【博学谷学习记录】超强总结,用心分享 | 狂野大数据-Hive函数
文章目录
- 一、Hive的内置函数
-
- 1.1数学函数
- 1.2 字符串函数
- 1.3 日期函数
- 1.4 条件判断函数
- 二、行转列和列转行函数
-
- 2.1行转列
- 2.2 列转行
- 三、 窗口函数
- 四、 自定义函数
-
- 4.1 自定义UDF函数
- 4.2 自定义UDTF函数
- 总结
一、Hive的内置函数
1.1数学函数
-- 四舍五入
select round(3.456);
-- 指定位数四舍五入
select round(3.455,1);
-- 向下取整
select floor(3.9);
-- 向上取整
select ceil(3.1);
-- 取随机数 -- 1到100之间的随机数
select `floor`((rand() * 100)+1);
-- 绝对值
select abs(-12);
-- 几次方运算
select pow(2,3); -- 2的3次方
1.2 字符串函数
-- URL路径解析
select parse_url('https://www.bilibili.com/video/BV1E4411H73v/?p=64&spm_id_from=pageDriver&vd_source=3673b24e06f610677de7d2b4998d22bc','HOST');
select parse_url('https://www.bilibili.com/video/BV1E4411H73v/?p=64&spm_id_from=pageDriver&vd_source=3673b24e06f610677de7d2b4998d22bc','PATH');
select parse_url('https://www.bilibili.com/video/BV1E4411H73v/?p=64&spm_id_from=pageDriver&vd_source=3673b24e06f610677de7d2b4998d22bc','QUERY');
select parse_url('https://www.bilibili.com/video/BV1E4411H73v/?p=64&spm_id_from=pageDriver&vd_source=3673b24e06f610677de7d2b4998d22bc','QUERY','p');
select parse_url('https://www.bilibili.com/video/BV1E4411H73v/?p=64&spm_id_from=pageDriver&vd_source=3673b24e06f610677de7d2b4998d22bc','QUERY','vd_source');
-- json数据解析
select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.name');
select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.age');
select get_json_object('{"name": {"aaa":"bbb"}}', '$.name.aaa');
-- 本地模式,测试环境加速查询
set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true;
-- 字符串拼接
create table student(
id int,
name string,
ageyear string,
gender string
) row format delimited fields terminated by '\t';
load data local inpath '/root/test/hive_data/student.txt' overwrite into table student;
select * from student;
select concat(`floor`((rand()*100)+1),'-',id) as sid, name from student;
-- 字符串拼接,带分隔符
select concat_ws('-','2022','10','15');
-- 对数函数
select log10(100); -- 对数函数
-- 字符串截取
select substr('2022-12-23 10:13:45',1,4); -- 2022
select substring('2022-12-23 10:13:45',6,2); -- 12
-- 字符串替换
select regexp_replace('floobar','oo','*');
-- 字符串切割
select split('2022-12-23','-');
1.3 日期函数
select unix_timestamp();-- 离1970年1月1日秒值,晚了8个小时
select current_date(); -- 获取当前的年月日
select `current_timestamp`(); -- 获取当前的年月日,时分秒
-- 将时间戳转换为时间格式
select from_unixtime(1677596757,'yyyy-MM-dd HH:mm:dd');
select from_unixtime(unix_timestamp()+8*3600,'yyyy-MM-dd HH:mm:dd');
-- 将时间转换为时间戳
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
select unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒');
select from_unixtime(unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒'),'yyyy-MM-dd HH:mm:dd');
-- 日期格式转换
select date_format('2022-1-1 3:5:6', 'yyyy-MM-dd HH:mm:ss');
-- 获取年月日
select to_date('2011-12-08 10:03:01');
select year('2011-12-08 10:03:01') +10;
select substring('2011-12-08 10:03:01', 1, 4) + 10;
select hour('2011-12-08 10:03:01');
--获取当前日期周几
select `dayofweek`('2023-02-28') -1;-- 默认周日是第一天
-- 获取当前日期是当年的第几周
select weekofyear('2023-02-28');
-- 获取季度
select quarter('2023-02-28');
-- 日期的差值
select datediff('2023-02-28', '2008-08-08');
select abs(datediff('2008-08-08', '2023-02-28'));
-- 日期向后推移(:天)
select date_add('2023-02-28',100);
-- 日期向前推移 (:天)
select date_add('2023-02-28',-100);
-- 日期向前推移 (:天)
select date_sub('2023-02-28',100);-- 同上
1.4 条件判断函数
-- if语句
select *,
if(sscore >= 60, '及格', '不及格') as flag
from score;
-- case语句
select *,
case sex
when 'm' then '男'
when 'f' then '女'
end as gender
from test3;
select *,
case
when sscore >= 90 then '优秀'
when sscore >= 80 then '良好'
when sscore >= 60 then '及格'
when sscore < 60 then '不及格'
else '其他' end
from score;
二、行转列和列转行函数
2.1行转列
用的是collect_list()函数,collect_set()函数(可去重)
代码如下(示例):
-- collect_list可以将每一组的ename存入数组,不去重
select deptno,collect_list(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重
select deptno,collect_set(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重,concat_ws将数组中的每一个元素进行拼接
select deptno,concat_ws('|',collect_set(ename)) as enames from emp group by deptno;
2.2 列转行
使用的是侧视图lateral view爆炸函数explode(),
代码如下(示例):
-- 将原来的表emp2和炸开之后的表进行内部的关联,判断炸开的每一行都来自哪个数组
select * from emp2 lateral view explode(names) t as name;
-- t是explode生成的函数的别名,name是explode列的别名
select deptno, name from emp2 lateral view explode(names) t as name
三、 窗口函数
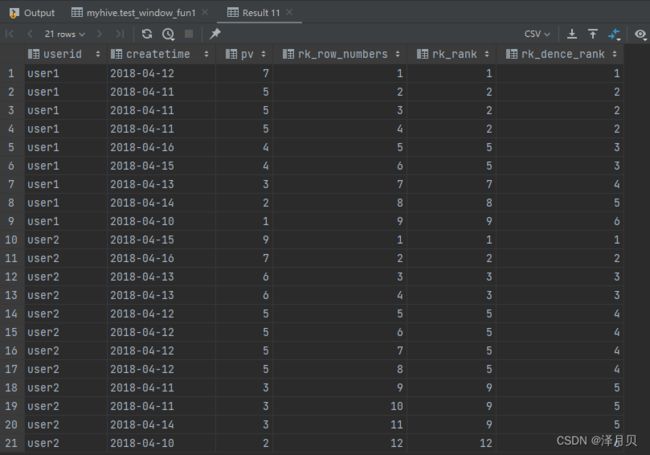
主要的窗口函数row_number(),rank(), dense_rank()将分组(group by)之后的的列与原表的其他列关联在一起查询显示
需求:按照用户进行分组,并且在每一组内部按照pv进行降序排序
-- row_number,rank,dense_rank
/*
partition by userid 按照哪个字段分组,等价于group by
order by pv desc 组内按照哪个字段排序
*/
select *,
row_number() over (partition by userid order by pv desc) as rk_row_numbers,
rank() over (partition by userid order by pv desc) as rk_rank,
dense_rank() over (partition by userid order by pv desc) as rk_dence_rank
from test_window_fun1;
运行结果如下
四、 自定义函数
1、当在进行数据分析时,如果Hive现存的所有函数都无法满足需求,则可以自定义函数
2、自定义函数的分类
UDF : 一进一出的函数 substring、floor、reverse
UDTF: 一进多出的函数 explode
UDAF: 多进一出的函数 聚合函数(count、max、min)
4.1 自定义UDF函数
1、 继承UDF类,重写evaluete()方法
import org.apache.hadoop.hive.ql.exec.UDF;
/*
手机号: 13812345678 ---> 138****5678
*/
@SuppressWarnings("all")
public class MyUDF extends UDF {
public String evaluate(String phoneNum){
String str1 = phoneNum.substring(0,3);
String str2 = phoneNum.substring(7);
return str1 + "****" + str2;
}
}
2、
3、将自定义类代码打成jar包,添加造Hive的lib目录,并重命名(自定义名字)
mv module_hive-1.0-SNAPSHOT.jar my_udf.jar
3、在hive的客户端添加我们的jar包
hive> add jar /export/server/hive-3.1.2/lib/my_udf.jar
4、注册函数
-- 注册临时函数
hive> create temporary function phone_num_enc as 'pack01_udf.MyUDF';
-- 注册永久函数
hive> create function phone_num_enc2 as 'pack01_udf.MyUDF'
using jar 'hdfs://node1:8020/hive_func/my_udf.jar';
5、使用自定义函数
hive> select phone_num_enc('13812345678');
hive> select phone_num_enc2('13812345678');
4.2 自定义UDTF函数
package pack02;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private final Object[] forwardList = new Object[1];
/*
该方法只会执行一次,用于初始化
该方法用来定义:UDTF输出结果有几列,每一列的名字和类型
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//设置UDTF函数输出的每一列的名字
ArrayList<String> fieldNames = new ArrayList<>();
//设置列名
fieldNames.add("name");
//设置UDTF函数输出的每一列类型
// ArrayList fieldOIs = new ArrayList<>();//检查器列表
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//第一列:String类型
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
//每来一行数据,该方法就会调用一次
/*
select my_udtf(字段,分隔符)
select my_udtf(‘zookeeper,hadoop,hdfs,hive,MapReduce’,',')
Object[] objects = {‘zookeeper,hadoop,hdfs,hive,MapReduce’,',' }
*/
@Override
public void process(Object[] objects) throws HiveException {
//1、获取原始数据
String line = objects[0].toString();
//2、获取数据传入的第二个参数,此处为分隔符
String splitKey = objects[1].toString();
//3.将原始数据按照传入的分隔符进行切分
String[] wordArray = line.split(splitKey);
//4:遍历切分后的结果,并写出
for (String word : wordArray) {
//将每一个单词添加值对象数组
forwardList[0] = word;
//将对象数组内容写出,每写一次就会多出一行
forward(forwardList);
}
}
@Override
public void close() throws HiveException {
}
}
上下步骤和实现UDF函数一致
总结
Hive SQL 的数学函数与mysql的sql语句基本一致,上文所列的窗口函数与mysql8.0支持的窗口函数也是大同小异,sql的语法都是差不多,就是hive是处理大数据的,hive sql会根据自己的需求做一些改变。