罕见!阿里云爆发史诗级故障!
南京林科斯拉-智能运维管家,智能极简 全栈监控。 (linksla.cn) https://www.linksla.cn/#/
https://www.linksla.cn/#/
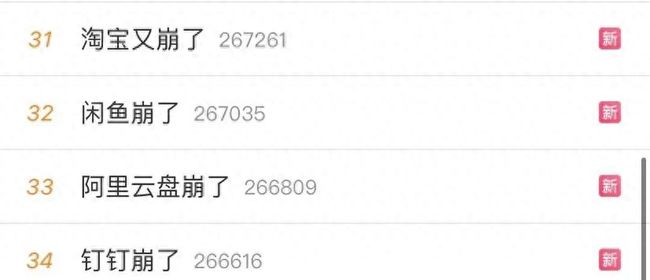
11月12日晚间阿里云发生故障。“阿里云盘崩了” “淘宝又崩了” “闲鱼崩了” “钉钉崩了” 等话题相继登上热搜,阿里系诸多产品受到影响。
阿里云对此公告称,2023年11月12日17:44起,阿里云监控发现云产品控制台访问及API调用出现异常,阿里云工程师正在紧急介入排查。18:54阿里云再度公告,经过工程师处理,杭州、北京等地域控制台已恢复,其他地域控制台服务逐步恢复中。
这次故障使大部分阿里系产品受到影响,包括:淘宝、阿里云、钉钉、语雀、闲鱼、阿里云盘…… 从17:44分开始, 截至晚上21:11分才完全恢复。

据悉,此次受影响产品包括企业级分布式应用服务、消息队列MQ、微服务引擎、链路追踪、应用高可用服务、应用实时监控服务、Prometheus监控服务、消息服务、消息队列Kafka版、机器学习、图像搜索、智能推荐AlRec等。
受影响地域涵盖华北2 (北京)、华北6 (乌兰察布)、 华北1 (青岛)、华东2(上海)、华南2(河源)、华北3(张家口)、中国香港、印度(孟买)、美国(硅谷)、华南1(深圳)、英国(伦敦)、韩国(首尔)、日本(东京)、阿联酉(迪拜)、西南1 (成都)、华南3 (广州)、新加坡、澳大利亚 (悉尼)、马来西亚(吉隆坡)、 华北5 (呼和浩特)、 印度 尼西亚(雅加达)、美国 (弗吉尼亚)、菲律宾 (马尼拉)、泰国(曼谷)、华东1(杭州)、华南1金融云。
这一次故障,影响范围之大,可以说是史诗级的,已经不是“杀个程序员祭天” 所能平息的,至少也得是CEO吧...
事件发生后,热心网友开始追根溯源,激烈讨论,其中有一股清流表示:
今年国内各大一线互联网大厂都下达了严苛的降本增效任务, 要求每个产品线的运营成本缩减20%-40%不等。为此不少身处一线的开发和运维童鞋都是绞尽脑汁的做各种代码逻辑优化,服务器配置缩容等。本来稳定运行的代码,新来的同事如果没有充分理解的情况下就下手修改,不可避免就会产生问题;服务器的配置本来有一定的空余,领导硬是要求要充分利用,多个组件混合部署在一起,也可能导致在高峰期硬件资源不足出现相互抢占,从而导致集群稳定性下降......
尽管这次故障不能影响阿里云在云服务的领先地位,但它确实揭示大型云服务提供商也可能存在的潜在问题;用户需要更加重视运维管理,毕竟备份重于一切才是IT运维中唯一真理。
上云后,风险被集中,故障影响更大。站在用户角度,如果单机部署,不管放在哪家云上,都存在一定的风险,相对于传统的分散计算,云计算把资源集中在一起,因而风险也被集中。云端成了单点故障,如果云端发生事故,则影响面非常巨大。用户对数据掌控灵活度降低,且系统运维的工作不会减少,传统运维手段不能满足云上业务需求,运维如何做到降本增效呢?
云上运维的进阶之道
1、全面敏捷的监控系统
将所有资产并入监控系统,对每个资源节点的状态、性能进行实时监控。展示系统运行状态,高效应对规模庞大的基础设施,网络设备、服务器、存储、应用等。
2、准确预测,实时掌握系统运行状态。
以业务视角监控系统健康度,系统视图展示各个资产运行的状态,业务拓扑图、告警列表趋势等。
能预先发现漏洞,防患于未然;事后控制不如事中控制,事中控制不如事前控制;
3、服务闭环,成本大降
“监”全栈监控,全局视角整合告警事件、性能指标、日志和容量等多维数据,重点发现故障节点;“管”就是配合资产变更和事件流程;“控”重点还是在增强可靠性减少故障。
提供7*24在线值守,配备moc专家和二线专家团队,提高事件的响应及处理效率,大大降低人力成本和专家技术成本,确保故障事件都能得到追踪和及时解决。
4、AI机器学习,精准预测及时响应
实现精准告警、异常检测、根因定位和容量分析等场景。异常告警智能化,基于动态阈值的报警确认,对海量的时序指标进行异常检测,实现故障快速响应:能发现问题,也能提供解决方案。
LinkSLA智能运维管家,开放生态广泛兼容,可延伸对接云服务,也可支持多厂商设备管理、异构资源池纳管。在全栈统一管理的基础上,结合业务高效发放以及 AI 技术赋予的智能故障定位、提前风险预知等能力,信息中心运维平台将快速从人工走向智能,实现高效率的运维管理。