_train[:,3])
ax[0].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[0].set_title("unnormalized")
ax[0].axis('equal')
ax[1].scatter(X_mean[:,0], X_mean[:,3])
ax[1].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[1].set_title(r"X - $\mu$")
ax[1].axis('equal')
ax[2].scatter(X_norm[:,0], X_norm[:,3])
ax[2].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[2].set_title(r"Z-score normalized")
ax[2].axis('equal') #横轴纵轴的单位长度相同
plt.tight_layout(rect=[0, 0.03, 1, 0.95]) #用来调整图形的布局
fig.suptitle("distribution of features before, during, after normalization")
plt.show()
3.来看看X_train和X_norm,比比
# normalize the original features
X_norm, X_mu, X_sigma = zscore_normalize_features(X_train)
print(f"X_mu = {X_mu}, \nX_sigma = {X_sigma}")
#np.ptp是求最小值和最大值的差,axis=0是对每列来说
print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}")
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")
- 未经特征缩放的 X_train :特征0-3最大值和最小值的差距分别是2410、4、1、9.5(这几个数还差挺大的吧)
- 经特征缩放的X_norm:缩放后特征0-3最大值和最小值的差距分别是5.85 6.14 2.06 3.69
【可见,通过归一化,每列的峰间范围从数千倍减小到2-3倍】
4.运行梯度下降,这里用的是特征缩放后的X_norm
w_norm, b_norm, hist = run_gradient_descent(X_norm, y_train, 1000, 1.0e-1, )
The scaled features get very accurate results much, much faster!
比较未经特征缩放的梯度下降情况:
_,_,hist = run_gradient_descent(X_train, y_train, 1000, alpha = 1e-7)
比较一下,可见特征缩放后的收敛加快了不少(可见特征缩放的重要意义)
5.看看预测的好不好
#predict target using normalized features
m = X_norm.shape[0]
yp = np.zeros(m)
for i in range(m):
yp[i] = np.dot(X_norm[i], w_norm) + b_norm
# plot predictions and targets versus original features
fig,ax=plt.subplots(1,4,figsize=(12, 3),sharey=True)
for i in range(len(ax)):
ax[i].scatter(X_train[:,i],y_train, label = 'target') #真实分布
ax[i].set_xlabel(X_features[i])
ax[i].scatter(X_train[:,i],yp,color=dlorange, label = 'predict') #模型的预测分布
ax[0].set_ylabel("Price");
ax[0].legend();
fig.suptitle("target versus prediction using z-score normalized model")
plt.show()
蓝色的点体现了真实的分布,黄色的点体现模型预测的分布(可见,我们找到的模型效果不错)
6.预测
新的样本数据(对应各特征)为:size 1200; #bedrooms 3; #floors 1;age of home in years 40
# First, normalize out example.
x_house = np.array([1200, 3, 1, 40])
x_house_norm = (x_house - X_mu) / X_sigma
print(x_house_norm)
x_house_predict = np.dot(x_house_norm, w_norm) + b_norm
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.0f}")将各数据进行特征缩放(X_house X_house_norm)
