CentOS7 Hadoop 3.3.4 集群安装(1 NameNode,3 DataNode)
集群网络配置:
准备三台CentOS7的服务器:
| IP | 服务器名称 |
|---|---|
| 192.168.21.25 | Master |
| 192.168.21.26 | Slave01 |
| 192.168.21.27 | Slave02 |
修改hosts
# Master服务器
vi /etc/hosts
192.168.21.26 Slave01
192.168.21.27 Slave02
192.168.21.25 Master
# Slave01服务器
vi /etc/hosts
192.168.21.27 Slave02
192.168.21.25 Master
# Slave02服务器
vi /etc/hosts
192.168.21.26 Slave01
192.168.21.25 Master
# 测试host连接(去不同服务器上测试相互是否能连接通)
ping Slave01 -c 3
SSH远程登录配置
让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上
# 以下全是Master服务器执行:
# 如果没有该目录,先执行一次ssh localhost
cd ~/.ssh
# 删除之前生成的公匙(如果有)
rm ./id_rsa*
# 创建秘钥(一直按回车就可以)
ssh-keygen -t rsa
# 秘钥写入authorized_keys
cat ~/.ssh/id_rsa.pub >> ./authorized_keys
# 测试免密码登录本机,第一次可能需要输入yes
ssh Master
# 将Master节点的秘钥传给Slave节点(使用root用户,传递id_rsa.pub文件到Slave01和Slave02的/root/hadoop目录下)
scp ~/.ssh/id_rsa.pub root@Slave01:/root/hadoop/
scp ~/.ssh/id_rsa.pub root@Slave02:/root/hadoop/
# 切换Slave01服务器
cat /root/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
# 切换Slave02服务器
cat /root/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
# 切换回Master服务器测试连接
ssh Slave01
ssh Slave02
JDK安装:
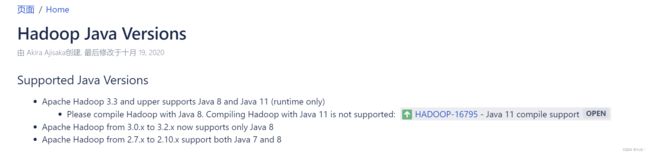
Hadoop Java版本对应
Hadoop Java Versions - Hadoop - Apache Software Foundation
本文采用的是yum安装(不推荐yum安装JDK,没有JPS等工具,并且JDK安装目录比较难找。)
# Master服务器:
yum install java-1.8.0-openjdk.x86_64
# 验证安装
java -version
# 切换到Slave01服务器,安装JDK
ssh Slave01
yum install java-1.8.0-openjdk.x86_64
java -version
# 退出Slave01服务器,返回Master服务器
exit
# 切换到Slave02服务器,安装JDK
ssh Slave02
yum install java-1.8.0-openjdk.x86_64
java -version
exit
# 因为yum安装的openjdk没有jps等工具,后续会经常用到,所以自行安装一下(每个服务器都安装一下)
yum install -y java-1.8.0-openjdk-devel
# 配置JAVA_HOME
# yum安装的jdk需要自己找一下安装目录
which java
# 结果:/usr/bin/java
ls -lr /usr/bin/java
# 结果:lrwxrwxrwx. 1 root root 22 Nov 18 14:48 /usr/bin/java -> /etc/alternatives/java
ls -lrt /etc/alternatives/java
# 结果:lrwxrwxrwx. 1 root root 73 Nov 18 14:48 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64/jre/bin/java
# 最终安装目录:
# /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64/jre/bin/java
# 验证安装目录是否正确
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64/jre/bin/java -version
# 输出版本号即正确
# 设置JAVA_HOME
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
# 验证一下
java -version
echo $JAVA_HOME
安装Hadoop:
下载地址:Apache Hadoop
3.3.4版本:下载地址
# Master服务器:
cd /root/hadoop # 没有目录自己创建一下,三台服务器都放在这个目录下
# 下载包
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz --no-check-certificate
# 解压包
tar -xzvf /root/hadoop/hadoop-3.3.4.tar.gz
# 修改环境变量
vi /etc/profile
export HADOOP_HOME=/root/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
# 设置Hadoop的JAVA_HOME
vi /root/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
# 添加以下配置:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64 # 上面配置JAVA_HOME的时候配置过
export HADOOP_PID_DIR=/root/hadoop/tmp
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
# 验证
hadoop version
配置Hadoop:
# 创建临时文件目录
mkdir -p /root/hadoop/tmp
cd /root/hadoop/hadoop-3.3.4
修改核心配置:
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/root/hadoop/tmpvalue>
property>
<property>
<name>hadoop.data.dirname>
<value>/opt/data/hadoop/datavalue>
property>
configuration>
hdfs配置
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>master:50070value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave01:50090value>
property>
configuration>
mapreduce配置:
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
yarn配置
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.application.classpathname>
<value>
/root/hadoop/hadoop-3.3.4/etc/hadoop:/root/hadoop/hadoop-3.3.4/share/hadoop/common/lib/*:/root/hadoop/hadoop-3.3.4/share/hadoop/common/*:/root/hadoop/hadoop-3.3.4/share/hadoop/hdfs:/root/hadoop/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/root/hadoop/hadoop-3.3.4/share/hadoop/hdfs/*:/root/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/lib/*:/root/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/*:/root/hadoop/hadoop-3.3.4/share/hadoop/yarn:/root/hadoop/hadoop-3.3.4/share/hadoop/yarn/lib/*:/root/hadoop/hadoop-3.3.4/share/hadoop/yarn/*
value>
property>
configuration>
修改工作节点:
vi etc/hadoop/workers
master
slave01
slave02
配置同步到Slave节点:
# Master服务器,hadoop文件同步到Slave节点
scp -r /root/hadoop/hadoop-3.3.4 slave01:/root/hadoop/
scp -r /root/hadoop/hadoop-3.3.4 slave01:/root/hadoop/
# Master服务器,hadoop配置同步到Slave节点
scp -r /etc/profile slave01:/etc
scp -r /etc/profile slave02:/etc
# 连接Slave节点,测试
ssh slave01
source /etc/profile
hadoop version
exit
ssh slave02
source /etc/profile
hadoop version
exit
启动集群:
# NameNode格式化(如果配置环境变量,就不需要进入bin或sbin目录)
hdfs namenode -format
# 启动
/root/hadoop/hadoop-3.3.4/sbin/start-dfs.sh
访问集群:
http://192.168.21.25:50070/dfshealth.html#tab-overview


完事~