大数据应用之 --- SparkSQL和 Hive的集成
大数据应用之 — SparkSQL和 Hive的集成
创建软链接
ln -s /opt/hive-3.1.3/conf/hive-site.xml /opt/spark-3.2.1/conf/hive-site.xml
复制mysql连接jar包
cp /opt/hive-3.1.3/lib/mysql-connector-java-5.1.48.jar /opt/spark-3.2.1/jars/
修改配置spark-defaults.conf
vi /opt/spark-3.2.1/conf/spark-defaults.conf
#增加如下内容
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
vi /opt/spark-3.2.1/conf/hive-site.xml
#增加如下内容
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-node1:9083</value>
</property>
启动spark-sql测试
spark-sql --master yarn
#进入客户端,进行sql语句操作
spark-sql (default)> show databases;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cyJJjqOc-1657903530540)(C:\Users\yuanf\AppData\Roaming\Typora\typora-user-images!在这里插入图片描述
)]
yarn日志:
发现只有一个job:
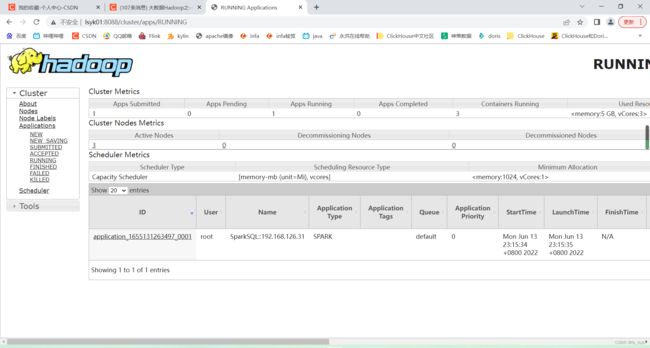
点进去能看到每一次执行sql语句:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kJQH3IxG-1657903530547)(C:\Users\yuanf\AppData\Roaming\Typora\typora-user-images
解决问题
1. WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
2. WARN HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
3. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
其中问题2很奇怪,实际上hive-site.xml里是有这个参数的,不知道为啥不认
估计是弃用了,干脆注释掉,问题解决
问题3:
【原因】spark预先编译的hadoop版本为32位的,放在64位的机器上执行会报这个错误
【解决】在spark的conf目录下,在spark-env.sh文件中加入LD_LIBRARY_PATH环境变量
LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
vi /opt/spark-3.2.1/conf/spark-env.sh
#添加以下内容:
LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
问题1:
【原因】是因为Spark提交任务到yarn集群,需要上传相关spark的jar包到HDFS。
【解决】 提前上传到HDFS集群,并且在Spark配置文件指定文件路径,就可以避免每次提交任务到Yarn都需要重复上传文件。下面是解决的具体操作步骤:
### 打包jars,jar相关的参数说明
#-c 创建一个jar包
# -t 显示jar中的内容列表
#-x 解压jar包
#-u 添加文件到jar包中
#-f 指定jar包的文件名
#-v 生成详细的报造,并输出至标准设备
#-m 指定manifest.mf文件.(manifest.mf文件中可以对jar包及其中的内容作一些一设置)
#-0 产生jar包时不对其中的内容进行压缩处理
#-M 不产生所有文件的清单文件(Manifest.mf)。这个参数与忽略掉-m参数的设置
#-i 为指定的jar文件创建索引文件
#-C 表示转到相应的目录下执行jar命令,相当于cd到那个目录,然后不带-C执行jar命令
cd /opt/spark-3.2.1
jar cv0f spark-libs.jar -C ./jars/ .
### 在hdfs上创建存放jar包目录
hadoop fs -mkdir -p /spark/jars
## 上传jars到HDFS
hadoop fs -put spark-libs.jar /spark/jars/
## 增加配置spark-defaults.conf
vi spark-defaults.conf
#增加以下内容
spark.yarn.archive=hdfs://lsyk01:9000/spark/jars/spark-libs.jar
验证:
spark-sql --master yarn

spar-sql客户端
-
sql语句
spark-sql --master yarn #输入sql语句即可
yarn里只有一个纵队appid
-
执行sql文件
编写sql 文件 /works/sparksql.sql:
use lsyk; select count(1) from lsyk.ls; -- select * from ls,yk; desc ls; show create table pqt; /* select * from pqt order by score; */ select ls.name ,row_number() over(partition by ls.name --- 这是注释 order by ls.age) as rn /* 这是注释2 */ from ls,yk ;
insert into table pqt partition (ds=‘p1’)
select ls.name,ls.age
from ls,
yk
;
执行:
```shell
spark-sql --master yarn -f /works/sparksql.sql
执行结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CFwFIPLE-1657903530552)(C:\Users\yuanf\AppData\Roaming\Typora\typora-user-images\image-20220616000837453.png)]
由此可见,支持换行,注释,中文等各格式,完全可以直接这样写个shell,传参,传sql文件,替换参数,写入新sql文件,作为spark-sql的-f文件执行
但是,yarn的name无法定义
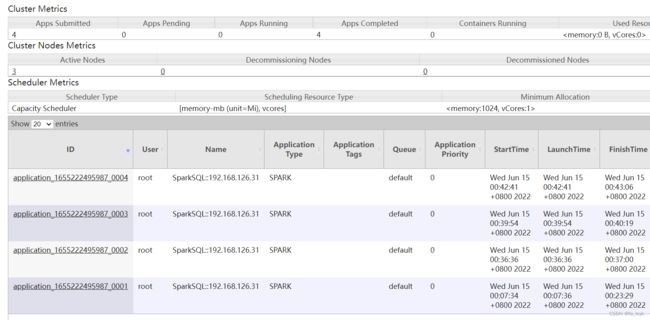
spark-submit提交
spark-submit \
--master yarn \
--class org.apache.demo \
--jar XX \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \