【论文阅读】MD-GAN: Multi-Discriminator Generative Adversarial Networks for Distributed Datasets
论文地址:[1811.03850] MD-GAN: Multi-Discriminator Generative Adversarial Networks for Distributed Datasets (arxiv.org)

本文介绍了一种名为MD-GAN的新方法,可以在分布式数据集上训练生成对抗网络(GAN)。文章首先介绍了GAN的背景和构成,然后提出了分布式GAN训练的挑战,即如何在多个工作节点上细粒度地分配GAN的两个组件:生成器和判别器。为了解决这个问题,作者提出了MD-GAN,使用单个生成器和多个判别器,并使用点对点通信模式在工作节点之间传递判别器。作者还比较了MD-GAN和联邦学习对GAN(在这里作者提出了一个将联邦学习和GAN结合的方法FL-GAN)的性能,使用了MNIST和CIFAR10数据集,并进行了实验。最后,作者讨论了分布式GAN的现实意义以及未来的研究方向。
Q1:论文试图解决一个什么问题?
这篇论文试图解决分布式数据集上的生成对抗网络(GAN)训练问题。GAN是一种生成式模型,需要大量的训练数据才能拟合目标应用。然而,由于GAN由两个深度神经网络组成,且需要在大型数据集上训练,因此计算成本很高。通常情况下,GAN是在单个服务器上训练的,而本文提出了一种新的学习程序——MD-GAN,可将GAN分布式训练在多个工作节点上。该方法通过降低工作节点上的计算负担,实现了更高效的训练。本文还将MD-GAN与联邦学习方法进行了比较,并在MNIST和CIFAR10数据集上进行了实验,证明了MD-GAN的优越性能。
Q2:MD-GAN的关键之处是什么?
MD-GAN的关键之处在于它是第一个能够在分布式数据集上训练生成对抗网络(GAN)的解决方案。为了解决分布式计算的挑战,MD-GAN提出了一种新颖的学习过程,通过将生成器放在服务器上,将部分负担从工作节点上移除,同时通过在工作节点之间建立点对点的通信模式来实现。MD-GAN通过将多个鉴别器放在工作节点上,使它们面对一个单独的生成器,从而在保持计算和通信效率的同时提高了模型的准确性。此外,MD-GAN还通过将训练批次大小与工作节点数成反比例关系,进一步优化了其计算复杂度。
Q3:实验设计?
- 使用Keras框架和Tensorflow后端进行实验。
- 在GPU服务器上模拟工作人员和服务器。
- 使用MNIST和CIFAR10数据集进行实验。
- 在实验中使用了传统的GAN(称为standalone-GAN),FL-GAN和MD-GAN三种方法进行比较。
- 使用Inception Score (IS) 和Fréchet Inception Distance (FID)这两种评估指标来评估生成模型的性能。
- 对于MNIST数据集,使用MNIST Score (MS) 作为评估指标。
- 在实验中比较了不同的GAN架构,如多层感知器(MLP)和卷积神经网络(CNN)。
- 对于MD-GAN,使用不同的参数设置(例如,k = 1和k = log(N))进行实验,以评估数据多样性对性能的影响。
- 通过增加工作人员数量来评估MD-GAN的可扩展性,并研究工作人员之间的通信对性能的影响。
- 通过模拟工作人员故障来评估MD-GAN的容错性能力。
- 使用CelebA数据集进行实验,以验证MD-GAN在更大的数据集上的性能表现。
Q4:文章贡献
这篇论文的主要贡献是提出了一种名为MD-GAN的方法,用于在分布式数据集上训练生成对抗网络(GAN)。这种方法利用一个参数服务器来承载生成器,并将判别器分配到多个工作机上。与其他方法相比,MD-GAN在每个节点上减少了一半的学习复杂度,并在MNIST和CIFAR10数据集上表现出更好的性能。此外,该论文还介绍了GAN的基本背景和与分布式计算相关的问题。
Q5:还存在的缺陷
- 实验的数据集较少。该论文只在MNIST和CIFAR10数据集上进行了实验,这两个数据集都是比较小的图像数据集。因此,该方法在更大规模的数据集上的表现仍然需要进一步探讨。(并且可以在表格数据集上进行探索)
- 没有考虑分布式环境下的安全性问题。在实际应用中,分布式训练往往需要考虑如何保护敏感数据以及防止恶意攻击等问题,而该论文并未对此进行充分的讨论。
- 作者并未考虑使用其他的优化算法。该论文采用了Adam优化算法来更新模型参数,但是并没有比较该算法和其他优化算法在分布式训练中的表现。
Q6:下一步工作
如何应对GAN中的对抗性环境,如何更好地实现容错性,如何在更多的工作节点上扩展MD-GAN算法等等。因此,未来的工作可以进一步研究这些问题,以提高分布式训练GAN的性能和效率。
MD-GAN的工作流程:
MD-GAN 的目标是训练一个中心生成器 G。在 MD-GAN 中,中心服务器上的 G 使用分布式服务器及其本地共享数据进行训练。这是一个 1-vs-N 游戏,其中 G 面临所有 Dn,即 G 尝试生成所有分布式服务器认为是真实的数据。各个分布式使用他们的本地数据集和Dn将生成的数据与真实数据区分开来。
1.中心服务器生成一组 K 个批次 K ={X(1),., X(k)},k ≤ N。每个 X(i) 由 G 生成的 b 个数据组成。然后服务器为每个分布式服务器 n 选择两个不同的批次,例如 X(i) 和 X(j),它们被发送到服务器 n 并本地重命名为 X(g)n 和 X(d)n。
2.每个服务器 n 使用 X(d)n 和 X(r)n 对其鉴别器 Dn 执行 L 次学习迭代,其中 X(r)n 是从 Bn 本地提取的一批真实数据。
3.每个服务器 n通过使用Dn计算X(g)n上的误差反馈Fn,并将该误差发送给服务器。
4.服务器使用所有 Fn 反馈为其参数 w 计算 Jgen 的梯度。然后它使用选定的优化器算法(例如 Adam)更新其参数。
MD-GAN与FL-GAN的区别:
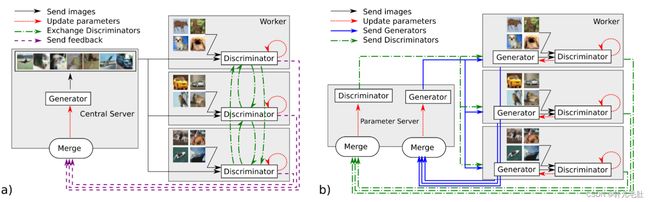
a) MD-GAN 通信模式,与 b) FL-GAN(适应 GAN 的联邦学习)相比。MD-GAN利用放置在服务器上的单个生成器;FL-GAN在服务器上和每个worker上使用生成器。MD-GAN 以点对点的方式交换工作人员之间的鉴别器,而在 FL-GAN 中,它们保持固定,并在收到工作人员后由服务器平均。
MD-GAN和FL-GAN都是用于分布式训练生成对抗网络(GANs)的方法。它们的主要区别在于如何处理生成器(G)的任务和工作负载。
在MD-GAN中,生成器(G)的任务由服务器处理,而工作节点只需处理本地鉴别器(D)的参数和计算误差反馈。每个全局迭代,工作节点执行2bD个浮点运算,其中D是一个数据对象的前向传递步骤中的浮点操作数。通信复杂性取决于数据对象的大小和批量大小。
相比之下,在FL-GAN中,每个工作节点都需要执行生成器(G)和鉴别器(D)的任务。每个工作节点在本地数据上执行E个迭代,然后将参数发送到服务器,以便进行平均值计算和参数更新。通信复杂性取决于GAN参数的大小。
总之,MD-GAN通过将生成器(G)的任务移到服务器上来降低了工作节点的工作量,从而提高了效率。FL-GAN则要求每个工作节点都执行生成器(G)和鉴别器(D)的任务,因此需要更多的通信和计算。
